使用SPSS进行分析求解
第一题
- 下表1.1是中国1994-2016年国内旅游总花费Y、国内生产总值X1、铁路里程X2和公路里程X3的数据,请据此分析如下问题:
(1)就建立简单线性回归模型,分别分析中国国内旅游总花费与国内生产总值、铁路里程和公路里程数据的数量关系。
(2)对建立的回归模型进行检验,对几个模型估计检验结果进行比较。
| 年份 | 国内旅游总花费/议员 | 国内生产总值/亿元 | 铁路里程/万公里 | 公路里程/万公里 |
|---|---|---|---|---|
| 1994 | 1023.5 | 48637.5 | 5.9 | 111.78 |
| 1995 | 1375.7 | 61339.9 | 6.24 | 115.7 |
| 1996 | 1638.4 | 71813.6 | 6.49 | 118.58 |
| 1997 | 2112.7 | 79715 | 6.6 | 122.64 |
| 1998 | 2391.2 | 85195.5 | 6.64 | 127.85 |
| 1999 | 2831.9 | 90564.4 | 6.74 | 135.17 |
| 2000 | 3175.5 | 100280.1 | 6.87 | 167.98 |
| 2001 | 3522.4 | 110863.1 | 7.01 | 169.8 |
| 2002 | 3878.4 | 121717.4 | 7.19 | 176.52 |
| 2003 | 3442.3 | 137422 | 7.3 | 180.98 |
| 2004 | 4710.7 | 161840.2 | 7.44 | 187.07 |
| 2005 | 5285.9 | 187318.9 | 7.54 | 334.52 |
| 2006 | 6229.7 | 219438.5 | 7.71 | 345.7 |
| 2007 | 7770.6 | 270232.3 | 7.8 | 358.37 |
| 2008 | 8749.3 | 319515.5 | 7.97 | 373.02 |
| 2009 | 10183.7 | 349081.4 | 8.55 | 386.08 |
| 2010 | 12579.8 | 413030.3 | 9.12 | 400.82 |
| 2011 | 19305.4 | 489300.6 | 9.32 | 410.64 |
| 2012 | 22706.2 | 540367.4 | 9.76 | 423.75 |
| 2013 | 26276.1 | 595244.4 | 10.31 | 435.62 |
