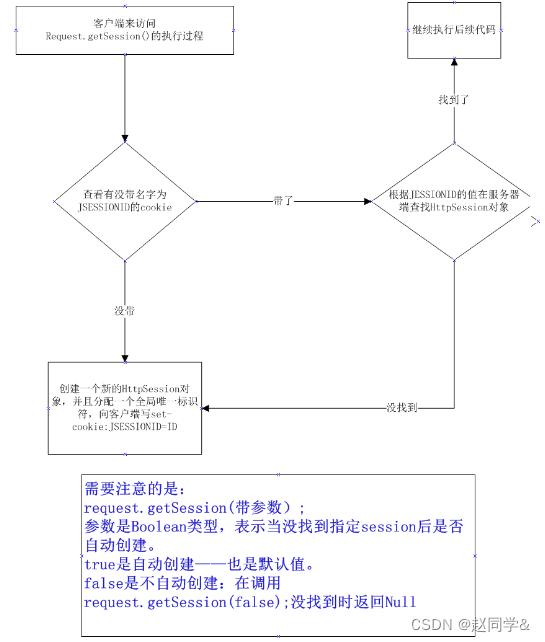
DDPM技术小结 (denoising diffusion probabilistic)
1 从直觉上理解DDPM
在详细推到公式之前,我们先从直觉上理解一下什么是扩散
对于常规的生成模型,如GAN,VAE,它直接从噪声数据生成图像,我们不妨记噪声数据为 z z z,其生成的图片为 x x x
对于常规的生成模型:
学习一个解码函数(即我们需要学习的模型)
p
p
p,实现
p
(
z
)
=
x
p(z)=x
p(z)=x
z
⟶
p
x
(1)
z \stackrel{p} \longrightarrow x \tag{1}
z⟶px(1)
常规方法只需要一次预测即能实现噪声到目标的映射,虽然速度快,但是效果不稳定。
常规生成模型的训练过程(以VAE为例)
x
⟶
q
z
⟶
p
x
^
(2)
x \stackrel{q} \longrightarrow z \stackrel{p} \longrightarrow \widehat{x} \tag{2}
x⟶qz⟶px
(2)
对于diffusion model
它将噪声到目标的过程进行了多步拆解。不妨假设一共有
T
+
1
T+1
T+1个时间步,第
T
T
T个时间步
x
T
x_T
xT是噪声数据,第0个时间步的输出是目标图片
x
0
x_0
x0。其过程可以表述为:
z
=
x
T
⟶
p
x
T
−
1
⟶
p
⋯
⟶
p
x
1
⟶
p
x
0
(3)
z = x_T \stackrel{p} \longrightarrow x_{T-1} \stackrel{p} \longrightarrow \cdots \stackrel{p} \longrightarrow x_{1} \stackrel{p} \longrightarrow x_0 \tag{3}
z=xT⟶pxT−1⟶p⋯⟶px1⟶px0(3)
对于DDPM它采用的是一种自回归式的重建方法,每次的输入是当前的时刻及当前时刻的噪声图片。也就是说它把噪声到目标图片的生成分成了T步,这样每一次的预测相当于是对残差的预测。优势是重建效果稳定,但速度较慢。
训练整体pipeline包含两个过程
2 diffusion pipeline
2.1前置知识:
高斯分布的一些性质
(1)如果 X ∼ N ( μ , σ 2 ) X \sim \mathcal{N}(\mu, \sigma^2) X∼N(μ,σ2),且 a a a与 b b b是实数,那么 a X + b ∼ N ( a μ + b , ( a σ ) 2 ) aX+b \sim \mathcal{N}(a\mu+b, (a\sigma)^2) aX+b∼N(aμ+b,(aσ)2)
(2)如果
X
∼
N
(
μ
(
x
)
,
σ
2
(
x
)
)
X \sim \mathcal{N}(\mu(x), \sigma^2(x))
X∼N(μ(x),σ2(x)),
Y
∼
N
(
μ
(
y
)
,
σ
2
(
y
)
)
Y \sim \mathcal{N}(\mu(y), \sigma^2(y))
Y∼N(μ(y),σ2(y)),且
X
,
Y
X,Y
X,Y是统计独立的正态随机变量,则它们的和也满足高斯分布(高斯分布可加性).
X
+
Y
∼
N
(
μ
(
x
)
+
μ
(
y
)
,
σ
2
(
x
)
+
σ
2
(
y
)
)
X
−
Y
∼
N
(
μ
(
x
)
−
μ
(
y
)
,
σ
2
(
x
)
+
σ
2
(
y
)
)
(4)
X+Y \sim \mathcal{N}(\mu(x)+\mu{(y), \sigma^2(x) + \sigma^2(y)}) \\ X-Y \sim \mathcal{N}(\mu(x)-\mu{(y), \sigma^2(x) + \sigma^2(y)}) \tag{4}
X+Y∼N(μ(x)+μ(y),σ2(x)+σ2(y))X−Y∼N(μ(x)−μ(y),σ2(x)+σ2(y))(4)
均值为
μ
\mu
μ方差为
σ
\sigma
σ的高斯分布的概率密度函数为
f
(
x
)
=
1
2
π
σ
exp
(
−
(
x
−
μ
)
2
2
σ
2
)
=
1
2
π
σ
exp
[
−
1
2
(
1
σ
2
x
2
−
2
μ
σ
2
x
+
μ
2
σ
2
)
]
\begin{align} f(x) &= \frac{1}{\sqrt{2\pi} \sigma } \exp \left ({- \frac{(x - \mu)^2}{2\sigma^2}} \right) \nonumber \\ &= \frac{1}{\sqrt{2\pi} \sigma } \exp \left[ -\frac{1}{2} \left( \frac{1}{\sigma^2}x^2 - \frac{2\mu}{\sigma^2}x + \frac{\mu^2}{\sigma^2} \right ) \right] \tag{5} \end{align}
f(x)=2πσ1exp(−2σ2(x−μ)2)=2πσ1exp[−21(σ21x2−σ22μx+σ2μ2)](5)
2.2 加噪过程
1 前向过程:将图片数据映射为噪声
每一个时刻都要添加高斯噪声,后一个时刻都是由前一个时刻加噪声得到。(其实每一个时刻加的噪声就是训练所用的标签)。即
x
0
⟶
q
x
1
⟶
q
x
2
⟶
q
⋯
⟶
q
x
T
−
1
⟶
q
x
T
=
z
(6)
x_0 \stackrel{q} \longrightarrow x_1 \stackrel{q} \longrightarrow x_{2} \stackrel{q} \longrightarrow \cdots \stackrel{q} \longrightarrow x_{T-1} \stackrel{q} \longrightarrow x_T=z \tag{6}
x0⟶qx1⟶qx2⟶q⋯⟶qxT−1⟶qxT=z(6)
下面我们详细来看
记
β
t
=
1
−
α
t
\beta_t = 1 - \alpha_t
βt=1−αt,
β
t
\beta_t
βt随t的增加而增大(论文中1时从0.0001 -> 0.02) (这是因为一开始加一点噪声就很明显,后面需要增大噪声的量才明显).DDPM将加噪声过程建模为一个马尔可夫过程
q
