1、 RNN模型简介




1.2传统RNN模型
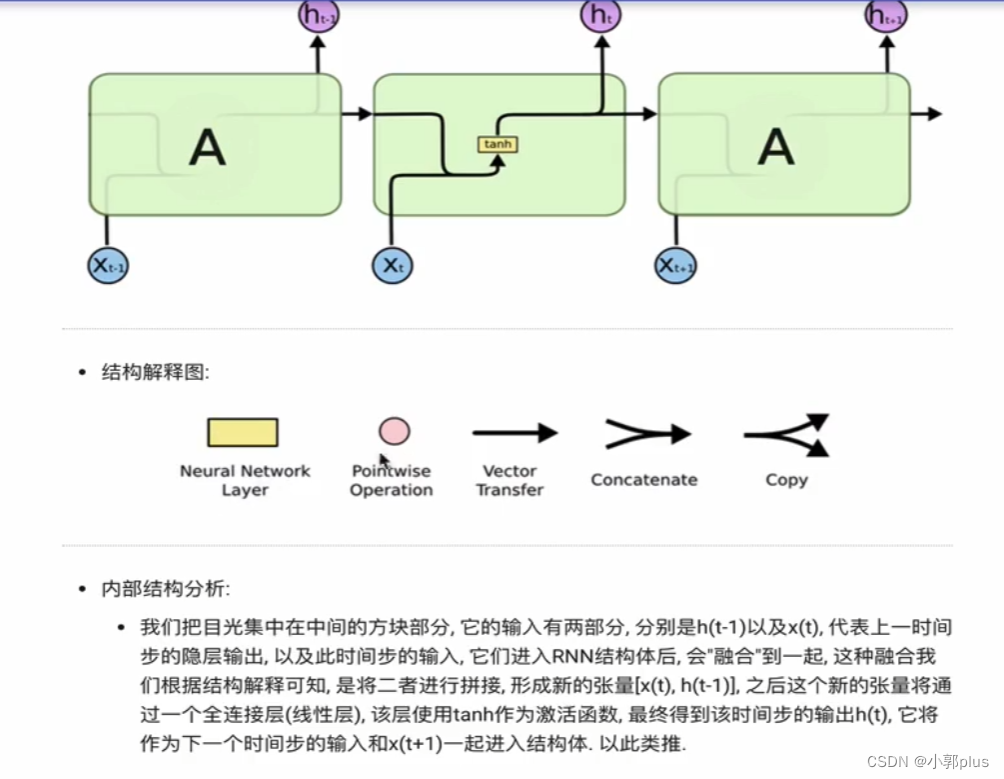
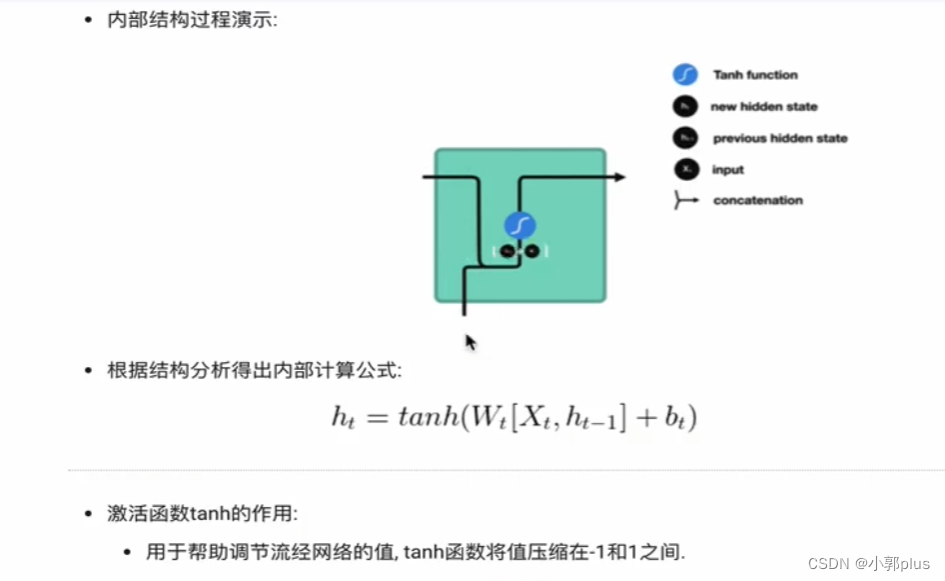





