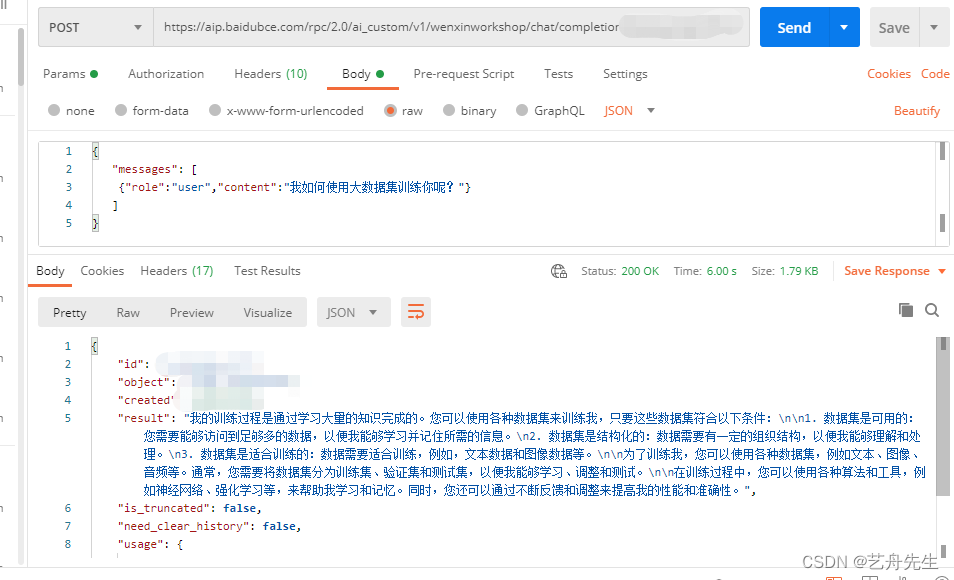
注:本文翻译自https://legacy-docs.timescale.com/v1.7/using-timescaledb/compression
从1.5版本开始,TimescaleDB支持本地压缩数据的能力。此功能不需要使用任何特定的文件系统或外部软件,并且正如您将看到的,用户可以很容易地设置和配置它。
在使用本指南之前,我们建议查看一下我们的体系结构部分,以了解有关压缩如何工作的更多信息。在高层次上,TimescaleDB的内置作业调度器框架将跨多个TimescaleDB超级表块异步地将最近的数据从未压缩的基于行的形式转换为压缩的列形式。
本节将介绍这些概念,并帮助您了解本机压缩的一些优点和局限性。
如何启用压缩
ALTER TABLE measurements SET (
timescaledb.compress,
timescaledb.compress_segmentby = 'device_id'
);
SELECT add_compress_chunks_policy('measurements', INTERVAL '7 days');
这两个命令配置压缩并告诉系统压缩超过7天的块。下面我们将描述如何选择压缩周期,以及如何设置compress_segmentby选项。
如何选择压缩周期
你可能想知道为什么我们只在数据老化后(在上面的例子中是7天后)压缩数据,而不是立即压缩数据。
有两个原因:查询效率和处理乱序数据的能力。
在查询效率方面,我们的经验表明,当数据刚刚被摄取并引用最近的时间间隔时,我们倾向于以更浅(时间上)和更宽(列上)的方式查询数据。这些通常是调试或“整个系统”查询。例如,“显示服务器’X’的当前CPU使用情况、磁盘使用情况、能耗和I/O”。在这种情况下,PostgreSQL原生的未压缩的基于行的格式将为我们提供最佳的查询性能。
随着数据开始老化,查询在本质上趋向于分析性,并且涉及更少的列。例如,此类深入而狭窄的查询可能想要计算上个月的平均磁盘使用情况。这些类型的查询极大地受益于压缩的列格式。
因此,我们的压缩设计使您可以两全其美:最近的数据以未压缩的行格式被吸收,用于高效的浅查询和宽查询,然后在老化后自动转换为压缩的列格式,并且最常用的查询是使用深查询和窄查询。因此,选择压缩数据的时间需要考虑的一个问题是,当查询模式从浅而宽变为深而窄时。
另一件要考虑的事情是,对已压缩的块的修改是低效的。实际上,当前版本的压缩完全禁止在压缩块上执行insert、UPDATES和delete操作(尽管您可以手动解压缩块来修改它)。因此,您只希望在不太可能进一步修改的情况下压缩块。为最小化解压缩块的需要,应该为块压缩添加的延迟量在每个用例中是不同的,但请记住要注意无序数据。
注:TimescaleDB的当前版本支持查询压缩块中的数据。但是,它不支持在压缩块中插入或更新。我们还阻止使用压缩块修改超级表的模式。
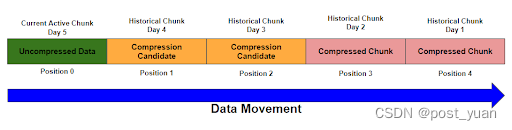
关于压缩,块可以处于三种状态之一:活动(未压缩)、压缩候选(未压缩)和压缩。活动块是那些当前正在摄取数据的块。由于压缩机制的性质,它们在压缩时不能有效地摄取数据。如下图所示,随着这些块的老化,它们成为压缩候选者,一旦它们根据压缩策略变得足够老,就会被压缩。
如何选择segmentby字段
segmentby选项决定访问压缩数据的主键。特别是,引用WHERE子句中的segmentby列的查询非常有效。因此,选择正确的分段列是很重要的。我们将在下面给出一些直觉。
