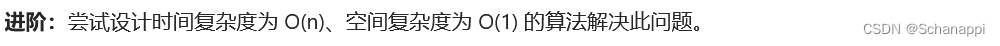精品题解 👉 九章刷题录👈 猛戳订阅
精品题解 👉 九章刷题录👈 猛戳订阅

JZ3 - 数组中重复的数字
📜 目录:
「 法一 」暴力大法(BF)
「 法二 」排序 + 遍历
「 法三 」哈希集合
「 法四 」哈希无序集
「 法五 」原地哈希
「 法六 」Map 查字典大法
「 法七 」ST 数组
🔗 题目链接:数组中重复的数字
📚 题目描述:在一个长度为 的数组里的所有数字都在 0 到
的范围内。 数组中某些数字是重复的,但不知道有几个数字是重复的。也不知道每个数字重复几次。请找出数组中任意一个重复的数字。 例如,如果输入长度为 7 的数组
,那么对应的输出是 2 或者 3。存在不合法的输入的话输出 -1。
- 数据范围:
- 进阶:时间复杂度
,空间复杂度
输入:[2,3,1,0,2,5,3]
返回值:2
说明:2或3都是对的💭 模板:C
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param numbers int整型一维数组
* @param numbersLen int numbers数组长度
* @return int整型
*/
int duplicate(int* numbers, int numbersLen ) {
// write code here
}💭 模板:C++
class Solution {
public:
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param numbers int整型vector
* @return int整型
*/
int duplicate(vector<int>& numbers) {
// write code here
}
};「 法一 」暴力大法(BF)
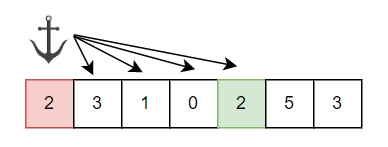
💡 思路:内外双 for 暴力搜索
最容易想到的方法,简单粗暴, 直接两层循环暴力遍历!外层循环依次选定一个数字作为 锚点 (Anchor) 。内层循环遍历锚点数字之后的数字 (target),当找到相同的数字时退出循环返回该数字 (target)。全部遍历完后仍未找到,按题目要求返回 -1 即可。
两层循环时间复杂度为 ,空间复杂度为
。
……
💬 代码:C
int duplicate(int* numbers, int numbersLen ) {
// 依次设置锚点
for (int i = 0; i < numbersLen; i++) {
// 遍历锚点之后的数字
for (int j = i + 1; i < numbersLen; j++) {
if (numbers[i] == numbers[j]) {
return numbers[i]; // 找到了
}
}
}
return -1; // 没找到
}💬 代码:C++
class Solution {
public:
int duplicate(vector<int>& numbers) {
for (int i = 0; i < numbers.size(); i++) {
for (int j = i + 1; j < numbers.size(); j++) {
if (numbers[i] == numbers[j]) {
return numbers[i]; // 找到了
}
}
}
return -1; // 没找到
}
};「 法二 」排序 + 遍历
💡 思路:排序后相同的元素会紧挨着
在允许修改原数组的前提下,我们可以尝试 "排序 + 遍历" 的方法,先对数组进行排序,因为 排序后,相同的元素肯定是紧挨着的,如此一来,我们只需要一层循环遍历整个数组即可。遍历时将下标 设置从 1 开始,依次和
下标的元素做对比即可。
如果使用系统函数 sort,或手写堆排序等,排序所需时间复杂度为 ,随后只需遍历一次数组所以为
,所以总的时间复杂度为
,空间复杂度为
。相较于 "法一" 的
的暴力,好多了。
💭 代码:C
int cmp(const void* a, const void* b) {
return (*(int*)a - * (int*)b);
}
int duplicate(int* numbers, int numbersLen ) {
// 使用qsort对数组进行升序排序
qsort(numbers, numbersLen, sizeof(int), cmp);
// 检查相邻元素是否相等
for (int i = 1; i < numbersLen; i++) {
if (numbers[i] == numbers[i - 1]) {
return numbers[i];
}
}
return -1;
}我们可以使用简单快捷的 qsort 函数,使用此函数另写一个 cmp 函数即可。排序完毕后直接遍历数组检查相邻元素是否相等即可。
💭 代码:C++
class Solution {
public:
int duplicate(vector<int>& numbers) {
// 直接调用 sort 排序
sort(numbers.begin(), numbers.end());
// 遍历数组,前后挨个比对
for (int i = 1; i < numbers.size(); i++) {
// 如果前后元素一致
if (numbers[i] == numbers[i - 1]) {
return numbers[i]; // 找到了
}
}
return -1; // 没找到
}
};C++ 做排序就更方便了,直接调 sort 就行,传入 vector 的 begin 和 end 即可。
「 法三 」哈希集合
💡 思路:集合的元素是唯一的
稍稍思考一下,既然要找重复的元素,本质上就是看是否 unique (唯一),这让我们想到了数学中的集合,可以利用 "集合元素是唯一的" 的特点。拿题目中的例子来说,如果我们以集合的方式存储一遍该数组,那么如果在存储过程中出现重复,那么不就找到我们想要的 target 了吗?