| 2014 | 30311.9 | 643974 | 11.18 | 446.39 |
| 2015 | 34195.1 | 689052.1 | 12.1 | 457.73 |
| 2016 | 39390 | 743585.5 | 12.4 | 469.63 |
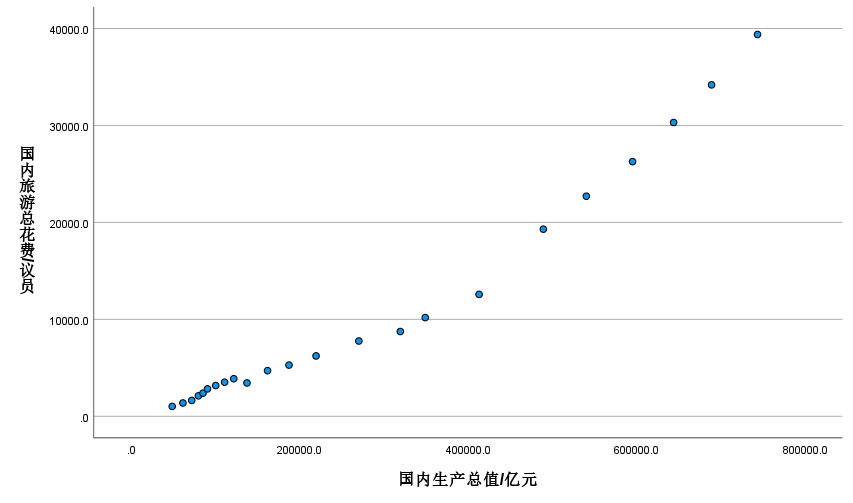
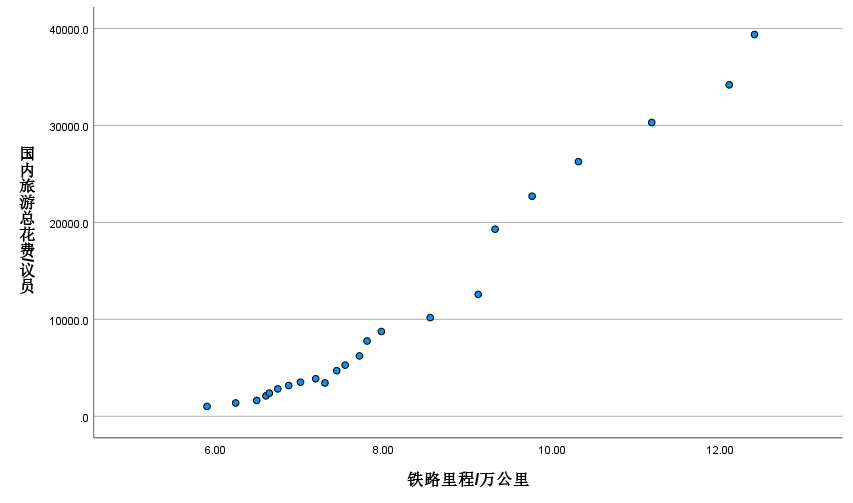
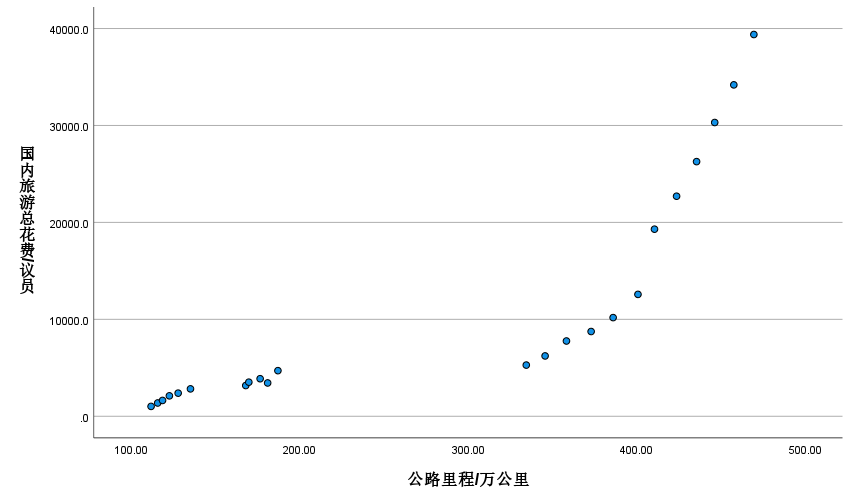
国内生产总值
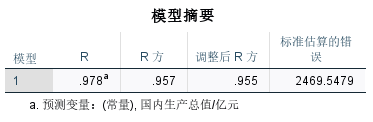

y ^ 1 = − 3228.021 + 0.05 x R 2 = 0.957 , t = 21.68 \begin{aligned}\widehat{y}_{1}=-3228.021+0.05x\\ R^{2}=0.957,t=21.68\end{aligned} y 1=−3228.021+0.05xR2=0.957,t=21.68
R2=0.957,表明所建模型整体上对样本数据拟合程度较好。
回归系数t的检验,t=21.7>t0.025(21)=2.08,对斜率系数的显著性表明,国内生产总值对中国国内旅游总花费存在显著影响
铁路里程
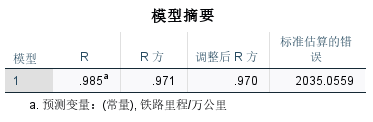

y ^ 2 = − 39438.731 + 6165.253 x R 2 = 0.971 , t = 26.496 \begin{aligned} \widehat{y}_{2}=-39438.731+6165.253x \\ R^{2}=0.971,t=26.496\end{aligned} y 2=−39438.731+6165.253xR2=0.971,t=26.496
R2=0.971,说明所建模型整体上对样本数据拟合程度较好。
t=26.496>t0.025(21)=2.08,对斜率系数的显著性表明,铁路里程对国内旅游总花费存在显著影响
公路里程
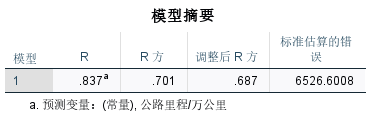

y ^ 3 = − 9106.166 + 71.639 x R 2 = 0.701 , t = 7.04 \begin{aligned}\widehat{y}_{3}=-9106.166+71.639x\\ R^{2}=0.701,t=7.04\end{aligned} y 3=−9106.166+71.639xR2=0.701,t=7.04
R2=0.701,说明所建模型整体上对样本数据拟合程度较好。
