目录
- 习题7-1 在小批量梯度下降中,试分析为什么学习率要和批量大小成正比
- 习题7-2 在Adam算法中,说明指数加权平均的偏差修正的合理性
- 习题7-9 证明在标准的随机梯度下降中,权重衰减正则化和L_{2}正则化的效果相同.并分析这一结论在动量法和Adam算法中是否依然成立
- 总结
习题7-1 在小批量梯度下降中,试分析为什么学习率要和批量大小成正比
在小批量梯度下降中有:
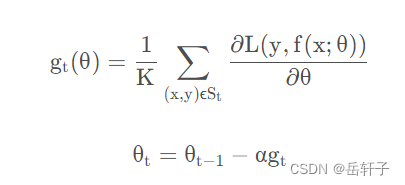
其中
g
t
=
δ
K
g_t = \frac{\delta }{K}
gt=Kδ ,则有:
θ
t
=
θ
t
−
1
−
δ
K
α
θ_t = θ_{t-1} - \frac{\delta }{K}α
θt=θt−1−Kδα
因此我们要使得参数最优,则
α
K
\frac{\alpha}{K}
Kα 为最优的时候的常数,故学习率要和批量大小成正比。
习题7-2 在Adam算法中,说明指数加权平均的偏差修正的合理性

习题7-9 证明在标准的随机梯度下降中,权重衰减正则化和L_{2}正则化的效果相同.并分析这一结论在动量法和Adam算法中是否依然成立


分析这一结论在动量法和Adam算法中是否成立?
L2正则化梯度更新的方向取决于最近一段时间内梯度的加权平均值。
当与自适应梯度相结合时(动量法和Adam算法),
L2正则化导致导致具有较大历史参数 (和/或) 梯度振幅的权重被正则化的程度小于使用权值衰减时的情况。
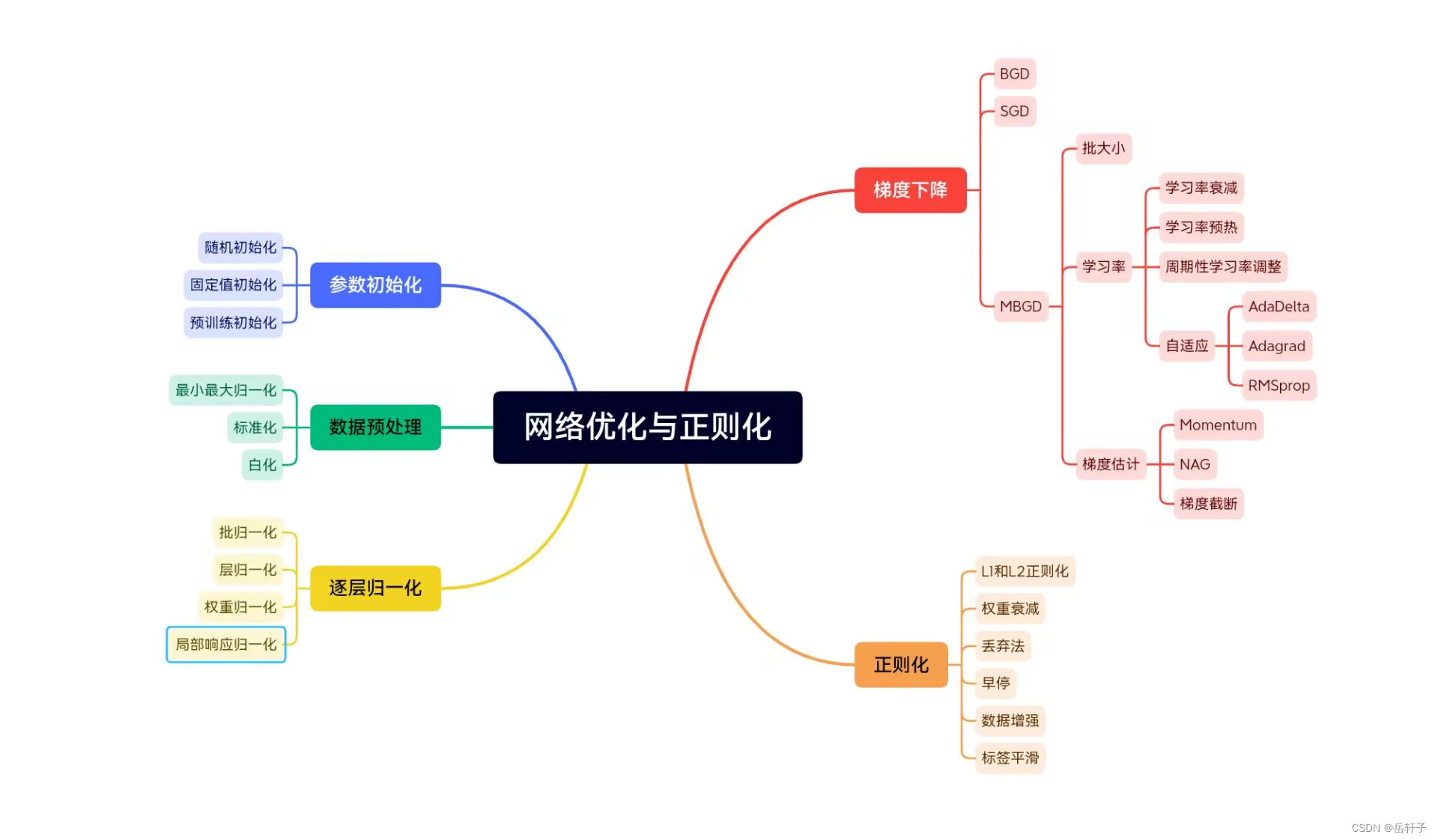
总结


![[附源码]Python计算机毕业设计大学生日常行为评分管理系统Django(程序+LW)](https://img-blog.csdnimg.cn/77891ceabe6a4aaaad074f5a5c4ec5b6.png)


![[附源码]Python计算机毕业设计Django安防管理平台](https://img-blog.csdnimg.cn/9154534cdc794ed3b2aaf397140920ab.png)