(
x
1
:
T
∣
x
0
)
:
=
∏
t
=
1
T
q
(
x
t
∣
x
t
−
1
)
q(x_{1:T}|x_0):= \prod \limits_{t=1}^Tq(x_t|x_{t-1})
q(x1:T∣x0):=t=1∏Tq(xt∣xt−1) ,其中
q
(
x
t
∣
x
t
−
1
)
:
=
N
(
x
t
;
α
t
x
t
−
1
,
(
1
−
α
t
)
I
)
q(x_t|x_{t-1}):=\mathcal{N}(x_t; \sqrt{\alpha_t}x_{t-1}, (1 - \alpha_t) \textbf{I})
q(xt∣xt−1):=N(xt;αtxt−1,(1−αt)I)
x
t
=
α
t
x
t
−
1
+
(
1
−
α
t
)
z
t
=
α
t
x
t
−
1
+
β
t
z
t
\begin{align} x_t &= \sqrt{\alpha_t}x_{t-1} + \sqrt{(1 - \alpha_t)}z_t \nonumber \\ &= \sqrt{\alpha_t}x_{t-1} + \sqrt{\beta_t}z_t \tag{7} \end{align}
xt=αtxt−1+(1−αt)zt=αtxt−1+βtzt(7)
x
t
x_t
xt为在
t
t
t时刻的图片,当
t
=
0
t=0
t=0时为原图;
z
t
z_t
zt为在
t
t
t时刻所加的噪声,服从标准正态分布
z
t
∼
N
(
0
,
I
)
z_t \sim \mathcal{N}(0, \textbf{I})
zt∼N(0,I);
α
t
\alpha_t
αt是常数,是自己定义的变量;从上式可见,随着
T
T
T增大,
x
t
x_t
xt越来越接近纯高斯分布.
同理:
x
t
−
1
=
α
t
−
1
x
t
−
2
+
1
−
α
t
−
1
z
t
−
1
(8)
x_{t-1} = \sqrt{\alpha_{t-1}}x_{t-2} + \sqrt{1 - \alpha_{t-1}}z_{t-1} \tag{8}
xt−1=αt−1xt−2+1−αt−1zt−1(8)
将式(8)代入式(7)可得:
x
t
=
α
t
(
α
t
−
1
x
t
−
2
+
1
−
α
t
−
1
z
t
−
1
)
+
1
−
α
t
z
t
=
α
t
α
t
−
1
x
t
−
2
+
(
α
t
(
1
−
α
t
−
1
)
z
t
−
1
+
1
−
α
t
z
t
)
\begin{align} x_t &=& \sqrt{\alpha_t} (\sqrt{\alpha_{t-1}}x_{t-2} + \sqrt{1 - \alpha_{t-1}}z_{t-1}) + \sqrt{1 - \alpha_t}z_t \nonumber\\ &=& \sqrt{\alpha_t \alpha_{t-1}}x_{t-2} + (\sqrt{\alpha_t (1 - \alpha_{t-1})} z_{t-1} + \sqrt{1 - \alpha_t}z_t) \tag{9} \end{align}
xt==αt(αt−1xt−2+1−αt−1zt−1)+1−αtztαtαt−1xt−2+(αt(1−αt−1)zt−1+1−αtzt)(9)
由于
z
t
−
1
z_{t-1}
zt−1服从均值为0,方差为1的高斯分布(即标准正态分布),根据定义
α
t
(
1
−
α
t
−
1
)
z
t
−
1
\sqrt{\alpha_t (1 - \alpha_{t-1})} z_{t-1}
αt(1−αt−1)zt−1服从的是均值为0,方差为
α
t
(
1
−
α
t
−
1
)
\alpha_t (1 - \alpha_{t-1})
αt(1−αt−1)的高斯分布.即
α
t
(
1
−
α
t
−
1
)
z
t
−
1
∼
N
(
0
,
α
t
(
1
−
α
t
−
1
)
I
)
\sqrt{\alpha_t (1 - \alpha_{t-1})} z_{t-1} \sim \mathcal{N}(0, \alpha_t (1 - \alpha_{t-1})\textbf{I})
αt(1−αt−1)zt−1∼N(0,αt(1−αt−1)I).同理可得
1
−
α
t
z
t
∼
N
(
0
,
(
1
−
α
t
)
I
)
\sqrt{1 - \alpha_t}z_t \sim \mathcal{N}(0, (1 - \alpha_t)\textbf{I})
1−αtzt∼N(0,(1−αt)I).则**(高斯分布可加性,可以通过定义推得,不赘述)**
(
α
t
(
1
−
α
t
−
1
)
,
z
t
−
1
+
1
−
α
t
z
t
)
∼
N
(
0
,
α
t
(
1
−
α
t
−
1
)
+
1
−
α
t
)
=
N
(
0
,
1
−
α
t
α
t
−
1
)
\begin{align} (\sqrt{\alpha_t (1 - \alpha_{t-1})} , z_{t-1} + \sqrt{1 - \alpha_t}z_t) \sim \mathcal{N}(0, \alpha_t (1 - \alpha_{t-1}) + 1 - \alpha_t) =& \mathcal{N}(0, 1 - \alpha_t \alpha_{t-1}) \tag{10} \end{align}
(αt(1−αt−1),zt−1+1−αtzt)∼N(0,αt(1−αt−1)+1−αt)=N(0,1−αtαt−1)(10)
我们不妨记
z
‾
t
−
2
∼
N
(
0
,
I
)
\overline{z}_{t-2} \sim \mathcal{N}(0, \textbf{I})
zt−2∼N(0,I),则
1
−
α
t
α
t
−
1
z
‾
t
−
2
∼
N
(
0
,
(
1
−
α
t
α
t
−
1
)
I
)
\sqrt{1 - \alpha_t \alpha_{t-1}} \overline{z}_{t-2} \sim \mathcal{N}(0, (1 - \alpha_t \alpha_{t-1})\textbf{I})
1−αtαt−1zt−2∼N(0,(1−αtαt−1)I)则式(10)最终可改写为
x
t
=
α
t
α
t
−
1
x
t
−
2
+
1
−
α
t
α
t
−
1
