今天来讲MySQL数据库的表增删查改操作。今天主要是通过栗子来演示语法使用的,话不多说,直奔主题~
表的增删查改:
CRUD : Create(创建), Retrieve(读取),Update(更新),Delete(删除)
目录
Create
单行数据 + 全列插入
多行数据 + 指定列插入
插入否则更新
替换
编辑Retrieve
select列
全列查询
指定列查询
查询字段为表达式
结果去重
where条件
>, >=, <, <=
=, <=>
BETWEEN a0 AND a1
IN (option, ...)
LIKE
语文成绩好于英语成绩的同学
总分在 200 分以下的同学
语文成绩 > 80 并且不姓孙的同学
孙某同学,否则要求总成绩 > 200 并且 语文成绩 < 数学成绩 并且 英语成绩 > 80
NULL的查询
结果排序
同学及 qq 号,按 qq 号排序显示
查询同学各门成绩,依次按 数学降序,英语升序,语文升序的方式显示
查询同学及总分,由高到低
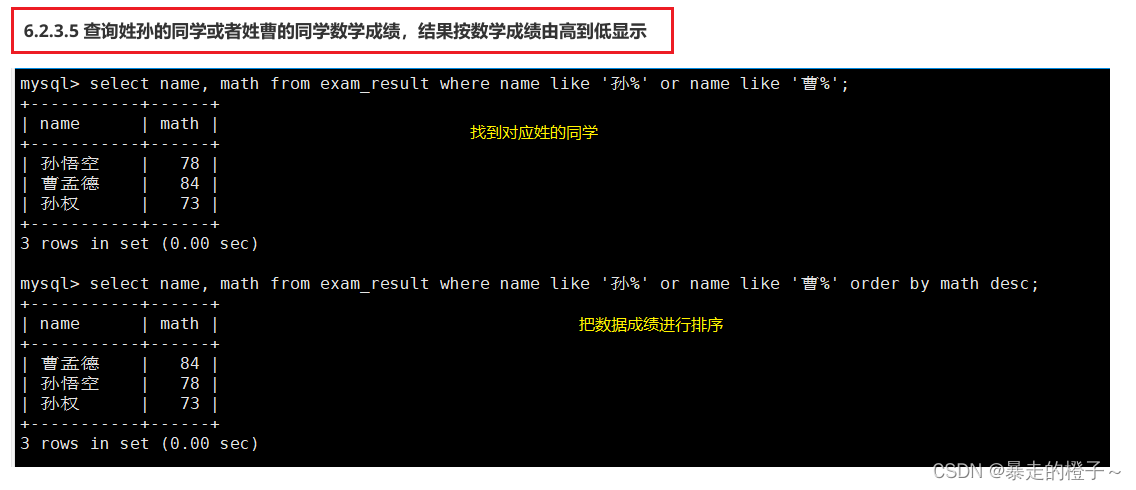
查询姓孙的同学或者姓曹的同学数学成绩,结果按数学成绩由高到低显示
筛选分页结果
limit n
limit s,n
limit n offset s
Update
将孙悟空同学的数学成绩变更为 80 分
将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分
将总成绩倒数前三的 3 位同学的数学成绩加上 30 分
将所有同学的语文成绩更新为原来的 2 倍
Delete
删除数据
删除孙悟空同学的考试成绩
删除整张表数据
