搭建Hadoop高可用框架分布式集群

一.基础配置
1.创建虚拟机,修改虚拟机的主机名



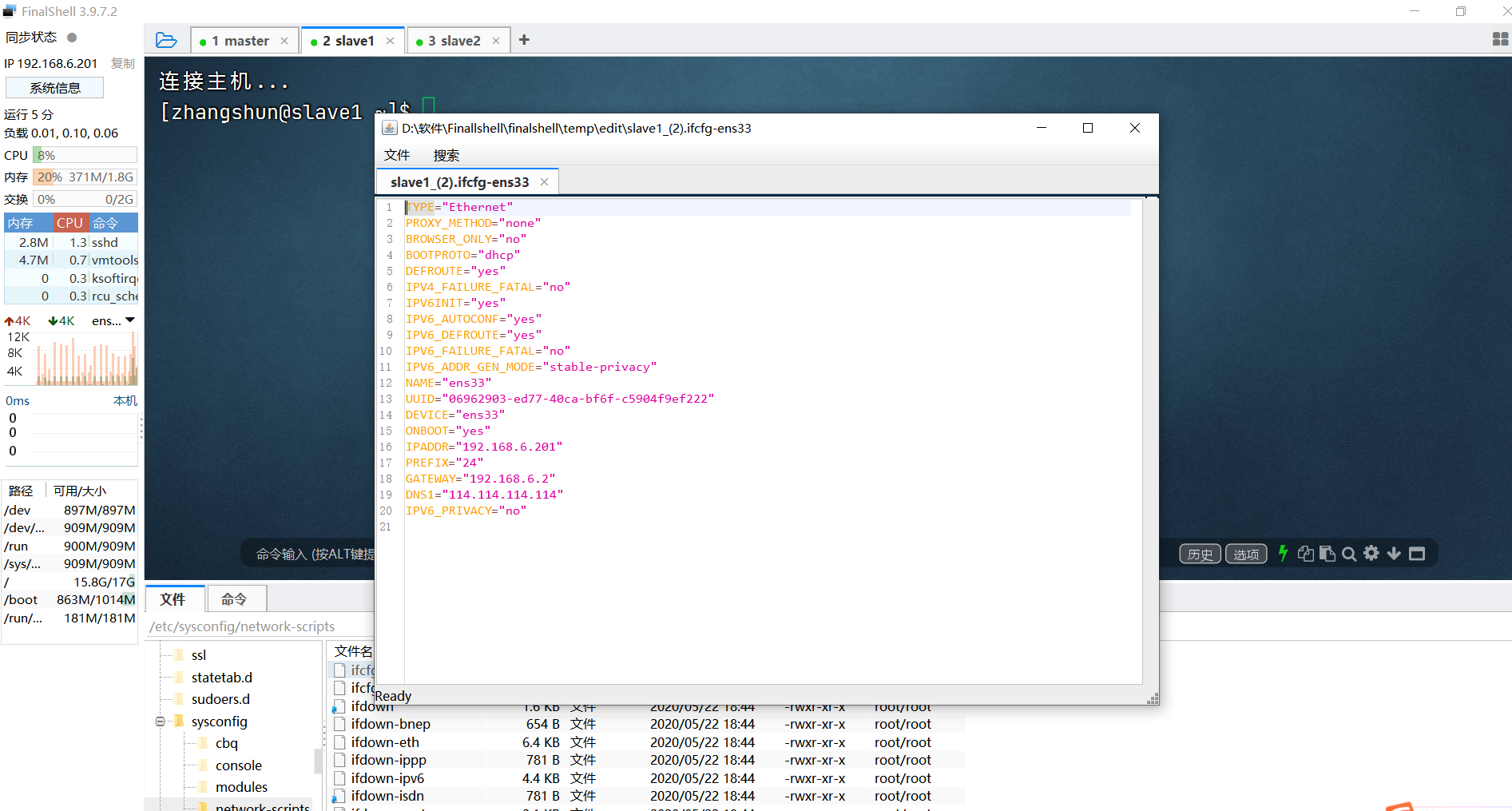
2.修改网络配置
master:192.168.6.200
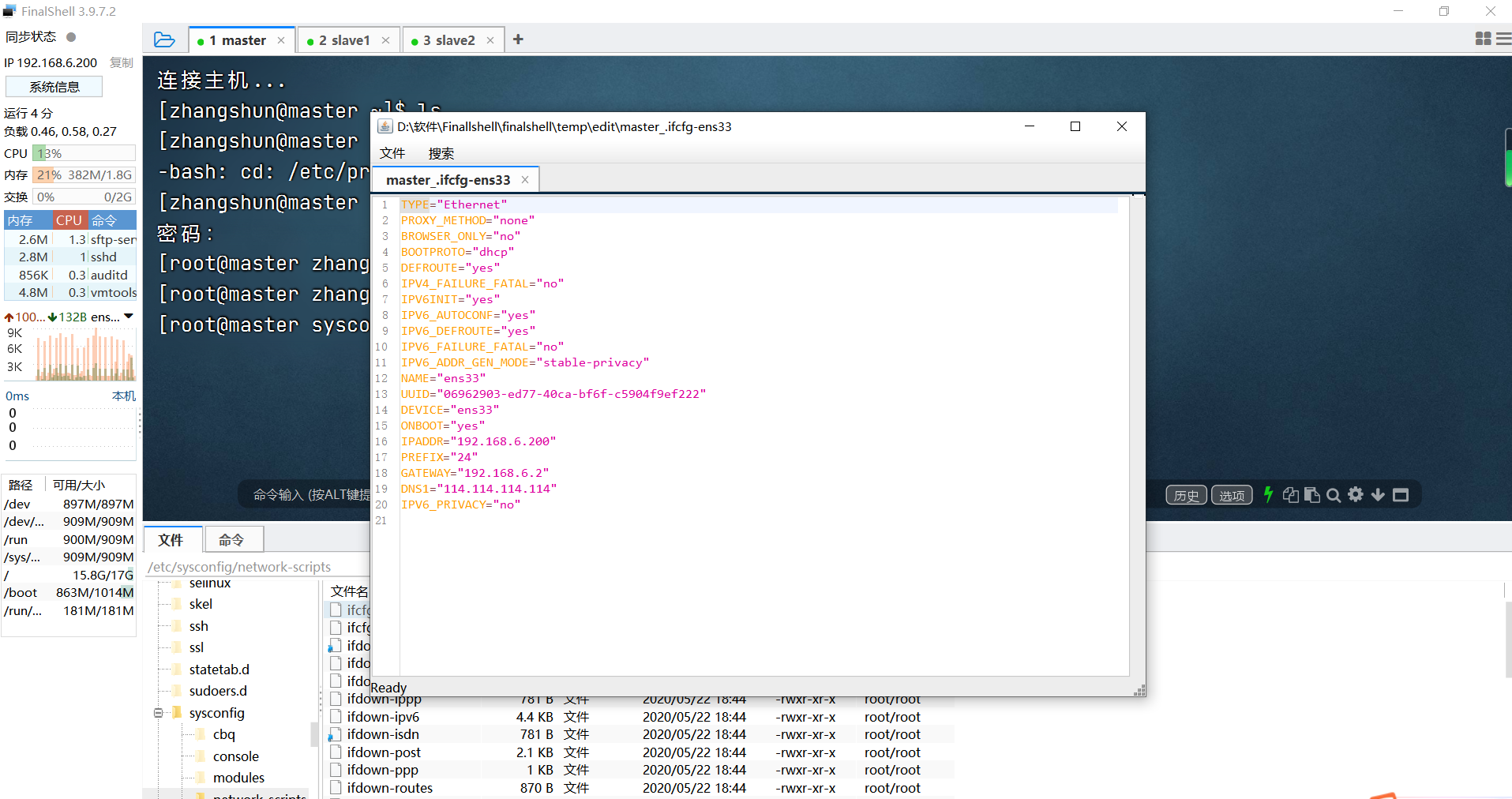