z
‾
t
−
2
(11)
x_t = \sqrt{\alpha_t \alpha_{t-1}} x_{t-2} + \sqrt{1 - \alpha_t \alpha_{t-1}} \overline{z}_{t-2} \tag{11}
xt=αtαt−1xt−2+1−αtαt−1zt−2(11)
通过递推,容易得到
x
t
=
α
t
α
t
−
1
⋯
α
1
x
0
+
1
−
α
t
α
t
−
1
…
α
1
z
‾
0
=
∏
i
=
1
t
α
i
x
0
+
1
−
∏
i
=
1
t
α
i
z
‾
0
=
令
α
‾
t
=
∏
i
=
1
t
α
i
α
‾
t
x
0
+
1
−
α
‾
t
z
‾
0
\begin{align} x_t =& \sqrt{\alpha_t \alpha_{t-1} \cdots \alpha_1} x_0 + \sqrt{1 - \alpha_t \alpha_{t-1} \dots \alpha_1} \overline{z}_0 \nonumber\\ =& \sqrt{\prod_{i=1}^{t} {\alpha_i}}x_0 + \sqrt{1 - \prod_{i=1}^{t} {\alpha_i}} \overline {z}_0 \nonumber \\ \stackrel{\mathrm{令} \overline{\alpha}_{t} = \prod_{i=1}^{t} {\alpha_i}} = & \sqrt{\overline{\alpha}_{t}}x_0+\sqrt{1 - \overline{\alpha}_{t}}\overline{z}_{0} \tag{12} \end{align}
xt===令αt=∏i=1tαiαtαt−1⋯α1x0+1−αtαt−1…α1z0i=1∏tαix0+1−i=1∏tαiz0αtx0+1−αtz0(12)
其中
z
‾
0
∼
N
(
0
,
I
)
\overline{z}_{0} \sim \mathcal{N}(0, \mathrm{I})
z0∼N(0,I),
x
0
x_0
x0为原图.从式(13)可见,我们可以从
x
0
x_0
x0得到任意时刻的
x
t
x_t
xt的分布(14),而无需按照时间顺序递推!这极大提升了计算效率.
q
(
x
t
∣
x
0
)
=
N
(
x
t
;
μ
(
x
t
,
t
)
,
σ
2
(
x
t
,
t
)
I
)
=
N
(
x
t
;
α
‾
t
x
0
,
(
1
−
α
‾
t
)
I
)
\begin{align} q(x_t|x_0) &= \mathcal{N}(x_t; \mu{(x_t, t)},\sigma^2{(x_t, t)}{}\textbf{I}) \nonumber\\ &= \mathcal{N}(x_t; \sqrt{\overline{\alpha}_{t}}x_0,(1 - \overline{\alpha}_{t})\textbf{I}) \tag{13} \end{align}
q(xt∣x0)=N(xt;μ(xt,t),σ2(xt,t)I)=N(xt;αtx0,(1−αt)I)(13)
⚠️加噪过程是确定的,没有模型的介入. 其目的是制作训练时标签
2.3 去噪过程
给定
x
T
x_T
xT如何求出
x
0
x_0
x0呢?直接求解是很难的,作者给出的方案是:我们可以一步一步求解.即学习一个解码函数
p
p
p,这个
p
p
p能够知道
x
t
x_{t}
xt到
x
t
−
1
x_{t-1}
xt−1的映射规则.如何定义这个
p
p
p是问题的关键.有了
p
p
p,只需从
x
t
x_{t}
xt到
x
t
−
1
x_{t-1}
xt−1逐步迭代,即可得出
x
0
x_0
x0.
z
=
x
T
⟶
p
x
T
−
1
⟶
p
⋯
⟶
p
x
1
⟶
p
x
0
(14)
z = x_T \stackrel{p} \longrightarrow x_{T-1} \stackrel{p} \longrightarrow \cdots \stackrel{p} \longrightarrow x_{1} \stackrel{p} \longrightarrow x_0 \tag{14}
z=xT⟶pxT−1⟶p⋯⟶px1⟶px0(14)
去噪过程是加噪过程的逆向.如果说加噪过程是求给定初始分布
x
0
x_0
x0求任意时刻的分布
x
t
x_t
xt,即
q
(
x
t
∣
x
0
)
q(x_t|x_0)
q(xt∣x0)那么去噪过程所求的分布就是给定任意时刻的分布
x
t
x_t
xt求其初始时刻的分布
x
0
x_0
x0,即
p
(
x
0
∣
x
t
)
p(x_0|x_t)
p(x0∣xt) ,通过马尔可夫假设,可以对上述问题进行化简
p
(
x
0
∣
x
t
)
=
p
(
x
0
∣
x
1
)
p
(
x
1
∣
x
2
)
⋯
p
(
x
t
−
1
∣
x
t
)
=
∏
i
=
0
t
−
1
p
(
x
i
∣
x
i
+
1
)
\begin{align} p(x_0|x_t) &= p(x_0|x1)p(x1|x2)\cdots p(x_{t-1}| x_t) \nonumber \\ &= \prod_{i=0}^{t-1}{p(x_i|x_{i+1})} \tag{15} \end{align}
p(x0∣xt)=p(x0∣x1)p(x1∣x2)⋯p(xt−1∣xt)=i=0∏t−1p(xi∣xi+1)(15)
如何求
p
(
x
t
−
1
∣
x
t
)
{p(x_{t-1}|x_{t})}
p(xt−1∣xt)呢?前面的加噪过程我们大力气推到出了
q
(
x
t
∣
x
t
−
1
)
{q(x_{t}|x_{t-1})}
q(xt∣xt−1),我们可以通过贝叶斯公式把它利用起来
p
(
x
t
−
1
∣
x
t
)
=
p
(
x
t
∣
x
t
−
1
)
p
(
x
t
−
1
)
p
(
x
t
)
(16)
p(x_{t-1}|x_t) = \frac{p(x_{t}|x_{t-1})p(x_{t-1})}{p(x_t)} \tag{16}
p(xt−1∣xt)=p(xt)p(xt∣xt−1)p(xt−1)(16)
⚠️这里的(去噪)
p
p
p和上面的(加噪)
q
q
q只是对分布的一种符号记法,它们是等价的.