回到语言角度,我们可以考虑使用 set 集合,该容器底层是红黑树,该部分时间复杂度为 ,和 "法二" 一样只需遍历一遍数组即可,所以时间复杂度为
,由于使用 set 要额外开空间,在悲观情况下 (没有找到返回 -1) 需要将全部元素存入,因此空间复杂度为
。
遍历数组,我们可以通过 count 接口检查集合中是否存在该数字,如果已经存在,则说明找到重复的数字了,返回该数字即可。如果该数字不在集合中 (说明是第一次出现),我们就用 insert 将该数字加入哈希表 (杂凑表) 中。遍历结束后仍未找到按题目要求我们返回 -1 即可。
那么只有两种情况:① 在集合中 ② 不在集合中,只需在循环内做一个简单的 if-else 即可。
💭 代码:C++ 实现
class Solution {
public:
int duplicate(vector<int>& numbers) {
set<int> s;
for (int i = 0; i < numbers.size(); i++) {
// 如果表中已经存在该数字 (count返回值1为存在,0不存在)
if (s.count(numbers[i]) == 1) {
return numbers[i]; // 找到了
}
else { // 不存在,首次出现
s.insert(numbers[i]); // 记录到表中
}
}
return -1; // 没找到
}
};
我们首先定义 set,模板设为 <int>。随后遍历整个数组,我们使用 count 接口来检查是否存在该数字。count 接收一个参数,此参数表示容器中是否存在需要检查的元素。count 的返回值:如果元素存在于容器中则返回1,否则返回 0。 所以我们将当前数字传入 count,如果返回值为 1 则存在,返回即可。如果不存在我们就调用 insert,将当前数字传给 insert 将该数字添加到集合中即可。
「 法四 」哈希无序集
💡 思路:尝试把容器换成 unordered_set
此法属于 「法三」的小优化,我们知道,set 的底层是红黑树,时间复杂度为 ,但而 unordered_set 的期望复杂度能够达到
。显然使用 unordered_set 更优。
我们来简单介绍一下该容器,unordered_set 即 无序集。是一种不按特定顺序存储唯一元素的关联容器,允许根据元素的值快速检索单个元素。在 unordered_set 内部的元素不会按任何顺序排序,而是通过元素值的 hash 值将元素分组放置到各个槽中,其采用 vector + list 开链法,能通过元素值快速访问各个对应的元素,均摊耗时为 ,相较于「法三」的 set 有小小的提升。但还是要遍历一次数组,所以时间复杂度还是
,并且仍然额外开空间,所以空间复杂度为
。
unordered_set 我们仍然是用 count 来检查是否在 hash 表内,用 insert 来插入。和 「法三」一样,只是容器换成了 unordered_set 而已。
⚡ 代码:C++ 实现
#include <unordered_set>
class Solution {
public:
int duplicate(vector<int>& numbers) {
unordered_set<int> u_set;
for (int i = 0; i < numbers.size(); i++) {
// 如果表中已经存在该数字 (count返回值1为存在,0不存在)
if (u_set.count(numbers[i]) == 1) {
return numbers[i]; // 找到了
}
else { // 不存在,首次出现
u_set.insert(numbers[i]); // 记录到表中
}
}
return -1; // 没找到
}
};我们首先定义 unordered_set,模板设为 <int>。随后遍历整个数组,我们使用 count 接口来检查是否存在该数字,count 接收一个参数,此参数表示容器中是否存在需要检查的元素。如果元素存在于容器中则返回1,否则返回 0。所以我们将当前数字传入 count,如果返回值为 1 则存在,返回即可。如果不存在我们就调用 insert,将当前数字传给 insert 将该数字添加到集合中即可。
「 法五 」原地哈希
💡 思路:
再读一遍题干 —— "在一个长度为 的数组里的所有数字都在 0 到
的范围内" 可知:数组长度为
,且数组中所有数字都在
内,我们可以用 swap 函数将数组中的数对应到数组下标上。首先遍历整个数组:
① 如果 numbers[i] 等于下标 ,则判断下一个下标是否对应。
② 如果 numbers[i] 不等于下标 ,那么:
- 如果 numbers[i] == numbers[numbers[i]],那么此时对应下标
的 numbers[i] 已经对应,则说明出现了重复的数字。