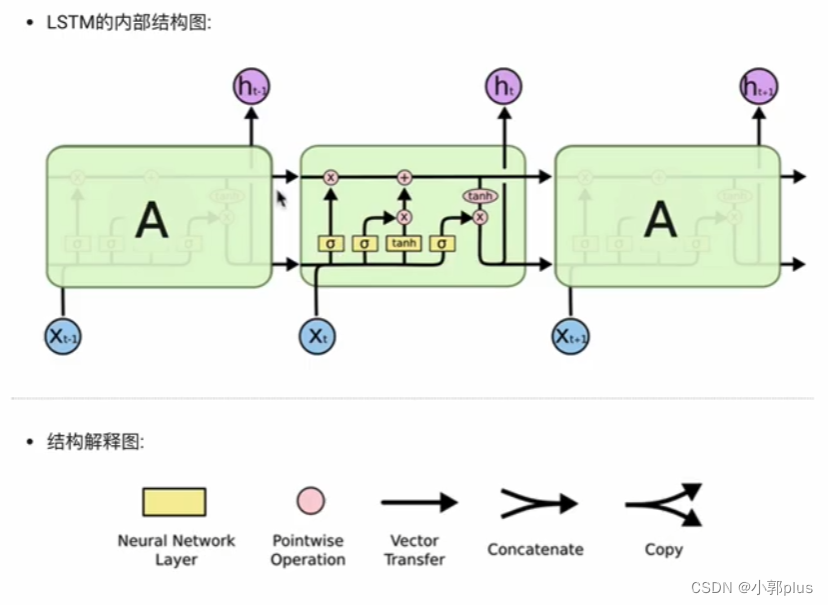
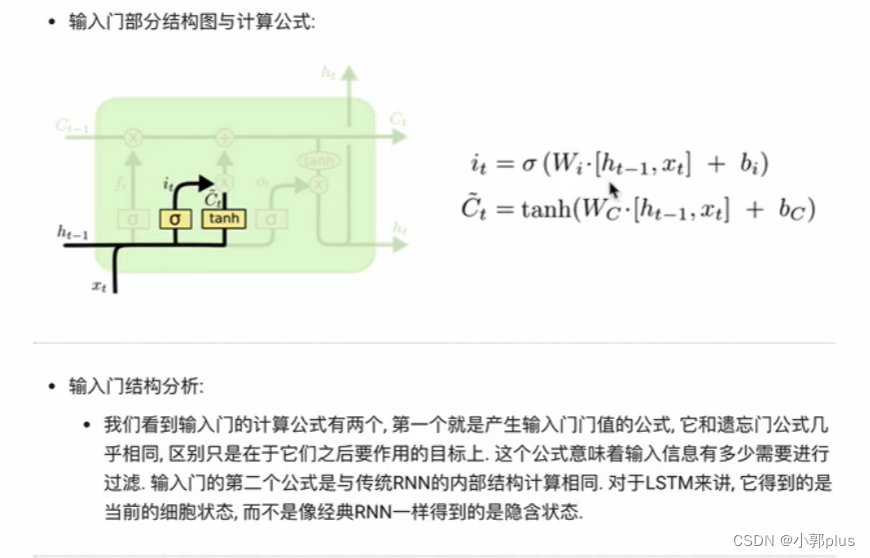
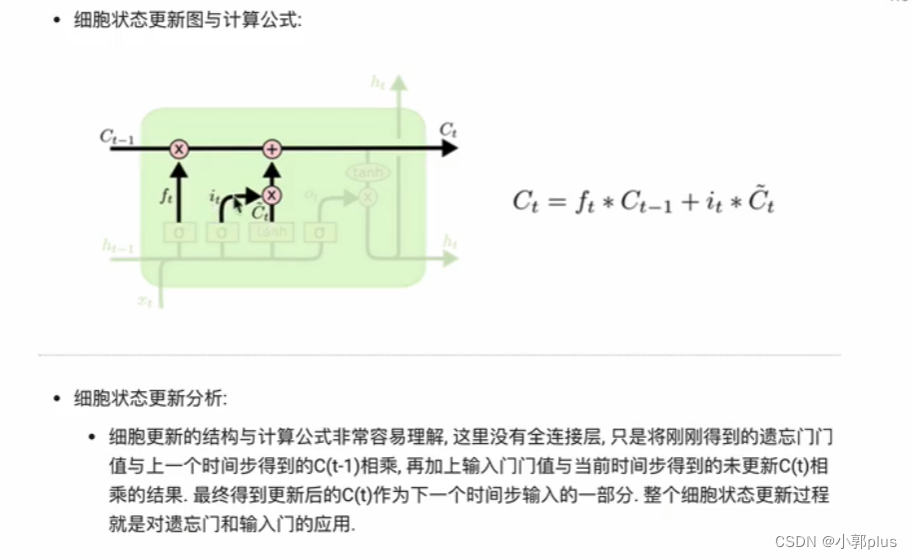
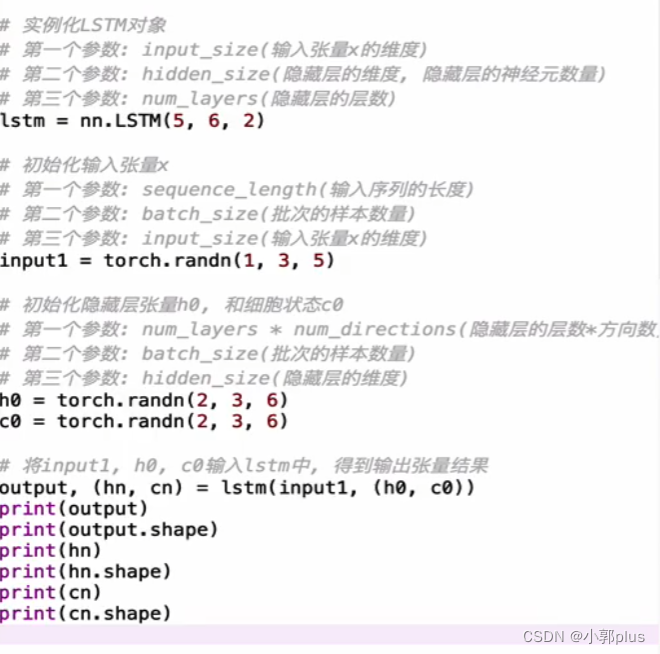
2、LSTM模型