截断表
delete from 和 truncate [table]
插入查询结果
案例:删除表中的的重复复记录,重复的数据只能有一份
聚合函数
统计班级共有多少同学
统计班级收集的 qq 号有多少
统计本次考试的数学成绩分数个数
统计数学成绩总分
统计平均总分
返回英语最高分
统计平均总分
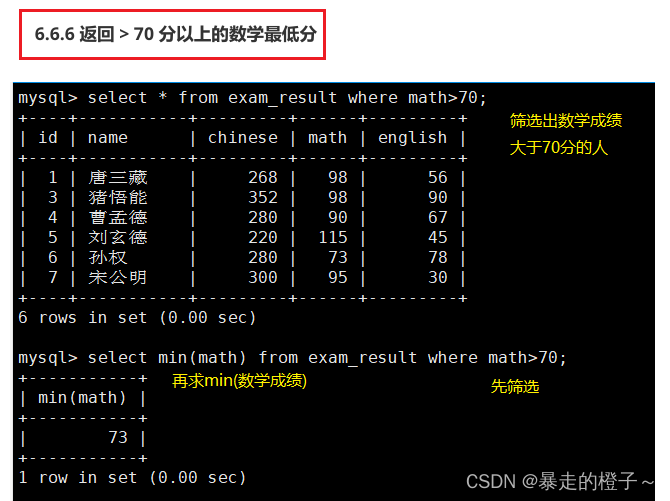
返回 > 70 分以上的数学最低分
group by子句的使用
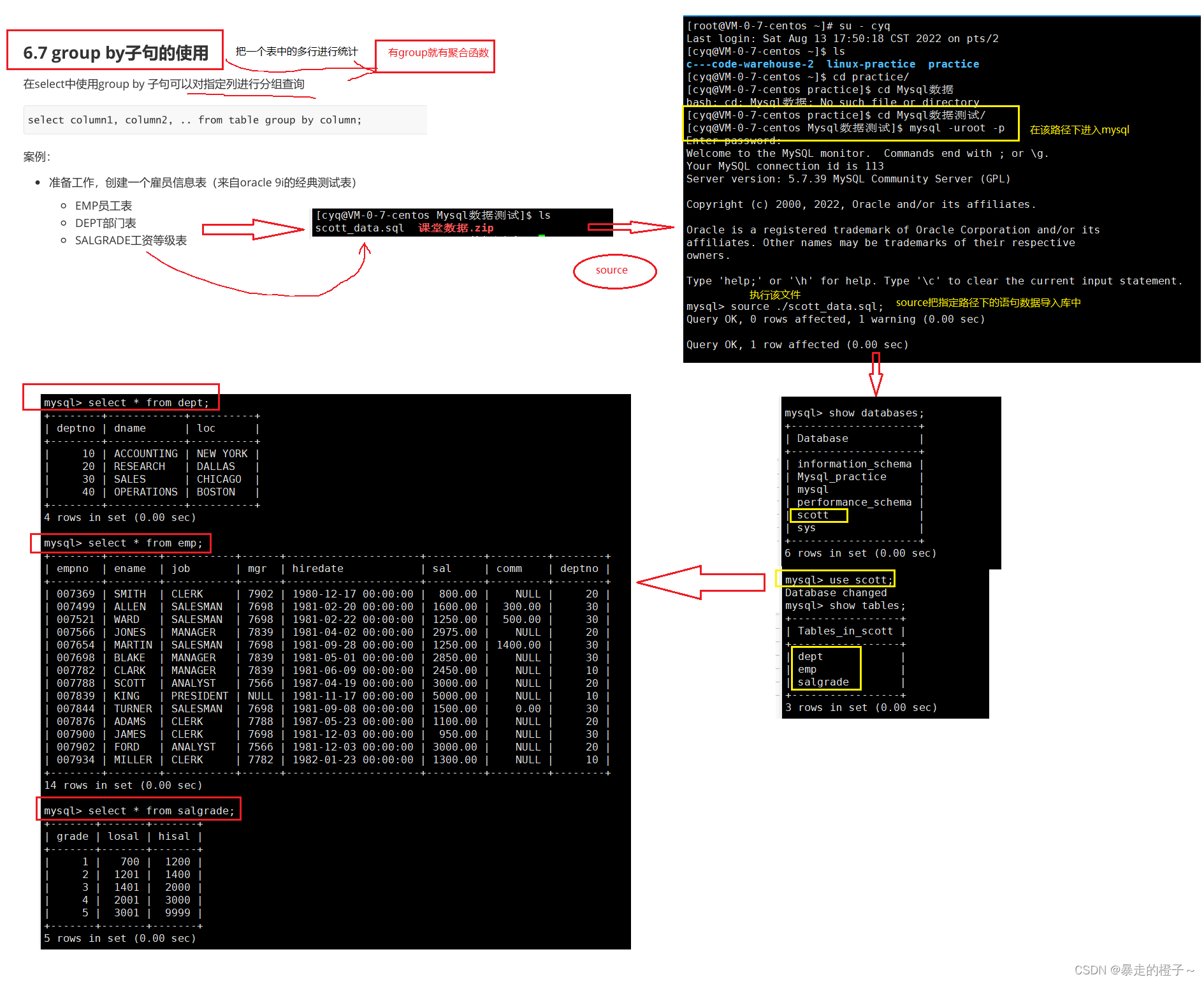
测试数据导入
如何显示每个部门的平均工资和最高工资
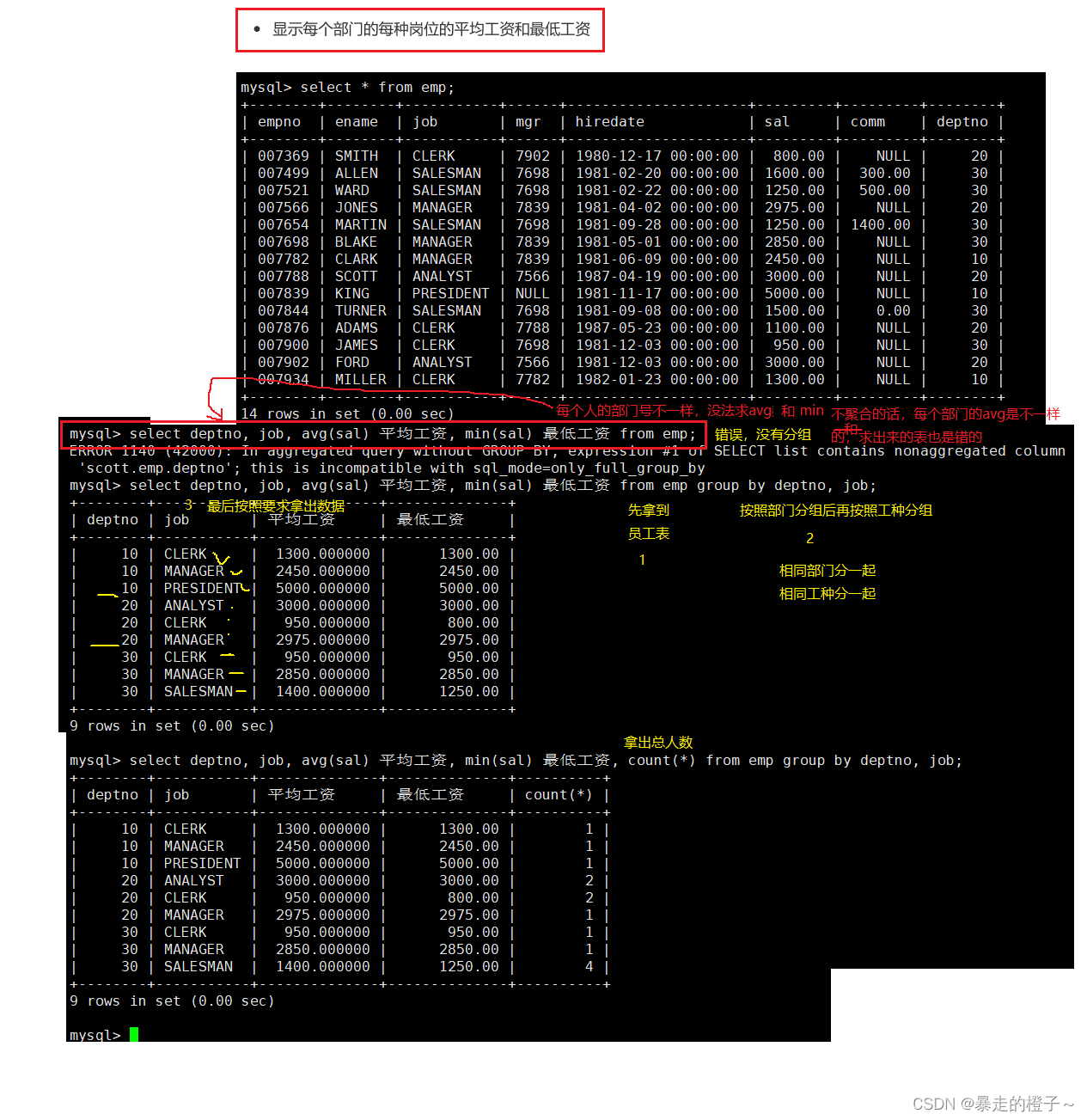
显示每个部门的每种岗位的平均工资和最低工资
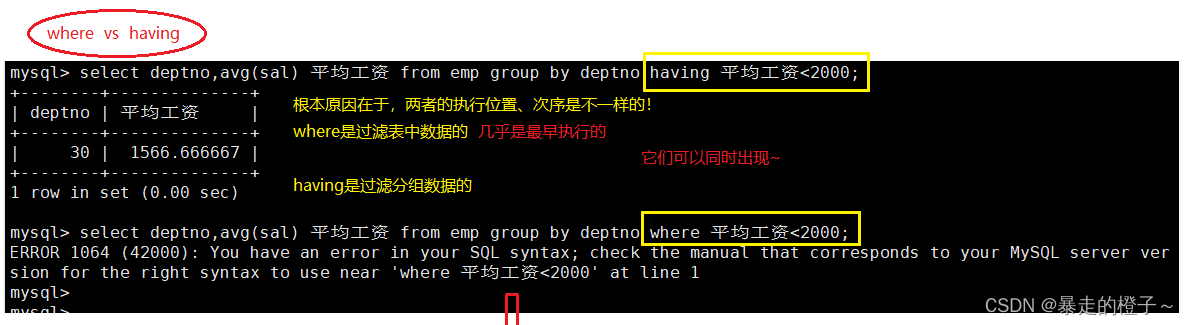
显示平均工资低于2000的部门和它的平均工资
where 和having比较
Create
语法
insert [into] table_name[(column [, column] ...)] values (value_list) [, (value_list)] ...
创建案例:
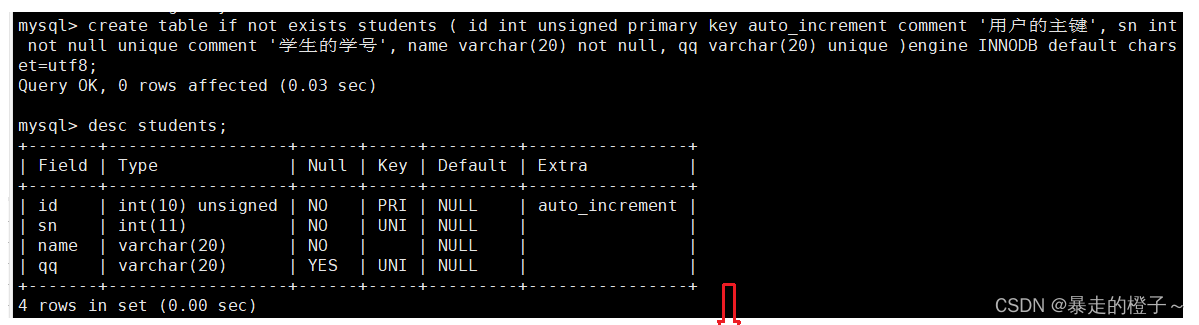
单行数据 + 全列插入
举个栗子:
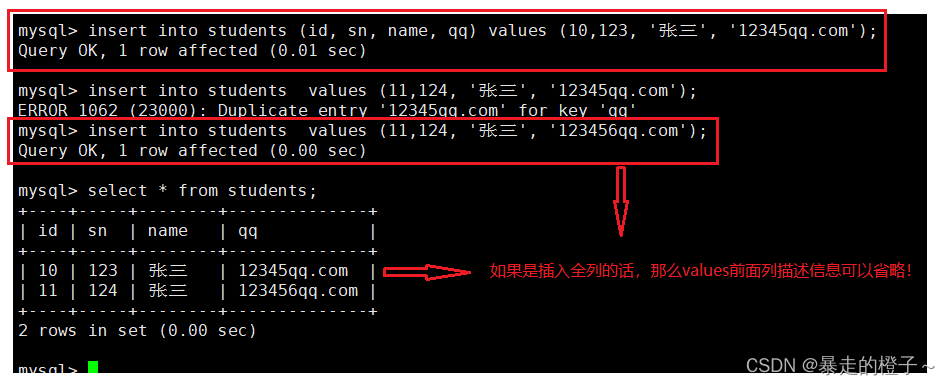
多行数据 + 指定列插入
举个栗子:
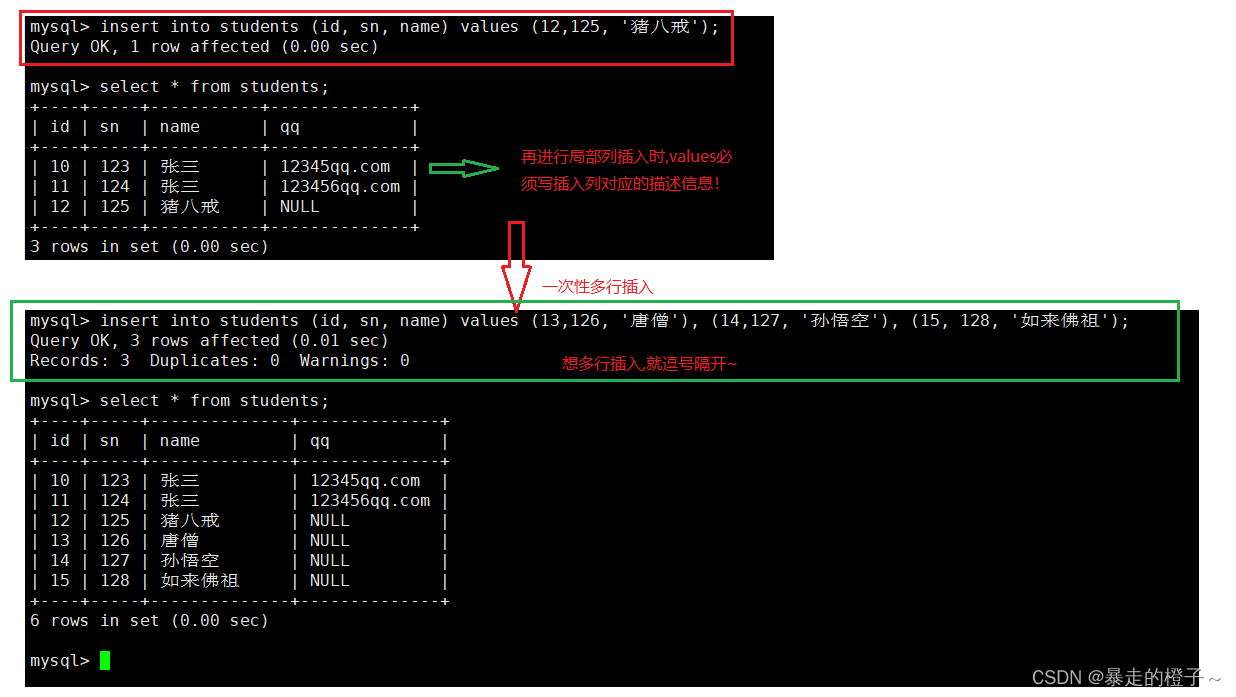
插入否则更新
由于 主键 或者 唯一键 对应的值已经存在而导致插入失败