t=7.04>t0.025(21)=2.08,对于斜率系数的显著性表明,公路里程对国内旅游总花费存在显著影响。
第二题
- 进入21世纪后,中国的家用汽车增长很快。家用汽车的拥有量收到经济增长、公共服务、市场价格、交通状况、社会环境、政策因素的影响。为了研究一些主要因素与家用汽车有用量的数量关系,选择“百户拥有家用汽车量”、“人均地区生产总值”“城镇人口比重”、“居民消费价格指数”等变量,2016年全国各省区市的有关数据如下表1.2,试分析下述问题:
(1)建立百户拥有家用汽车量计量经济模型,估计参数并对模型进行检验,检验结论的依据是什么?
(2)分析模型参数估计结果的经济意义,你如何解读模型估计检验的结果?
(3)你认为模型需要如何改进?
| 地区 | 百户拥有家用汽车量/辆 | 人均地区生产总值/万元 | 城镇人口比重/% | 居民消费价格指数(上年=100) |
|---|---|---|---|---|
| 北京 | 47.3 | 11.81 | 86.5 | 101.4 |
| 天津 | 43.1 | 11.45 | 82.93 | 102.1 |
| 河北 | 35.3 | 4.29 | 53.32 | 101.5 |
| 山西 | 24.6 | 3.54 | 56.21 | 101.1 |
| 内蒙古 | 34.1 | 7.19 | 61.19 | 101.2 |
| 辽宁 | 24.2 | 5.08 | 67.37 | 101.6 |
| 吉林 | 21.4 | 5.41 | 55.97 | 101.6 |
| 黑龙江 | 14.2 | 4.05 | 59.2 | 101.5 |
| 上海 | 29.3 | 11.64 | 87.9 | 103.2 |
| 江苏 | 37.9 | 9.67 | 67.72 | 102.3 |
| 浙江 | 45.2 | 8.45 | 67 | 101.9 |
| 安徽 | 18.7 | 3.94 | 51.99 | 101.8 |
| 福建 | 26.5 | 7.44 | 63.6 | 101.7 |
| 江西 | 21.5 | 4.03 | 53.1 | 102 |
| 山东 | 44.1 | 6.84 | 59.02 | 102.1 |
| 河南 | 23.7 | 4.25 | 48.5 | 101.9 |
| 湖北 | 17.6 | 5.55 | 58.1 | 102.2 |
| 湖南 | 21.4 | 4.62 | 52.75 | 101.9 |
| 广东 | 29.4 | 7.35 | 69.2 | 102.3 |
| 广西 | 22.2 | 3.79 | 48.08 | 101.6 |
