文章目录
- 一、介绍KNN
- 1.1 定义
- 1.2 工作流程
- 二、自实现KNN
- 2.1 问题
- 2.2 步骤
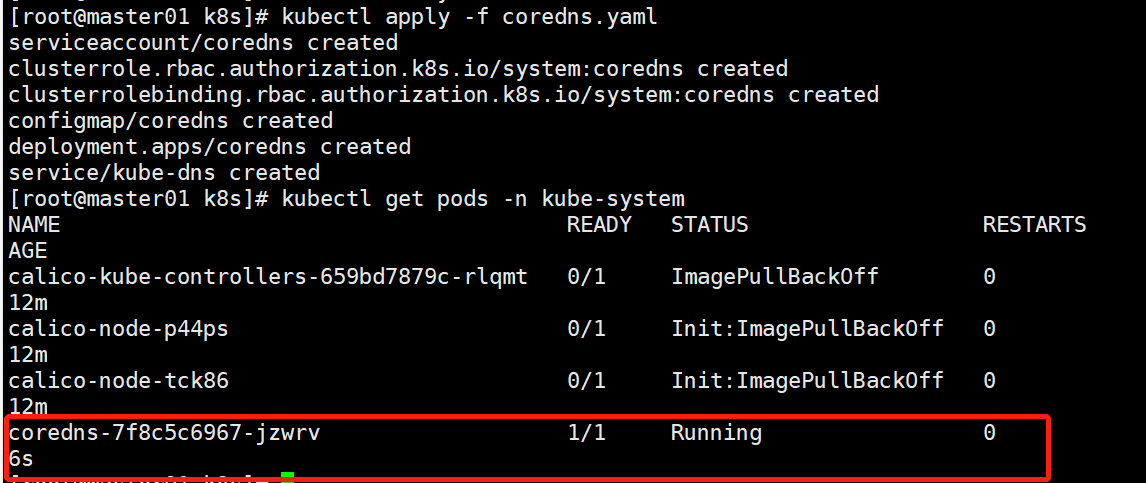
一、介绍KNN
1.1 定义
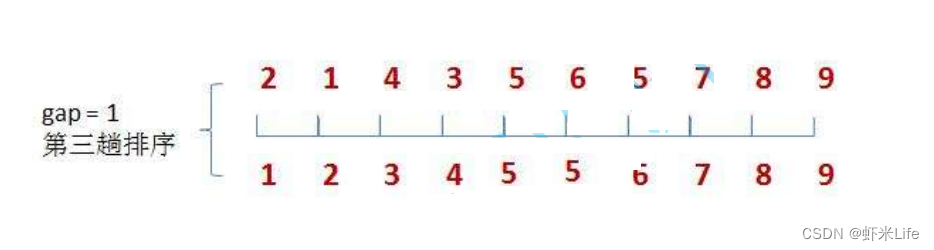
如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
涉及到距离的计算(欧式距离)
1.2 工作流程
- 计算待分类物体与其他物体之间的距离;
- 统计距离最近的 K 个邻居;
- 对于 K 个最近的邻居,它们属于哪个分类最多,待分类物体就属于哪一类。
二、自实现KNN
2.1 问题
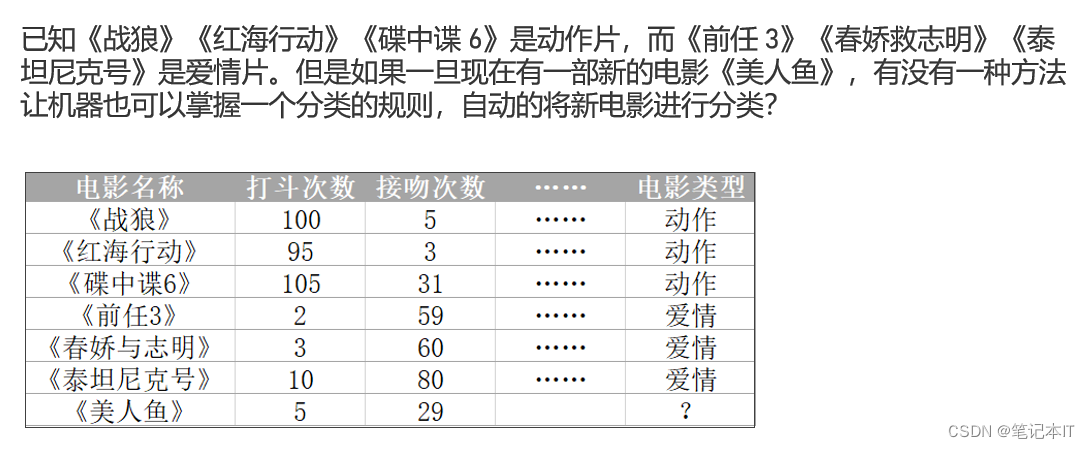
2.2 步骤
- 准备数据
- 训练集数据 即 特征数据 + 目标数据
- 预测数据 即 特征数据
- 计算 预测数据 与 训练数据的欧氏距离
- 获取到 k个 欧氏距离最小的值
- 将获取到的k个近邻进行分类统计,谁是大头,预测值就属于哪个分类
代码运行环境是 jupyter notebook
KNN主要代码如下:
class MyKnn(object):
def __init__(self,train_df,k):
self.train_df = train_df
self.k = k
def predict(self,test_df):
# 首先,计算test数据与train数据的欧式距离
self.train_df["距离"] = np.sqrt((test_df["打斗次数"]-self.train_df["打斗次数"])**2+(test_df["接吻次数"]-self.train_df["接吻次数"])**2)
# print(self.train_df)
# 其次,得出k个最小距离
# loc 根据行索引; 排序后会被打乱
# iloc 根据下标
# 注意:loc 与 iloc 切片用法不一样
mv_types = self.train_df.sort_values(by="距离").iloc[:self.k]["电影类型"]
# print(mv_types)
# 最后,分类 并 选择占大多数的类别
# value_counts()方法:统计 并 降序
new_mv_types = mv_types.value_counts().index[0]
# print(new_mv_types)
return new_mv_types
完整代码可以在页面最上方下载