选择同步性更新语法:
insert ... on duplicate key update column = value [, column = value] ...
举个栗子:
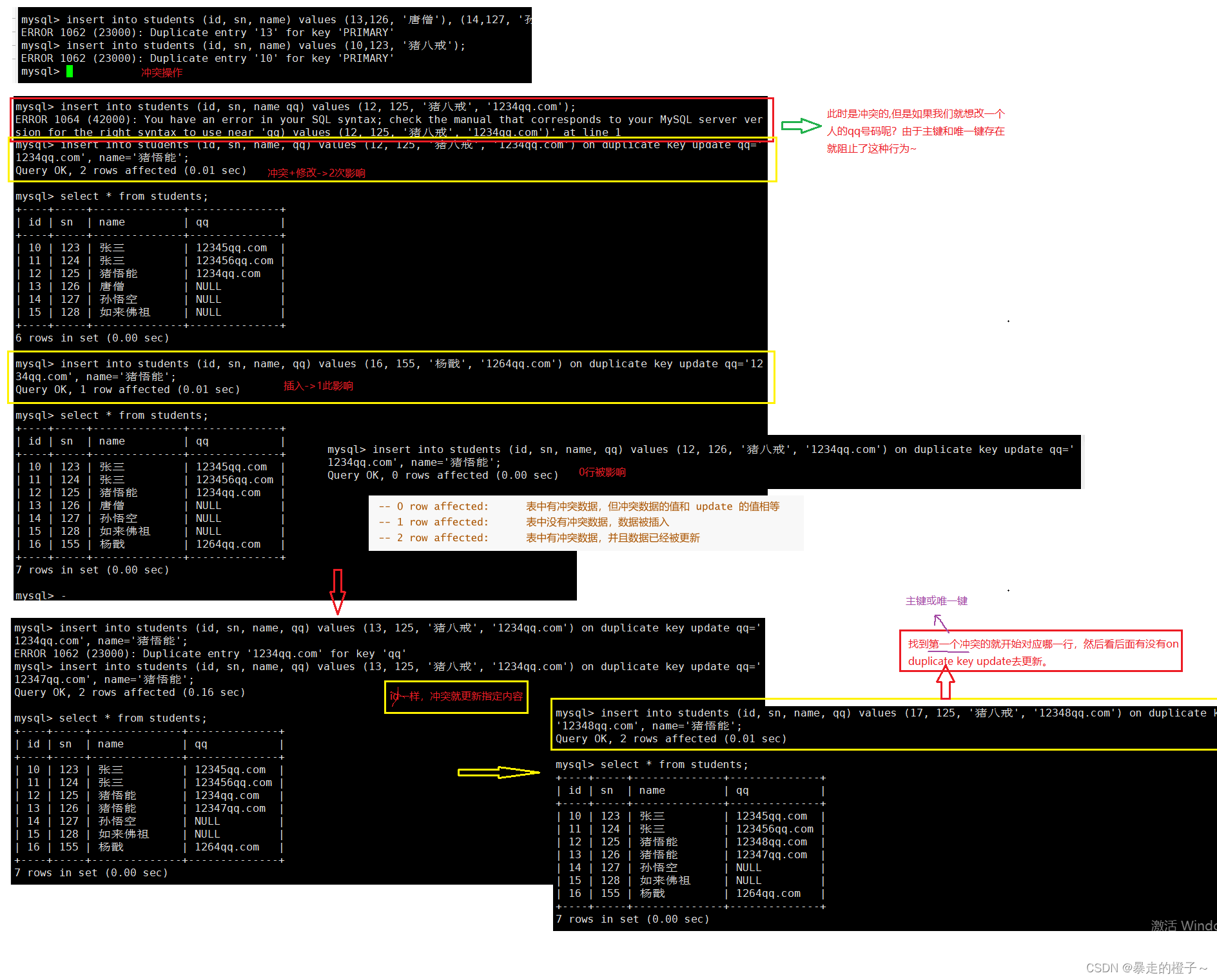
我们插入数据时有主键或者唯一键冲突了,我们使用on duplicate key update后,哪一个键先冲突,就更新那一行的数据内容,按照update后的内容进行更新。
替换
-- 主键 或者 唯一键 没有冲突,则直接插入;
-- 主键 或者 唯一键 如果冲突,则删除后再插入REPLACE INTO students (sn, name) VALUES (20001, '曹阿瞒');
Query OK, 2 rows affected (0.00 sec)
-- 1 row affected: 表中没有冲突数据,数据被插入
-- 2 row affected: 表中有冲突数据,删除后重新插入
举个栗子:
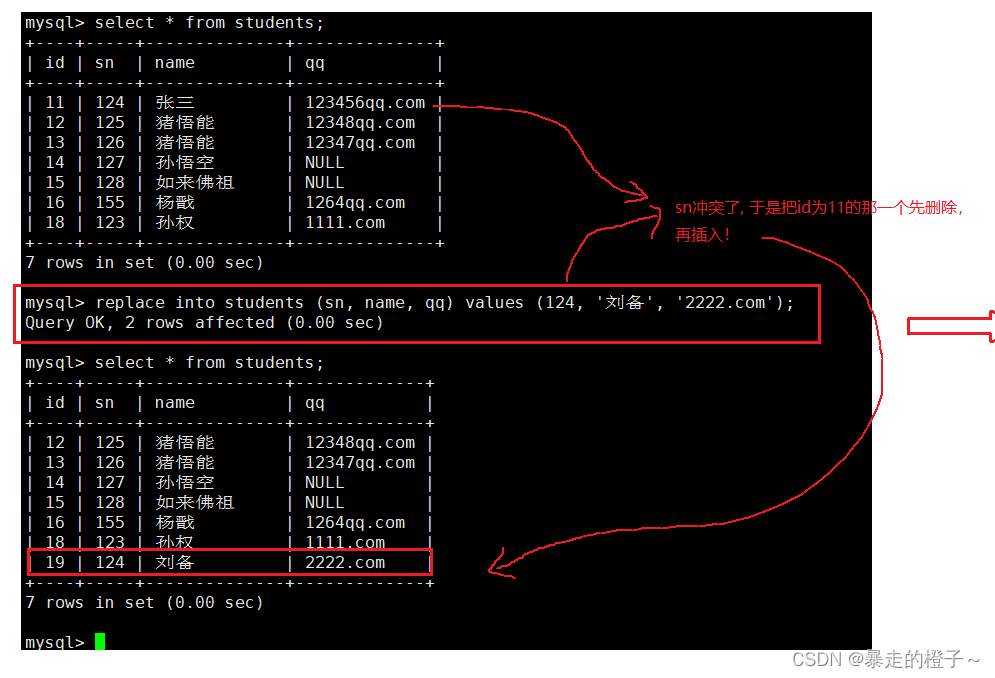
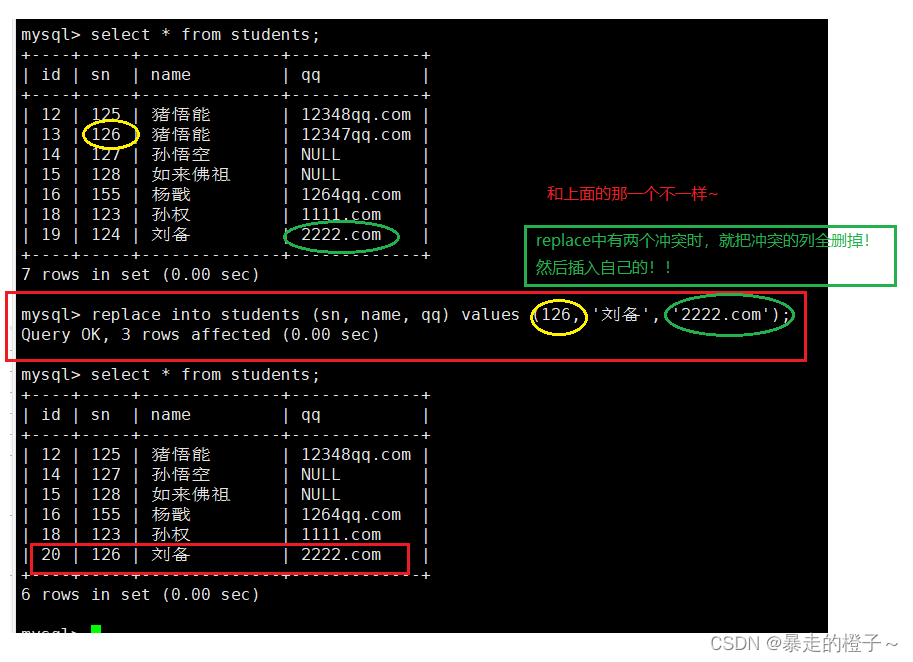
多个列数据冲突时:
 Retrieve
Retrieve
准备工作,创建表结构:
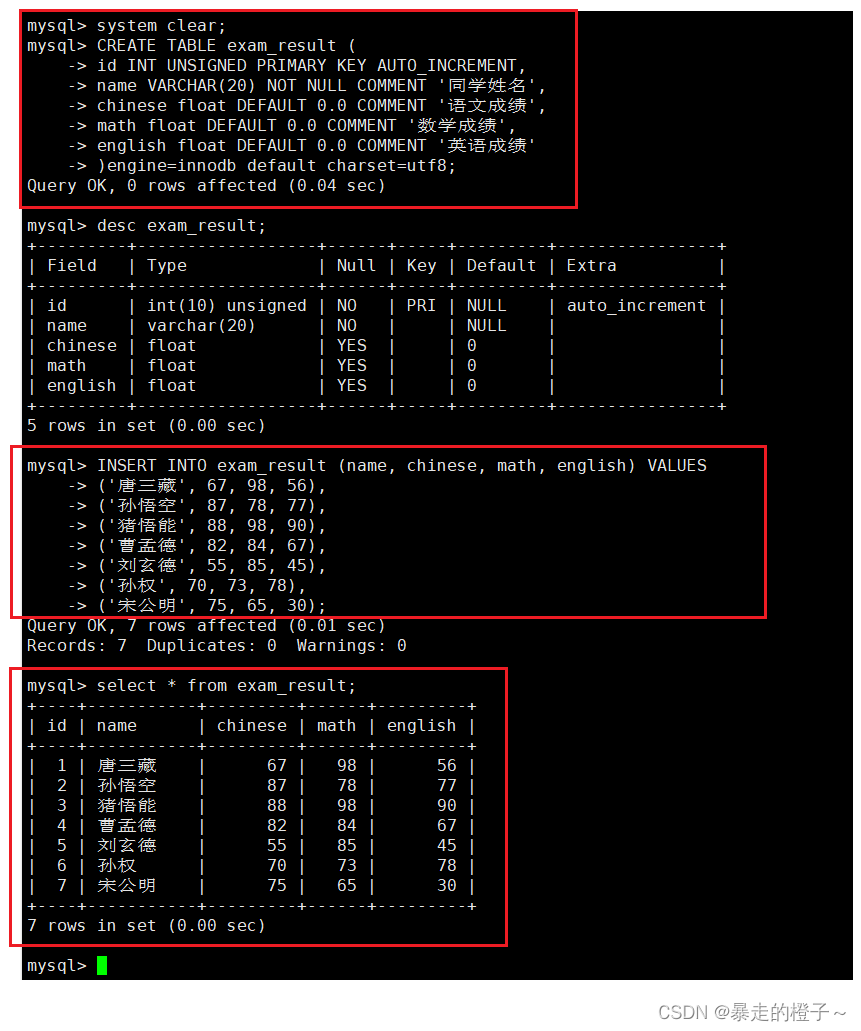
select列
全列查询
-- 通常情况下不建议使用 * 进行全列查询
-- 1. 查询的列越多,意味着需要传输的数据量越大,会导致数据大量刷屏,效率降低;
-- 2. 可能会影响到索引的使用。
指定列查询