如果您的表有一个主键,那么除了“time”之外的所有主键列都应该进入segmentby列表。在上面的例子中,可以很容易地想象在(device_id, time)上有一个主键,因此分段列表是device_id。
考虑这个问题的另一种方法是,每个分段列的具体值集应该定义一个可以随时间绘制的值的“时间序列”。例如,如果我们有一个像下面这样的EAV表:
| time | device_id | metric_name | value |
|---|---|---|---|
| 8/22/2019 0:00 | 1 | cpu | 88.2 |
| 8/22/2019 0:00 | 1 | device_io | 0.5 |
| 8/22/2019 1:00 | 1 | cpu | 88.6 |
| 8/22/2019 1:00 | 1 | device_io | 0.6 |
然后,该系列将由device_id和metric_name列对定义。因此,segmentby选项应该是device_id, metric_name。
压缩如何工作
我们构建列式存储的高级方法是将许多宽数据行(例如1000行)转换为单行数据。但是现在,新行的每个字段(列)存储了一个有序的数据集,包括1000行的整个列。
因此,让我们考虑一个简化的例子,使用如下所示的表:
| time | device_id | cpu | dis_io | energy_consumption |
|---|---|---|---|---|
| 12:00:02 | 1 | 88.2 | 20 | 0.8 |
| 12:00:010 | 2 | 300.5 | 30 | 0.9 |
| 12:00:01 | 1 | 88.6 | 25 | 0.85 |
| 12:00:01 | 2 | 299.1 | 40 | 0.95 |
将此数据转换为单行后,数据以“数组”形式:
| time | device_id | cpu | disk_io | energy_consumption |
|---|---|---|---|---|
| [12:00:02, 12:00:02, 12:00:01, 12:00:1 ] | [1, 2, 1, 2] | [88.2, 300.5, 88.6, 299.1] | [20, 30, 25, 40] | [0.8, 0.9, 0.85, 0.95] |
理解segmentby选项
我们可以根据特定的列对压缩行进行分段,这样每个压缩行对应于单个项目的数据,例如,特定的device_id。segmentby选项强制系统分解压缩数组,以便每个压缩行对于每个segmentby列具有单个值。例如,如果我们将device_id设置为segmentby列,那么我们运行的示例的压缩版本将是这样的:
| time | device_id | cpu | dis_io | energy_consumption |
|---|---|---|---|---|
| [12:00:02, 12:00:01] | 1 | [88.2, 88.6] | [20, 25] | [0.8, 0.85] |
| [12:00:02, 12:00:01] | 2 | [300.5, 299.1] | [30, 40] | [0.9, 0.95] |
上面的示例显示device_id列不再是一个数组,而是定义了与该行中所有压缩数据相关联的单个值。