有了式(17)还是一头雾水, p ( x t ) p(x_t) p(xt)和 p ( x t − 1 ) p(x_{t-1}) p(xt−1)都不知道啊!该怎么办呢?这就要借助模型的威力了.下面来看如何构建我们的模型.
延续加噪过程的推导
p
(
x
t
∣
x
0
)
p(x_t|x_0)
p(xt∣x0)和
p
(
x
t
−
1
∣
x
0
)
p(x_{t-1}|x_0)
p(xt−1∣x0)我们是可以知道的.因此若我们知道初始分布
x
0
x_0
x0,则
p
(
x
t
−
1
∣
x
t
,
x
0
)
=
p
(
x
t
∣
x
t
−
1
,
x
0
)
p
(
x
t
−
1
∣
x
0
)
p
(
x
t
∣
x
0
)
=
N
(
x
t
;
α
t
x
t
−
1
,
(
1
−
α
t
)
I
)
N
(
x
t
−
1
;
α
‾
t
−
1
x
0
,
(
1
−
α
‾
t
−
1
)
I
)
N
(
x
t
;
α
‾
t
x
0
,
(
1
−
α
‾
t
)
I
)
∝
将式
(
6
)
代入
exp
(
−
(
x
t
−
α
t
x
t
−
1
)
2
2
(
1
−
α
t
)
)
exp
(
−
(
x
t
−
1
−
α
‾
t
−
1
x
0
)
2
2
(
1
−
α
‾
t
−
1
)
)
exp
(
−
(
x
t
−
α
‾
t
x
0
)
2
2
(
1
−
α
‾
t
)
)
=
exp
[
−
1
2
(
(
x
t
−
α
t
x
t
−
1
)
2
1
−
α
t
+
(
x
t
−
1
−
α
‾
t
−
1
x
0
)
2
1
−
α
‾
t
−
1
−
(
x
t
−
α
‾
t
x
0
)
2
1
−
α
‾
t
)
]
=
exp
[
−
1
2
(
(
α
t
1
−
α
t
+
1
1
−
α
‾
t
−
1
)
x
t
−
1
2
−
(
2
α
t
‾
1
−
α
t
x
t
+
2
α
‾
t
−
1
1
−
α
‾
t
−
1
x
0
)
x
t
−
1
+
C
(
x
t
,
x
0
)
)
]
\small \begin{align} p(x_{t-1}|x_t,x_0) &= \frac{p(x_{t}|x_{t-1}, x_0)p(x_{t-1}|x_0)}{p(x_t|x_0)} \tag{17} \\ &= \frac{\mathcal{N}(x_t; \sqrt{\alpha_t}x_{t-1}, (1 - \alpha_t) \textbf{I} ) \mathcal{N}(x_{t-1}; \sqrt{\overline{\alpha}_{t-1}}x_0,(1 - \overline{\alpha}_{t-1}) \textbf{I})} { \mathcal{N}(x_t; \sqrt{\overline{\alpha}_{t}}x_0,(1 - \overline{\alpha}_{t}) \textbf{I} )} \tag{18} \\ &\stackrel{将式(6)代入} \propto \frac{ \exp \left ({- \frac{(x_t - \sqrt{\alpha_t}x_{t-1} )^2}{2 (1 - \alpha_t)}} \right) \exp \left ({- \frac{(x_{t-1} - \sqrt{\overline{\alpha}_{t-1}}x_0 )^2}{2 (1 - \overline{\alpha}_{t-1})}} \right) } { \exp \left ({- \frac{(x_{t} - \sqrt{\overline{\alpha}_{t}}x_0 )^2}{2 (1 - \overline{\alpha}_{t})}} \right) } \tag{19} \\ &= \exp \left [-\frac{1}{2} \left ( \frac{(x_t - \sqrt{\alpha_t}x_{t-1} )^2}{1 - \alpha_t} + \frac{(x_{t-1} - \sqrt{\overline{\alpha}_{t-1}}x_0 )^2}{1 - \overline{\alpha}_{t-1}} - \frac{(x_{t} - \sqrt{\overline{\alpha}_{t}}x_0 )^2}{1 - \overline{\alpha}_{t}} \right) \right] \tag{20} \\ &= \exp \left [ -\frac{1}{2} \left( \left( \frac{\alpha_t}{1-\alpha_t} + \frac{1}{1 - \overline{\alpha}_{t-1}} \right)x^2_{t-1} - \left ( \frac{2\sqrt{\overline{\alpha_{t}}}}{1 - \alpha_t}x_t + \frac{2 \sqrt{\overline{\alpha}_{t-1}}} {1 - \overline{\alpha}_{t-1} }x_0 \right)x_{t-1} + C(x_t, x_0) \right) \right] \tag{21} \end{align}
p(xt−1∣xt,x0)=p(xt∣x0)p(xt∣xt−1,x0)p(xt−1∣x0)=N(xt;αtx0,(1−αt)I)N(xt;αtxt−1,(1−αt)I)N(xt−1;αt−1x0,(1−αt−1)I)∝将式(6)代入exp(−2(1−αt)(xt−αtx0)2)exp(−2(1−αt)(xt−αtxt−1)2)exp(−2(1−αt−1)(xt−1−αt−1x0)2)=exp[−21(1−αt(xt−αtxt−1)2+1−αt−1(xt−1−αt−1x0)2−1−αt(xt−αtx0)2)]=exp[−21((1−αtαt+1−αt−11)xt−12−(1−αt2αtxt+1−αt−12αt−1x0)xt−1+C(xt,x0))](17)(18)(19)(20)(21)
结合高斯分布的定义(6)来看式(22),不难发现 p ( x t − 1 ∣ x t , x 0 ) p(x_{t-1}|x_t,x_0) p(xt−1∣xt,x0)也是服从高斯分布的.并且结合式(6)我们可以求出其方差和均值
⚠️式17做了一个近似
p
(
x
t
∣
x
t
−
1
,
x
0
)
=
p
(
x
t
∣
x
t
−
1
)
p(x_t|x_{t-1}, x_0) =p(x_t| x_{t-1})
p(xt∣xt−1,x0)=p(xt∣xt−1),能做这个近似原因是一阶马尔科夫假设,当前时间点只依赖前一个时刻的时间点.
