内核:5.9.0
流程图

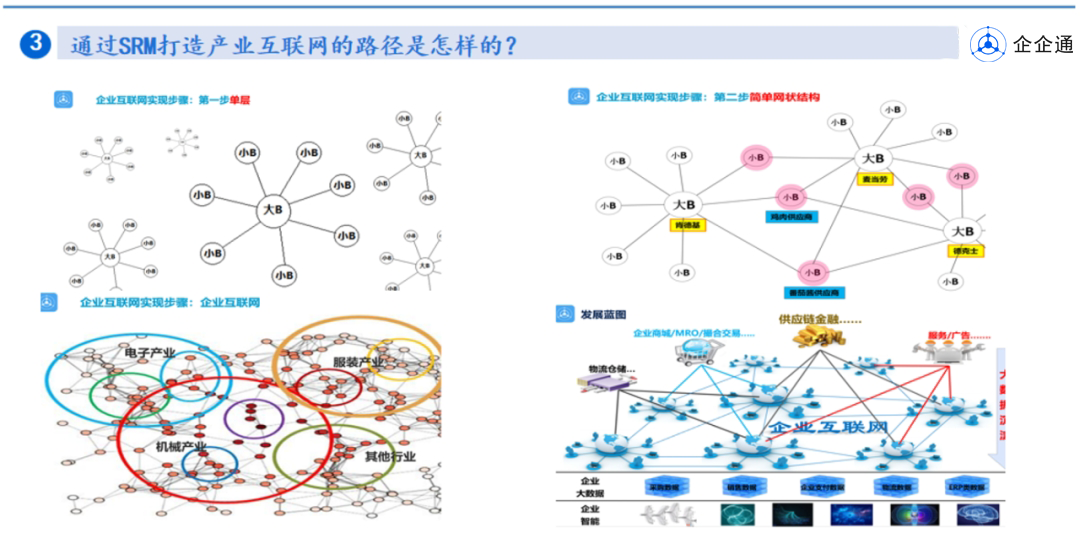
generic_file_buffered_read一种调用路径(cat某个文件触发):
#0 ondemand_readahead (mapping=0xffff888005c61340, ra=0xffff888005927598, filp=0xffff888005927500, hit_readahead_marker=false, index=0, req_size=16) at mm/readahead.c:445
#1 0xffffffff812eeea1 in page_cache_sync_readahead (req_count=<optimized out>, index=<optimized out>, filp=<optimized out>, ra=<optimized out>, mapping=<optimized out>) at mm/readahead.c:585
#2 page_cache_sync_readahead (mapping=<optimized out>, ra=0xffff888005927598, filp=0xffff888005927500, index=<optimized out>, req_count=16) at mm/readahead.c:567
#3 0xffffffff812dcae7 in generic_file_buffered_read (iocb=0xffffc90000033cc0, iter=<optimized out>, written=0) at mm/filemap.c:2199
#4 0xffffffff812dd8ed in generic_file_read_iter (iocb=0xffffc90000033cc0, iter=0xffffc90000033c98) at mm/filemap.c:2507
#5 0xffffffff814c7fc9 in ext4_file_read_iter (to=<optimized out>, iocb=<optimized out>) at fs/ext4/file.c:131
#6 ext4_file_read_iter (iocb=0xffffc90000033cc0, to=0xffffc90000033c98) at fs/ext4/file.c:114
#7 0xffffffff81405c0f in call_read_iter (file=<optimized out>, iter=<optimized out>, kio=<optimized out>) at ./include/linux/fs.h:1876
#8 generic_file_splice_read (in=0xffff888005927500, ppos=0xffffc90000033da8, pipe=<optimized out>, len=<optimized out>, flags=<optimized out>) at fs/splice.c:312
#9 0xffffffff81407b51 in do_splice_to (in=0xffff888005927500, ppos=0xffffc90000033da8, pipe=0xffff8880058fb6c0, len=65536, flags=<optimized out>) at fs/splice.c:890
#10 0xffffffff81407cab in splice_direct_to_actor (in=<optimized out>, sd=0xffffc90000033e00, actor=<optimized out>) at fs/splice.c:970
#11 0xffffffff81408012 in do_splice_direct (in=<optimized out>, ppos=0xffffc90000033ea8, out=0xffff888005927400, opos=0xffffc90000033eb0, len=16777216, flags=<optimized out>) at fs/splice.c:1079
#12 0xffffffff813ae9b1 in do_sendfile (out_fd=<optimized out>, in_fd=<optimized out>, ppos=0x0 <fixed_percpu_data>, count=<optimized out>, max=<optimized out>) at fs/read_write.c:1548
#13 0xffffffff813af30b in __do_sys_sendfile64 (count=<optimized out>, offset=<optimized out>, in_fd=<optimized out>, out_fd=<optimized out>) at fs/read_write.c:1609
#14 __se_sys_sendfile64 (count=<optimized out>, offset=<optimized out>, in_fd=<optimized out>, out_fd=<optimized out>) at fs/read_write.c:1595
generic_file_buffered_read核心逻辑:
- 尝试从page cache(address_space数据结构)中查找,如果命中返回。
- 如果未在page cache中,readpage从磁盘读取数据到page cache中。
- 按需(不是所有场景下才会预读)预读(readahead),提升IO性能。
/**
* generic_file_buffered_read - generic file read routine
* @iocb: the iocb to read
* @iter: data destination
