Softmax回归,虽然它的名称叫做回归,其实它是一个分类问题。
回归VS分类
回归估计一个连续值
如:回归估计下个月的房价
分类预测一个离散类别
如:
(1)MNIST:手写数字识别(10类)
(2)ImageNet:自然物体分类(1000类)
Kaggle上的分类问题
(1)将人类蛋白质显微镜图片分成28类
(2)将恶意软件分成9个类别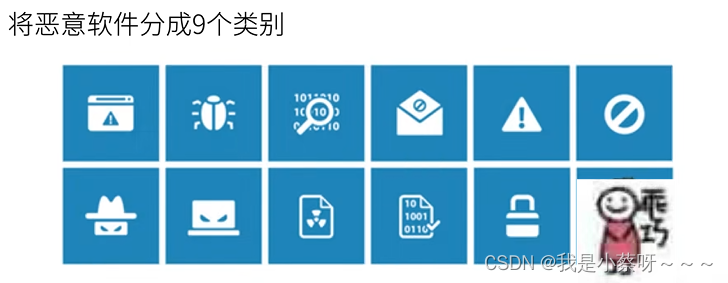
(3)将恶意的Wikipedia评论分成7类

从回归到多类分类
回归:
(1)单连续数值输出;
(2)自然区间R;
(3)跟真实值的区别作为损失;
分类:
(1)通常多个输出;
(2)输出i是预测为第i类的置信度;

从回归到多类分类——均方损失

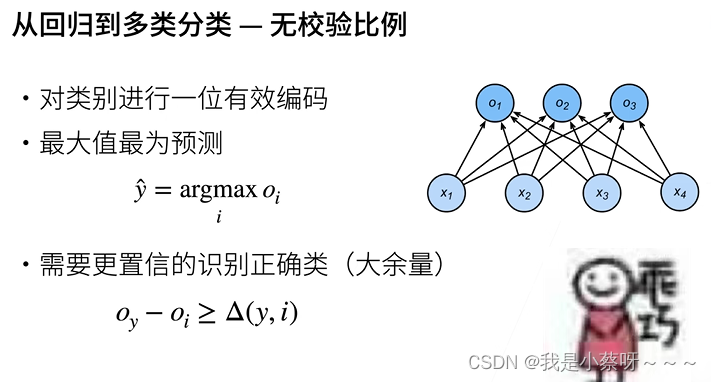
从回归到多类分类——无校验比例
对于分类,我们不关心它们实际的值差距有多大,而是关心对正确类别的置信度有多大。

Softmax和交叉熵损失

交叉熵的特点:不关心非正确类的预测值,只关心正确类的预测值的置信度是否够大。
总结
用sofrmax做结果概率化,用交叉熵做损失函数。
(1)Softmax回归是一个多类分类模型;
(2)使用Softmax操作只得到每个类的预测置信度;
(3)使用交叉熵来衡量预测和标号的区别,作为损失函数。




![[附源码]计算机毕业设计springboot学生综合数据分析系统](https://img-blog.csdnimg.cn/db61731a14cc45bbb0ac762be72cfa6e.png)

![[附源码]JAVA毕业设计简易在线教学系统(系统+LW)](https://img-blog.csdnimg.cn/7d60562ec015400eaddfd30f5b1d6ea9.png)