slave1:192.168.6.201
slave2:192.168.6.202
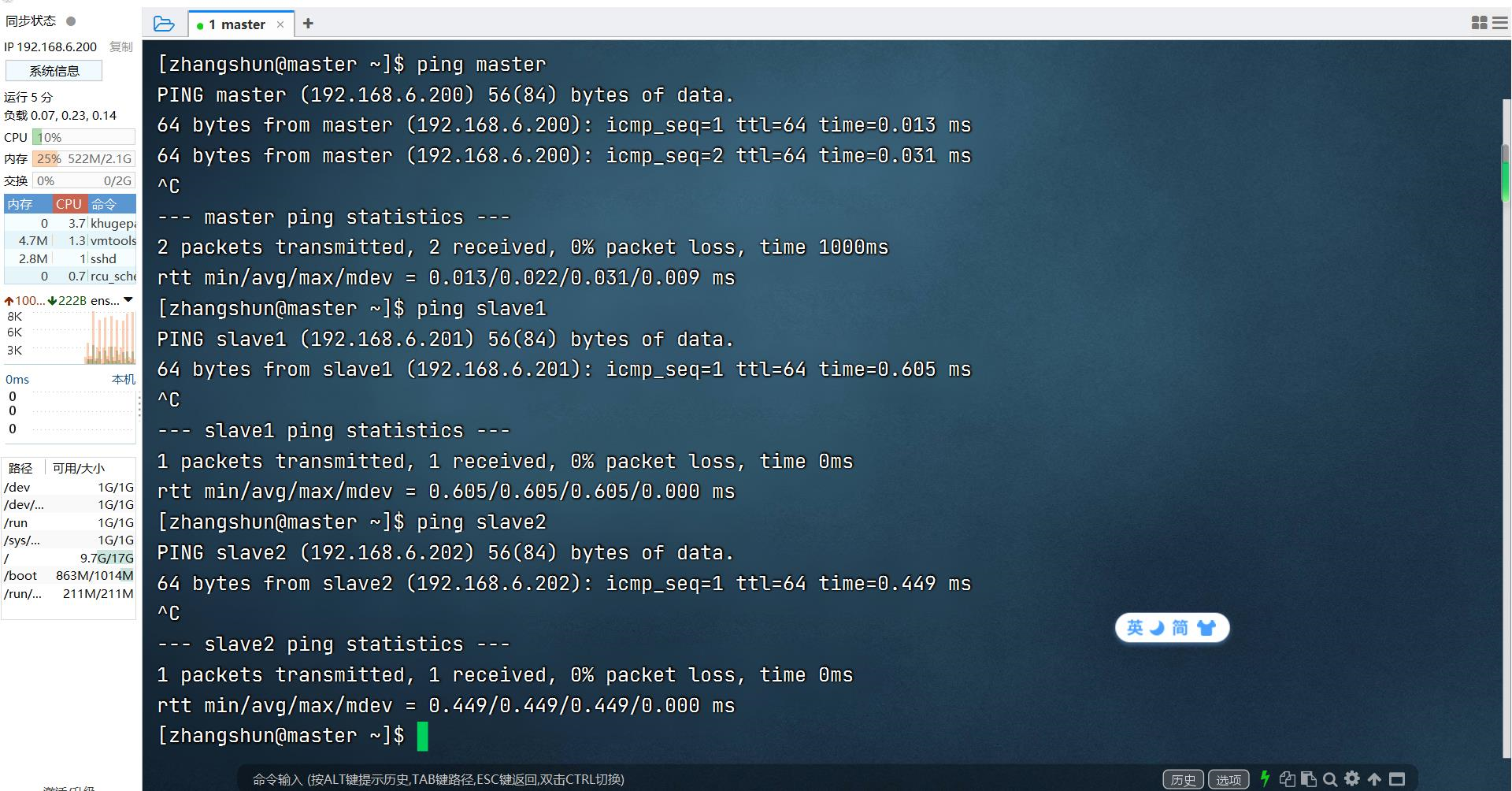
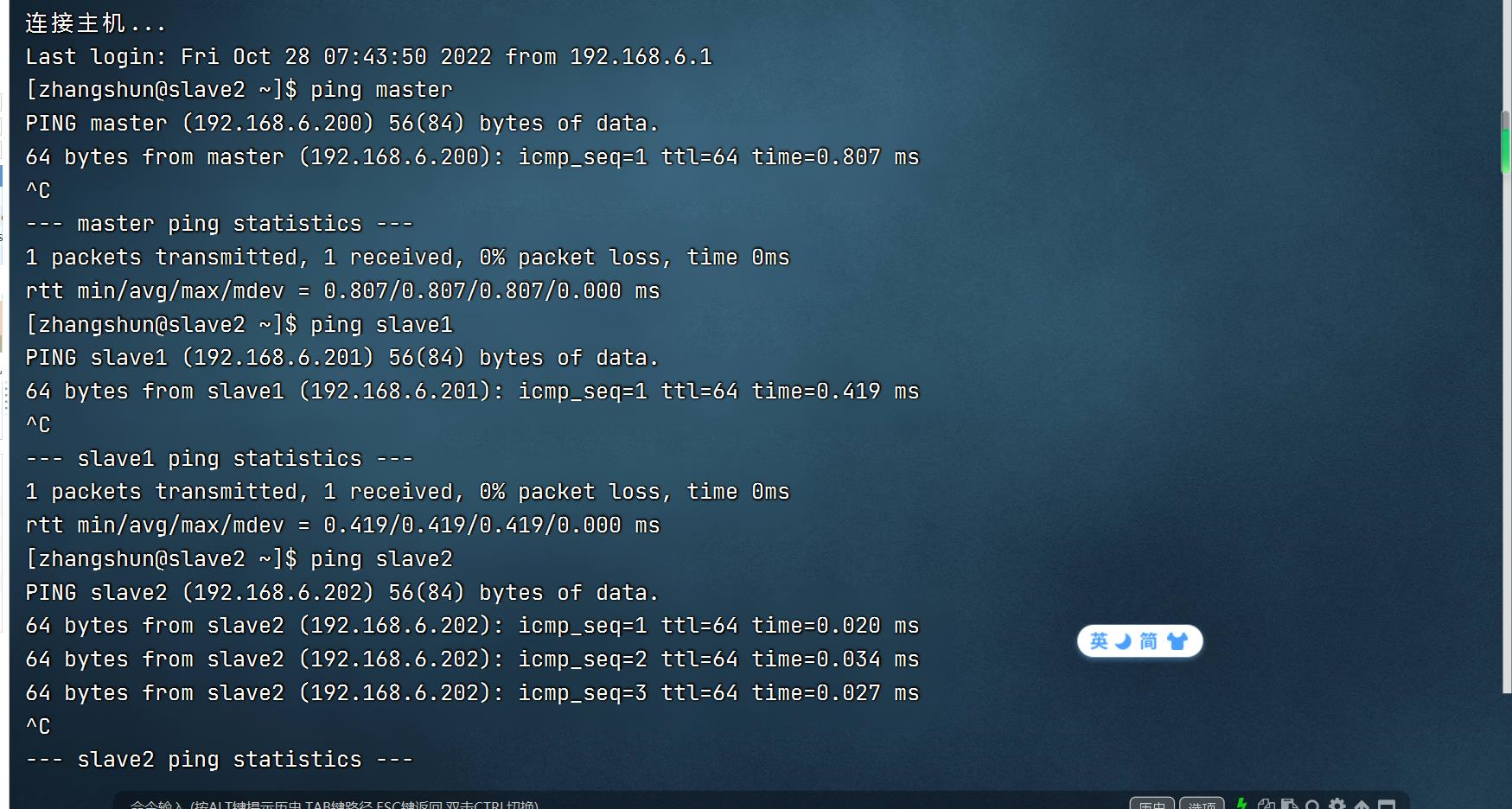
3.互ping测试