* @written: already copied
*
* This is a generic file read routine, and uses the
* mapping->a_ops->readpage() function for the actual low-level stuff.
*
* 本段代码自己注释说逻辑实现的真的“丑陋”....
* This is really ugly. But the goto's actually try to clarify some
* of the logic when it comes to error handling etc.
*
* Return:
* * total number of bytes copied, including those the were already @written
* * negative error code if nothing was copied
*/
ssize_t generic_file_buffered_read(struct kiocb *iocb,
struct iov_iter *iter, ssize_t written)
{
struct file *filp = iocb->ki_filp;
struct address_space *mapping = filp->f_mapping;
struct inode *inode = mapping->host;
//预读的数据结构,预读后面会有专门的文章分析
struct file_ra_state *ra = &filp->f_ra;
//文件读取位置,即在文件内偏移量,字节为单位
loff_t *ppos = &iocb->ki_pos;
pgoff_t index;
pgoff_t last_index;
pgoff_t prev_index;
unsigned long offset; /* offset into pagecache page */
unsigned int prev_offset;
int error = 0;
if (unlikely(*ppos >= inode->i_sb->s_maxbytes))
return 0;
iov_iter_truncate(iter, inode->i_sb->s_maxbytes);
//把文档按4K分成数据页,index代表是数据页索引
//|----index 0----|----index 1----|----index 2----|
// 4K 4K 4K
index = *ppos >> PAGE_SHIFT;
//上次预读的位置
prev_index = ra->prev_pos >> PAGE_SHIFT;
prev_offset = ra->prev_pos & (PAGE_SIZE-1);
//iter->count 要读取得字节数,last_index是要读取得最后一个index
last_index = (*ppos + iter->count + PAGE_SIZE-1) >> PAGE_SHIFT;
offset = *ppos & ~PAGE_MASK;
//循环读取iter->count bytes数据(即应用程序要求读取的数据)
for (;;) {
struct page *page;
pgoff_t end_index;
loff_t isize;
unsigned long nr, ret;
cond_resched();
find_page:
if (fatal_signal_pending(current)) {
error = -EINTR;
goto out;
}
//mapping指向的address_space缓存中,根据index查找是否已经有缓存数据
page = find_get_page(mapping, index);
if (!page) {
//如果执行了不进行时机的磁盘io操作(必须在cache中)返回错误
if (iocb->ki_flags & IOCB_NOIO)
goto would_block;
//"同步预读",注意,这里同步并非真的同步等待,本质上也是向block layer
//提交一个io请求就返回了
page_cache_sync_readahead(mapping,
ra, filp,
index, last_index - index);
page = find_get_page(mapping, index);
//如果没有成功(因为sync_readahead给page申请内存时,不会进入慢路径,所以
//有可能失败。失败后goto no_cache_page:分配page页面,并readpage进行磁盘io操作
if (unlikely(page == NULL))
goto no_cached_page;
}
//走到这里,代表readahead成功,也就是当前想读取的页面,已经被预读了
//理解这句话要看readahead机制和数据结构,PageReadahead page是怎么设置的
if (PageReadahead(page)) {
if (iocb->ki_flags & IOCB_NOIO) {
put_page(page);
goto out;
}
//触发一次异步read_ahead,因为异步读成功命中,重新取预读更多的页面,也会
//更新ra数据结构
page_cache_async_readahead(mapping,
ra, filp, page,
index, last_index - index);
}
//如果页面数据无效,比如系统I/O非常繁忙,上面异步读没有完成,这里就需要等待了
if (!PageUptodate(page)) {
/*
* See comment in do_read_cache_page on why
* wait_on_page_locked is used to avoid unnecessarily
* serialisations and why it's safe.