| 海南 | 18.1 | 4.42 | 56.78 | 102.8 |
| 重庆 | 19.6 | 5.82 | 62.6 | 101.8 |
| 四川 | 20.4 | 3.99 | 49.21 | 101.9 |
| 贵州 | 21.2 | 3.31 | 44.15 | 101.4 |
| 云南 | 28.7 | 3.1 | 45.03 | 101.5 |
| 西藏 | 23.3 | 3.48 | 29.56 | 102.5 |
| 陕西 | 19.9 | 5.09 | 55.34 | 101.3 |
| 甘肃 | 18 | 2.76 | 44.69 | 101.3 |
| 青海 | 30.5 | 4.34 | 51.63 | 101.8 |
| 宁夏 | 30.1 | 4.69 | 56.29 | 101.5 |
| 新疆 | 25.2 | 4.02 | 48.35 | 101.4 |
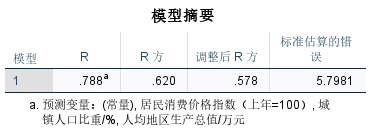
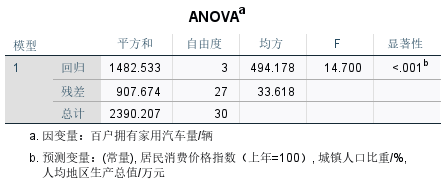
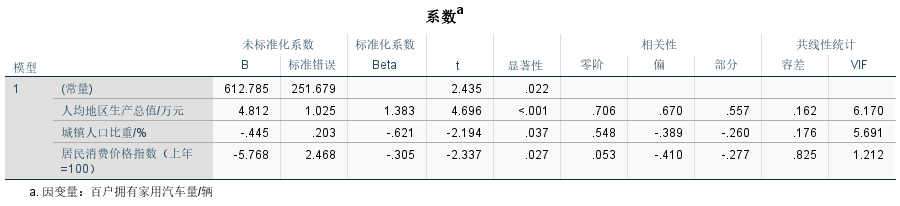
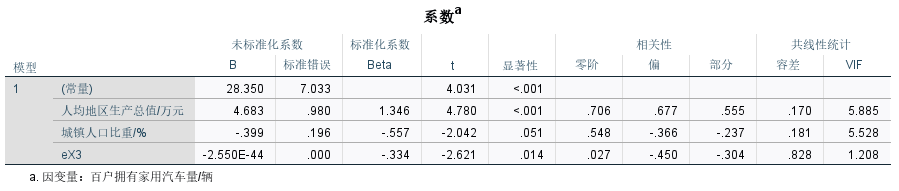
(1)模型建立:y=612.785+4.812x1-0.445x2-5.768x3
模型检验:
- R2=0.62,修正后的R2=0.578,接近于1,说明样本拟合度较好
- F检验:F=14.7>F0.05(3,27)=2.97,拒绝原假设,说明“人均地区生产总值”、“城镇人口比重”、“居民消费价格指数”对“百户拥有家用汽车量”有显著影响
- T检验:t0.025(27)=2.052,在模型系数中,t的值分别为2.435、4.696、-2.194、-2.337,四个的绝对值均大于2.052。同时,四个变量的显著性值P均小于0.05。因此可以判断“人均地区生产总值”、“城镇人口比重”、“居民消费价格指数”对“百户拥有家用汽车量”有显著影响
检验依据:
- 可决系数越大,说明拟合程度越好。
- F 的值与临界值比较,若大于临界值,则否定原假设,回归方程是显著的; 若小于临界值,则接受原假设,回归方程不显著。
- t 的值与临界值比较,若大于临界值,则否定原假设,系数都是显著地:若小于临界值,则接受原假设,系数不显著。
- 显著水平与p值比较,若大于p值,则可在显著性水平下拒绝原假设,系数显著:若小于p值,则接受原假设,系数不显著。
(2)模型估计结果说明,在假定其他变量不变的情况下,人均地区生产总值每增长1万元,百户拥有家用汽车量增加4.812辆;城镇人口比重每增长1%,百户拥有家用汽车量减少0.445辆;居民消费价格指数增长1个百分点,百户拥有家用汽车量减少5.768辆。