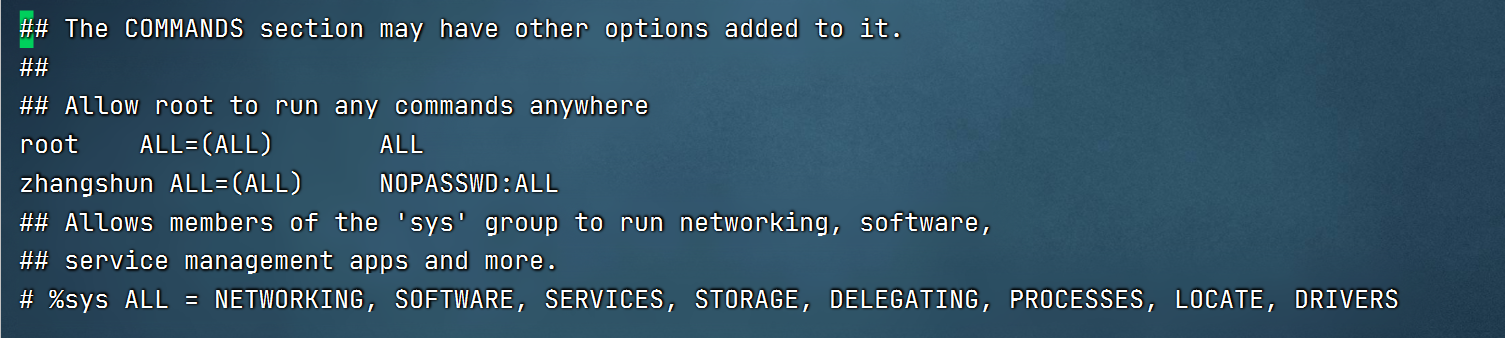
4.sudo授权
5.安装vim编辑器

6.配置网络映射
master配置映射
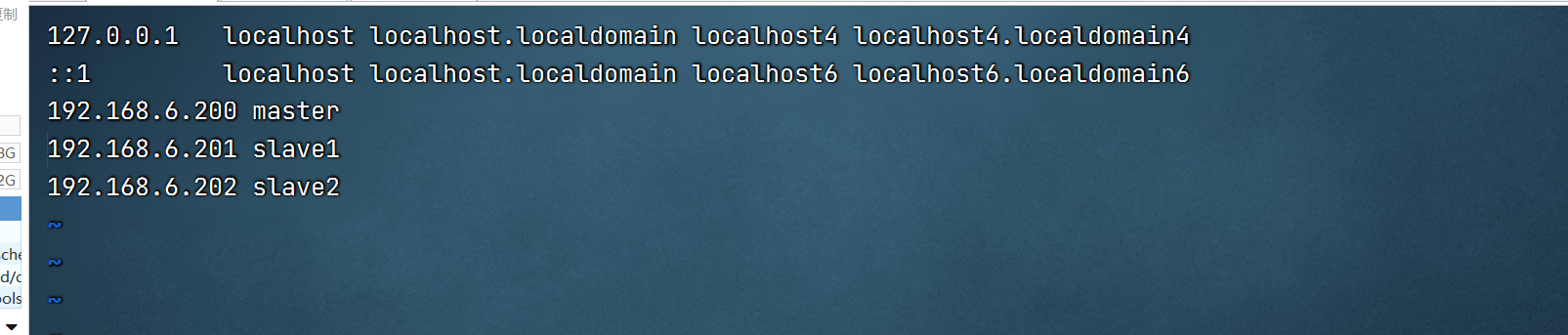
master向slave1传递映射配置
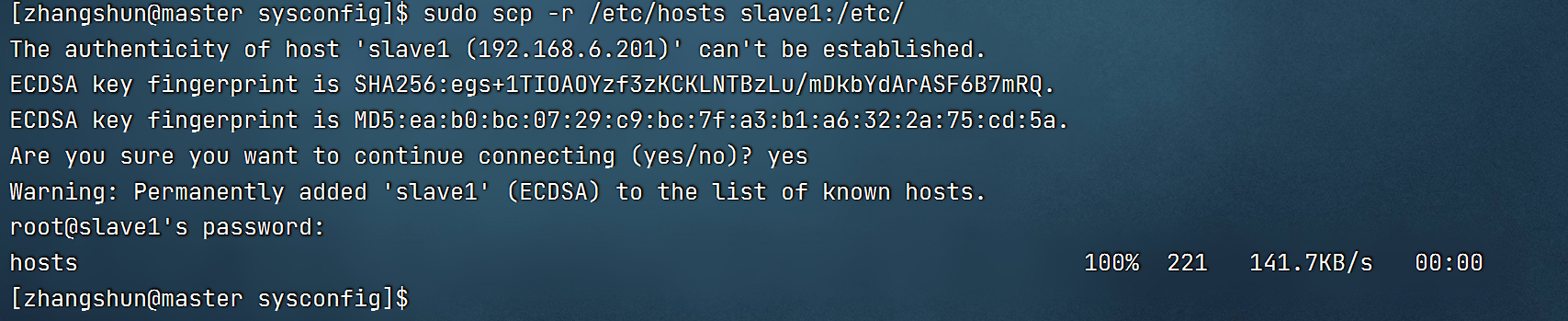
master向slave2传递映射配置
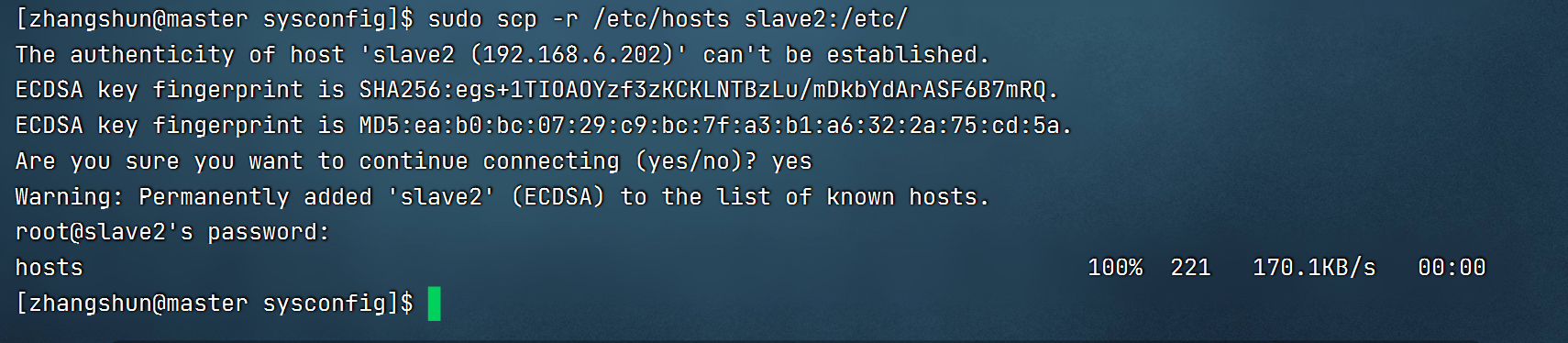
7.配置免密
master配置免密
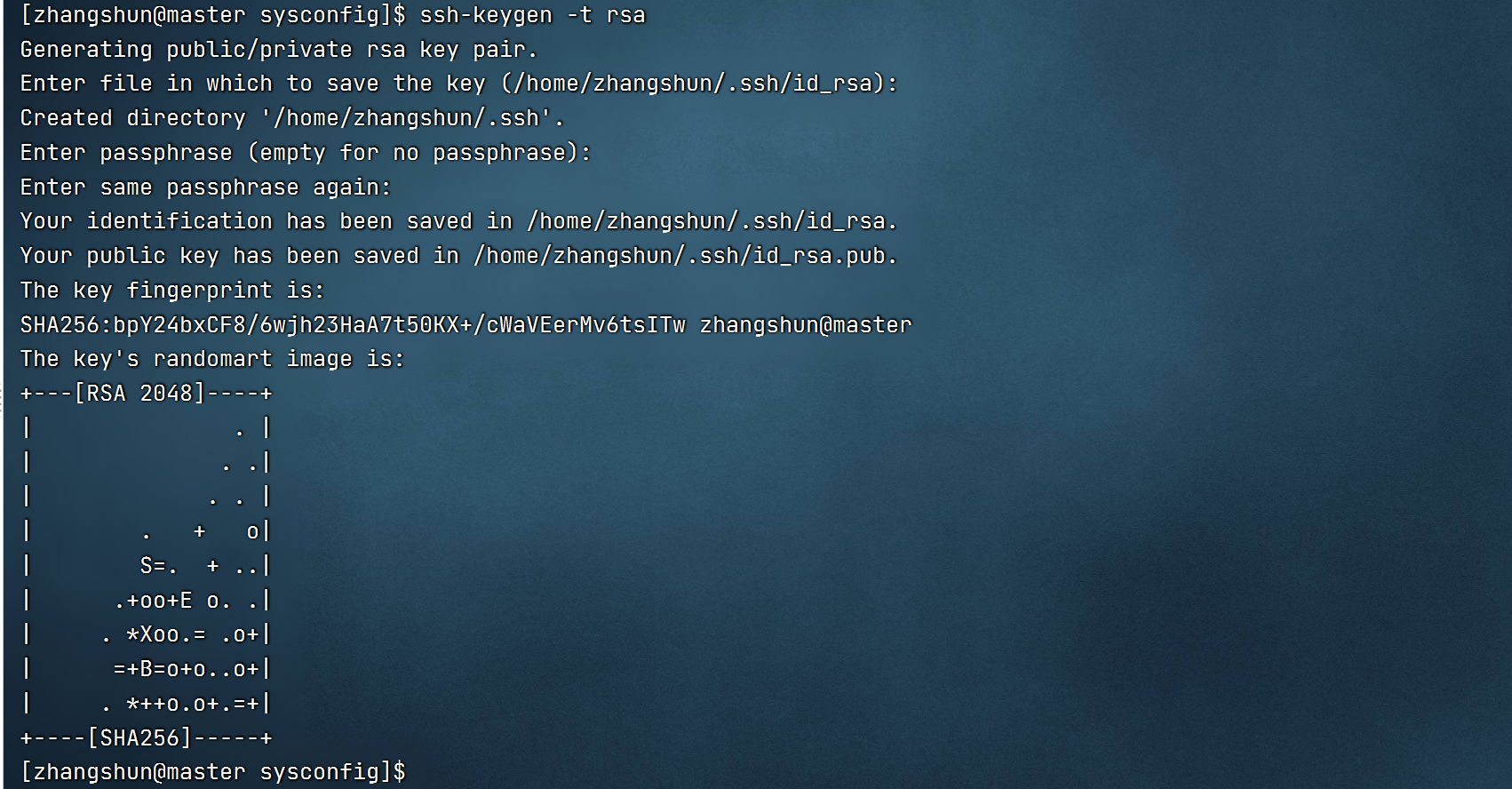



免密验证

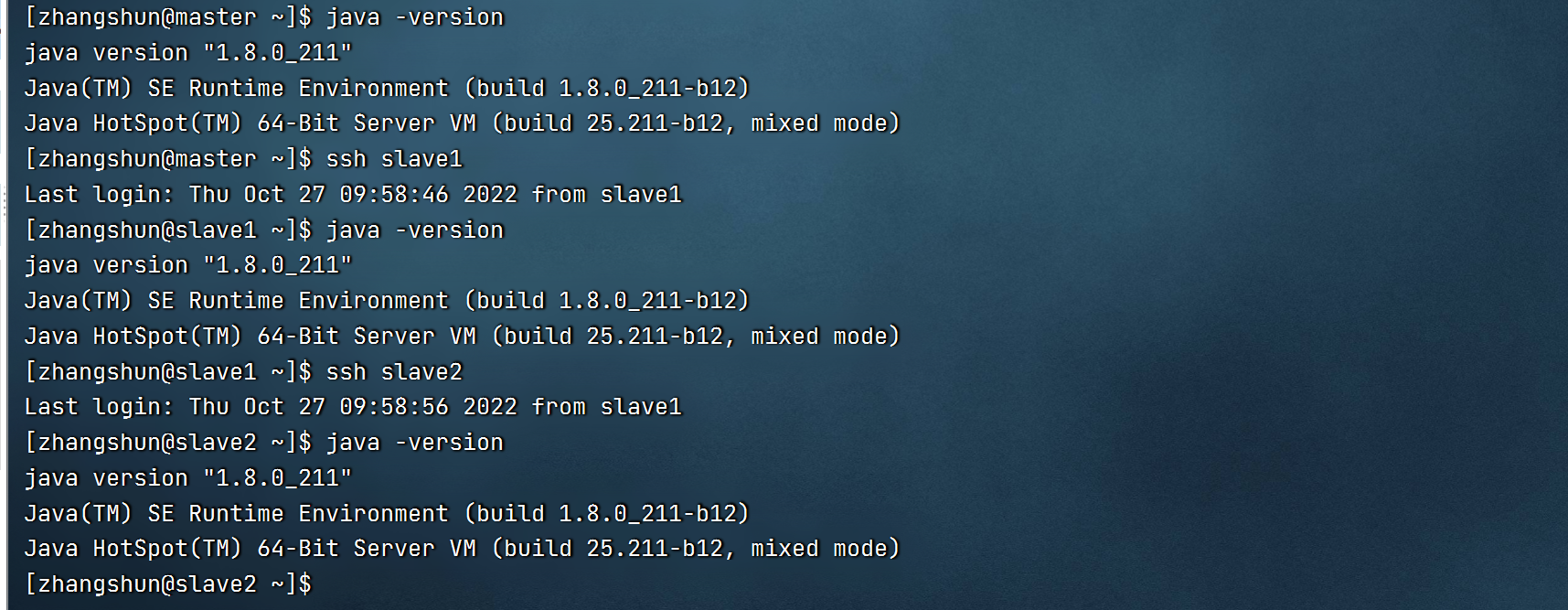
二.配置 JAVA 环境
三.配置zookeeper
1.配置zoo.cfg的配置文件