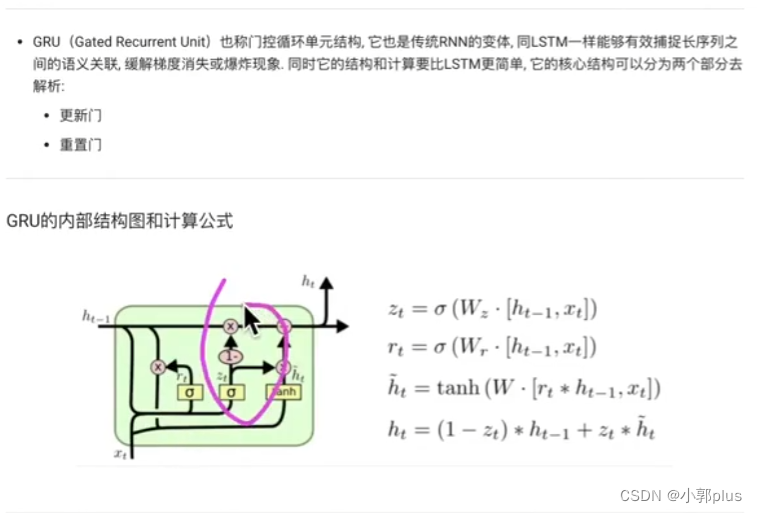
3、GRU模型




5、注意力机制





6、人名分类器

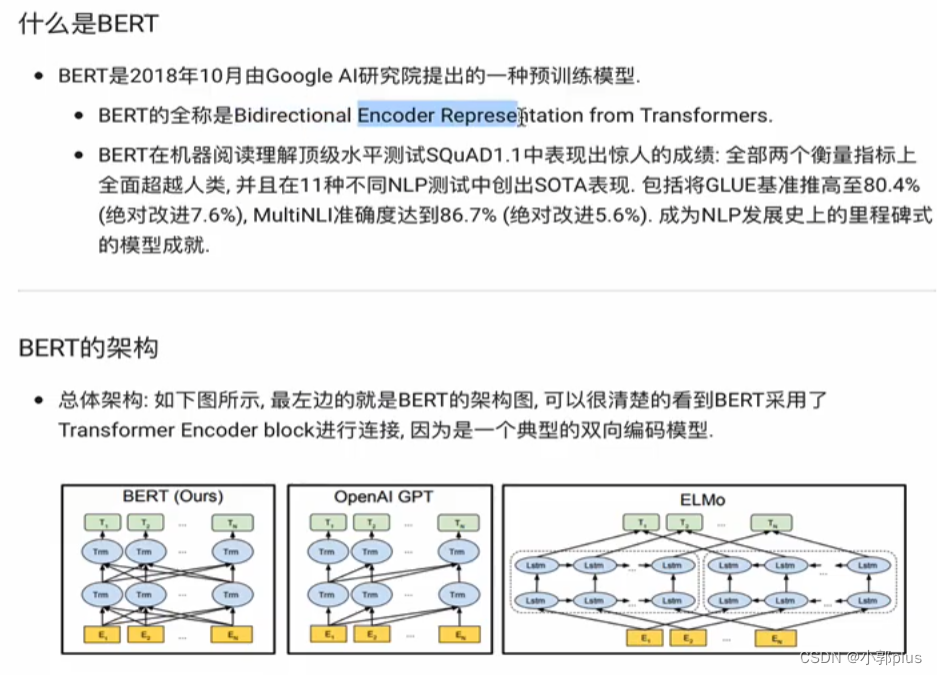
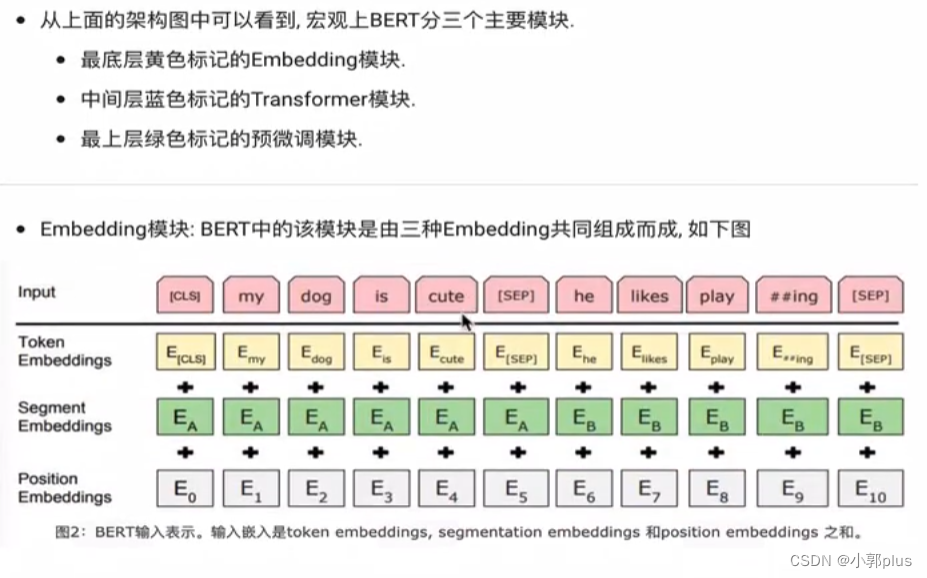
7 、BERT