查询字段为表达式
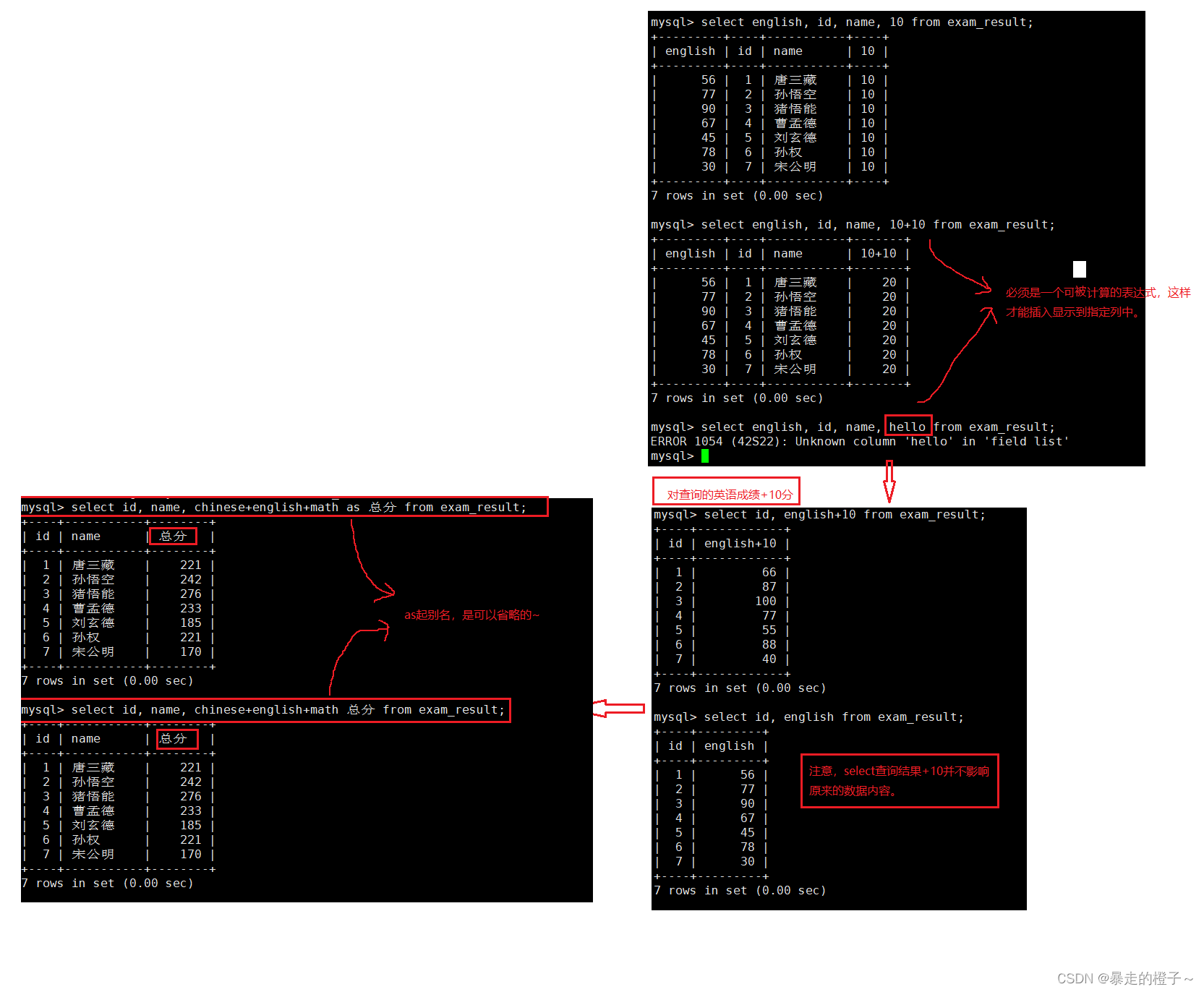
结果去重
举个栗子:
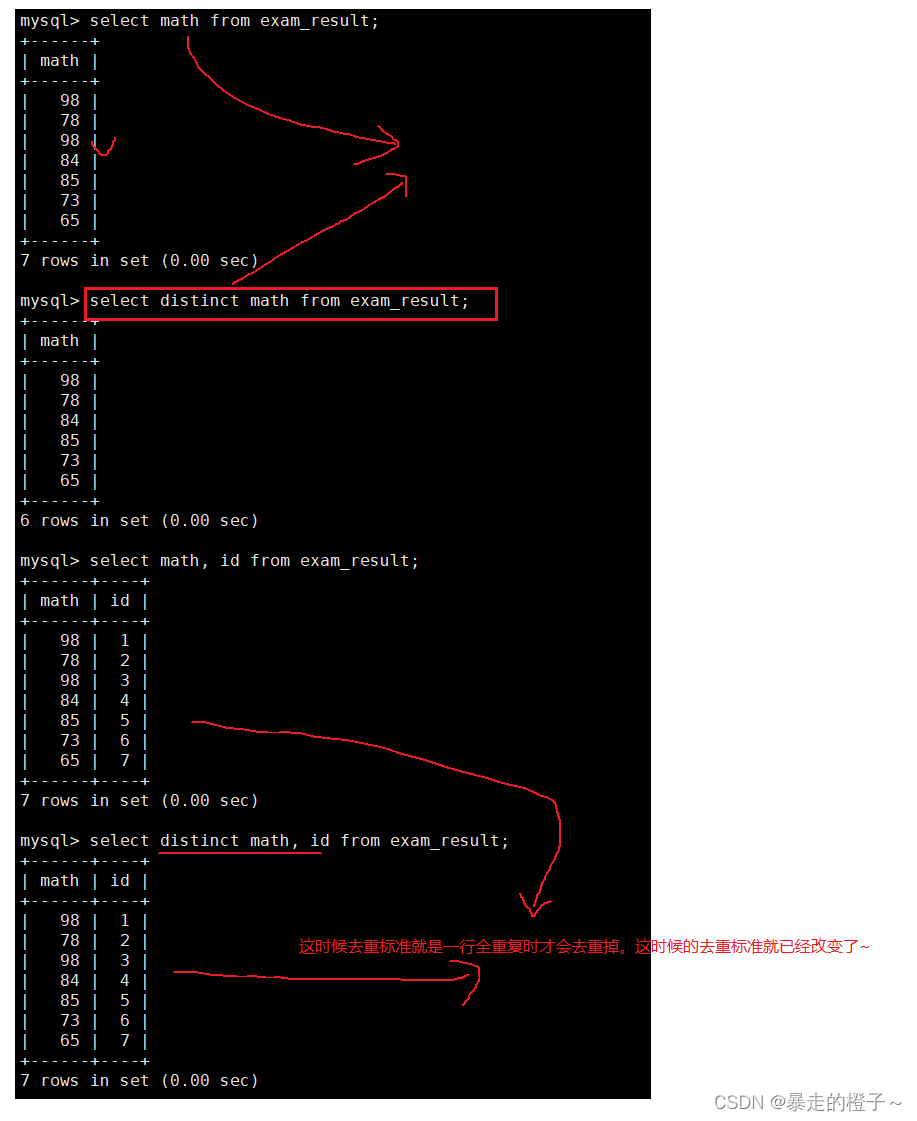
注意distinct后面跟一个列名和多个列名的情况。
where条件
关于比较运算符如下,我们下面通过场景来学习。
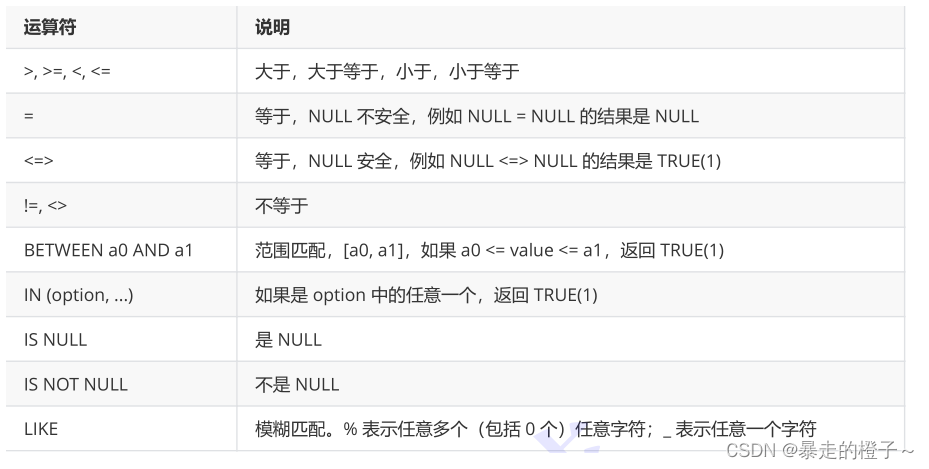
>, >=, <, <=
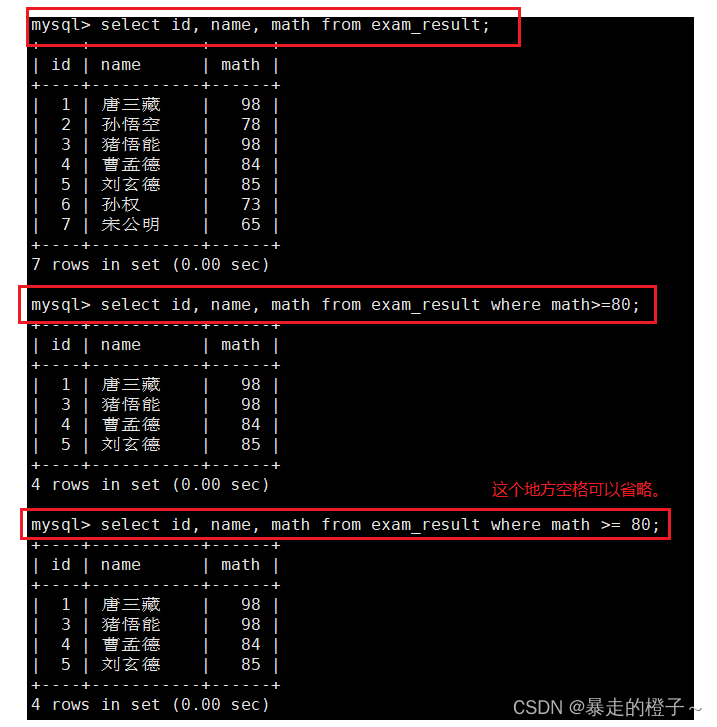
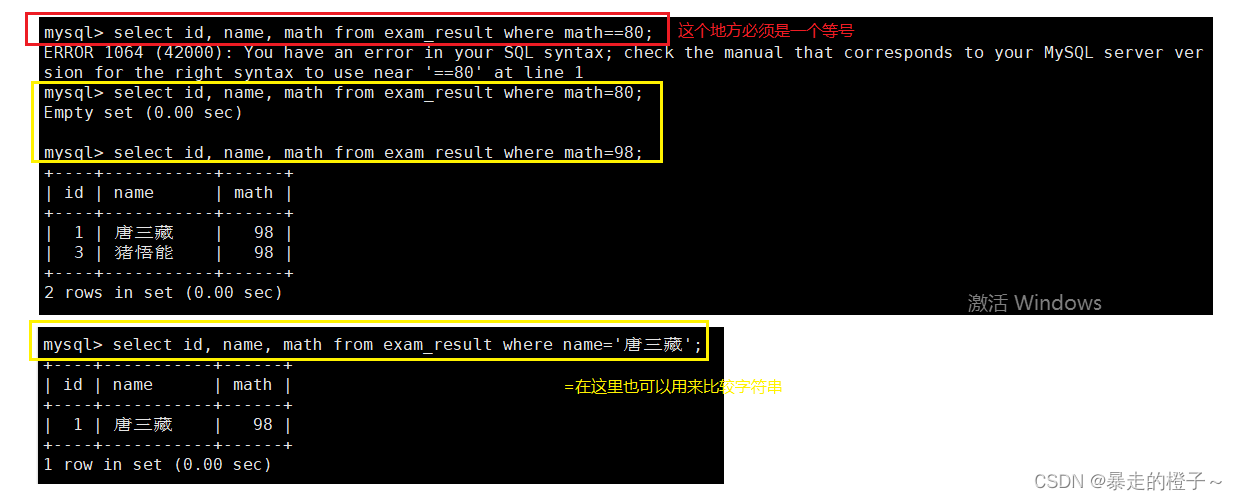
注意,MySQL中比较等于时,是用=来比较的,和语言中的等号是不同的。
=, <=>
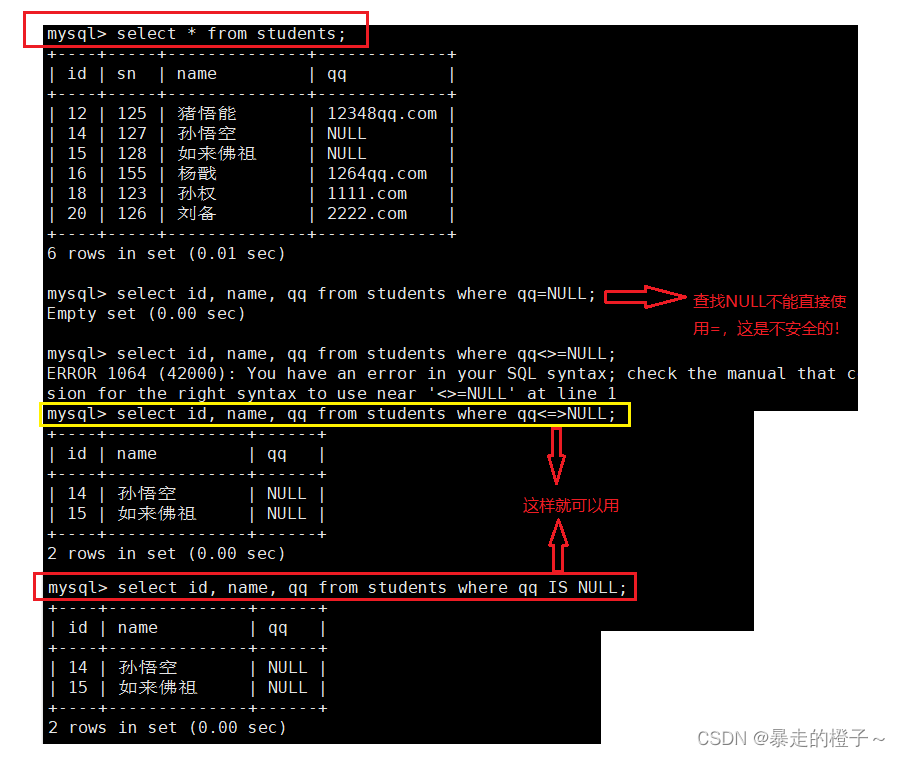
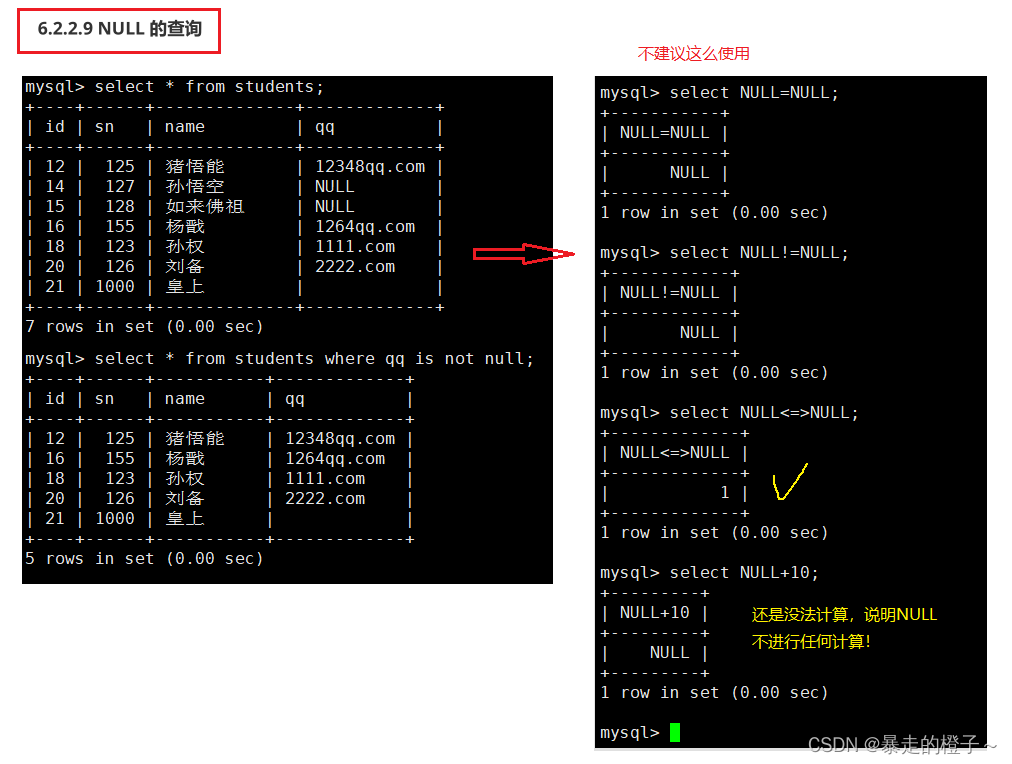
那判断不为NULL呢?