- 否则 swap(numbers[numbers[i]], numbers[i])
③ 当遍历结束后都没有找到重复的数字,根据题目要求返回 -1。
时间复杂度为 ,空间复杂度为
。
💬 代码:C++ 实现
class Solution {
public:
int duplicate(vector<int>& numbers) {
int i = 0;
while (i < numbers.size()) {
if (i == numbers[i]) {
i++;
}
else {
if (numbers[numbers[i]] == numbers[i]) {
return numbers[i];
}
else {
// 交换
std::swap(numbers[numbers[i]], numbers[i]);
}
}
}
return -1;
}
};「 法六 」Map 查字典大法
💡 思路:直接用 map 统计
在遍历的过程中使用 map 记录当前数字,存在就记为1,遍历前这个数如果已经存在则说明该数字重复。我们可以通过 count 来检查数字是否为 1,发现是 1 就说明找到了重复的了。
定义 map<int,int>,map 部分的时间复杂度为 ,遍历一遍数组是
。由于使用了
额外空间,空间复杂度为 。
当然,我们可以换用 unordered_map 容器,其期望复杂度为 。
💭 代码:C++ 实现
class Solution {
public:
int duplicate(vector<int>& numbers) {
map<int, int> m;
for (int i = 0; i < numbers.size(); i++) {
if (m.count(numbers[i]) > 0) {
return numbers[i];
}
else {
m[numbers[i]] = 1;
}
}
return -1;
}
};⚡ 优化:使用 unorderd_map
class Solution {
public:
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param numbers int整型vector
* @return int整型
*/
int duplicate(vector<int>& numbers) {
unordered_map<int, int> m;
for (int i = 0; i < numbers.size(); i++) {
if (m.count(numbers[i]) > 0) {
return numbers[i];
}
else {
m[numbers[i]] = 1;
}
}
return -1;
}
};「 法七 」ST 数组
💡 思路:ST 数组
在遍历数组时,使用 st 数组记录当前数字,如果该数存在则说明该数字重复。由于要遍历数组,时间复杂度为 ,由于使用了额外的空间开辟了新的数组,大小取决于值域,空间复杂度为
。
💭 代码:C++ 实现
class Solution {
public:
int duplicate(vector<int>& numbers) {
bool st[10000] = { 0 }; // 初始化为0
for (int i = 0; i < numbers.size(); i++) {
if (st[ numbers[i] ] != 0) { // 如果不为0
return numbers[i];
}
st[ numbers[i] ] = 1; // 设置为1
}
return -1;
}
};
定义布尔数组 st 用来记录每个数字是否已经出现过,并将所有元素初始化为 0。然后我们循环遍历数组 numbers 中的每个元素。对于每个元素 numbers[i],检查 st[numbers[i]] 是否为0。如果不为0,说明该元素已经出现过,就可以返回该元素作为重复的数字。如果 st[numbers[i]] 为0,表示该元素还未出现过,将 st[numbers[i]] 设置为1,表示该元素已经出现过。如果遍历完都没有找到重复的数字,根据题意返回 -1 即可。

📌 [ 笔者 ] 王亦优
📃 [ 更新 ] 2023.5.24
❌ [ 勘误 ] /* 暂无 */
📜 [ 声明 ] 由于作者水平有限,本文有错误和不准确之处在所难免,
本人也很想知道这些错误,恳望读者批评指正!| 📜 参考资料 C++reference[EB/OL]. []. http://www.cplusplus.com/reference/. Microsoft. MSDN(Microsoft Developer Network)[EB/OL]. []. . 百度百科[EB/OL]. []. https://baike.baidu.com/. 数组中重复的数字_牛客题霸_牛客网 |