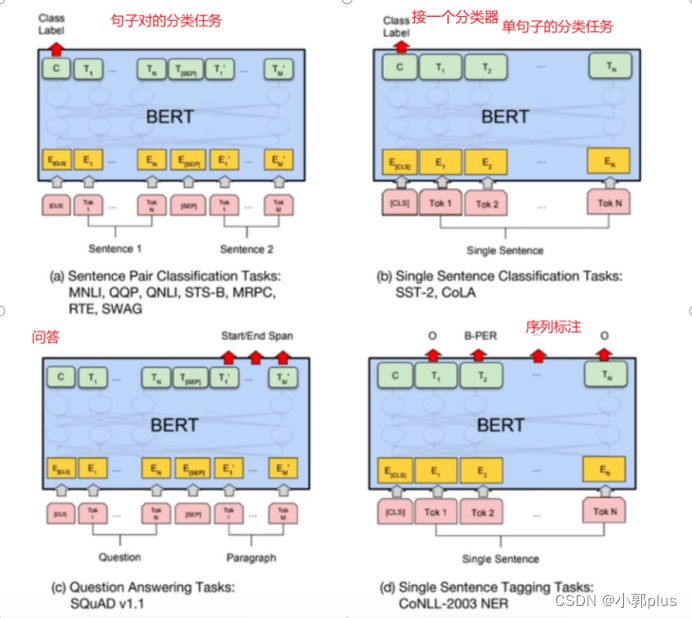





8、Transformer 的结构是什么样子的? 各个子模块有什么作用?
8.1 Encoder模块



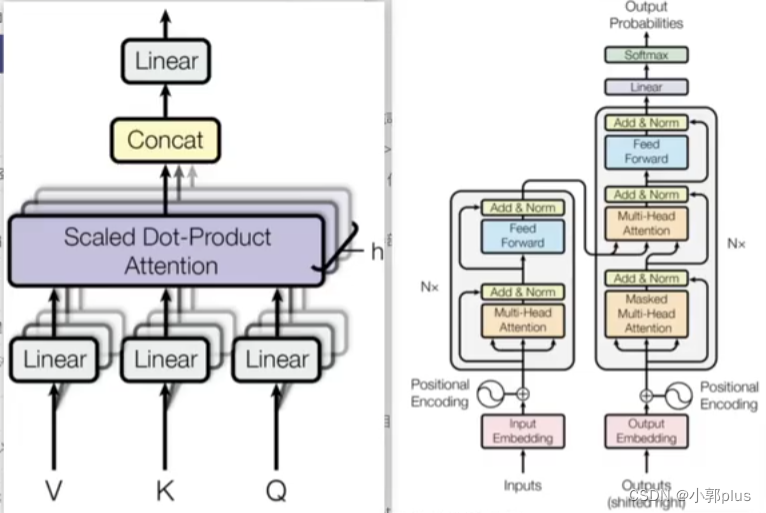
8.2 Decoder模块







8.3 Transformer 结构中的Decoder端具体输入是什么? 在训练阶段和预测阶段一致吗?



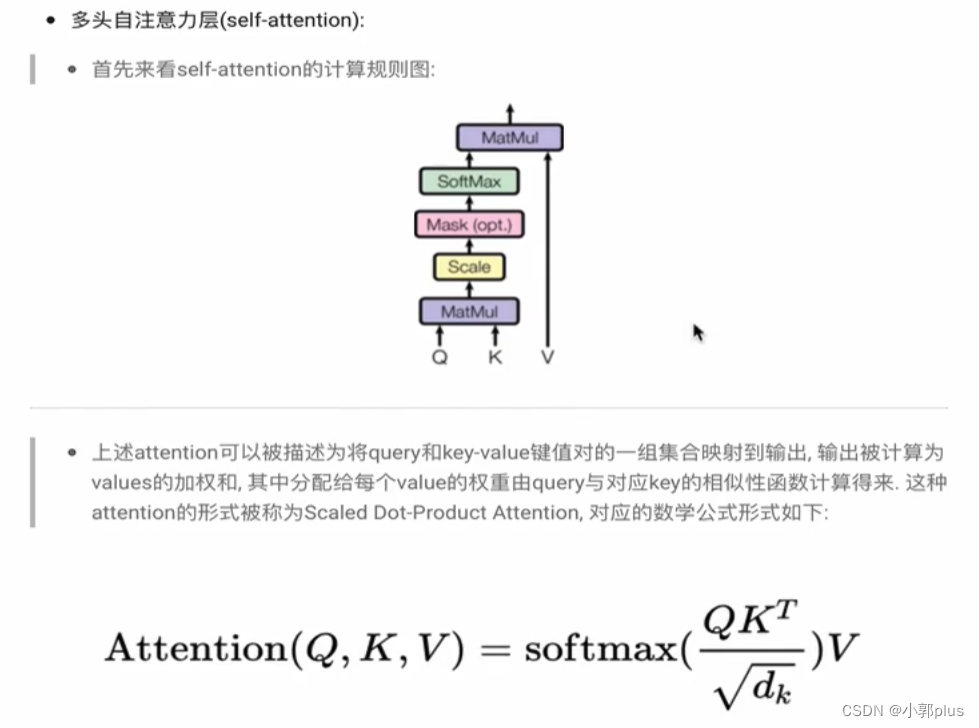
8.4 Transformer中一直强调的self-attention是什莫?为什么能发挥如此大的作用?计算的时候如果不使用三元组(Q,K,V),而仅仅使用(Q,V)或者(K,V)或者(V)行不行、