由于单个值与压缩行相关联,因此不需要解压缩来计算该值。使用WHERE子句按分段按列进行过滤的查询效率要高得多,因为解压可以在过滤之后而不是之前进行(从而避免了对过滤掉的行进行解压缩)。实际上,为了获得更高效的访问,我们在每个分段列上构建b-tree索引。
分段列很有用,但可能被过度使用。如果指定的分段列太多,则每个压缩列中的项数就会变小,压缩效果就会降低。因此,我们建议您确保每个段每个块至少包含100行。如果不是这种情况,那么您可以将一些分段列移动到orderby选项中(如下一节所述)。
理解orderby选项
orderby选项确定压缩数组中项的顺序。
默认情况下,此选项被设置为超表时间列的降序。如果适当地设置了segmentby选项,这在大多数情况下就足够了,但在高级场景中也可以手动设置为不同的设置。
顺序对压缩比和查询性能都有影响。
当相邻数据在量级上接近或呈现某种趋势时,压缩是最有效的。换句话说,随机或无序的数据压缩效果很差。因此,在压缩数据时,输入数据的顺序使其遵循趋势是很重要的。
让我们再看一下没有任何segmentby列的运行示例。
| time | device_id | cpu | disk_io | energy_consumption |
|---|---|---|---|---|
| [12:00:02, 12:00:02, 12:00:01, 12:00:01 ] | [1, 2, 1, 2] | [88.2, 300.5, 88.6, 299.1] | [20, 30, 25, 40] | [0.8, 0.9, 0.85, 0.95] |
注意,数据是按时间列排序的。但是,如果我们看一下cpu列,我们可以看到压缩器将无法有效地压缩它。虽然两个设备输出的值都是浮点数,但测量值的大小不同。浮点数列表[88.2,300.5,88.6,299.1]的压缩效果很差,因为相同大小的值不是相邻的。但是,我们可以按device_id,时间DESC排序,通过设置表选项如下:
ALTER TABLE measurements
SET (timescaledb.compress,
timescaledb.compress_orderby = 'device_id, time DESC');
使用这些设置,压缩表将如下所示:
| time | device_id | cpu | disk_io | energy_consumption |
|---|---|---|---|---|
| [12:00:02, 12:00:01, 12:00:02, 12:00:01 ] | [1, 1, 2, 2] | [88.2, 88.6, 300.5, 299.1] | [20, 25, 30, 40] | [0.8, 0.85, 0.9, 0.95] |
现在,每个设备的测量顺序是连续的,因此测量值表现出更多的趋势。cpu系列[88.2,88.6,300.5,299.1]将压缩得更好。
如果你看一下上面的例子,device_id作为一个分段,你会发现这将有很好的压缩,因为排序只在一个段内重要,而按设备分段保证每个段表示一个序列,如果只按时间排序。因此,将项目按顺序和分段列排列可以获得类似的结果。这就是为什么,如果通过标识符分段导致段变得太小,我们建议将segmentby列移动到顺序列表的前缀中。
我们还使用排序来提高查询性能。如果查询使用与压缩相同(或类似)的顺序,我们知道可以增量解压缩,并且仍然以相同的顺序返回结果。我们也可以避免排序。此外,系统还会自动创建存储任意顺序列的最小值和最大值的附加列。这样,查询执行器就可以查看这个指定压缩列中值范围(例如,时间戳)的特殊列,而无需首先执行任何解压缩,以便确定该行是否可能匹配用户SQL查询指定的时间谓词。