目录
原因
由于实时性,所以算法设计需要满足一下两点
算法设计
算法实现
算法公式
完整代码
原因
用户对电影的偏好随着时间的推移总是会发生变化的。此时离线系统无法解决,需要实时推荐。
由于实时性,所以算法设计需要满足一下两点
1 根据用户最近几次评分进行推荐;
2 计算量要小,满足响应时间上面的实时;
算法设计
借鉴基于物品Item-CF的算法,将相似度和评分结合起来。
算法实现
1 当用户完成一次评分后,从Redis里取最近的k次评分的数据(mid,score);
2 备选电影(与评分电影的相似的电影)和评分过的电影,根据电影形似度矩阵计算相似度;
3 为提高精准率和召回率,设置偏移项,进行模型的鼓励与惩罚。
算法公式
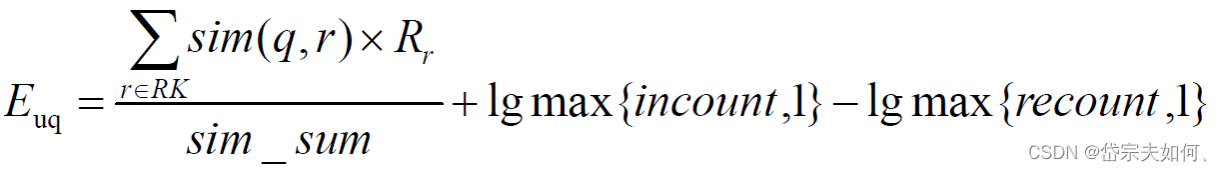
其中:
表示用户 u 对电影 r 的评分;
sim(q,r)表示电影 q 与电影 r 的相似度,设定最小相似度为 0.6,当电影 q 和 电影 r 相似度低于 0.6 的阈值,则视为两者不相关并忽略;
sim_sum 表示 q 与 RK 中电影相似度大于最小阈值的个数;
incount 表示 RK 中与电影 q 相似的、且本身评分较高(>=3)的电影个数;
recount 表示 RK 中与电影 q 相似的、且本身评分较低(<3)的电影个数;
核心代码
def computeMovieScore(candidateMovies: Array[Int],userRecentlyRatings: Array[(Int, Double)],simMovies:scala.collection.Map[Int,scala.collection.immutable.Map[Int,Double]]): Array[(Int, Double)] = {
val scores = scala.collection.mutable.ArrayBuffer[(Int, Double)]()
val increMap = scala.collection.mutable.HashMap[Int, Int]()
val decreMap = scala.collection.mutable.HashMap[Int, Int]()
for(candidateMovie <- candidateMovies; userRecentlyRating <- userRecentlyRatings ){
val simScore =getMoviesSimScore( candidateMovie, userRecentlyRating._1, simMovies )
if(simScore > 0.7){
scores += ( (candidateMovie, simScore * userRecentlyRating._2) )
if (userRecentlyRating._2 > 3) {
increMap(candidateMovie) = increMap.getOrDefault(candidateMovie, 0) + 1
} else {
decreMap(candidateMovie) = decreMap.getOrDefault(candidateMovie, 0) + 1
}
}
}
scores.groupBy(_._1).map{
case (mid, scoreList) =>
(mid,scoreList.map(_._2).sum / scoreList.length + log(increMap.getOrDefault(mid, 1)) - log(decreMap.getOrDefault(mid, 1)) )
}.toArray
}完整代码
package com.qh.streaming
import com.mongodb.casbah.commons.MongoDBObject
import com.mongodb.casbah.{MongoClient, MongoClientURI}
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import redis.clients.jedis.Jedis
/**
* 连接助手
* 序列化
*/
object ConnHelper extends Serializable {
lazy val jedis = new Jedis("hadoop100") //redis
lazy val mongoClient = MongoClient(MongoClientURI("mongodb://hadoop100:27017/recommender"))
}
case class MongoConfig(uri: String, db: String)
// 定义一个基准推荐对象
case class Recommendation(mid: Int, score: Double)
// 定义基于预测评分的用户推荐列表
case class UserRecs(uid: Int, recs: Seq[Recommendation])
// 定义基于LFM电影特征向量的电影相似度列表
case class MovieRecs(mid: Int, recs: Seq[Recommendation])
object StreamingRecommender {
val MAX_USER_RATINGS_NUM = 20
val MAX_SIM_MOVIES_NUM = 20
val MONGODB_STREAM_RECS_COLLECTION = "StreamRecs"
val MONGODB_RATING_COLLECTION = "Rating"
val MONGODB_MOVIE_RECS_COLLECTION = "MovieRecs"
def main(args: Array[String]): Unit = {
val config = Map(
"spark.cores" -> "local[*]",
"mongo.uri" -> "mongodb://hadoop100:27017/recommender",
"mongo.db" -> "recommender",
"kafka.topic" -> "recommender"
)
val sparkConf = new SparkConf().setMaster(config("spark.cores")).setAppName("StreamingRecommender")
// spark2.x sparksession已封装除了 sparkstream上下文之外的 session