*/
//IOCB_WAITQ代表异步io,比如io_uring
if (iocb->ki_flags & IOCB_WAITQ) {
if (written) {
put_page(page);
goto out;
}
error = wait_on_page_locked_async(page,
iocb->ki_waitq);
} else {
//指定不等待,就返回错误
if (iocb->ki_flags & IOCB_NOWAIT) {
put_page(page);
goto would_block;
}
//block等待IO完成,systrace上显示进程block i/o就是等在此处。
error = wait_on_page_locked_killable(page);
}
if (unlikely(error))
goto readpage_error;
//上面的等待成功了
if (PageUptodate(page))
goto page_ok;
if (inode->i_blkbits == PAGE_SHIFT ||
!mapping->a_ops->is_partially_uptodate)
goto page_not_up_to_date;
/* pipes can't handle partially uptodate pages */
if (unlikely(iov_iter_is_pipe(iter)))
goto page_not_up_to_date;
if (!trylock_page(page))
goto page_not_up_to_date;
/* Did it get truncated before we got the lock? */
if (!page->mapping)
goto page_not_up_to_date_locked;
if (!mapping->a_ops->is_partially_uptodate(page,
offset, iter->count))
goto page_not_up_to_date_locked;
unlock_page(page);
}
page_ok:
/*
* i_size must be checked after we know the page is Uptodate.
*
* Checking i_size after the check allows us to calculate
* the correct value for "nr", which means the zero-filled
* part of the page is not copied back to userspace (unless
* another truncate extends the file - this is desired though).
*/
isize = i_size_read(inode);
end_index = (isize - 1) >> PAGE_SHIFT;
if (unlikely(!isize || index > end_index)) {
put_page(page);
goto out;
}
/* nr is the maximum number of bytes to copy from this page */
nr = PAGE_SIZE;
if (index == end_index) {
nr = ((isize - 1) & ~PAGE_MASK) + 1;
if (nr <= offset) {
put_page(page);
goto out;
}
}
nr = nr - offset;
/* If users can be writing to this page using arbitrary
* virtual addresses, take care about potential aliasing
* before reading the page on the kernel side.
*/
if (mapping_writably_mapped(mapping))
flush_dcache_page(page);
/*
* When a sequential read accesses a page several times,
* only mark it as accessed the first time.
*/
if (prev_index != index || offset != prev_offset)
mark_page_accessed(page);
prev_index = index;
/*
* Ok, we have the page, and it's up-to-date, so
* now we can copy it to user space...
