文章目录
- 1、正则表达式介绍
- 2、正则表达式和BeautifulSoup
- 3、获取属性
- 4、Lambda表达式
1、正则表达式介绍
正则表达式是指一个用来描述或者匹配一系列符合某个句法规则的字符串的单个字符串。它描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
由一些普通字符和一些元字符(metacharacters)组成。普通字符包括大小写的字母和数字,而元字符则具有特殊的含义。
(1)常用的正则表达式符号:
| 符号 | 含义 | 例子 | 匹配结果 |
|---|---|---|---|
| * | 匹配前面的字符、子表达式或括号里的字符0次或多次 | ab | aaaaaaa, aaabbbbb, bbbbb |
| + | 匹配前面的字符、子表达式或括号里的字符至少1次 | a+b+ | aaaaaab, aaabbbb, abbbbb |
| [ ] | 匹配中括号里的任意一个字符(相当于“任选一个”) | [A-Z]* | APPLE, CAPITALS |
| ( ) | 表达式编组(在正则表达式的规则里编组会优先运行) | (ab) | aaabab, abaaab, ababaaaab |
| {m, n} | 匹配前面的字符、子表达式或括号里的字符m到n次(包括m或n) | a{2, 3}b{2, 3} | aabb, aabbb, aaabbb |
| [^] | 匹配任意一个不在中括号的字符 | [^A-Z]* | apple, lowercase |
| I | 匹配任意一个由竖线分割的字符、子表达式 | b(a | i |
| . | 匹配除换行符(\n、\r)之外的任意单个字符 | b.d | bad, b%d, b d |
| ^ | 匹配输入字符串的开始位置 | ^a | apple, asdf, a |
| \ | 转义字符(把特殊含义的字符转换成字面形式) | .\I\ | .I\ |
| $ | 匹配输入字符串的结束位置 | [A-Z][a-z]$ | ABCabc, zzzyx, Bob |
| ?! | “不包含”。这个奇怪的组合通常放在字符或正则表达式前面,表示字符不能出现在目标字符串里。这个符号比较难用,毕竟字符通常会在字符串的不同部位出现。如果要在整个字符串中彻底排除某个字符,就加上^和$符号 | ^((?![A-Z]).)*$ | no-caps-here, $ymb0ls, a4e f!ne |
(2)经典应用-识别邮箱:
| 规则 | 正则表达式 |
|---|---|
| 1.邮箱地址的第一部分至少包括一种内容:大写字母,小写字母、数字0-9、点号(.)、加号(+)或下划线(_) | [A-Za-z0-9._+]+:这个正则表达式简写写的非常智慧。例如,它用“A-Z”表示“A-Z中的任意大写字母”。把所有可能的序列和符号放在中括号(不是小括号)里表示 “可以是方括号中的任何一个符号”。要注意后面的加号,它表示 “这些符号都可以出现多次,但至少要出现1次” |
| 2.之后,邮箱地址会包含一个@符号 | @:这个符号很简单:@符号必须出现在中间位置,并且只能出现1次 |
| 3.在符合 @之后,邮箱地址还必须至少包含一个大写或小写字母 | [A-Za-z]+:可能只在域名的前半部分、符号 @ 后面用字母。而且,至少要有一个字符 |
| 4. 之后跟一个点号(.) | .:在域名前必须有一个点号(.)。退格在这里用作转义字符 |
| 5. 最后邮箱地址用 com、org、 edu、net结尾(实际上,顶级域名有很多种可能,但是作为示例演示这4个后缀够用了) | (comIorgIeduInet):这样列出了后半部分邮箱地址中可能出现在点号之后的字母序列 |
完整的表达式:[A-Za-z0-9\._+]+@[A-Za-z]+\.(com|org|edu|net)
2、正则表达式和BeautifulSoup
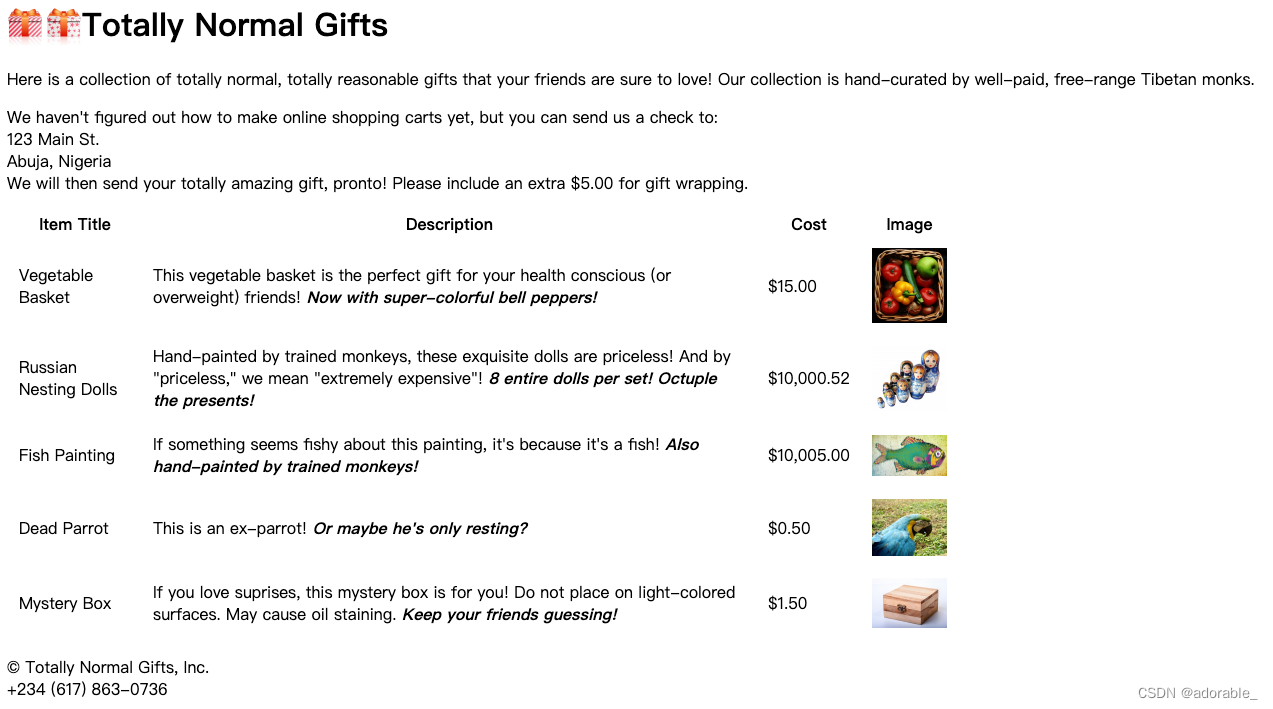