在这里判断是否为NULL虽说不止一种写法,但是我们只要使用is noll 和is not null来判断就好了,这样降低自己的学习成本,还看起来比较主观。
BETWEEN a0 AND a1
逻辑运算符:


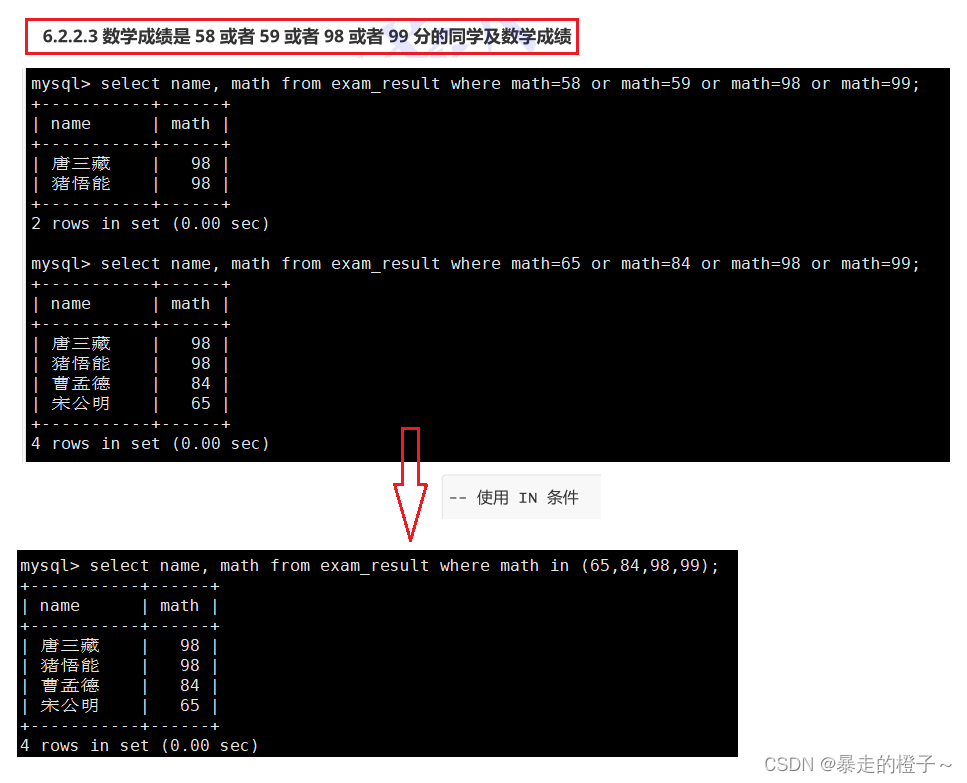
IN (option, ...)
LIKE

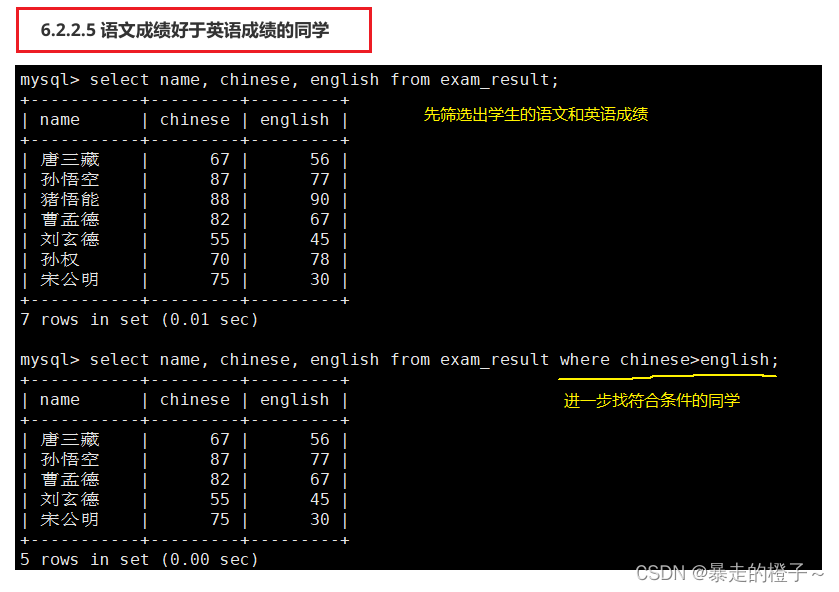
语文成绩好于英语成绩的同学
总分在 200 分以下的同学
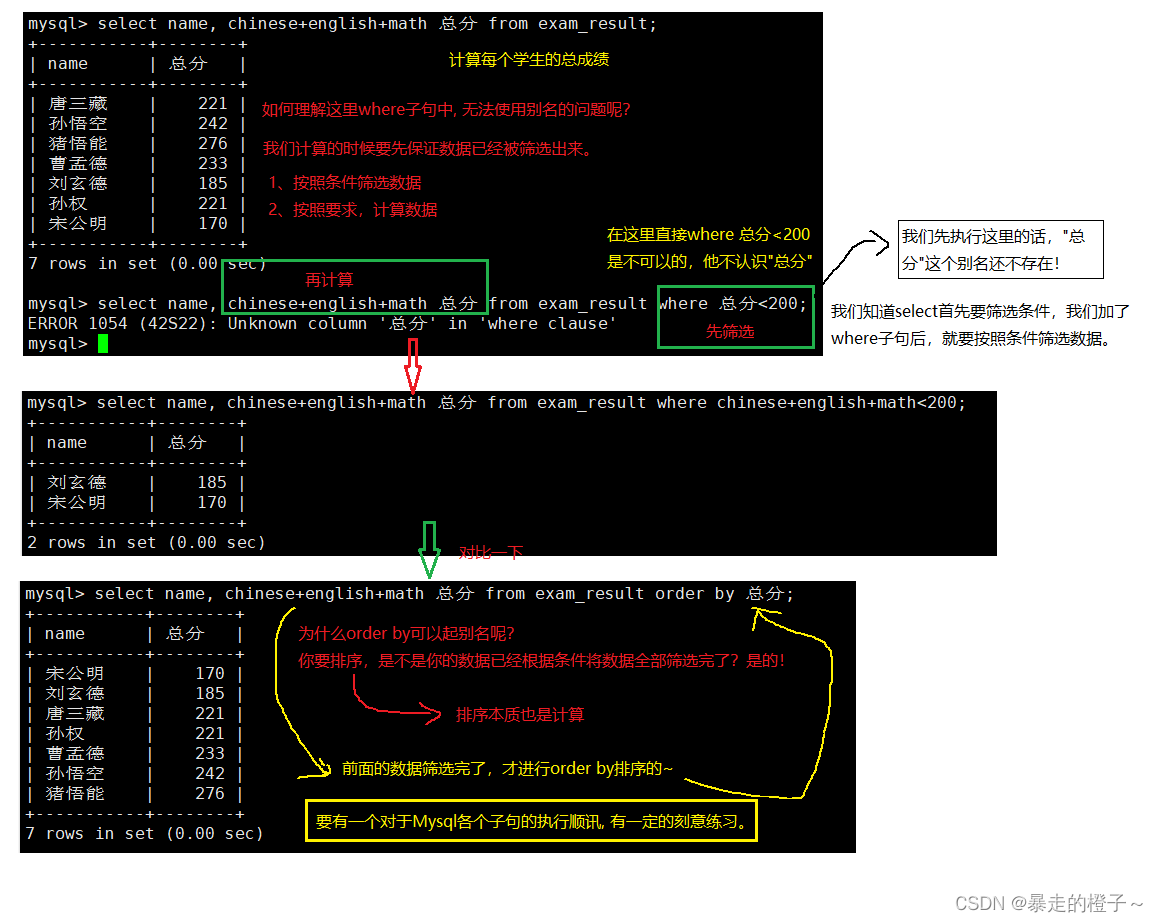
我们要注意where和order by语句的执行顺序。
where语句中不能取别名

语文成绩 > 80 并且不姓孙的同学

孙某同学,否则要求总成绩 > 200 并且 语文成绩 < 数学成绩 并且 英语成绩 > 80

NULL的查询
结果排序

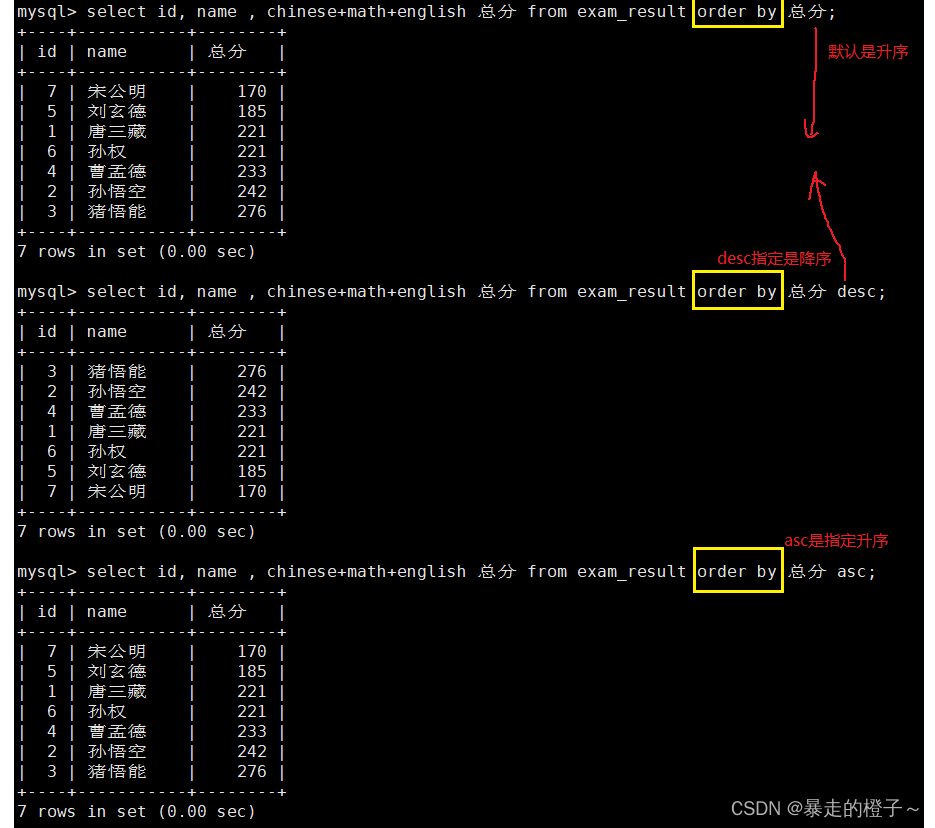
同学及 qq 号,按 qq 号排序显示

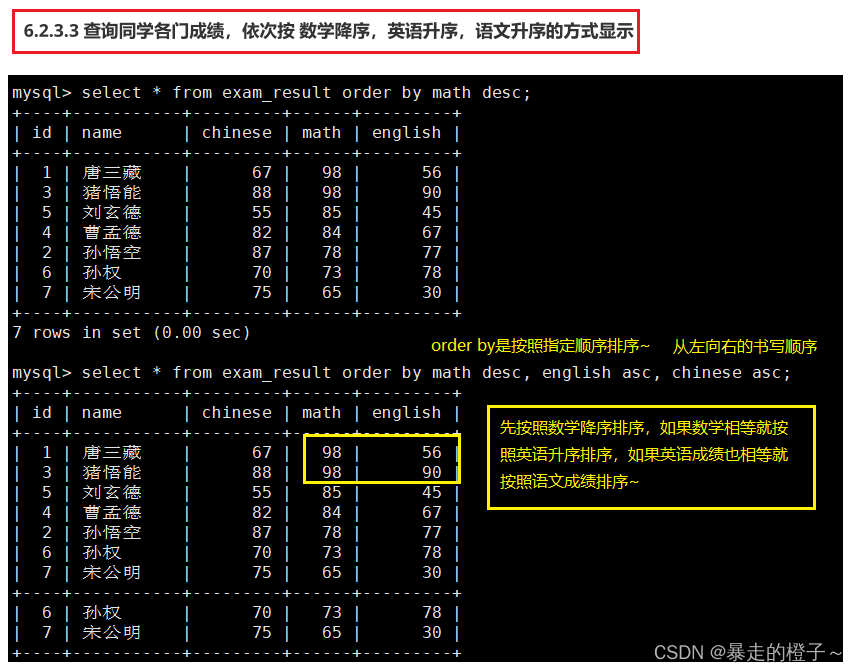
查询同学各门成绩,依次按 数学降序,英语升序,语文升序的方式显示
查询同学及总分,由高到低
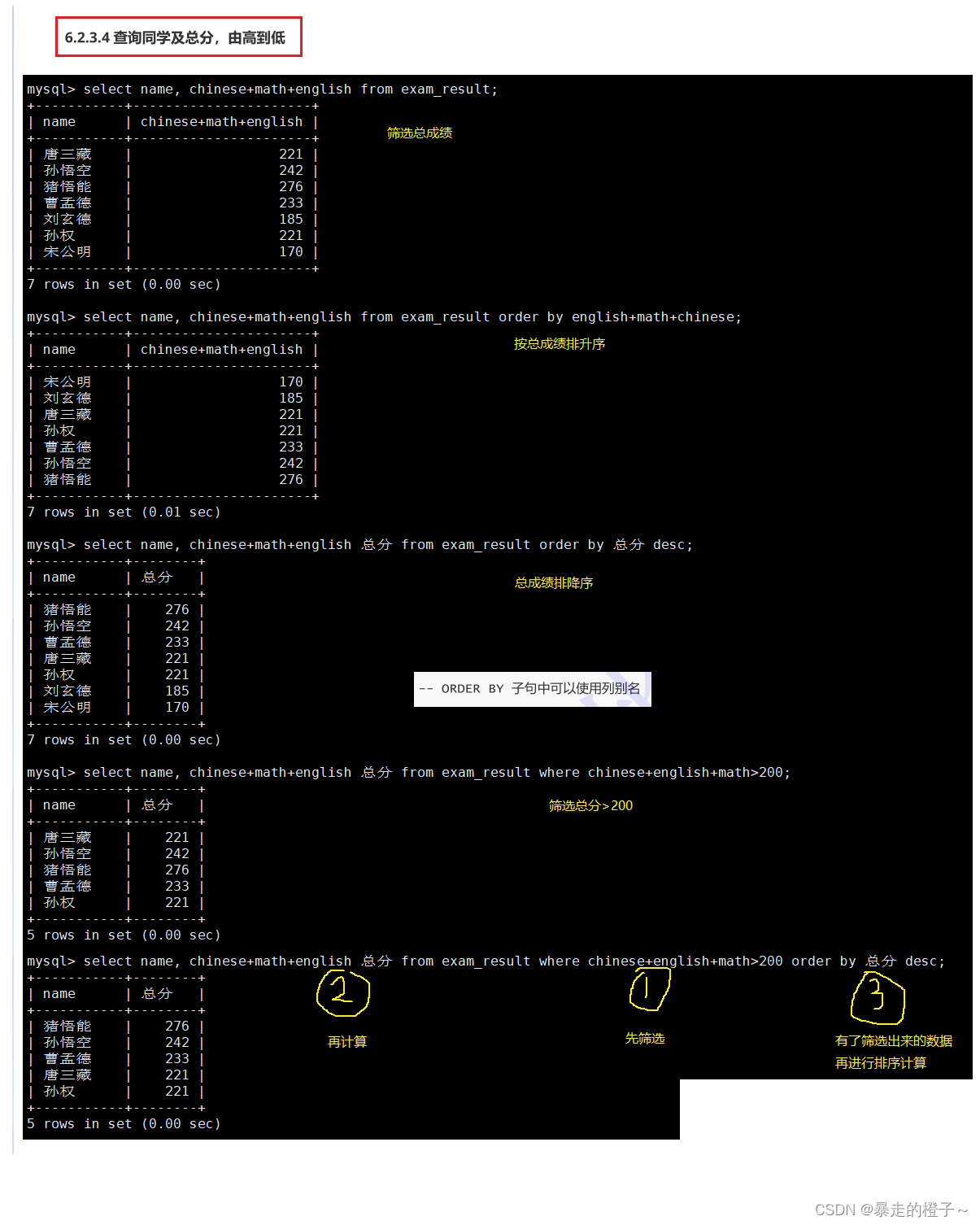
查询姓孙的同学或者姓曹的同学数学成绩,结果按数学成绩由高到低显示
筛选分页结果
-- 起始下标为 0
-- 从 0 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n;
-- 从 s 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT s, n;
-- 从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n OFFSET s;
limit n

