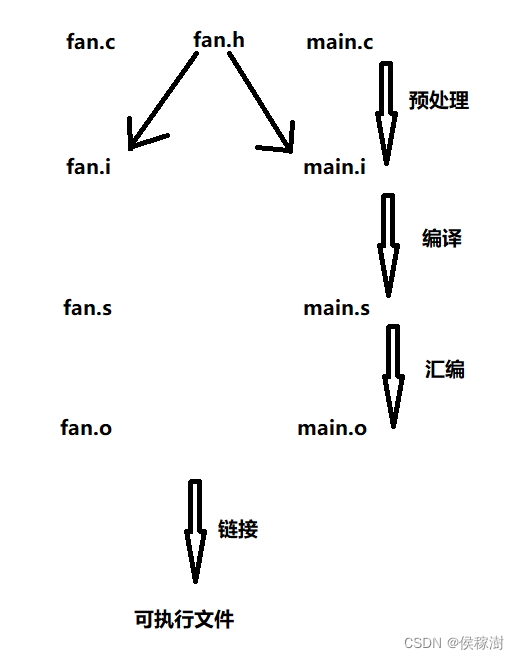
策略梯度法的思路
之前我们是用表格的形式来表达策略,现在我们同样可以用函数来表达策略。之前学的所有的方法都是被称为 value-based,接来下学的叫 policy-based 。接下来我们来看一下 策略梯度法的思路。之前学的的策略全都是用表格来表示的,如下:

现在,我们把表格改成函数,那么
π
π
π 的写法也会发生改变,如下:

其中,
θ
θ
θ 是一个向量可以用来表示
π
π
π 这个函数里边的参数。
用表格与函数表示不同之处还在于获取一个 action 的概率。 表格形式直接通过索引查表,而用函数会稍微麻烦一点,不能直接去索引了,需要计算对应的 π ( a ∣ s , θ ) π(a|s,\theta) π(a∣s,θ)
用表格与函数表示不同之处还在于更新策略的方式。表格中直接通过修改表格中的值就可以了。当用参数化函数表示时,策略 π π π 只能通过修改参数 θ \theta θ 去更新策略。
.
策略梯度法的思路:
用函数表示时,我们会建立某些标量的目标函数
J
(
θ
)
J(\theta)
J(θ),通过优化目标函数使得策略
π
π
π 达到最优,如下:

标量的目标函数的选取
上面我们知道要建立一个标量的目标函数,那么这个标量的目标函数是什么呢?通常,我们常用两大类标量的目标函数。
第一个是状态值平均值,或者简单地称为平均值,其实就是 state value 的一 个加权平均,如下:

v
ˉ
\bar v
vˉ 是 state value 的加权平均
d
(
s
)
d(s)
d(s) 代表了状态
s
s
s 被选中的概率
以上的形式我们还可以写成一种更简洁形式,就是两个向量的内积:

.
那么,我们怎么去选择 d ( s ) d(s) d(s) 呢?我们分两种情况 ,一是 d d d 和 π π π 没有关系;而是 d d d 和 π π π 有关系。
当 d d d 和 π π π 没有关系时,我们分别用 d 0 d_0 d0 和 π ˉ 0 \bar π_0 πˉ0 表示,同样的我们可以采取均匀分布 d 0 ( s ) = 1 / ∣ S ∣ = 1 / n d_0(s)=1/|S|=1/n d0(s)=1/∣S∣=1/n ,如果某一状态比较重要,那么我们可以将其权重提高。
当
d
d
d 和
π
π
π 有关系时,常用的方法选择平稳分布,如下:

.
第二个是即时奖励平均值 ,就是即时奖励的一 个加权平均,如下:

上面是 reward 的第一种形式,我们经常会看到 reward 的另外一种形式,如下:

其中,我们假设遵循给定的策略并生成一个轨迹,得到一系列的奖励
(
R
t
+
1
,
R
t
+
2
,
…
…
)
(R_{t+1},R_{t+2},……)
(Rt+1,Rt+2,……) ;在跑了无穷多步之后,
s
0
s_0
s0 已经不重要了,所以最后把
s
0
s_0
s0 去掉了
.
上面我们介绍了两种标量的目标函数的选取方式,接下来我们对这两个标量做进行进一步的总结:
1、他们都是策略
π
π
π 的函数
2、策略
π
π
π 是一个函数的形式,它的参数是
θ
\theta
θ ,不同的
θ
\theta
θ 会得到不同的值
3、可以通过找到最优的
θ
\theta
θ 去最大化标量的值
4、
r
ˉ
π
\bar r_π
rˉπ 与
v
ˉ
π
\bar v_π
vˉπ 是等价的,对其中一个做优化的时候另外也进行了优化。在折扣系数
γ
<
1
γ<1
γ<1 是,有
r
ˉ
π
=
(
1
−
γ
)
v
ˉ
π
\bar r_π=(1-γ)\bar v_π
rˉπ=(1−γ)vˉπ
策略梯度求解
得到一个策略标量后,计算出其梯度。然后,应用基于梯度的方法进行优化,其中,梯度计算是最复杂部分之一。那是因为,首先,我们需要区分不同的 v ˉ π \bar v_π vˉπ , r ˉ π \bar r_π rˉπ , v ˉ π 0 \bar v_π^0 vˉπ0 ;其次,我们需要区分折扣和未折扣。梯度的计算,这里我们就做比较简要的介绍。