1
σ
2
=
α
t
1
−
α
t
+
1
1
−
α
‾
t
−
1
2
μ
σ
2
=
2
α
t
‾
1
−
α
t
x
t
+
2
α
‾
t
−
1
1
−
α
‾
t
−
1
x
0
\begin{align} \frac{1}{\sigma_2} &= \frac{\alpha_t}{1-\alpha_t} + \frac{1}{1 - \overline{\alpha}_{t-1}} \tag{22} \\ \frac{2\mu}{\sigma^2} &= \frac{2\sqrt{\overline{\alpha_{t}}}}{1 - \alpha_t}x_t + \frac{2 \sqrt{\overline{\alpha}_{t-1}}} {1 - \overline{\alpha}_{t-1} }x_0 \tag{23} \end{align}
σ21σ22μ=1−αtαt+1−αt−11=1−αt2αtxt+1−αt−12αt−1x0(22)(23)
可以求得:
σ
2
=
1
−
α
‾
t
−
1
1
−
α
‾
t
(
1
−
α
t
)
μ
=
α
t
(
1
−
α
‾
t
−
1
)
1
−
α
‾
t
x
t
+
α
‾
t
−
1
(
1
−
α
t
)
1
−
α
‾
t
x
0
\begin{align} \sigma^2 &= \frac{1 - \overline{\alpha}_{t-1}}{1 - \overline{\alpha}_{t}} (1 - \alpha_t) \nonumber \\ \mu &= \frac{\sqrt{\alpha_t} (1 - \overline{\alpha}_{t-1})} {1 - \overline{\alpha}_t}x_t + \frac{\sqrt{\overline{\alpha}_{t-1}} (1 - \alpha_t) }{1 - \overline{\alpha}_t}x_0 \tag{24} \end{align}
σ2μ=1−αt1−αt−1(1−αt)=1−αtαt(1−αt−1)xt+1−αtαt−1(1−αt)x0(24)
通过上式,我们可得
p
(
x
t
−
1
∣
x
t
,
x
0
)
=
N
(
x
t
−
1
;
α
t
(
1
−
α
‾
t
−
1
)
1
−
α
‾
t
x
t
+
α
‾
t
−
1
(
1
−
α
t
)
1
−
α
‾
t
x
0
,
(
1
−
α
‾
t
−
1
1
−
α
‾
t
(
1
−
α
t
)
)
I
)
(25)
p(x_{t-1}|x_t,x_0) = \mathcal{N}(x_{t-1}; \frac{\sqrt{\alpha_t} (1 - \overline{\alpha}_{t-1})} {1 - \overline{\alpha}_t}x_t + \frac{\sqrt{\overline{\alpha}_{t-1}} (1 - \alpha_t) }{1 - \overline{\alpha}_t}x_0 , (\frac{1 - \overline{\alpha}_{t-1}}{1 - \overline{\alpha}_{t}} (1 - \alpha_t)) \textbf{I}) \tag{25}
p(xt−1∣xt,x0)=N(xt−1;1−αtαt(1−αt−1)xt+1−αtαt−1(1−αt)x0,(1−αt1−αt−1(1−αt))I)(25)
该式是真实的条件分布.我们目标是让模型学到的条件分布
p
θ
(
x
t
−
1
∣
x
t
)
p_\theta(x_{t-1}|x_t)
pθ(xt−1∣xt)尽可能的接近真实的条件分布
p
(
x
t
−
1
∣
x
t
,
x
0
)
p(x_{t-1}|x_t, x_0)
p(xt−1∣xt,x0).从上式可以看到方差是个固定量,那么我们要做的就是让
p
(
x
t
−
1
∣
x
t
,
x
0
)
p(x_{t-1}|x_t, x_0)
p(xt−1∣xt,x0)与
p
θ
(
x
t
−
1
∣
x
t
)
p_\theta(x_{t-1}|x_t)
pθ(xt−1∣xt)的均值尽可能的对齐,即
(这个结论也可以通过最小化上述两个分布的KL散度推得)
a
r
g
m
i
n
θ
∥
u
(
x
0
,
x
t
)
,
u
θ
(
x
t
,
t
)
∥
(26)
\mathrm{arg} \mathop{min}_\theta \parallel u(x_0, x_t), u_\theta(x_t, t) \parallel \tag{26}
argminθ∥u(x0,xt),uθ(xt,t)∥(26)
下面的问题变为:如何构造
u
θ
(
x
t
,
t
)
u_\theta(x_t, t)
uθ(xt,t)来使我们的优化尽可能的简单
我们注意到
μ
(
x
0
,
x
t
)
\mu(x_0, x_t)
μ(x0,xt)与
μ
θ
(
x
t
,
t
)
\mu_\theta(x_t, t)
μθ(xt,t)都是关于
x
t
x_t
xt的函数,不妨让他们的
x
t
x_t
xt保持一致,则可将
μ
θ
(
x
t
,
t
)
\mu_\theta(x_t, t)
μθ(xt,t)写成
μ
θ
(
x
t
,
t
)
=
α
t
(
1
−
α
‾
t
−
1
)
1
−
α
‾
t
x
t
+
α
‾
t
−
1
(
1
−
α
t
)
1
−
α
‾
t
f
θ
(
x
t
,
t
)
(27)
\mu_\theta(x_t, t) = \frac{\sqrt{\alpha_t} (1 - \overline{\alpha}_{t-1})} {1 - \overline{\alpha}_t}x_t + \frac{\sqrt{\overline{\alpha}_{t-1}} (1 - \alpha_t) }{1 - \overline{\alpha}_t} f_\theta(x_t, t) \tag{27}
μθ(xt,t)=1−αtαt(1−αt−1)xt+1−αtαt−1(1−αt)fθ(xt,t)(27)
f
θ
(
x
t
,
t
)
f_\theta(x_t, t)
fθ(xt,t)是我们需要训练的模型.这样对齐均值的问题就转化成了: **给定
x
t
,
t
x_t, t
xt,t来预测原始图片输入
x
0
x_0
x0.**根据上文的加噪过程,我们可以很容易制造训练所需的数据对! (Dalle2的训练采用的是这个方式,可能这就是大力出奇迹吧).事情到这里就结束了吗?
