文章目录
- 0. 介绍
- 1. DeepLabV3+
- 2. 结论
- 3. 参考
0. 介绍
DeepLabV3+文章:https://arxiv.org/pdf/1802.02611.pdf
DeepLabV3+代码:https://github.com/VainF/DeepLabV3Plus-Pytorch
语义分割的两个主要问题:
- 物体的多尺度问题。
- 多次下采样会造成特征图的分辨率变小,导致预测精度降低,边界信息丢失。
针对第一个问题,DeepLabV3很好的进行解决。第二个问题,从DeepLabV1引入空洞卷积开始,但仍没有进行很好的解决。
对于DeepLabV3,在处理高分辨率图像非常的耗时。
1. DeepLabV3+
为了解决以上问题,提出两个创新点:
- encode-decode
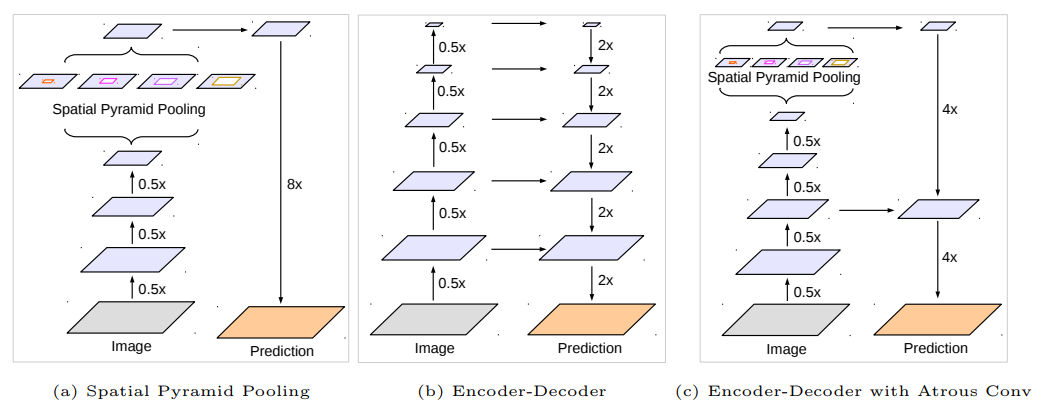
其中,a为SPP结构,8x直接进行双线性插值,不参与训练,b是encode-decode,将高层和底层信息进行融合。c是DeepLabV3+使用的结构。
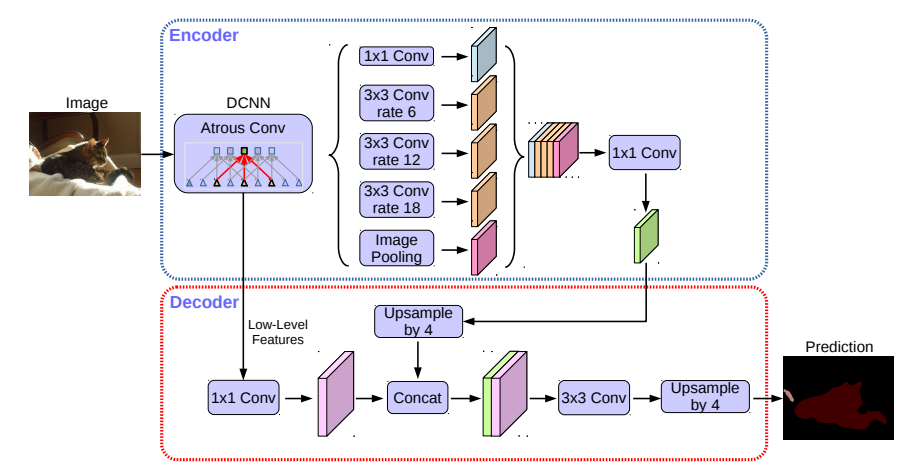
编码部分是一个DeepLabV3网络。由于低层特征所占比重不大,使用11conv进行通道压缩。encode提取的特征具有更丰富的信息,所以所占比重大,有利于训练。然后,将编码器的结果进行4倍上采样与底层特征一致。将两种特征图连接后,通过33卷积进行细化,最后再进行一次4倍上采样,得到像素级的预测。
该结构,在stide=16时,具有高精度和高效率。stride=8时,精度略微提升,计算量增加。
- 更改主干网络
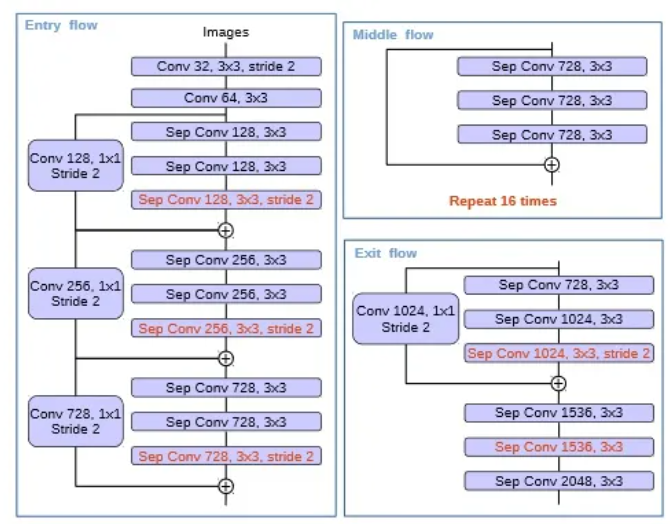
- 更深的Xception结构,不同的地方在于不修改entry flow network的结构,为了快速计算和有效的使用内存
- 所有的max pooling结构被stride=2的深度可分离卷积代替
- 每个3x3的depthwise convolution都跟BN和Relu
- 将改进后的Xception作为encode主干网络,替换原本DeepLabv3的ResNet101
2. 结论
论文提出的DeepLabv3+是encoder-decoder架构,其中encoder架构采用Deeplabv3,decoder采用一个简单却有效的模块用于恢复目标边界细节。并可使用空洞卷积在指定计算资源下控制feature的分辨率。论文探索了Xception和深度分离卷积在模型上的使用,进一步提高模型的速度和性能。
3. 参考
https://zhuanlan.zhihu.com/p/92454657


![[附源码]计算机毕业设计JAVA校园新闻管理系统](https://img-blog.csdnimg.cn/e295943b29c14169893781f7d315d297.png)




![[Java]图论详解(内附详细代码)](https://img-blog.csdnimg.cn/07aba73044864a539f5305e003a6f28a.png)
![[Linux]------线程控制与互斥](https://img-blog.csdnimg.cn/a845f85eb75349838d8701ba4b13d84f.png)




![[附源码]计算机毕业设计影评网站系统Springboot程序](https://img-blog.csdnimg.cn/48bab4f4f45a496583dfb054cf041434.png)