limit s,n
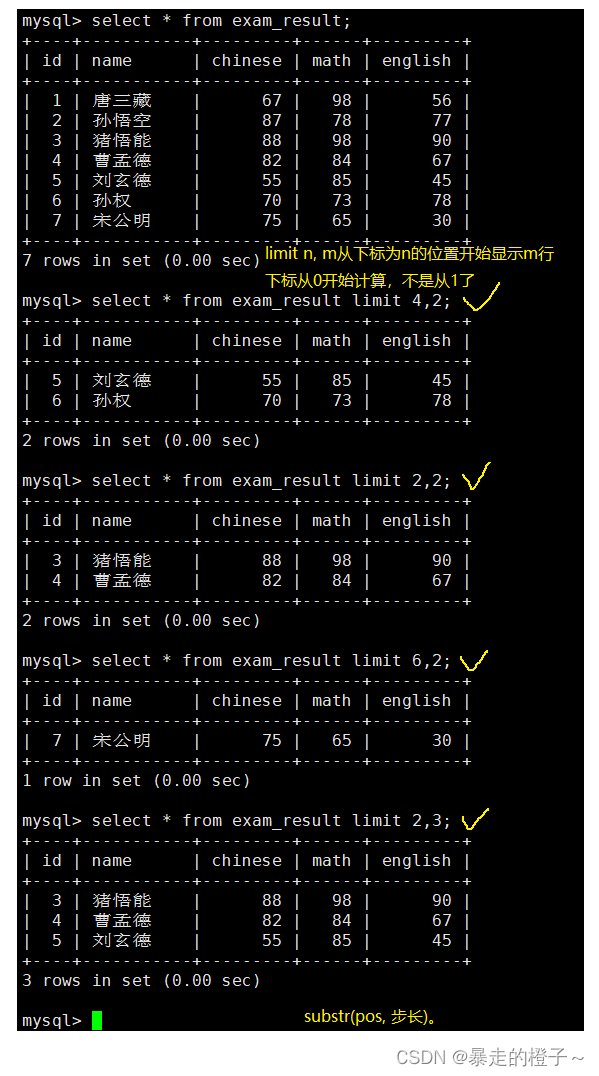
limit n offset s
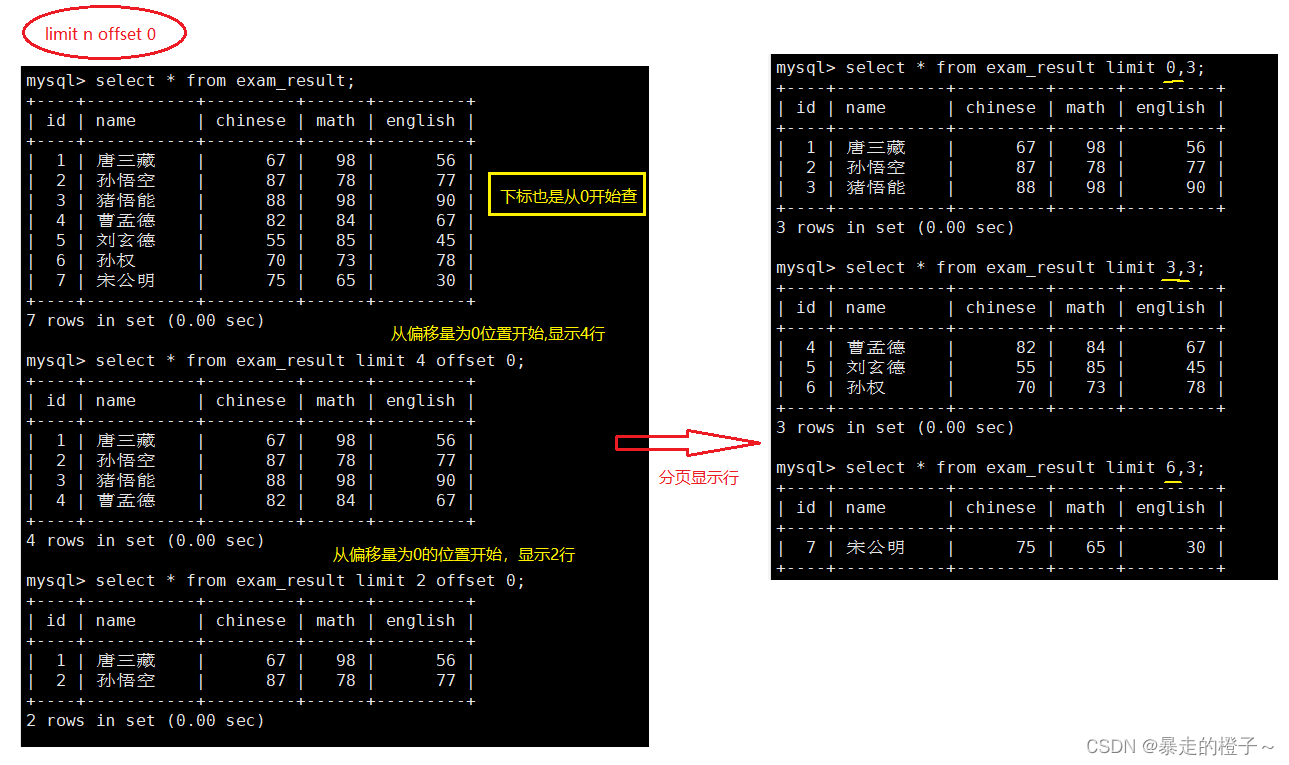
Update
UPDATE table_name SET column = expr [, column = expr ...] [WHERE ...] [ORDER BY ...] [LIMIT ...]
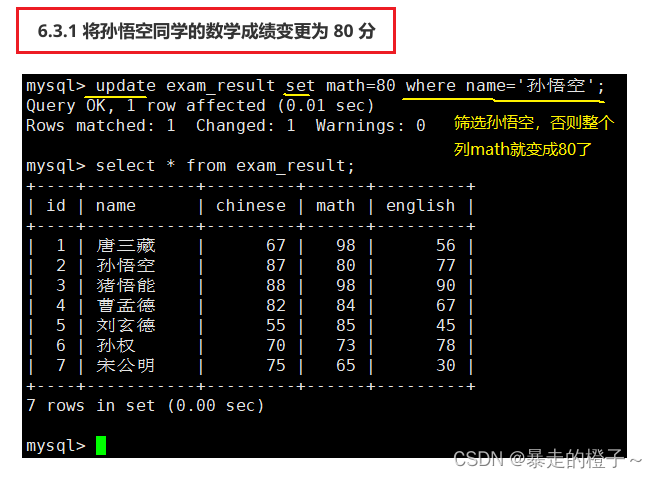
将孙悟空同学的数学成绩变更为 80 分
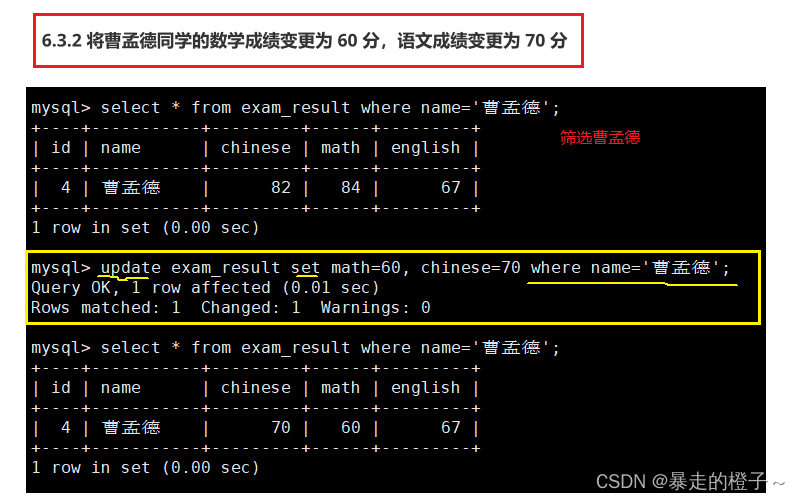
将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分
将总成绩倒数前三的 3 位同学的数学成绩加上 30 分