DDPM作者表示直接从
x
t
x_t
xt到
x
0
x_0
x0的预测数据跨度太大了,且效果一般.我们可以将式(12)做一下变形
x
t
=
α
‾
t
x
0
+
1
−
α
‾
t
z
‾
0
x
0
=
1
α
‾
t
(
x
t
−
1
−
α
‾
t
z
‾
0
)
\begin{align} x_t &= \sqrt{\overline{\alpha}_{t}}x_0+\sqrt{1 - \overline{\alpha}_{t}}\overline{z}_{0} \nonumber \\ x_0 &= \frac{1}{\sqrt{\overline{\alpha}_{t}}}(x_t - \sqrt{1 - \overline{\alpha}_{t}}\overline{z}_{0}) \tag{28} \end{align}
xtx0=αtx0+1−αtz0=αt1(xt−1−αtz0)(28)
代入到式(24)中
μ
=
α
t
(
1
−
α
‾
t
−
1
)
1
−
α
‾
t
x
t
+
α
‾
t
−
1
(
1
−
α
t
)
1
−
α
‾
t
1
a
‾
t
(
x
t
−
1
−
a
‾
t
z
‾
0
)
=
α
t
(
1
−
α
‾
t
−
1
)
1
−
α
‾
t
x
t
+
(
1
−
α
t
)
1
−
α
‾
t
1
α
t
(
x
t
−
1
−
α
‾
t
z
‾
0
)
=
合并
x
t
α
t
(
1
−
α
‾
t
−
1
)
+
(
1
−
α
t
)
α
t
(
1
−
α
‾
t
)
x
t
−
1
−
α
‾
t
(
1
−
α
t
)
α
t
(
1
−
α
‾
t
)
z
‾
0
=
1
−
α
‾
t
α
t
(
1
−
α
‾
t
)
x
t
−
1
−
α
t
α
t
1
−
α
‾
t
z
‾
0
=
1
α
t
x
t
−
1
−
α
t
α
t
1
−
α
‾
t
z
‾
0
\begin{align} \mu &= \frac{\sqrt{\alpha_t} (1 - \overline{\alpha}_{t-1})} {1 - \overline{\alpha}_t}x_t + \frac{\sqrt{\overline{\alpha}_{t-1}} (1 - \alpha_t) }{1 - \overline{\alpha}_t} \frac{1}{\sqrt{\overline{a}_{t}}}(x_t - \sqrt{1 - \overline{a}_{t}}\overline{z}_{0}) \nonumber \\ &= \frac{\sqrt{\alpha_t} (1 - \overline{\alpha}_{t-1})} {1 - \overline{\alpha}_t}x_t + \frac{(1 - \alpha_t) }{1 - \overline{\alpha}_t} \frac{1}{\sqrt{\alpha}_{t}}(x_t - \sqrt{1 - \overline{\alpha}_{t}}\overline{z}_{0}) \nonumber \\ &\stackrel{合并x_t} = \frac{\alpha_t(1 - \overline{\alpha}_{t-1}) + (1 - \alpha_t) }{\sqrt{\alpha}_t (1 - \overline{\alpha}_t)}x_t - \frac{\sqrt{1 - \overline{\alpha}_t}(1 - \alpha_t) }{\sqrt{\alpha_t}(1 - \overline{\alpha}_t)}\overline{z}_0 \nonumber \\ &= \frac{1 - \overline{\alpha}_t}{\sqrt{\alpha}_t (1 - \overline{\alpha}_t)}x_t - \frac{1 - \alpha_t }{\sqrt{\alpha_t}\sqrt{1 - \overline{\alpha}_t}}\overline{z}_0 \nonumber \\ &= \frac{1}{\sqrt{\alpha}_t}x_t - \frac{1 - \alpha_t }{\sqrt{\alpha_t}\sqrt{1 - \overline{\alpha}_t}}\overline{z}_0 \tag{29} \end {align}
μ=1−αtαt(1−αt−1)xt+1−αtαt−1(1−αt)at1(xt−1−atz0)=1−αtαt(1−αt−1)xt+1−αt(1−αt)αt1(xt−1−αtz0)=合并xtαt(1−αt)αt(1−αt−1)+(1−αt)xt−αt(1−αt)1−αt(1−αt)z0=αt(1−αt)1−αtxt−αt1−αt1−αtz0=αt1xt−αt1−αt1−αtz0(29)
经过这次化简,我们将
μ
(
x
0
,
x
t
)
⇒
μ
(
x
t
,
z
‾
0
)
\mu{(x_0, x_t)} \Rightarrow \mu{(x_t, \overline{z}_0)}
μ(x0,xt)⇒μ(xt,z0),其中
z
‾
0
∼
N
(
0
,
I
)
\overline{z}_0 \sim \mathcal{N}(0, \textbf{I})
z0∼N(0,I),可以将式(29)转变为
μ
θ
(
x
t
,
t
)
=
1
α
t
x
t
−
1
−
α
t
α
t
1
−
α
‾
t
f
θ
(
x
t
,
t
)
(30)
\mu_\theta(x_t, t) = \frac{1}{\sqrt{\alpha_t}} x_t - \frac{1 - \alpha_t }{\sqrt{\alpha_t}\sqrt{1 - \overline{\alpha}_t}}f_\theta(x_t, t) \tag{30}
μθ(xt,t)=αt1xt−αt1−αt1−αtfθ(xt,t)(30)
此时对齐均值的问题就转化成:给定
x
t
,
t
x_t, t
xt,t预测
x
t
x_t
xt加入的噪声
z
‾
0
\overline{z}_0
z0, 也就是说我们的模型预测的是噪声
f
θ
(
x
t
,
t
)
=
ϵ
θ
(
x
t
,
t
)
≃
z
‾
0
f_\theta{(x_t, t)} = \epsilon_{\theta}(x_t, t) \simeq \overline{z}_0
fθ(xt,t)=ϵθ(xt,t)≃z0
2.3.1 训练与采样过程
训练的目标就是这所有时刻两个噪声的差异的期望越小越好(用MSE或L1-loss).