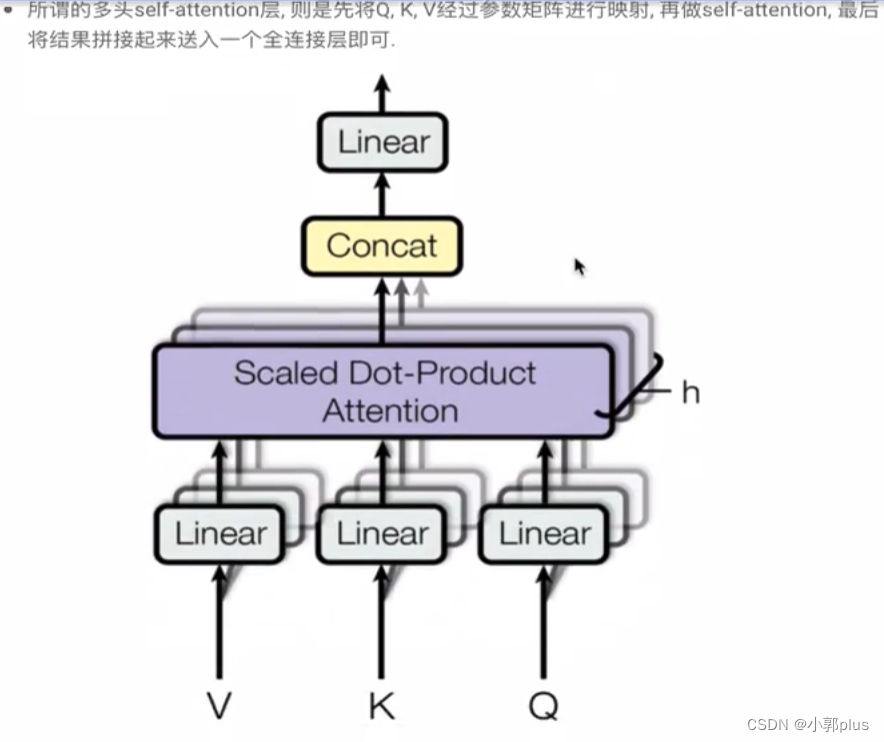
8.5 Transformer 为什莫需要进行Multi-Head Attention? Multi-head Attention 的计算过程是什莫?



8.6 Transformer 相比于RNN/LSTM有什莫优势?为什莫?


8.7 为什么说Transformer可以替代seq2seq?