提取页面的图片链接:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
html = urlopen('http://pythonscraping.com/pages/page3.html')
bs = BeautifulSoup(html.read(), 'html.parser')
images = bs.find_all('img', {'src': re.compile('\.\.\/img\/gifts\/img.*\.jpg')})
for image in images:
print(image['src'])
# ../img/gifts/img1.jpg
# ../img/gifts/img2.jpg
# ../img/gifts/img3.jpg
# ../img/gifts/img4.jpg
# ../img/gifts/img6.jpg
3、获取属性
对于一个标签对象,可以用下面的代码获取它的全部属性:
myTag.attrs
要注意这行代码返回的是一个Python字典对象,可以轻松获取和操作这些属性。比如要获取图片的源位置src,可以用下面这行代码:
myImgTag.attrs['src']
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen('http://pythonscraping.com/pages/page3.html')
bs = BeautifulSoup(html.read(), 'html.parser')
tr = bs.find('tr', {'id': 'gift2'})
print(tr.attrs)
print(tr['id'])
print(tr['class'])
# {'id': 'gift2', 'class': ['gift']}
# gift2
# ['gift']
4、Lambda表达式
Lambda表达式本质上就是一个函数,可以作为变量传入两亿个函数;也就是说,一个函数不是定义成f(x, y),而是可以定义成f(g(x), h(y))的形式。
BeautifulSoup允许我们把特定类型的函数作为参数传入find_all函数。唯一的限制条件就是这些函数必须把一个标签对象作为参数并且返回布尔类型的结果。BeautifulSoup用这个函数来评估它遇到的每个标签对象,最后把评估结果为“真”的标签保留,把其他标签剔除。
如,下面的代码就是获取有两个属性的所有标签:
bs.find_all(lambda tag : len(tag.attrs) == 2)
这里,作为参数传入的函数是len(tag.attrs) == 2。当该参数为真时,find_all函数将返回tag。即找出带有两个属性的所有标签。
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
html = urlopen('http://pythonscraping.com/pages/page3.html')
bs = BeautifulSoup(html.read(), 'html.parser')
print(bs.find_all(lambda tag : tag.get_text() == 'Or maybe he\'s only resting?'))
print(bs.find_all(text='Or maybe he\'s only resting?'))
# [<span class="excitingNote">Or maybe he's only resting?</span>]
# ["Or maybe he's only resting?"]





![python中,数组 nums[:] 和nums有何区别?](https://img-blog.csdnimg.cn/f930e09b837348e3bac96a82c60fb7e5.png)