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
// 拿到streaming context
val sc = spark.sparkContext
val ssc = new StreamingContext(sc, Seconds(2)) // batch duration 批处理时间 微批次
import spark.implicits._
implicit val mongoConfig = MongoConfig(config("mongo.uri"), config("mongo.db"))
//加载电影相似度矩阵,广播
val simMovieMatrix = spark.read
.option("uri", mongoConfig.uri)
.option("collection", MONGODB_MOVIE_RECS_COLLECTION)
.format("com.mongodb.spark.sql")
.load()
.as[MovieRecs]
.rdd //为了查询相似度的过程更快,转换成map
.map {
movieRecs =>
(movieRecs.mid, movieRecs.recs.map(x => (x.mid, x.score)).toMap)
}.collectAsMap()
val simMovieMatrixBroadCast = sc.broadcast(simMovieMatrix)
// 定义kafka连接参数
val kafkaParam = Map(
"bootstrap.servers" -> "hadoop100:9092",
"key.deserializer" -> classOf[StringDeserializer], //反序列化
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "recommender",
"auto.offset.reset" -> "latest" //偏移量初始化设置
)
//kafka创建一个DStream
val kafkaStream = KafkaUtils.createDirectStream[String, String](
ssc, LocationStrategies.PreferConsistent, ConsumerStrategies.Subscribe[String, String](Array(config("kafka.topic")), kafkaParam )
)
//把原始数据 UID|MID|SCORE|TIMESTAMP =>评分流
val ratingStream = kafkaStream.map {
msg =>
val attr = msg.value().split("\\|")
(attr(0).toInt, attr(1).toInt, attr(2).toDouble, attr(3).toInt)
}
//继续做流式处理,核心实时算法
ratingStream.foreachRDD{
rdds => rdds.foreach{
case (uid,mid, score, timestamp) =>
println("rating data coming ! >>>>>>>>>>>>>>>>")
//1 从redis里获取当前用户最近的k次评分,保存成Array[(mid, score)]
val userRecentlyRatings = getUserRecentlyRating( MAX_USER_RATINGS_NUM, uid, ConnHelper.jedis )
//2 从相似度矩阵中获取当前电影最相似的N个电影,作为备选列表,Array[mid]
// 根据uid过滤,将该用户评分过的电影过滤掉
// 在mongodb里面进行过滤
val candidateMovies = getTopSimMovies( MAX_SIM_MOVIES_NUM, mid, uid, simMovieMatrixBroadCast.value )
//3 最每个备选电影计算推荐优先级,得到当前用户的实时推荐列表,Array[(mid, score)]
val streamResc = computeMovieScore( candidateMovies, userRecentlyRatings, simMovieMatrixBroadCast.value )
//4 把推荐数据保存到mongodb
saveDataToMongoDB( uid, streamResc )
}
}
ssc.start()
println(">>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> streaming started")
ssc.awaitTermination()
}
// redis返回的是java类,需要引入转换类
import scala.collection.JavaConversions._
/**
* 从 redis 中选取 该用户最近 num次的 对某个电影的评分
* @param num 选取的最近评分记录的 数量
* @param uid 该用户的 ID
* @param jedis
* @return 该用户的最近num次 的评分记录
*/
def getUserRecentlyRating(num: Int, uid: Int, jedis: Jedis): Array[(Int, Double)] = {
//从redis读数据,用户评分数据保存在 uid:UID 为Key的队列里, value MID:SCORE
jedis.lrange("uid:" + uid, 0, num-1)
.map{
item =>
val attr = item.split("\\:")
( attr(0).trim.toInt, attr(1).trim.toDouble ) //uid , score
}
.toArray
}
/**
* 根据当前电影 从相似度矩阵 选取除了用户已看的电影 之外的 num个形似的电影列表
* @param num 要选取相似的电影数量
* @param mid 当前低钠盐的ID
* @param uid 当前评分的用户ID
* @param simMovies 相似度矩阵
* @param mongoConfig
* @return 过滤后的 备选电影的列表
*/