8.8 self-attention公式中的归一化有什莫作用?为什么要添加scaled

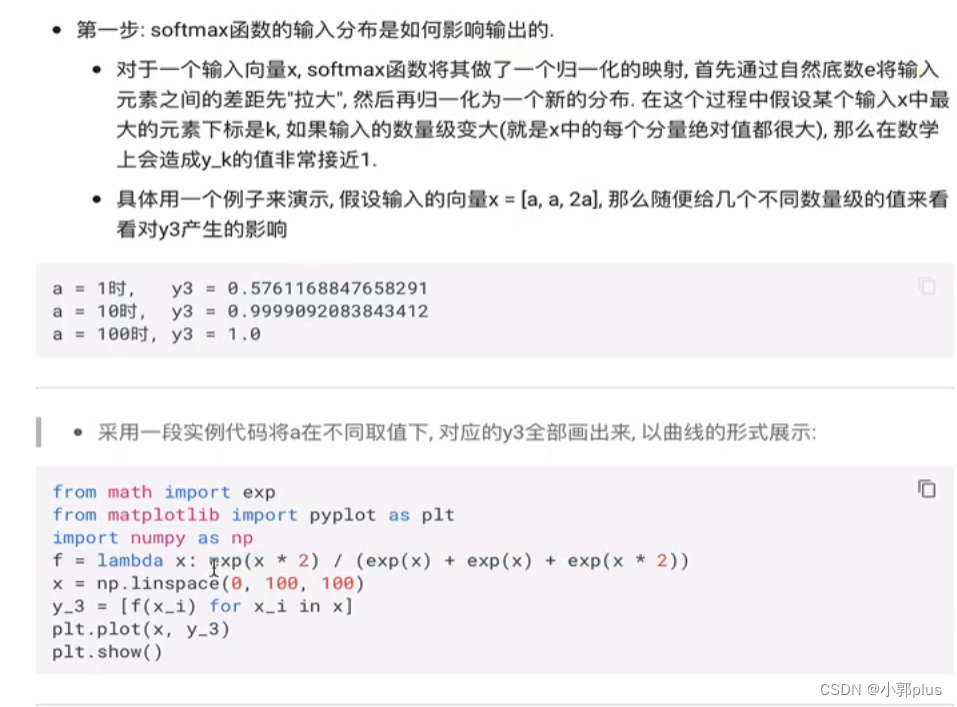
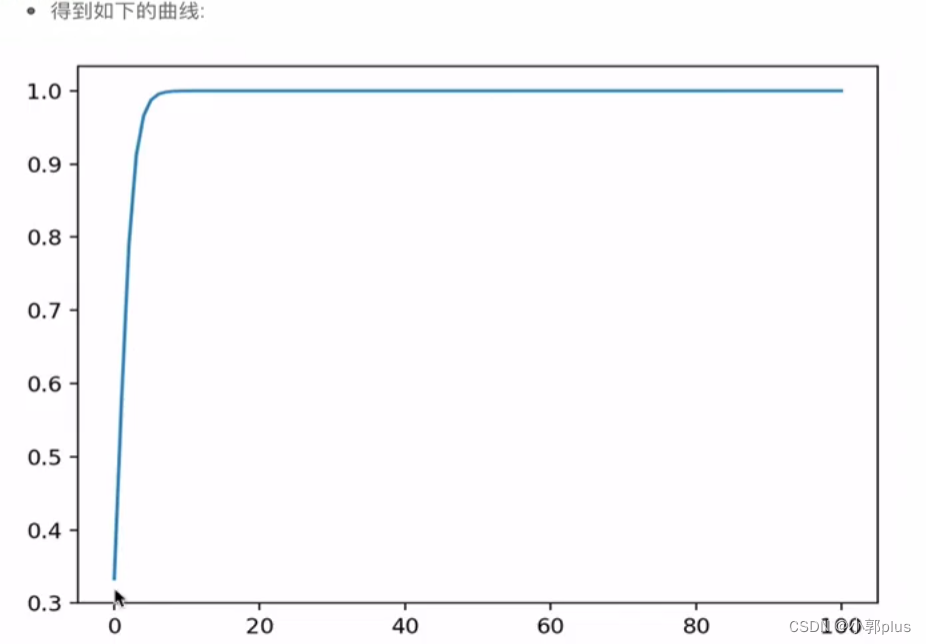