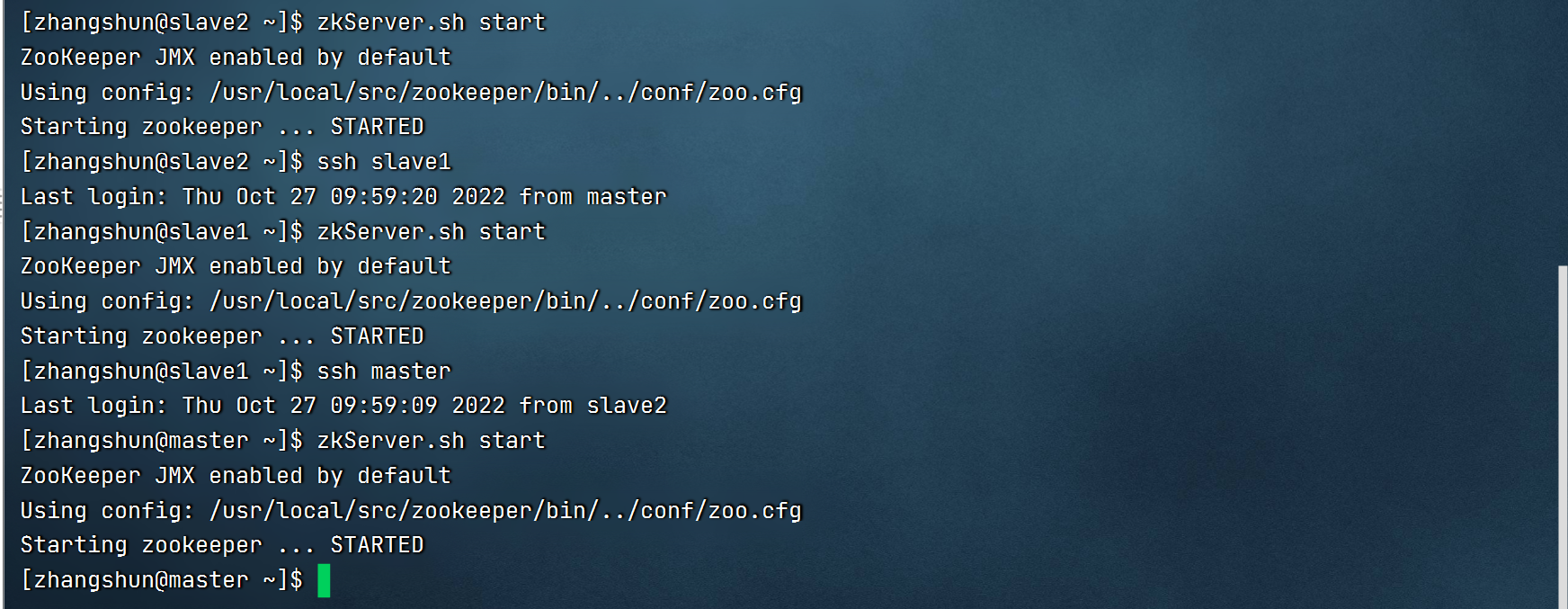
2.启动zookeeper
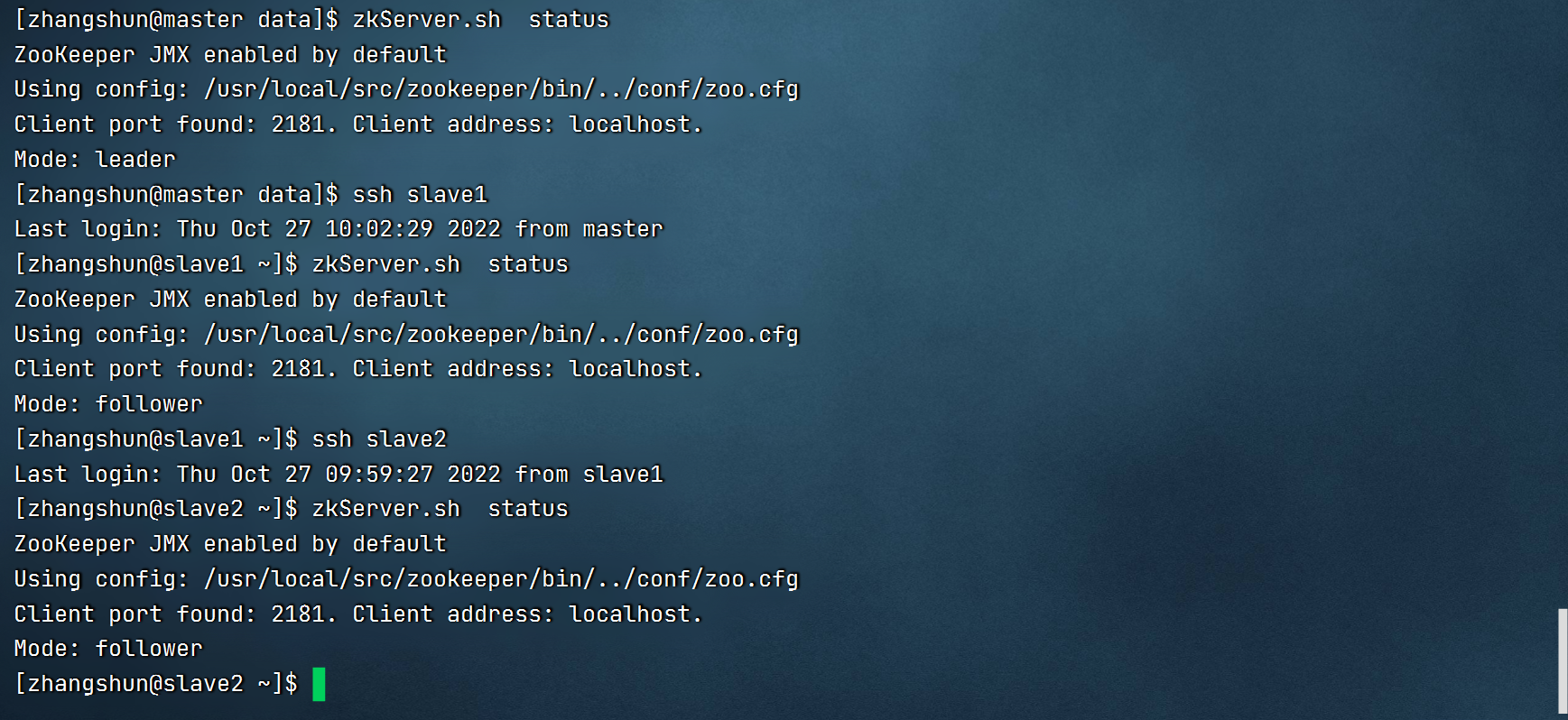
3查看集群状态
四.配置Hadoop集群
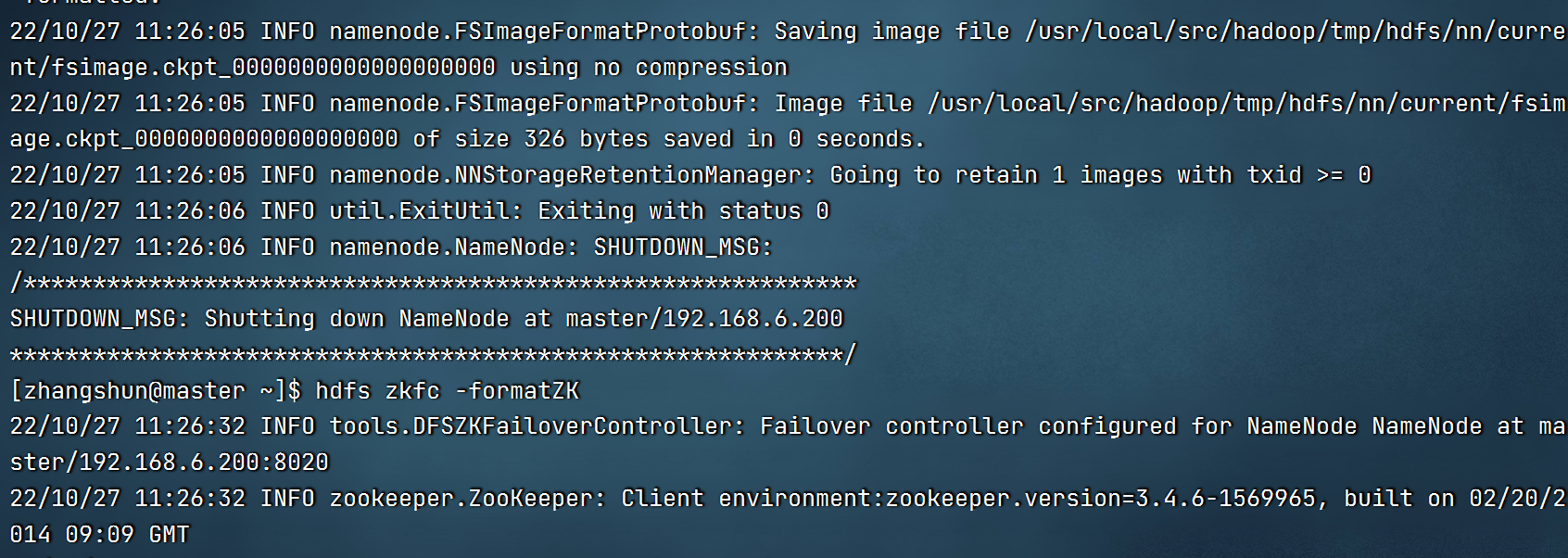
1.格式化hadoop集群
2.master节点