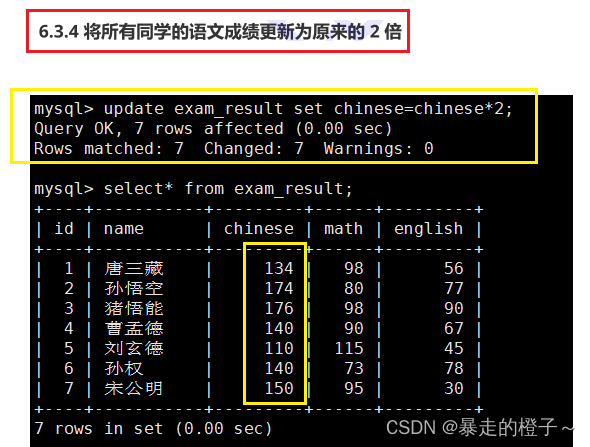
将所有同学的语文成绩更新为原来的 2 倍
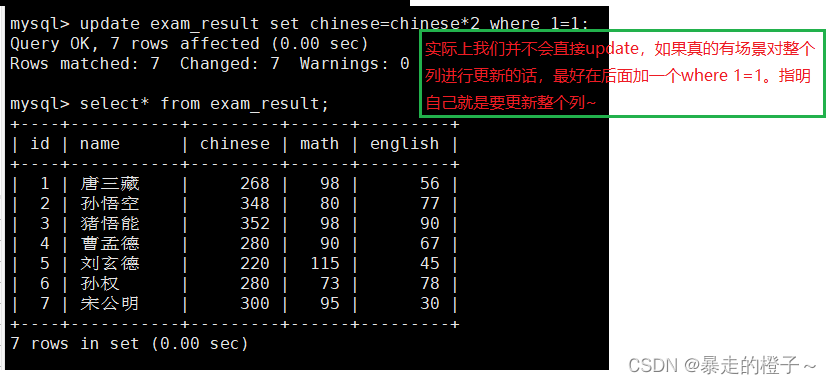
注意一个细节:
Delete
删除数据
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]
删除孙悟空同学的考试成绩
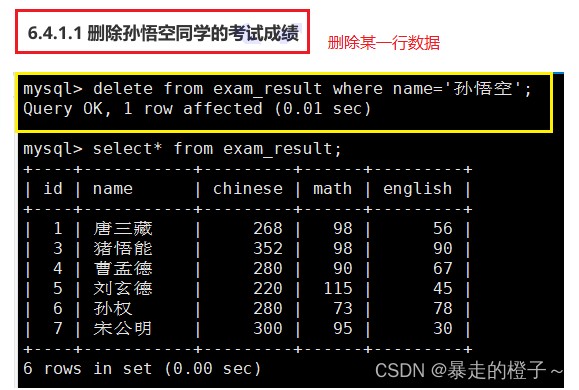
删除整张表数据
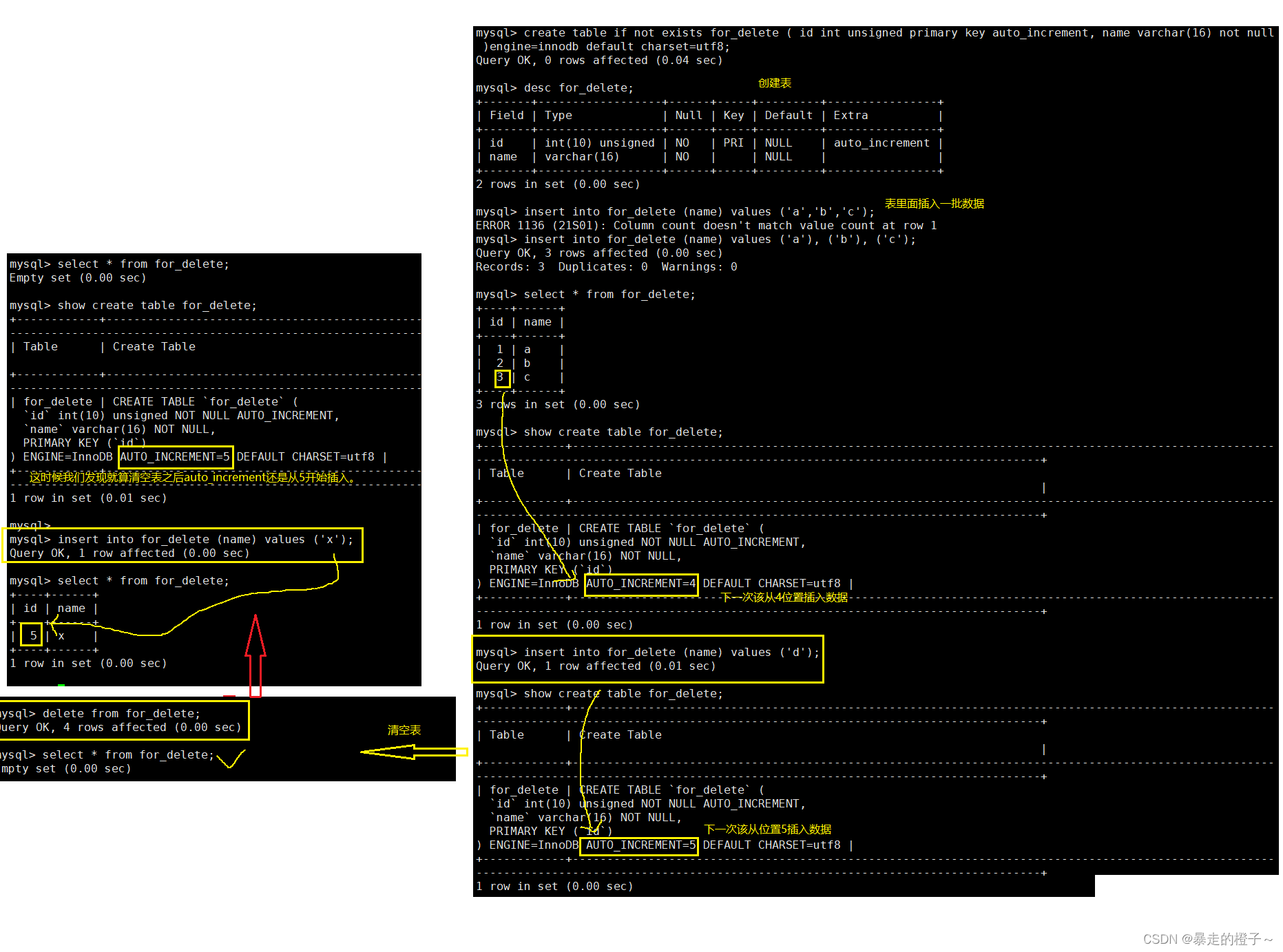
我们使用delete from 表名删除表数据后,对于表结构是不改变的。 如auto_increment字段记录的默认值是不变的。
截断表
truncate [TABLE] table_name

举个栗子:
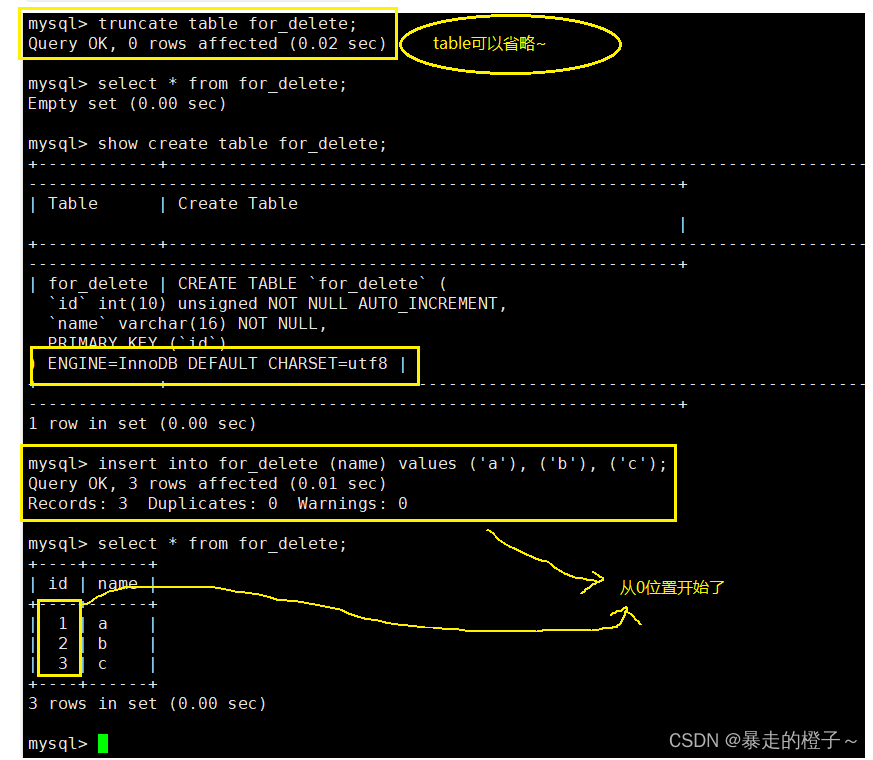
delete from 和 truncate [table]

delete from操作会被记录在bin log日志中,而truncate操作是不会记录在bin log记录中,说明后者是不适合数据备份的。
插入查询结果
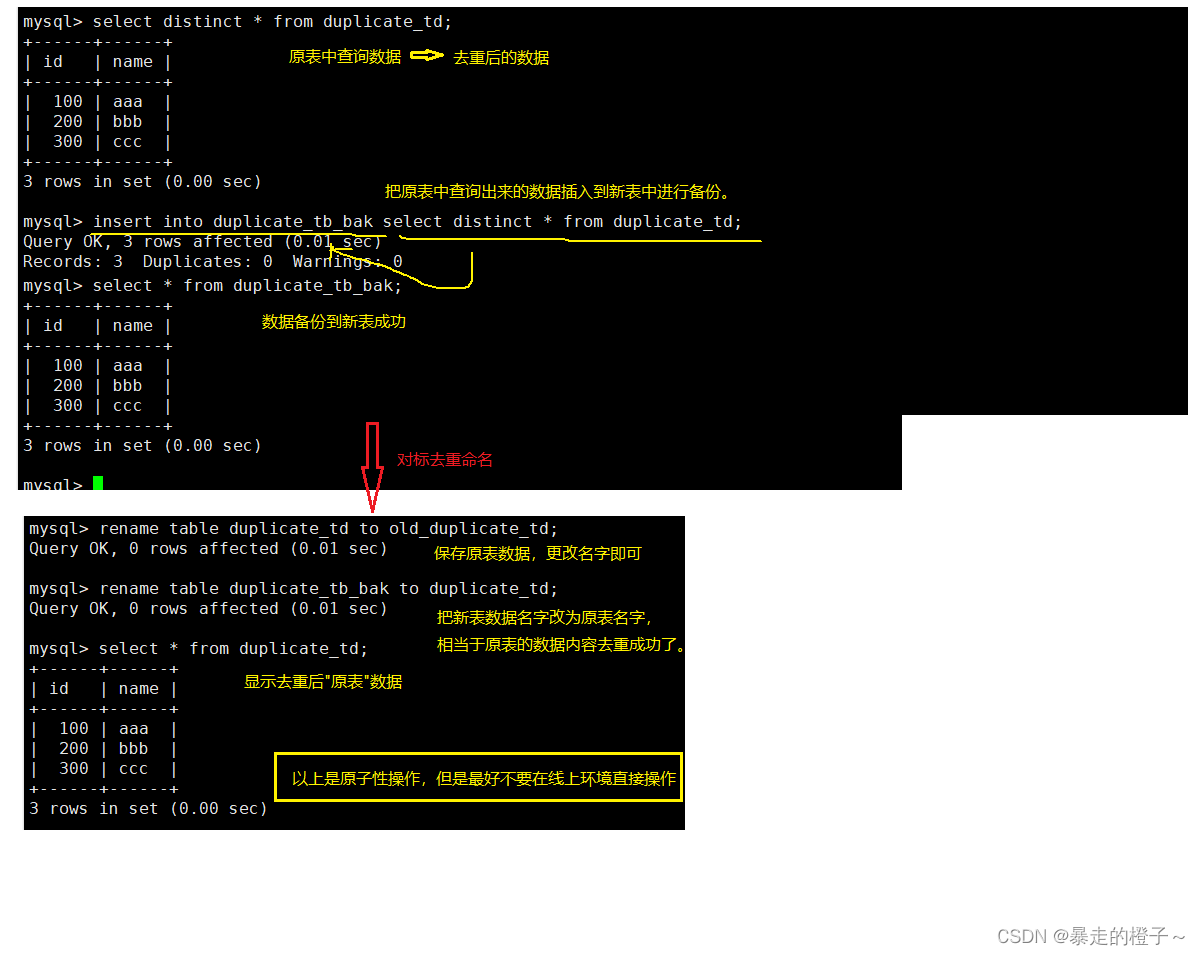
案例:删除表中的的重复复记录,重复的数据只能有一份
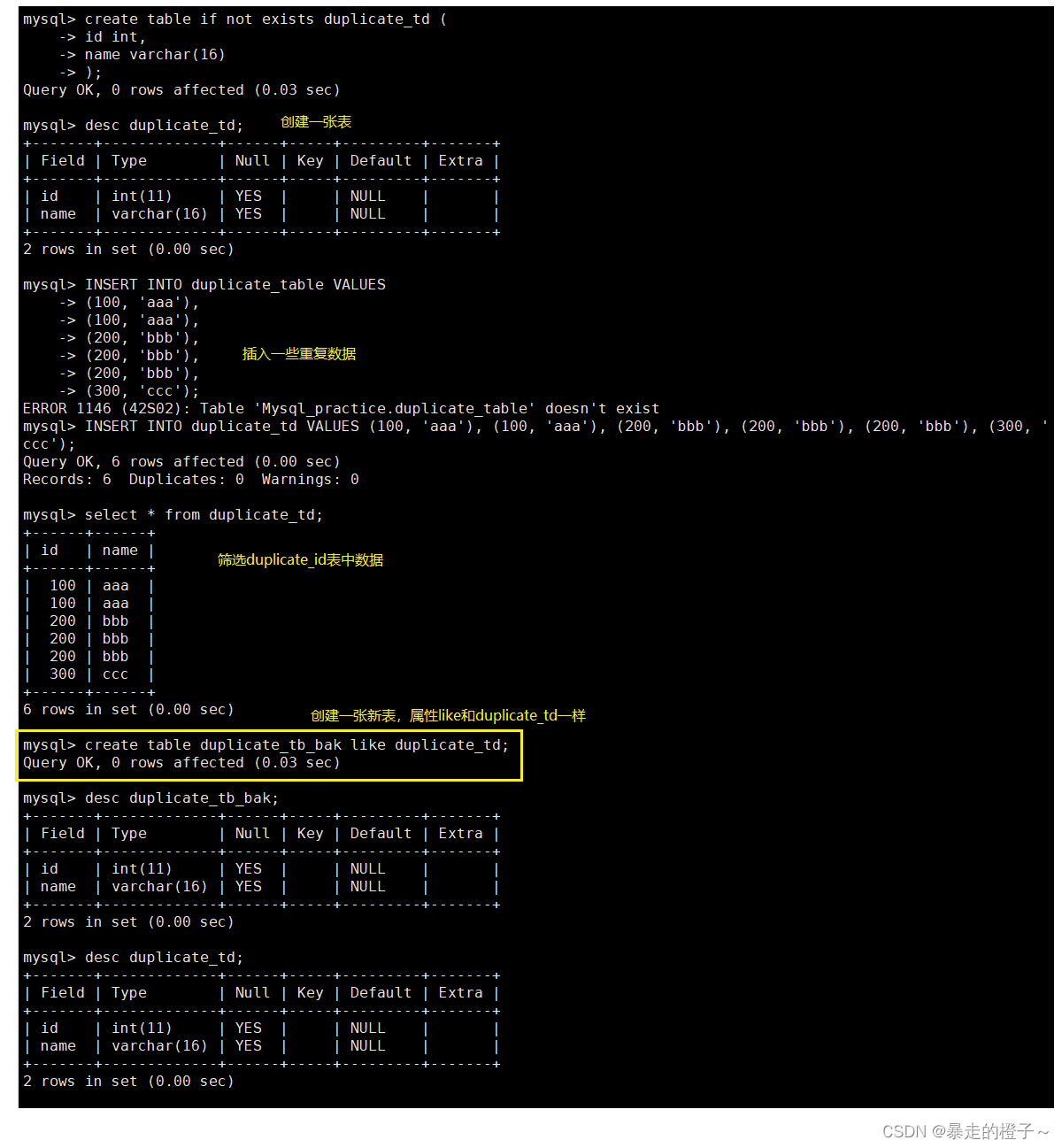
去重操作:
聚合函数