(3)模型改进
y=28.35+4.683x1-0.399x2-2.55*10-44ex3
y = 28.35 + 4.683 x 1 − 0.399 x 2 − 2.55 × 1 0 − 44 e x 3 \begin{aligned}y=28.35+4.683x_{1}-0.399x_{2}-2.55\times 10^{-44} e^{x_{3}}\end{aligned} y=28.35+4.683x1−0.399x2−2.55×10−44ex3
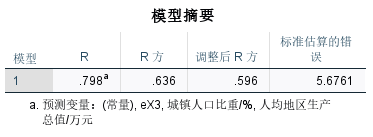
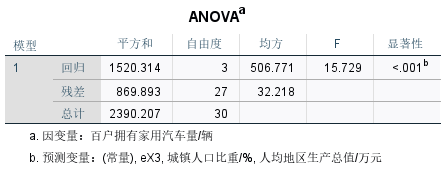
模型改进后R2=0.636,修正后的R2=0.596,样本拟合度更高
第三题
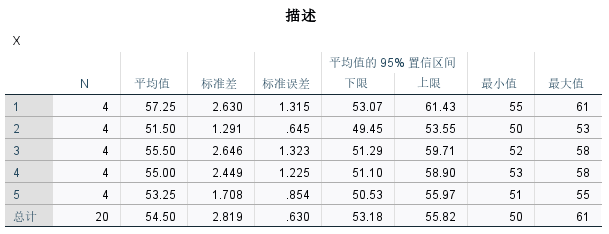
- 5个水稻品种的产量比较实验,随机区组设计,4次重复,获得每个小区产量资料如下表1.3,试分析这5个水稻品种间产量水平有无明显差异。
| 品种 | 区组(重复) | |||
|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |
| 1 | 61 | 57 | 55 | 56 |
| 2 | 53 | 52 | 50 | 51 |
| 3 | 52 | 58 | 55 | 57 |
| 4 | 58 | 56 | 53 | 53 |
| 5 | 53 | 51 | 54 | 55 |
对原始数据集进行调整
X Y1 61 1 57 1 55 1 56 1 53 2 52 2 50 2 51 2 58 4 56 4 53 4 53 4 53 5 51 5 54 5 55 5 52 3 58 3 55 3 57 3
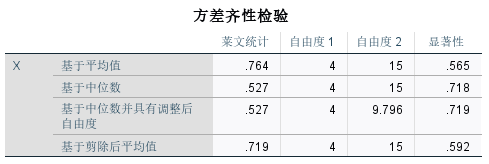
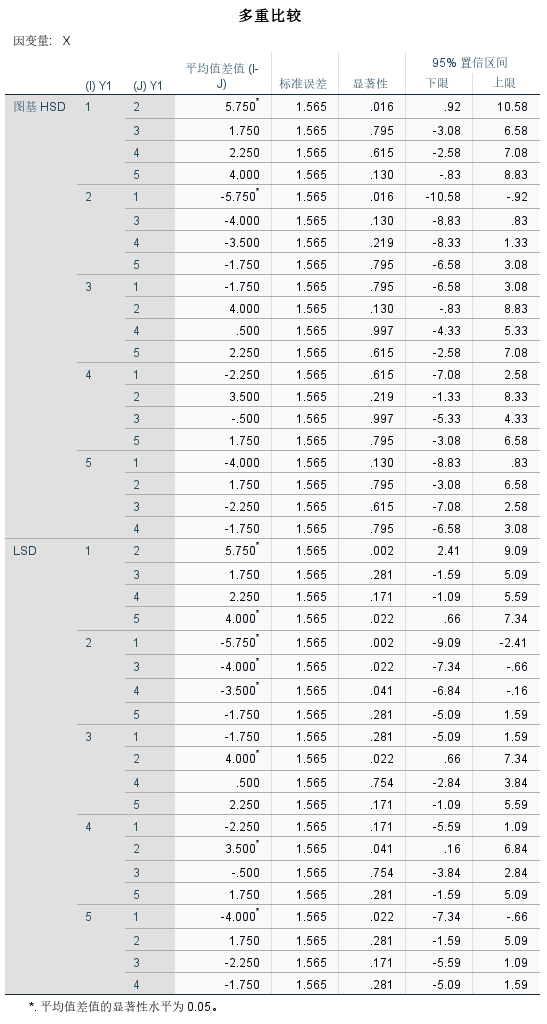
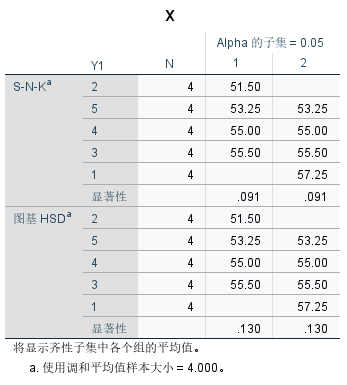
在方差齐性检验表中,显著性均大于0.05,因此满足方差齐性这一前提条件。
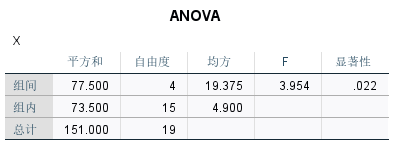
在ANOVA表中,F对应的显著性0.022小于0.05,因此拒绝原假设,认为五组数据中,至少有一组数据与其它几组数据之间存在显著性差异的。
在多重比较表中,分析LSD下的比较结果得出结论:
品种1的产量显著高于品种2、5;品种2的产量显著低于品种1、3、4