3.slave1节点

4.slave2节点

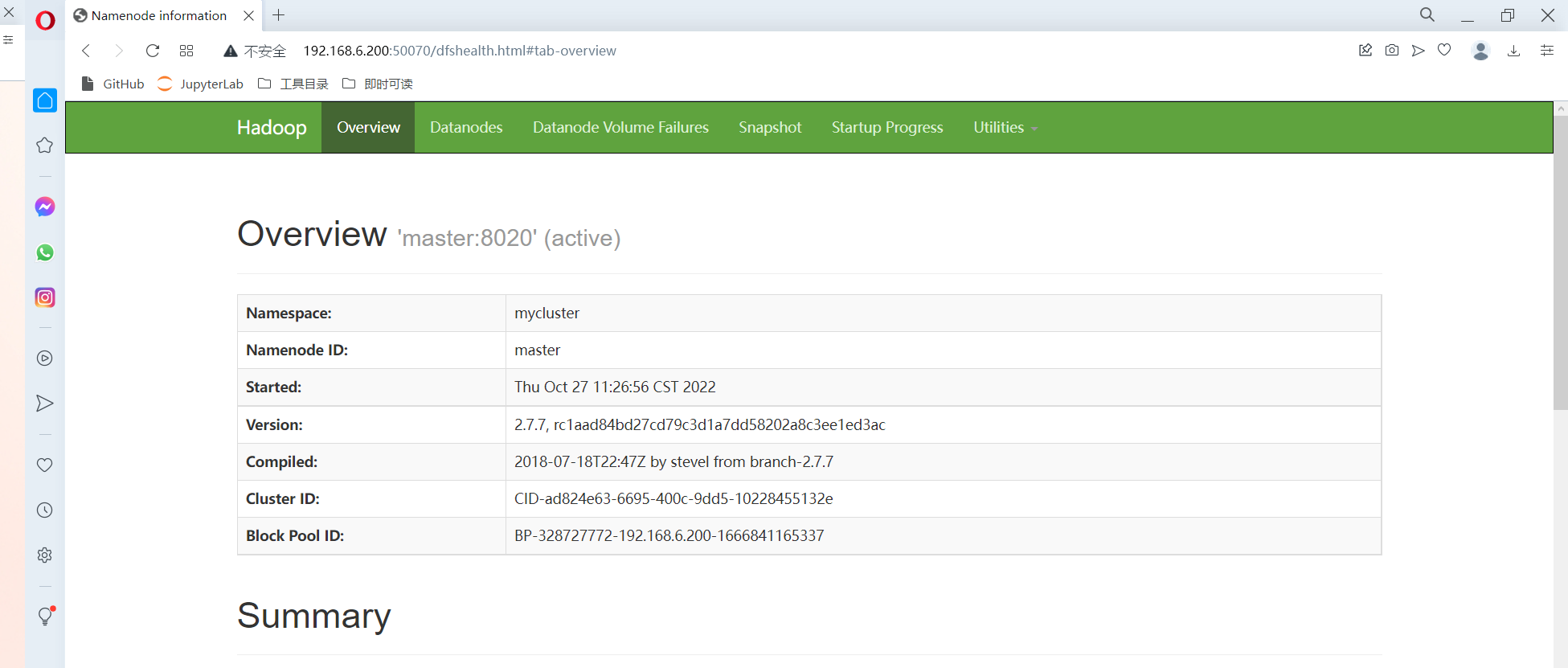
5.50070web端口访问
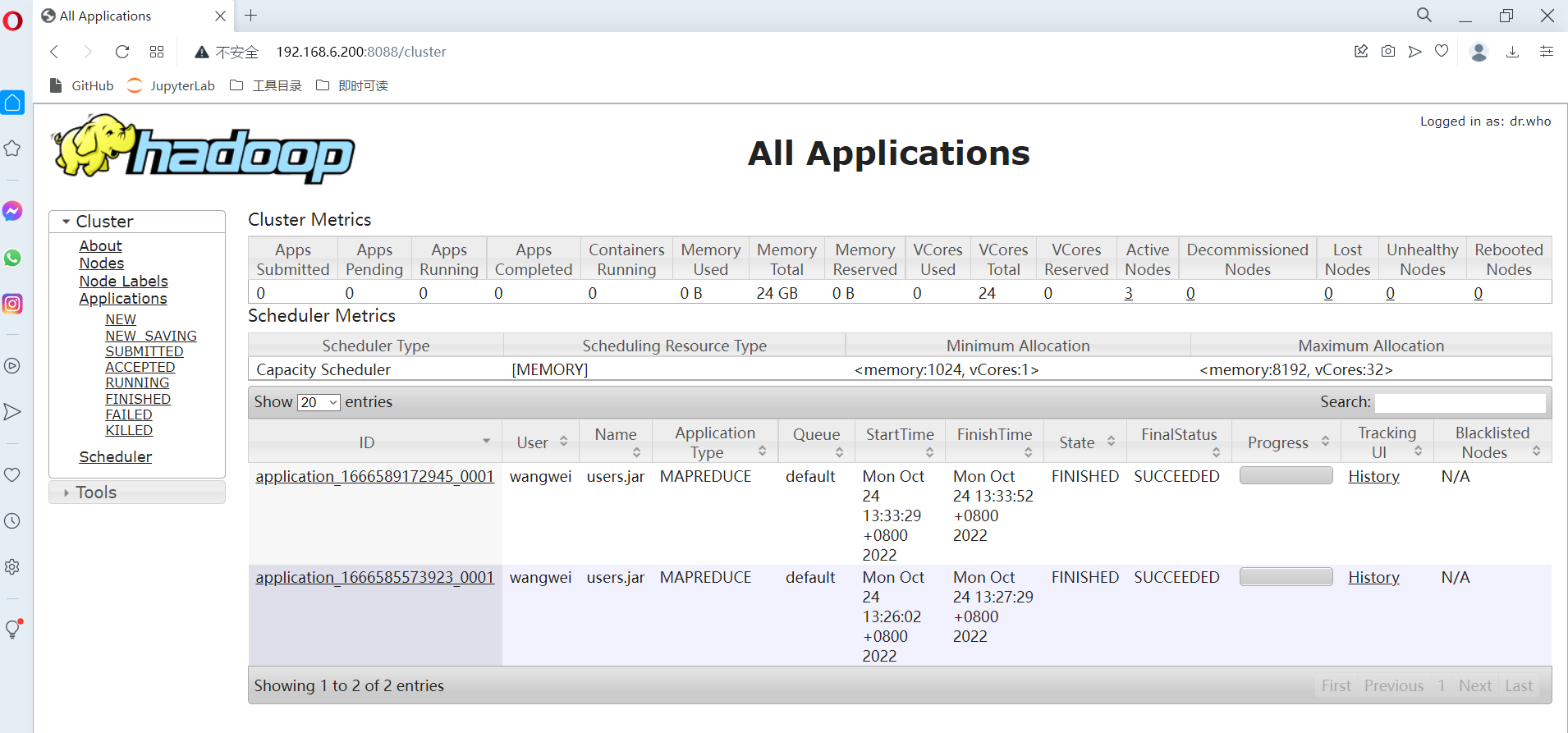
6.8088端口访问
7.计数测试

五.安装hbase存储管理系统
1.启动hbase查看节点信息

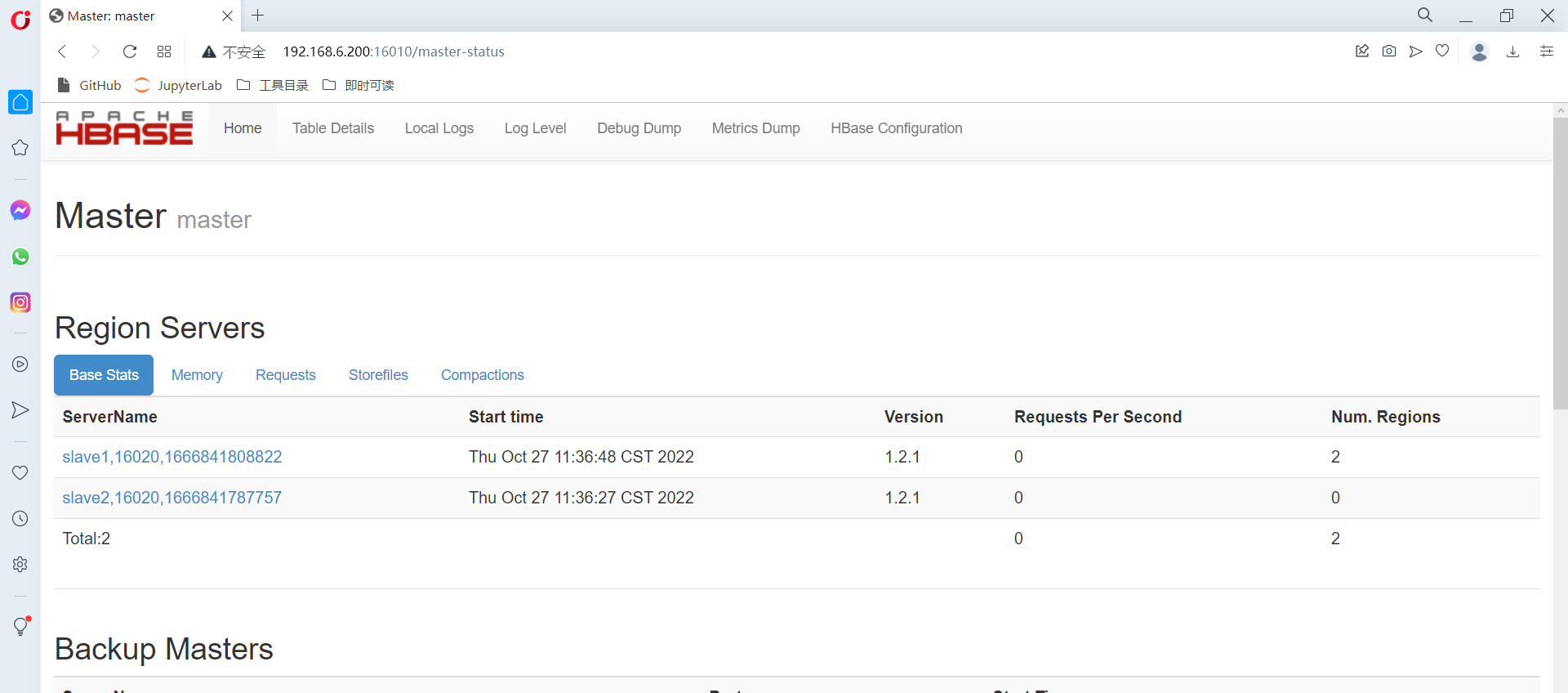
2.查看web UI 界面
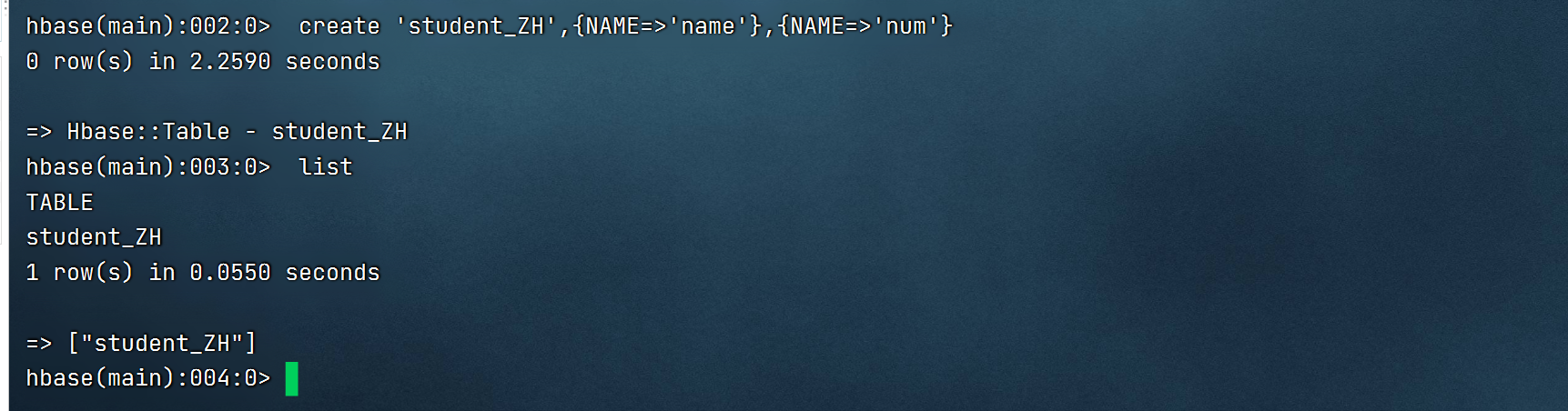
3.创建hbase表