J
(
θ
)
J(\theta)
J(θ) 可以是
v
ˉ
π
\bar v_π
vˉπ ,
r
ˉ
π
\bar r_π
rˉπ ,
v
ˉ
π
0
\bar v_π^0
vˉπ0 ;
η
η
η 是分布概率或权重
"=” 可以表示严格相等、近似或与成正比
v
ˉ
π
\bar v_π
vˉπ ,
r
ˉ
π
\bar r_π
rˉπ ,
v
ˉ
π
0
\bar v_π^0
vˉπ0 相应的梯度公式如下:

.
梯度公式分析:
上面的式子我们可以写成如下形式:

S 服从 η 分布 S服从η分布 S服从η分布 ; A 服从 π ( A ∣ S , θ ) 分布 A服从π(A|S,\theta)分布 A服从π(A∣S,θ)分布
为什么我们需要这样一个式子呢?这是因为真实的梯度含有期望
E
E
E ,而期望
E
E
E 是不知道的,所以我们可以通过采样来近似来做优化,如下:

补充说明:
因为要计算
l
n
π
(
a
∣
s
,
θ
)
lnπ(a|s,\theta)
lnπ(a∣s,θ),所以要求
π
(
a
∣
s
,
θ
)
>
0
π(a|s,\theta)>0
π(a∣s,θ)>0 ,怎么确保所有的
π
π
π 对所有的
a
a
a 全都是大于0呢?使用 softmax function 进行归一化,如下:

那么,
π
π
π 的表达形式如下:

h
(
s
,
a
,
θ
)
h(s,a,\theta)
h(s,a,θ) 是另一个函数,通常由神经网络得到。
梯度上升和REINFORCE
梯度上升算法的基本思路是,真实的梯度有期望 E E E ,所以用随机的梯度来代替真实梯度,但还有一个 q π ( s , a ) q_π(s,a) qπ(s,a) 即策略 π π π 所对应的真实的 action value 是不知道的,同样的我们用一个方法来近似或者对 q π q_π qπ 进行采样,方法是与MC结合——reinforce ,如下:

.
我们是用随机的梯度来代替真实梯度,那么我们怎么对随机变量
(
S
,
A
)
(S,A)
(S,A) 采样呢?首先对
S
S
S 采样,因为
S
服从
η
分布
S服从η分布
S服从η分布 它要求大量的数据,在现实中等难以达到平稳的状态,所以在实际当中一般是不太考虑的。那怎么对
A
A
A 采样呢?因为
A
服从
π
(
A
∣
S
,
θ
)
分布
A服从π(A|S,\theta)分布
A服从π(A∣S,θ)分布 ,因此,在
s
t
s_t
st 应该根据策略
π
(
θ
)
π(\theta)
π(θ) 对
a
t
a_t
at 进行取样。所有这里的策略梯度属于 on-policy 算法。

算法理解

要求
α
β
t
\alpha\beta_t
αβt 较小,可以发现
β
t
\beta_t
βt 能够平衡算法发 探索 和 数据利用。因为
β
t
\beta_t
βt 与
q
t
(
s
t
,
a
t
)
q_t(s_t,a_t)
qt(st,at) 成正比,因此,当
q
t
(
s
t
,
a
t
)
q_t(s_t,a_t)
qt(st,at) 较大时
β
t
\beta_t
βt 也会比较大,意味着
π
t
(
s
t
,
a
t
)
π_t(s_t,a_t)
πt(st,at) 有较大的概率被选择。
β
t
\beta_t
βt 与
π
(
a
t
∣
s
t
,
θ
t
)
π(a_t|s_t,\theta_t)
π(at∣st,θt) 成反比,因此,当
β
t
\beta_t
βt 较大时
π
(
a
t
∣
s
t
,
θ
t
)
π(a_t|s_t,\theta_t)
π(at∣st,θt) 会比较小,意味着如果之前我选择
π
t
(
s
t
,
a
t
)
π_t(s_t,a_t)
πt(st,at) 的概率是比较小的,下一时刻给它更大的概率去选择它。
当
β
t
>
0
\beta_t>0
βt>0 时,这是
π
(
a
t
∣
s
t
,
θ
)
π(a_t|s_t,θ)
π(at∣st,θ) 梯度上升算法,有:

当
β
t
<
0
\beta_t<0
βt<0 时,这是
π
(
a
t
∣
s
t
,
θ
)
π(a_t|s_t,θ)
π(at∣st,θ) 梯度下降算法,有:

.
reinforce 算法
用
q
t
(
s
t
,
a
t
)
q_t(s_t,a_t)
qt(st,at) 去近似代替
q
π
(
s
t
,
a
t
)
q_π(s_t,a_t)
qπ(st,at) ,
q
t
(
s
t
,
a
t
)
q_t(s_t,a_t)
qt(st,at) 是用蒙特卡洛的方法求得,即就是从
(
s
t
,
a
t
)
(s_t,a_t)
(st,at) 出发得到一个 episode ,然后把这个episode 的 return 赋给
q
t
q_t
qt,这种就是 reinforce 算法。

.
reinforce 算法,其伪代码如下:

在进行第
k
k
k 次迭代时,先选定一个初始的
s
t
a
t
e
state
state 根据当前的策略
π
(
θ
k
)
π(\theta _k)
π(θk) 和环境进行交互就得到一个 episode ,针对这个episode 当中的每一个元素我们要过一遍。然后对每一个元素进行操作,分为两步。第一步是做 value update,就是用蒙特卡洛的方法去估计
q
t
q_t
qt ,从
(
s
t
,
a
t
)
(s_t,a_t)
(st,at) 出发把后边所得到的所有的 reward 相加。接下来就是 policy update ,将得到的
q
t
q_t
qt 代到公式里去更新
θ
t
θ_t
θt ,最后把最后所得到的
θ
T
θ_T
θT 作为一个新的
θ
k
θ_k
θk 进行迭代更新。