E
t
∼
T
∥
ϵ
−
ϵ
θ
(
x
t
,
t
)
∥
2
2
(31)
\mathbb{E}_{t \sim T } \parallel \epsilon - \epsilon_{\theta}(x_t, t)\parallel_2 ^2 \tag{31}
Et∼T∥ϵ−ϵθ(xt,t)∥22(31)
下图为论文提供的训练和采样过

2.3.2 采样过程
通过以上讨论,我们推导出
p
θ
(
x
t
−
1
∣
x
t
)
p_\theta(x_{t-1}|x_t)
pθ(xt−1∣xt)高斯分布的均值和方差.
p
θ
(
x
t
−
1
∣
x
t
)
=
N
(
x
t
−
1
;
μ
θ
(
x
t
,
t
)
,
σ
2
(
t
)
I
)
p_\theta(x_{t-1}|x_t)=\mathcal{N}(x_{t-1}; \mu_{\theta}(x_t, t), \sigma^2(t) \textbf{I})
pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),σ2(t)I),根据文献2从一个高斯分布中采样一个随机变量可用一个重参数化技巧进行近似
x
t
−
1
=
μ
θ
(
x
t
,
t
)
+
σ
(
t
)
ϵ
,
其中
ϵ
∈
N
(
ϵ
;
0
,
I
)
=
1
α
t
(
x
t
−
1
−
α
t
1
−
α
‾
t
ϵ
θ
(
x
t
,
t
)
)
+
σ
(
t
)
ϵ
\begin{align} x_{t-1} &= \mu_{\theta}(x_t, t) + \sigma(t) \epsilon,其中 \epsilon \in \mathcal{N}(\epsilon; 0, \textbf{I}) \tag{32} \\ & = \frac{1}{\sqrt{\alpha_t}} (x_t - \frac{1 - \alpha_t }{\sqrt{1 - \overline{\alpha}_t}}\epsilon_\theta(x_t, t)) + \sigma(t) \epsilon \tag{33} \end{align}
xt−1=μθ(xt,t)+σ(t)ϵ,其中ϵ∈N(ϵ;0,I)=αt1(xt−1−αt1−αtϵθ(xt,t))+σ(t)ϵ(32)(33)
式(39)和论文给出的采样递推公式一致.
至此,已完成DDPM整体的pipeline.
还没想明白的点,为什么不能根据(7)的变形来进行采样计算呢?
x
t
−
1
=
1
α
t
x
t
−
1
−
α
t
α
t
f
θ
(
x
t
,
t
)
(34)
x_{t-1} = \frac{1}{\sqrt{\alpha_t}}x_t - \sqrt{\frac{1 - \alpha_t}{\alpha_t}} f_\theta(x_t, t) \tag{34}
xt−1=αt1xt−αt1−αtfθ(xt,t)(34)
3 从代码理解训练&预测过程
3.1 训练过程
参考代码仓库: https://github.com/lucidrains/denoising-diffusion-pytorch/tree/main/denoising_diffusion_pytorch
已知项: 我们假定有一批 N N N张图片 { x i ∣ i = 1 , 2 , ⋯ , N } \{x_i |i=1, 2, \cdots, N\} {xi∣i=1,2,⋯,N}
第一步: 随机采样 K K K组成batch,如 x _ s t a r t = { x k ∣ k = 1 , 2 , ⋯ , K } \mathrm{x\_start}= \{ x_k|k=1,2, \cdots, K \} x_start={xk∣k=1,2,⋯,K}, S h a p e ( x _ s t a r t ) = ( K , C , H , W ) \mathrm{Shape}(\mathrm{x\_start}) = (K, C, H, W) Shape(x_start)=(K,C,H,W)
第二步: 随机采样一些时间步
t = torch.randint(0, self.num_timesteps, (b,), device=device).long() # 随机采样时间步
第三步: 随机采样噪声
noise = default(noise, lambda: torch.randn_like(x_start)) # 基于高斯分布采样噪声
第四步: 计算 x _ s t a r t \mathrm{x\_start} x_start在所采样的时间步的输出 x T x_T xT(即加噪声).(根据公式12)
def linear_beta_schedule(timesteps):
scale = 1000 / timesteps
beta_start = scale * 0.0001
beta_end = scale * 0.02
return torch.linspace(beta_start, beta_end, timesteps, dtype = torch.float64)
betas = linear_beta_schedule(timesteps)
alphas = 1. - betas
alphas_cumprod = torch.cumprod(alphas, dim=0)
sqrt_one_minus_alphas_cumprod = torch.sqrt(1. - alphas_cumprod)
sqrt_alphas_cumprod = torch.sqrt(alphas_cumprod)
def extract(a, t, x_shape):
b, *_ = t.shape
out = a.gather(-1, t)
return out.reshape(b, *((1,) * (len(x_shape) - 1)))
def q_sample(x_start, t, noise=None):
"""
\begin{eqnarray}
x_t &=& \sqrt{\alpha_t}x_{t-1} + \sqrt{(1 - \alpha_t)}z_t \nonumber \\
&=& \sqrt{\alpha_t}x_{t-1} + \sqrt{\beta_t}z_t
\end{eqnarray}
"""
return (
extract(sqrt_alphas_cumprod, t, x_start.shape) * x_start +
extract(sqrt_one_minus_alphas_cumprod, t, x_start.shape) * noise
)
x = q_sample(x_start = x_start, t = t, noise = noise) # 这就是x0在时间步T的输出
第五步: 预测噪声.输入 x T , t x_T,t xT,t到噪声预测模型,来预测此时的噪声 z ^ t = ϵ θ ( x T , t ) \hat{z}_t = \epsilon_\theta(x_T, t) z^t=ϵθ(xT,t).论文用到的模型结构是Unet,与传统Unet的输入有所不同的是增加了一个时间步的输入.