统计班级共有多少同学

统计班级收集的 qq 号有多少

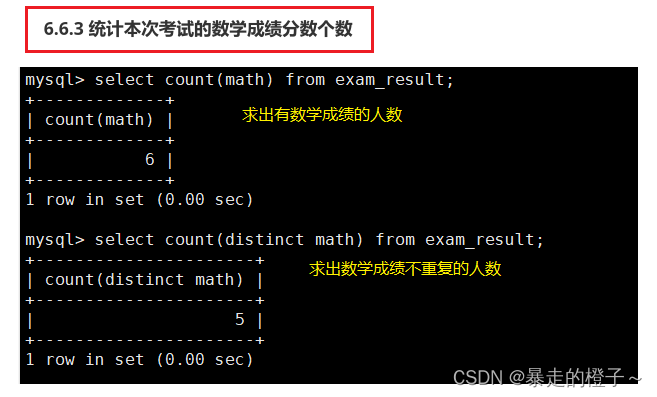
统计本次考试的数学成绩分数个数
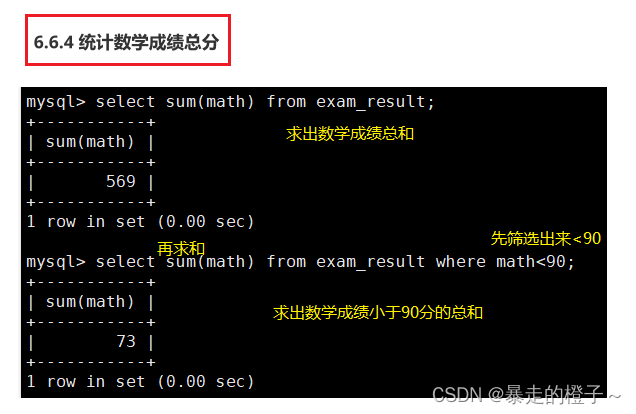
统计数学成绩总分
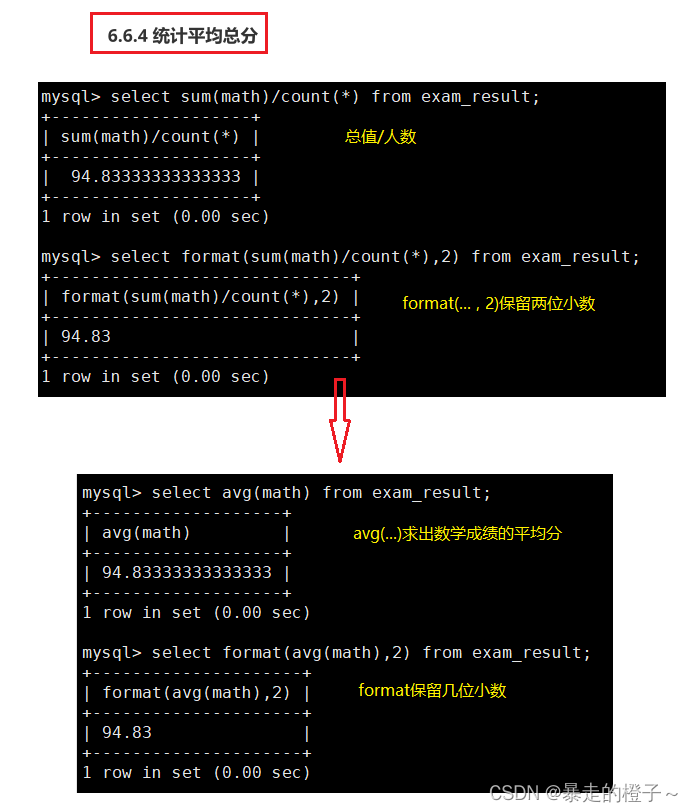
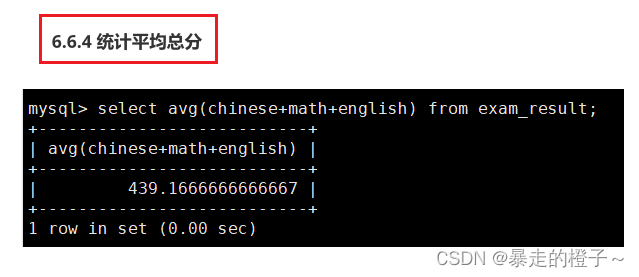
统计平均总分
返回英语最高分
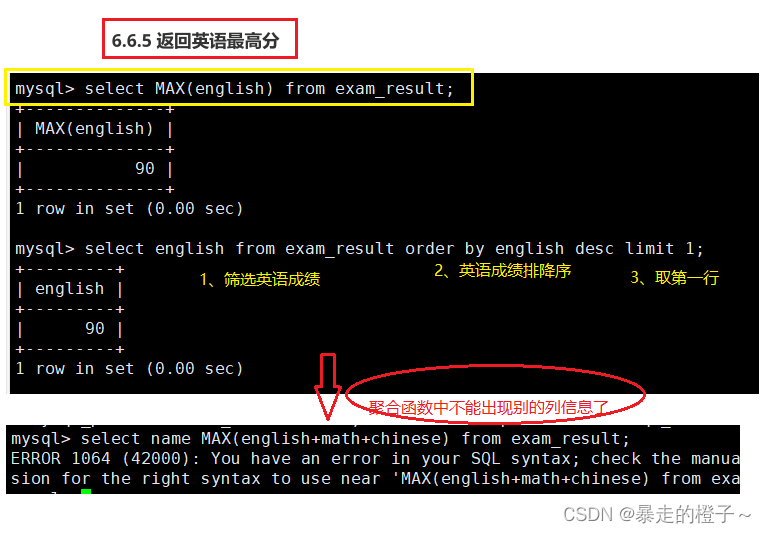
统计平均总分
返回 > 70 分以上的数学最低分
group by子句的使用
测试数据导入
如何显示每个部门的平均工资和最高工资
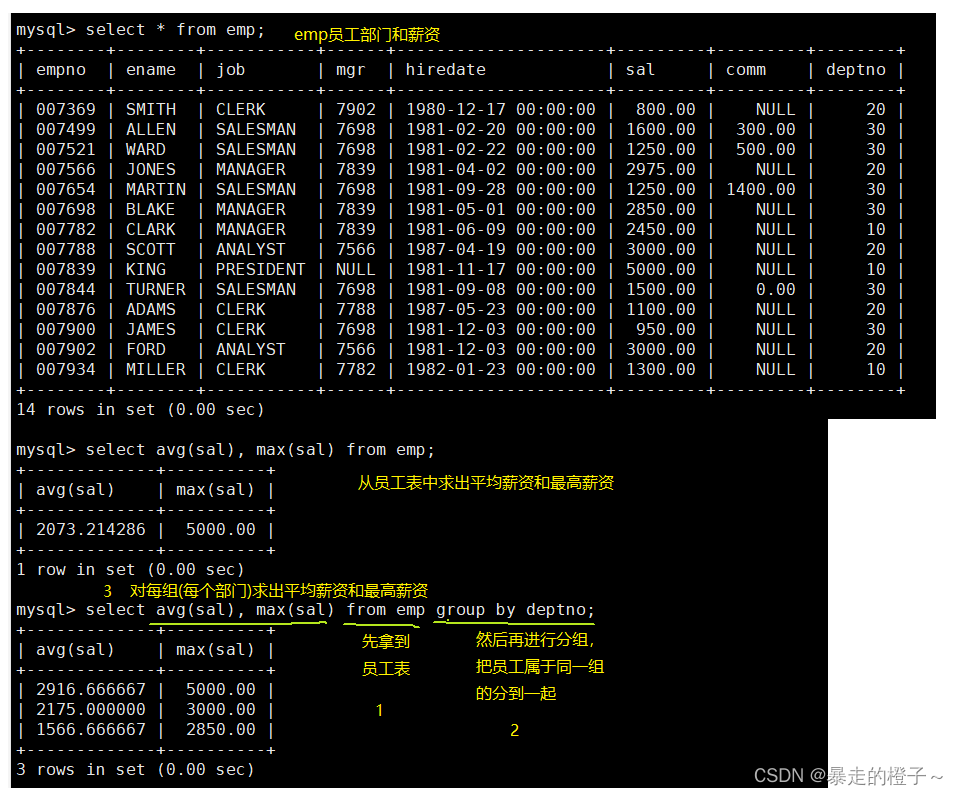
显示每个部门的每种岗位的平均工资和最低工资
显示平均工资低于2000的部门和它的平均工资

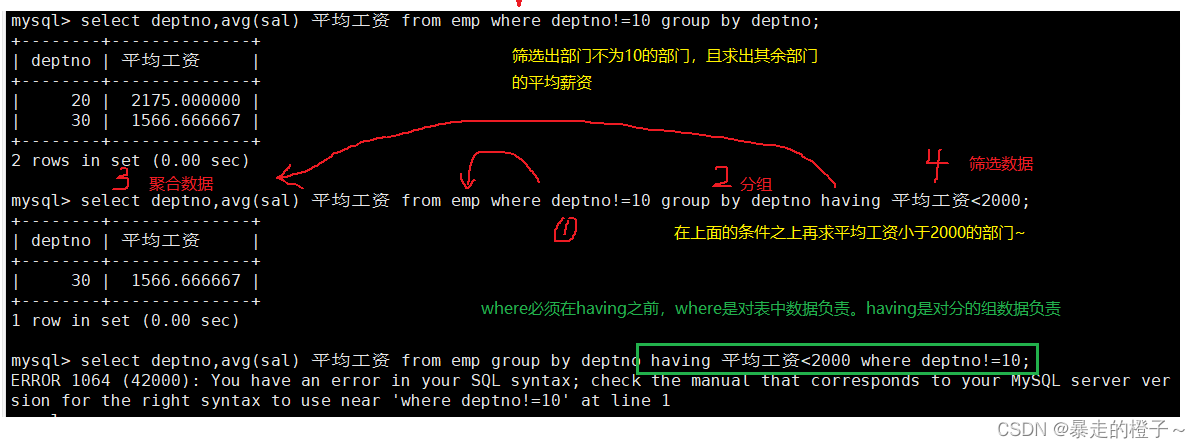
注意,对于这种情况分组是排到第一步的,where使用就不合适了,因为where几乎是先执行的子句,这时候我们只能借助having来帮助我们筛选。
where 和having比较
where和having可以一起配合使用
给博主点个赞呗~




![[论文阅读] Generative Adversarial Networks for Video-to-Video Domain Adaptation](https://img-blog.csdnimg.cn/0051da86ae354bde889cd39211bf7216.jpeg#pic_center)