def getTopSimMovies(num: Int, mid: Int, uid: Int, simMovies: scala.collection.Map[Int, scala.collection.immutable.Map[Int, Double]])
(implicit mongoConfig: MongoConfig): Array[Int] = {
//从相似度矩阵中取出所有相似的电影
val allSimMovies: Array[(Int, Double)] = simMovies(mid).toArray
//从mongodb中查询用户已看过的电影, 用于过滤
val ratingExist = ConnHelper.mongoClient(mongoConfig.db)(MONGODB_RATING_COLLECTION)
.find( MongoDBObject("uid" -> uid) )
.toArray
.map{
item => item.get("mid").toString.toInt
}
//过于该用户看过的电影(用户如果评过分数 就代表用户看过该电影)
allSimMovies.filter( x => ! ratingExist.contains(x._1) )
.sortWith(_._2>_._2)
.take(num)
.map( x => x._1 )
}
def computeMovieScore(candidateMovies: Array[Int],
userRecentlyRatings: Array[(Int, Double)],
simMovies: scala.collection.Map[Int, scala.collection.immutable.Map[Int, Double]]): Array[(Int, Double)] = {
//定义一个ArrayBuffer.用户保存每一个备选电影的基础得分
val scores = scala.collection.mutable.ArrayBuffer[(Int, Double)]()
// 定义一个HashMap,保存每一个备选电影的增强减弱因子
val increMap = scala.collection.mutable.HashMap[Int, Int]()
val decreMap = scala.collection.mutable.HashMap[Int, Int]()
for( candidateMovie <- candidateMovies; userRecentlyRating <- userRecentlyRatings ){
//先拿到相似度(备选电影和 最近评分电影)
// 相当于从 相似度矩阵中 最近取 相应坐标 的值
// 可能 没有值 ,所以需要 设置默认值
val simScore = getMoviesSimScore( candidateMovie, userRecentlyRating._1, simMovies )
// 相似度矩阵 在 离线计算中 存储时,筛选条件为 > 0.6
// 这里进一步 筛选
if(simScore > 0.7){
//* 打分 => 备选电影的基础推荐得分
// ArrayBuffer += 运算符重载 第一个()为 +=()的函数() 第二个() 为 元组
scores += ( (candidateMovie, simScore * userRecentlyRating._2) )
// 统计 增强因子 和 减弱因子
if (userRecentlyRating._2 > 3) {
increMap(candidateMovie) = increMap.getOrDefault(candidateMovie, 0) + 1 //设置默认值
} else {
decreMap(candidateMovie) = decreMap.getOrDefault(candidateMovie, 0) + 1
}
}
}
// 除 总数
// 合并相同mid 的 groupby
scores.groupBy(_._1).map{
// groupBY => Map[Int, ArrayBuffer[(Int, Double)]
case (mid, scoreList) =>
( mid, scoreList.map(_._2).sum / scoreList.length + log(increMap.getOrDefault(mid, 1)) - log(decreMap.getOrDefault(mid, 1)) )
}.toArray
}
/**
* 获取两个电影之间的相似度
* @param mid1
* @param mid2
* @param simMovies
* @return
*/
def getMoviesSimScore(mid1: Int, mid2: Int, simMovies: scala.collection.Map[Int, scala.collection.immutable.Map[Int, Double]]): Double = {
// 用模式匹配判断是否为 空值
simMovies.get(mid1) match {
case Some(sims1) => sims1.get(mid2) match {
case Some(sims2) => sims2
case None => 0.0
}
case None => 0.0
}
}
/**
* 自定义 log 将 底数作为超参数
* 超参数N 默认为 10
*/
def log(x: Int):Double ={
val N = 10
// 对数换底公式
math.log(x) / math.log(N)
}
//覆盖 更新
def saveDataToMongoDB(uid: Int, streamRecs: Array[(Int, Double)])(implicit mongoConfig: MongoConfig): Unit ={
// 连接表
val streamRecsCollection = ConnHelper.mongoClient(mongoConfig.db)(MONGODB_STREAM_RECS_COLLECTION)
// 如果有 先删除
streamRecsCollection.findAndRemove( MongoDBObject("uid" -> uid) )
// 再更新
streamRecsCollection.insert(MongoDBObject("uid" -> uid,
"recs" -> streamRecs.map(x => MongoDBObject("mid" -> x._1, "score" -> x._2))))
}
}