品种1和品种3、4无显著差异;品种2和品种5无显著差异;品种5和品种2、3、4无显著差异
第四题
- 某位老师正在探讨新的历史教学方法,包括使用录音录像和计算机。他想知道这些新技木对于普通学生和较有天赋的学生的影响是否一样。12 名普通学生和 12 名较有天赋学生被随机分到三个组,在学期未所有学生都进行同样的期末考试,结果见下表1.4。试进行一次两因素方差分析,为你的结果生成一个方差分析表,并分析报告你的结果。
| 分类 | 传统方法 | 录音录像 | 计算机 |
|---|---|---|---|
| 普通学生 | 72 | 69 | 63 |
| 83 | 66 | 72 | |
| 96 | 78 | 78 | |
| 79 | 64 | 59 | |
| 较有天赋学生 | 83 | 96 | 89 |
| 95 | 87 | 93 | |
| 89 | 93 | 86 | |
| 98 | 86 | 95 |
原始数据集调整
X Y1 Y2 72 1 1 69 1 2 63 1 3 83 1 1 66 1 2 72 1 3 96 1 1 78 1 2 78 1 3 79 1 1 64 1 2 59 1 3 83 2 1 96 2 2 89 2 3 95 2 1 87 2 2 93 2 3 89 2 1 93 2 2 86 2 3 98 2 1 86 2 2 95 2 3

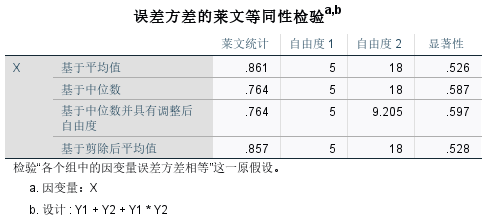
通过误差方差的莱文等同性检验表可知,显著性值均大于0.05,所以满足方差齐性的条件
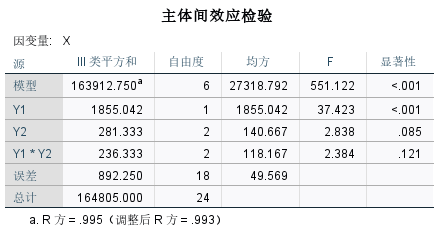
分析主体间效应检验表读出如下结论:
- Y1的检测统计量,F=37.423,P<0.001<0.05,说明学生是否有天赋对学生成绩有显著影响
- Y2的监测统计量,F=2.838,P=0.085>0.05,说明教学方式的更换对学生成绩无显著影响
- Y1*Y2的监测统计量,F=2.384,P=0.121>0.05,说明学生是否有天赋和教学方式可能无交互作用
在上述分析的基础上结合描述统计表得出结论:
较有天赋的学生成绩显著高于普通学生的成绩,虽然不能得出教学方式对学生成绩是否有显著影响,但是在现有数据的分析中,表现出传统教学方式的学生成绩优于新教学方式。










![[23] TriPlaneNet: An Encoder for EG3D Inversion](https://img-blog.csdnimg.cn/f0f3b565861042ae95284c2974cfe7b7.png)