*/
//数据copy给用户空间,iter->count会减去copy的数据大小
ret = copy_page_to_iter(page, offset, nr, iter);
offset += ret;
index += offset >> PAGE_SHIFT;
offset &= ~PAGE_MASK;
prev_offset = offset;
put_page(page);
written += ret;
//如果iter->count = 0,即已经完成数据读取goto out跳出循环。
if (!iov_iter_count(iter))
goto out;
if (ret < nr) {
error = -EFAULT;
goto out;
}
continue;
page_not_up_to_date:
/* Get exclusive access to the page ... */
if (iocb->ki_flags & IOCB_WAITQ)
error = lock_page_async(page, iocb->ki_waitq);
else
error = lock_page_killable(page);
if (unlikely(error))
goto readpage_error;
page_not_up_to_date_locked:
/* Did it get truncated before we got the lock? */
if (!page->mapping) {
unlock_page(page);
put_page(page);
continue;
}
/* Did somebody else fill it already? */
if (PageUptodate(page)) {
unlock_page(page);
goto page_ok;
}
readpage:
//low-level page read,即调用readpage触发磁盘i/o
if (iocb->ki_flags & (IOCB_NOIO | IOCB_NOWAIT)) {
unlock_page(page);
put_page(page);
goto would_block;
}
/*
* A previous I/O error may have been due to temporary
* failures, eg. multipath errors.
* PG_error will be set again if readpage fails.
*/
ClearPageError(page);
/* Start the actual read. The read will unlock the page. */
error = mapping->a_ops->readpage(filp, page);
if (unlikely(error)) {
if (error == AOP_TRUNCATED_PAGE) {
put_page(page);
error = 0;
goto find_page;
}
goto readpage_error;
}
if (!PageUptodate(page)) {
if (iocb->ki_flags & IOCB_WAITQ)
error = lock_page_async(page, iocb->ki_waitq);
else
error = lock_page_killable(page);
if (unlikely(error))
goto readpage_error;
if (!PageUptodate(page)) {
if (page->mapping == NULL) {
/*
* invalidate_mapping_pages got it
*/
unlock_page(page);
put_page(page);
goto find_page;
}
unlock_page(page);
shrink_readahead_size_eio(ra);
error = -EIO;
goto readpage_error;
}
unlock_page(page);
}
goto page_ok;
readpage_error:
/* UHHUH! A synchronous read error occurred. Report it */
put_page(page);
goto out;
no_cached_page:
//address space没有缓存页面,alloc page,然后插入cache中。
/*
* Ok, it wasn't cached, so we need to create a new
* page..
*/
page = page_cache_alloc(mapping);
if (!page) {
error = -ENOMEM;
goto out;
}
error = add_to_page_cache_lru(page, mapping, index,
mapping_gfp_constraint(mapping, GFP_KERNEL));
if (error) {
put_page(page);
if (error == -EEXIST) {
error = 0;
goto find_page;
}
goto out;
}
goto readpage;
}
would_block:
error = -EAGAIN;
out:
ra->prev_pos = prev_index;
ra->prev_pos <<= PAGE_SHIFT;
ra->prev_pos |= prev_offset;
*ppos = ((loff_t)index << PAGE_SHIFT) + offset;
file_accessed(filp);
return written ? written : error;
}重点提示:代码中为什么先触发一次sync_readahead,再触发一次async_readahead?
- 如果代码注释的一样,这两个函数命令很容易误解,其实这两个从应用调用的角度来看,都是”异步"的,以为他们都只是向block layer submit io,所以是异步,从代码上下文也能推测出来,比如sync_readahead调用完之后,紧接调用了find_get_page还是判断了page == NULL的情况,从这点就充分看出来sync_readahead也是异步调用。
- 如果系统io情况正常,100%顺序读取的情况下,sync_readahead调用一次,触发了预读,后面再顺序读就不会触发sync_readhead了,而是触发async_readahead,async_readahead触发的条件是要读取的page满足PageReadahead(page),即预读页面被命中了。就像网络协议栈中的滑动窗口,既然请求已经来到预读的窗口中,那么就要重新触发新的预读,预读更多的页面。
具体上面这段话不理解的话,参考我后面readahead算法介绍的文章。
参考文章:
Linux 通用块层 bio 详解 – 字节岛技术分享
Life of an ext4 write request - Ext4
深入分析Linux内核File cache机制(上篇) - 知乎
Linux内核中跟踪文件PageCache预读_读取