model_out = self.model(x, t, x_self_cond=None) # 预测噪声
这里面有一个需要注意的点:模型是如何对时间步进行编码并使用的
- 首先会对时间步进行一个编码,将其变为一个向量,以正弦编码为例
class SinusoidalPosEmb(nn.Module):
def __init__(self, dim):
super().__init__()
self.dim = dim
def forward(self, x):
"""
Args:
x (Tensor), shape like (B,)
"""
device = x.device
half_dim = self.dim // 2
emb = math.log(10000) / (half_dim - 1)
emb = torch.exp(torch.arange(half_dim, device=device) * -emb)
emb = x[:, None] * emb[None, :]
emb = torch.cat((emb.sin(), emb.cos()), dim=-1)
return emb
# 时间步的编码pipeline如下,本质就是将一个常数映射为一个向量
self.time_mlp = nn.Sequential(
SinusoidalPosEmb(dim),
nn.Linear(fourier_dim, time_dim),
nn.GELU(),
nn.Linear(time_dim, time_dim)
)
- 将时间步的embedding嵌入到Unet的block中,使模型能够学习到时间步的信息
class Block(nn.Module):
def __init__(self, dim, dim_out, groups = 8):
super().__init__()
self.proj = WeightStandardizedConv2d(dim, dim_out, 3, padding = 1)
self.norm = nn.GroupNorm(groups, dim_out)
self.act = nn.SiLU()
def forward(self, x, scale_shift = None):
x = self.proj(x)
x = self.norm(x)
if exists(scale_shift):
scale, shift = scale_shift
x = x * (scale + 1) + shift # 将时间向量一分为2,一份用于提升幅值,一份用于修改相位
x = self.act(x)
return x
class ResnetBlock(nn.Module):
def __init__(self, dim, dim_out, *, time_emb_dim = None, groups = 8):
super().__init__()
self.mlp = nn.Sequential(
nn.SiLU(),
nn.Linear(time_emb_dim, dim_out * 2)
) if exists(time_emb_dim) else None
self.block1 = Block(dim, dim_out, groups = groups)
self.block2 = Block(dim_out, dim_out, groups = groups)
self.res_conv = nn.Conv2d(dim, dim_out, 1) if dim != dim_out else nn.Identity()
def forward(self, x, time_emb = None):
scale_shift = None
if exists(self.mlp) and exists(time_emb):
time_emb = self.mlp(time_emb)
time_emb = rearrange(time_emb, 'b c -> b c 1 1')
scale_shift = time_emb.chunk(2, dim = 1)
h = self.block1(x, scale_shift = scale_shift)
h = self.block2(h)
return h + self.res_conv(x)
第六步:计算损失,反向传播.计算预测的噪声与实际的噪声的损失,损失函数可以是L1或mse
@property
def loss_fn(self):
if self.loss_type == 'l1':
return F.l1_loss
elif self.loss_type == 'l2':
return F.mse_loss
else:
raise ValueError(f'invalid loss type {self.loss_type}')
通过不断迭代上述6步即可完成模型的训练
3.2采样过程
第一步:随机从高斯分布采样一张噪声图片,并给定采样时间步
img = torch.randn(shape, device=device)
第二步: 根据预测的当前时间步的噪声,通过公式计算当前时间步的均值和方差
posterior_mean_coef1 = betas * torch.sqrt(alphas_cumprod_prev) / (1. - alphas_cumprod) # 式(24)x_0的系数
posterior_mean_coef = (1. - alphas_cumprod_prev) * torch.sqrt(alphas) / (1. - alphas_cumprod) # 式(24) x_t的系数
def extract(a, t, x_shape):
b, *_ = t.shape
out = a.gather(-1, t)
return out.reshape(b, *((1,) * (len(x_shape) - 1)))
def q_posterior(self, x_start, x_t, t):
posterior_mean = (
extract(self.posterior_mean_coef1, t, x_t.shape) * x_start +
extract(self.posterior_mean_coef2, t, x_t.shape) * x_t
) # 求出此时的均值
posterior_variance = extract(self.posterior_variance, t, x_t.shape) # 求出此时的方差
posterior_log_variance_clipped = extract(self.posterior_log_variance_clipped, t, x_t.shape) # 对方差取对数,可能为了数值稳定性
return posterior_mean, posterior_variance, posterior_log_variance_clipped
def p_mean_variance(self, x, t, x_self_cond = None, clip_denoised = True):
preds = self.model_predictions(x, t, x_self_cond) # 预测噪声
x_start = preds.pred_x_start # 模型预测的是在x_t时间步噪声,x_start是根据公式(12)求
if clip_denoised:
x_start.clamp_(-1., 1.)
model_mean, posterior_variance, posterior_log_variance = self.q_posterior(x_start = x_start, x_t = x, t = t)
return model_mean, posterior_variance, posterior_log_variance, x_start
第三步: 根据公式(33)计算得到前一个时刻图片 x t − 1 x_{t-1} xt−1
@torch.no_grad()
def p_sample(self, x, t: int, x_self_cond = None, clip_denoised = True):
b, *_, device = *x.shape, x.device
batched_times = torch.full((x.shape[0],), t, device = x.device, dtype = torch.long)
model_mean, _, model_log_variance, x_start = self.p_mean_variance(x = x, t = batched_times, x_self_cond = x_self_cond, clip_denoised = clip_denoised) # 计算当前分布的均值和方差
noise = torch.randn_like(x) if t > 0 else 0. # 从高斯分布采样噪声
pred_img = model_mean + (0.5 * model_log_variance).exp() * noise # 根据
return pred_img, x_start
通过迭代以上三步,直至 T = 0 T=0 T=0完成采样.
思考和讨论
DDPM区别与传统的VAE与GAN采用了一种新的范式实现了更高质量的图像生成.但实践发现,需要较大的采样步数才能得到较好的生成结果.由于其采样过程是一个马尔可夫的推理过程,导致会有较大的耗时.后续工作如DDIM针对该特性做了优化,数十倍降低采样所用时间。
参考文献
[Denoising Diffusion Probabilistic Models]( ↩︎
Understanding Diffusion Models: A Unified Perspective ↩︎