0 数据集
# Visual Python: Data Analysis > File
vp_df = pd.read_csv('https://raw.githubusercontent.com/visualpython/visualpython/main/visualpython/data/sample_csv/fish.csv')
vp_df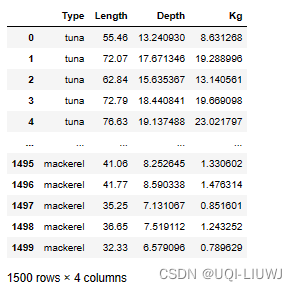
1 单列聚合
vp_df.groupby('Type')['Kg'].mean()
'''
Type
mackerel 1.417456
salmon 5.996645
tuna 18.038317
Name: Kg, dtype: float64
'''按照Type 聚类,聚类后将同组的Kg属性合并,求均值
聚合的内容可以是 max, min, mean, unique(唯一值), nunique(唯一值数量),lambda 表达式
1.1 单列聚合多个操作
vp_df.groupby('Type')[['Kg']].agg(['mean','max'])
1.2 单列聚合多个属性
vp_df.groupby('Type')[['Kg','Depth']].mean() 
按照Type 聚类,聚类后将同组的Kg、Depth属性合并,求均值
1.3 单列聚合多个属性多个操作
vp_df.groupby('Type')[['Kg','Depth']].agg(['mean','max'])
1.4 多列聚合
vp_df.groupby(['Type','Depth']).agg(mean_kg=('Kg','mean'),
max_depth=('Depth','max')) 
2 对聚合结果重命名
重命名的名字=(需要操作的列名,需要的操作名)
vp_df.groupby('Type').agg(mean_kg=('Kg','mean'),
max_depth=('Depth','max'))
3 生成了多少个组 ngroups
vp_df.groupby(['Type','Depth']).ngroups
#1500参考内容:Python数据分组处理必备:pandas groupby (qq.com)




![P2698 [USACO12MAR] Flowerpot S](https://img-blog.csdnimg.cn/img_convert/ff4753d36db6acc0d7816ad125b19377.png)


![[驱动开发]字符设备驱动应用——点灯](https://img-blog.csdnimg.cn/a0ef0b3f46424f258ec4d32e0324a17a.png)