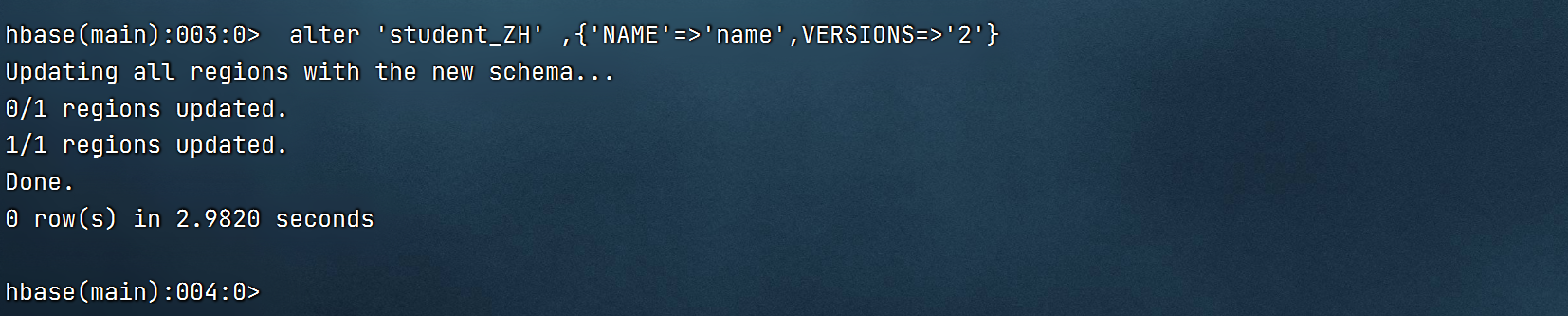
4.修改数据表


5.删除表


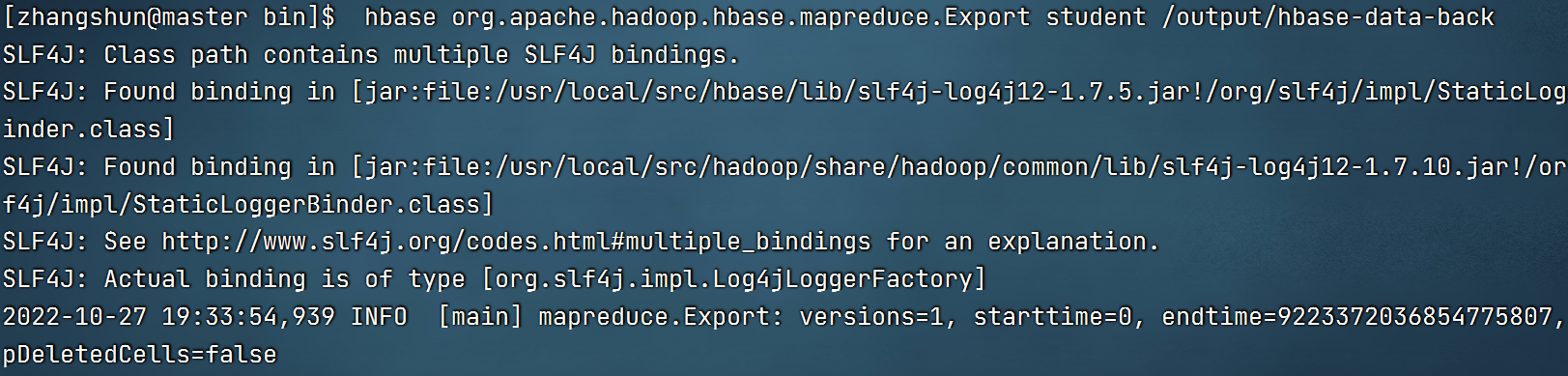
6.导出数据
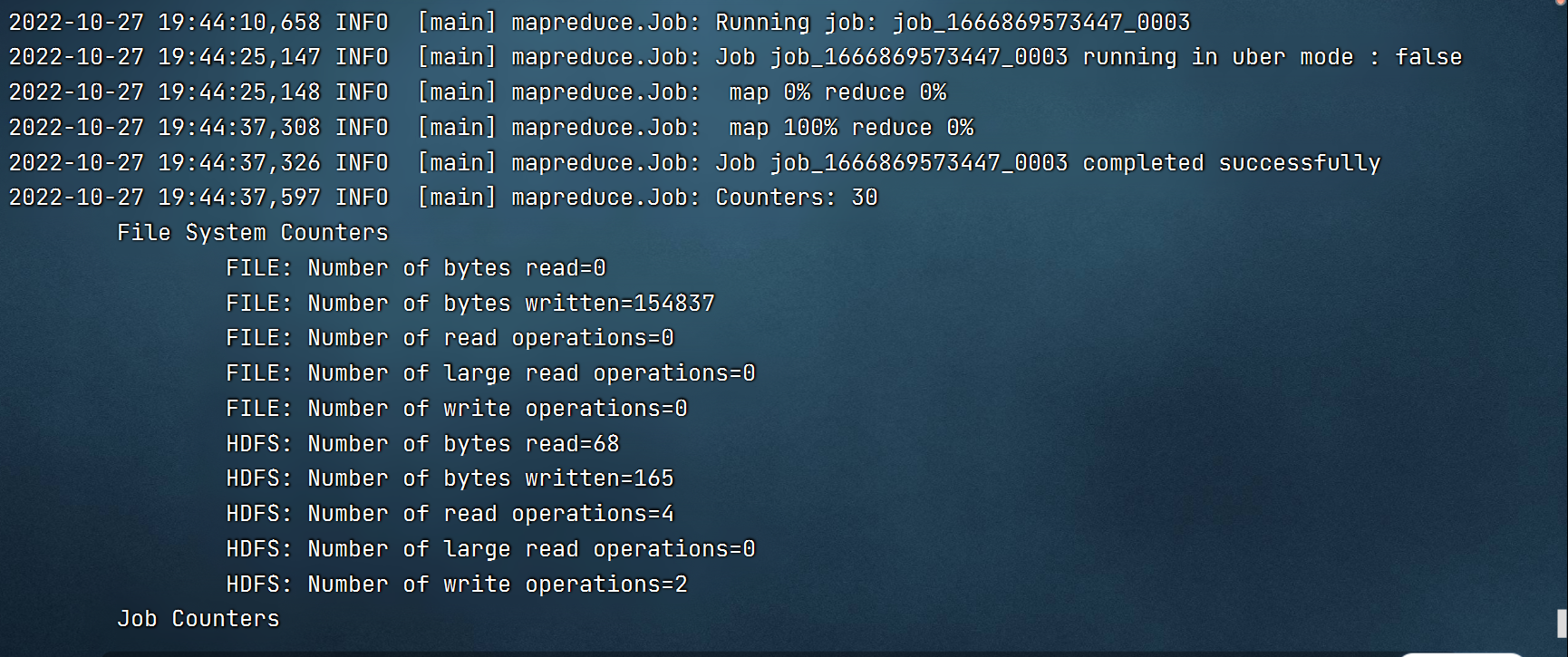
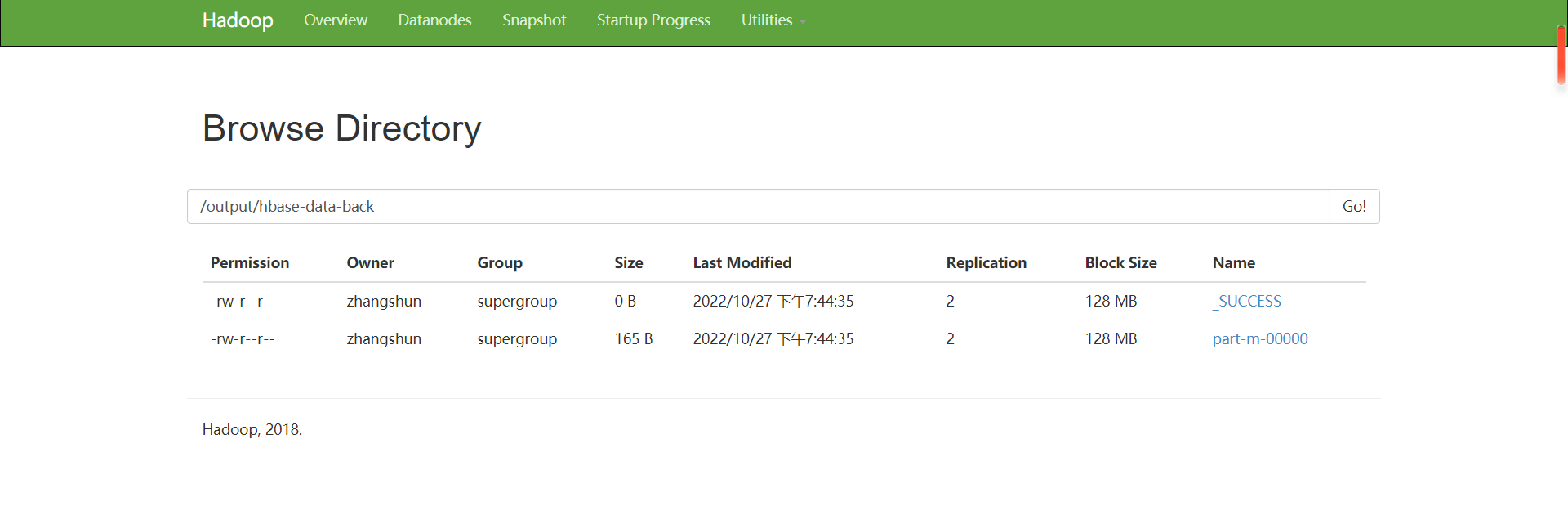