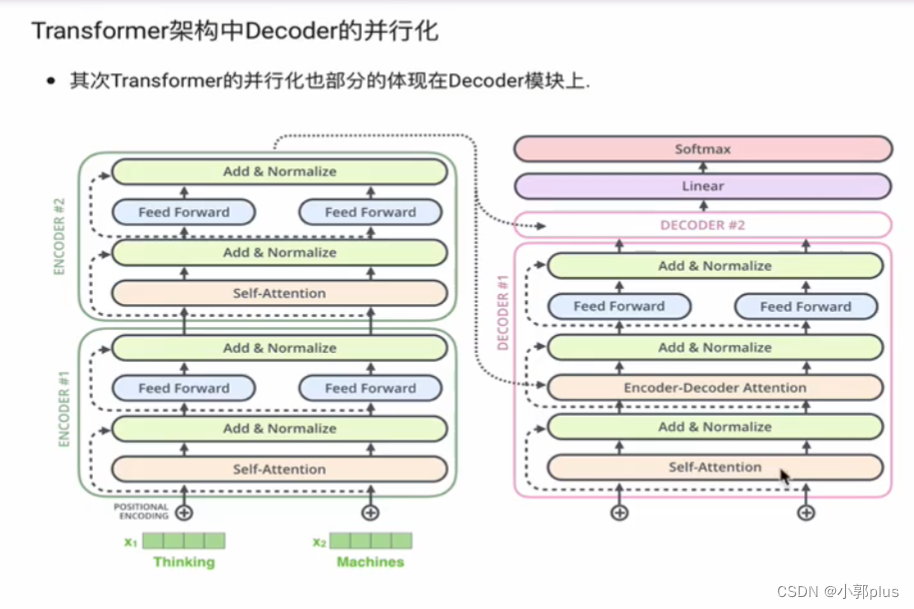
8.8 Transformer 架构的并行化如何进行的?具体体现在在哪?



8.10 BERT 模型的优点和缺点


8.11 BRET 的MLM任务中为什么采用了80%,10%,10%的策略?


8.11 长文本预测任务如果想用BERT来实现,如何构造训练样本?