from sklearn.decomposition import PCA
# ---------------------------------------------
# 最佳主成分数量
pca = PCA(n_components=None)
pca.fit_transform(x_train)
var_values = pca.explained_variance_ratio_
def select_best_components(var_, goal_var):
best_components, total_var = 0, 0.0 # 初始化
for var in var_:
total_var += var
best_components += 1
if total_var >= goal_var: # 达到目标方差,终止整个循环
break
return best_components
n = select_best_components(var_=var_values, goal_var=0.95)
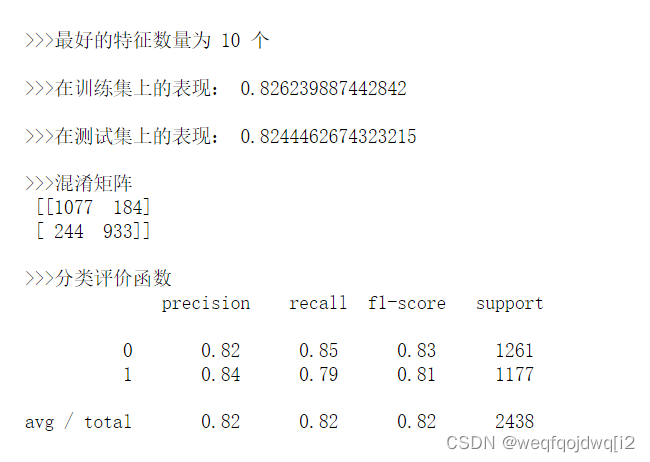
print('\n>>>最好的特征数量为 %d 个'% n)
# ---------------------------------------------
# 根据上面的最佳 n_components 数量,进行降维
pca = PCA(n_components=10)
x_train_pca = pca.fit_transform(x_train)
x_test_pca = pca.fit_transform(x_test)
# ---------