7.数据导出
六.MySQL环境配置
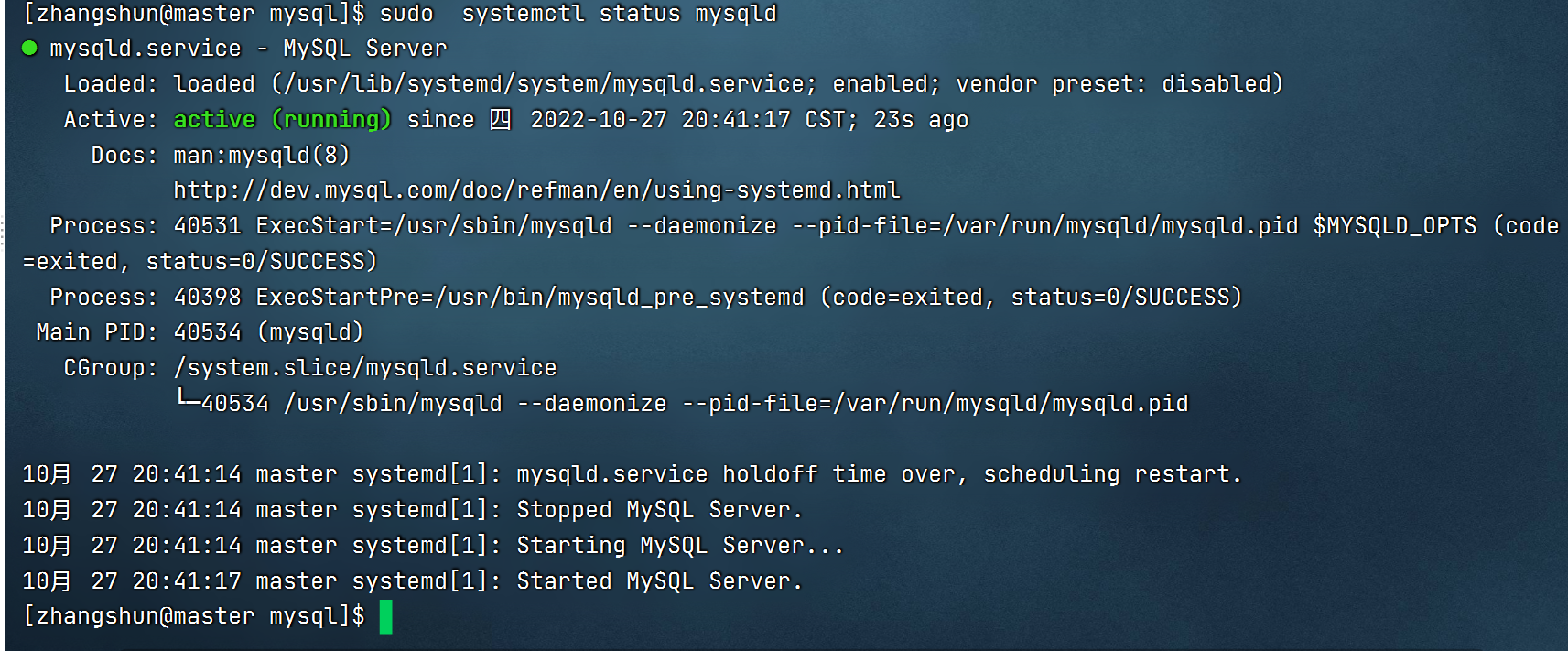
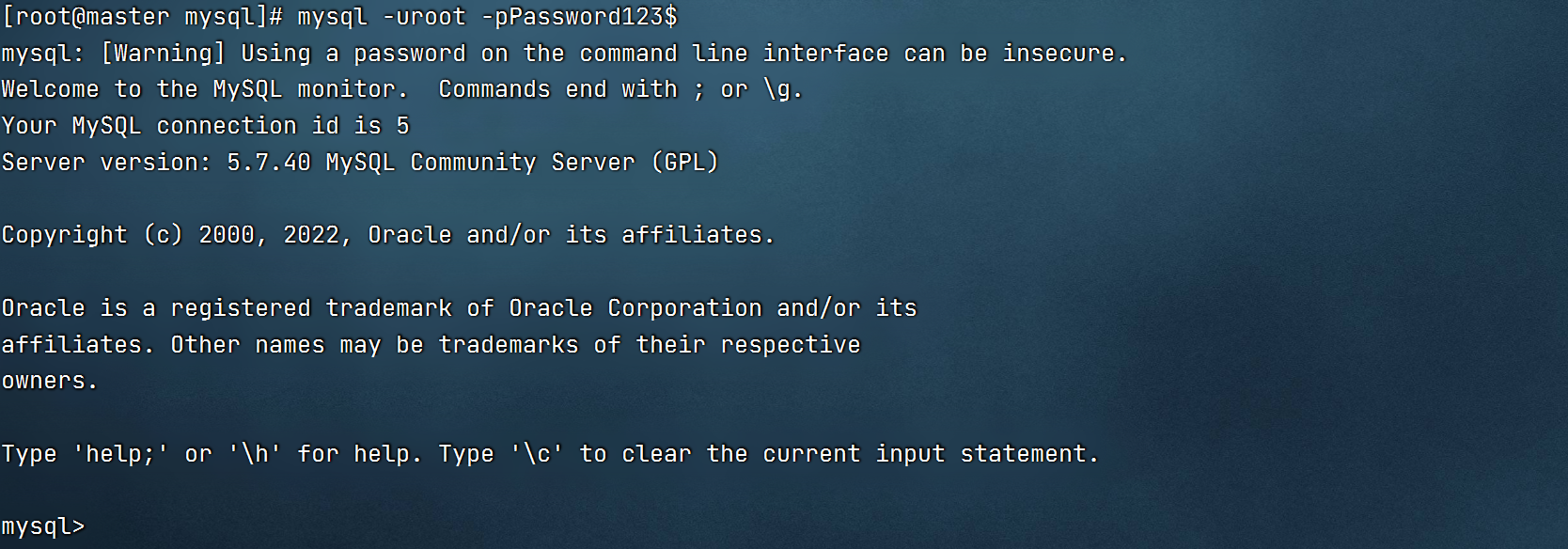
1.数据库测试
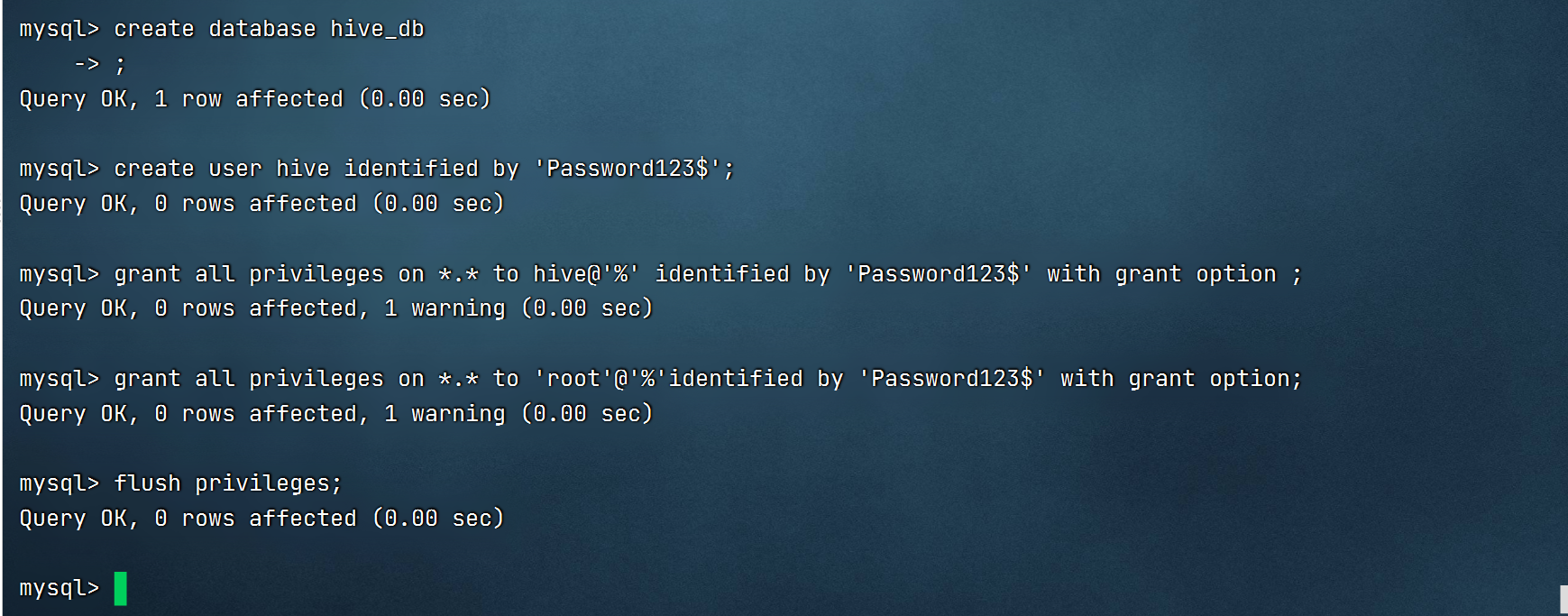
2.新建 Hive 用户与元数据
七.配置 hive
1.启动hive

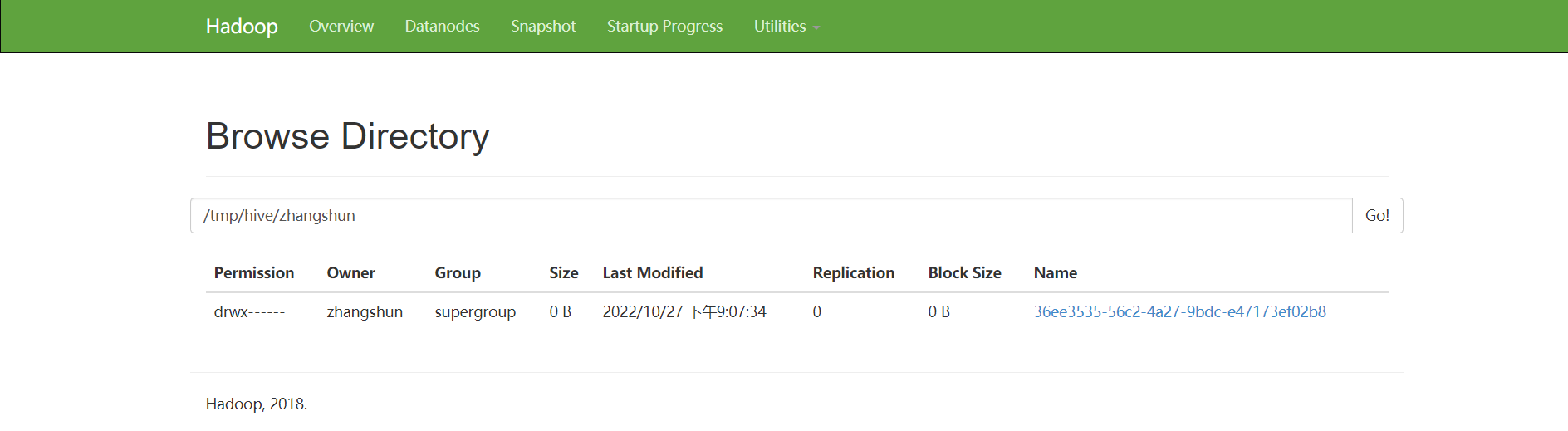
2.Hive 表操作

八.sqoop的导入导出
1.sqoop版本
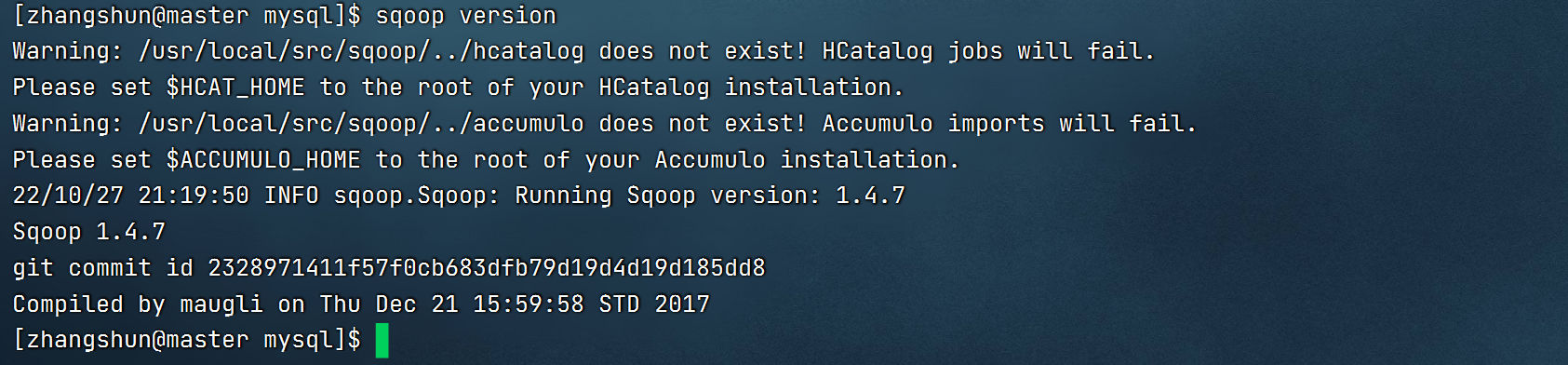
2.创建数据库以及数据表

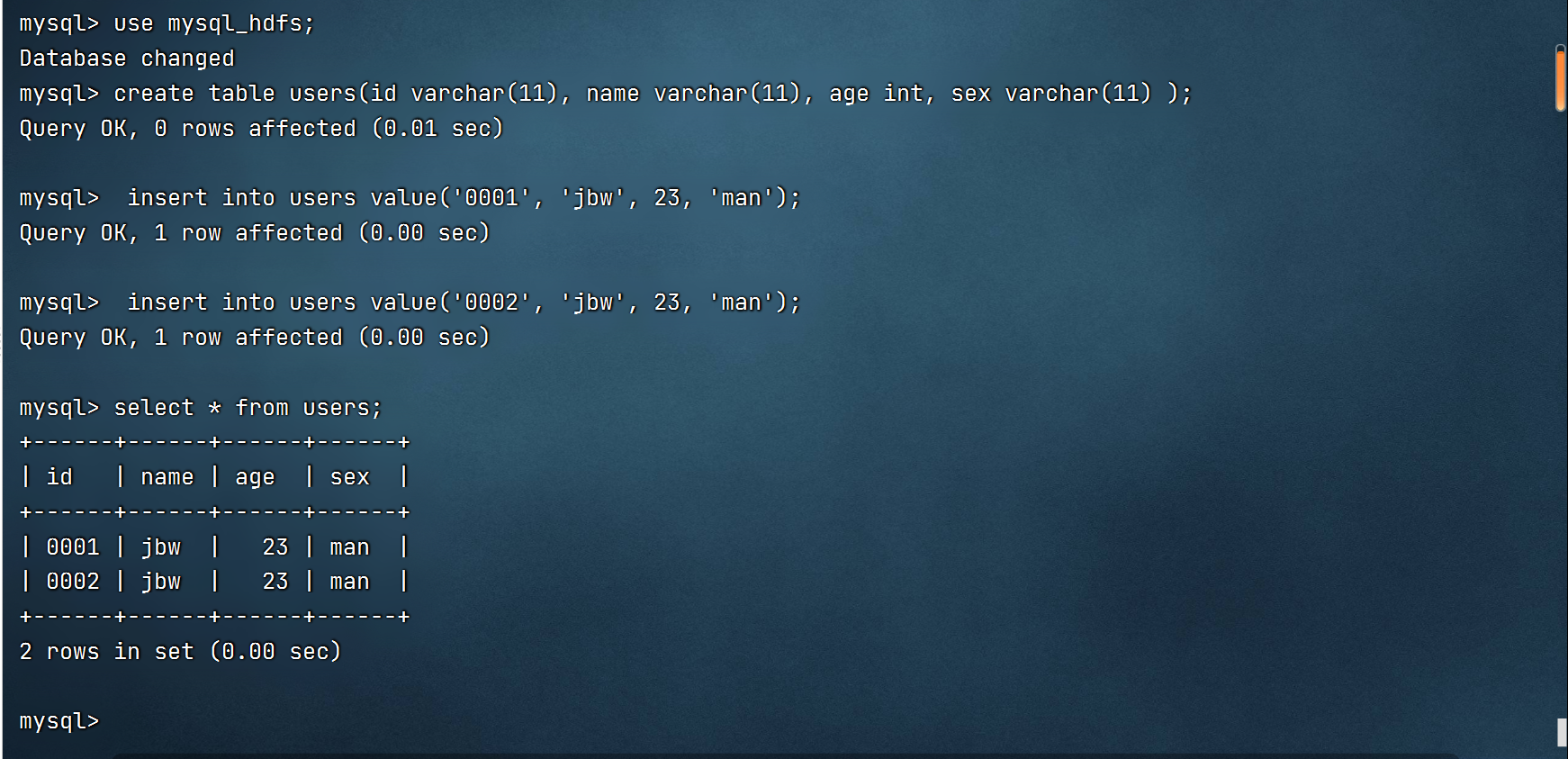
3.数据导入到HDFS


4.hdfs 上的数据导出到 mysql 表中

5.导出数据


九.flume安装配置
1.创建配置文件
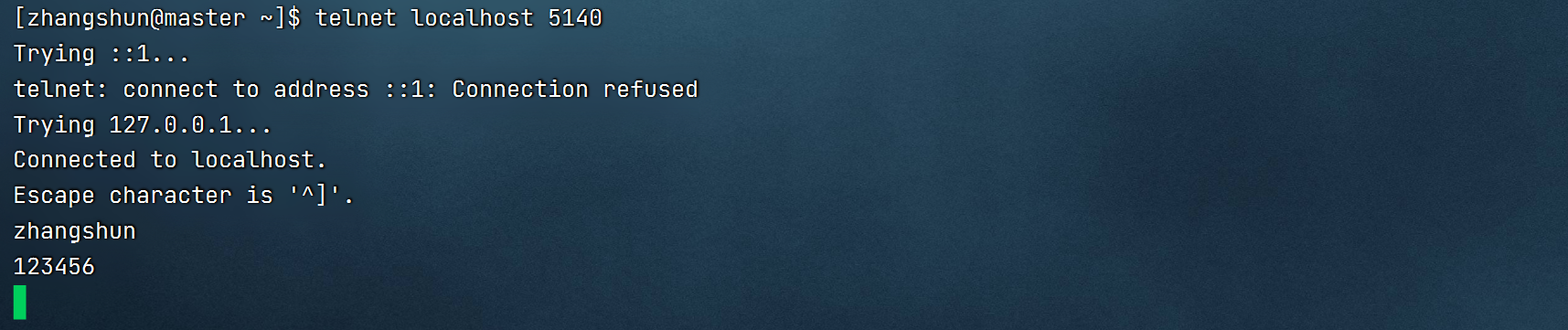
2.安装telnet接口测试

3.数据测试

十.kafka部署
1.查看主题

2.消费者和生产者互动


十一.安装Scala
1.环境验证

十二.安装spark
1.文件上传

2.以集群模式运行 SparkPi 实例程序

3.在spark-shell上运行一个WordCount案例