1.网络问题
(1)机器联网出现问题
情况:ping一下百度,发现百度ping不通
sudo vim /etc/sysconfig/network-scripts/ifcfg-ens33
检查GATEWAY是否正确,修改过来之后保存退出,重启虚拟机
sudo systemctl restart network(2) 域名解析问题
情况:ping 百度,提示是未知的网络或服务
解决:同上,只不过修改的是DNS
2.HDFS故障
2.1 HDFS集群无法启动,请分析问题并修复
先看看集群能否启动,
start -dfs.sh如果集群不能启动,显示权限不够,则说明权限分配错误,修改atuigu用户的权限即可
sudo xcall chown -R atguigu: atguigu /opt/ module/*
如果权限可以启动,则查看所有集群的开启情况:
xcall jps发现集群中的datanode都没有启动,然后查看日志:利用notepad++通过NppFTP连接到hadoop101,查看opt/module/hadoop/logs下面的日志:
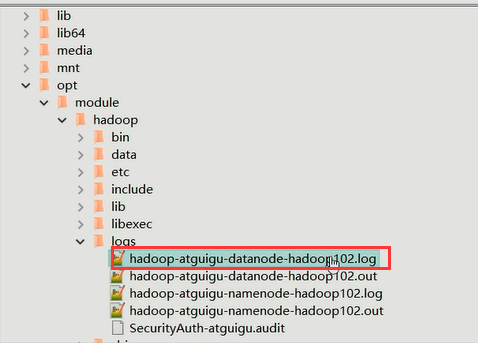
在日志里面找Exception,发现
java. io. IOException: Incompatible clusterIDS
问题分析:说明NN和DN的集群ID不一致,一般发生在HDFS已经可以使用,又二次格式化NameNode,使NameNode得到了一个新的集群ID,造成两者不匹配,
解决办法:修改NN的ID为DN,在data/dfs/name/current下面,vim version.把其中
clusterID那一行改成DN的ID.然后退出保存重启即可
stop -dfs.sh
start -dfs.shps.如果看不出来,直接把Exception中的内容进行百度
2.2 HDFS运行异常
start -dfs.sh
xcall jps发现所有集群启动正常,但是通过9870端口只能发现一台DN,说明三台DN的ID一致,查看三台机器的Version,发现DataNodeUuid一致,需要修改他们的id,在三台机器输入:
sed -i "/^datanodeUuid/s/.*/datanodeUuid= $(uuidgen)" VERSION
ps.uuidgen可以随机生成一串id
最后重启集群即可
3.Yarn故障
场景1:运行jar包的时候,运行一半报错,提示virtual memories limit(虚拟内存溢出)
办法:进入yarn-site.xml,关闭虚拟内存检查
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
然后集群同步:
xsync etc/最后重启yarn即可
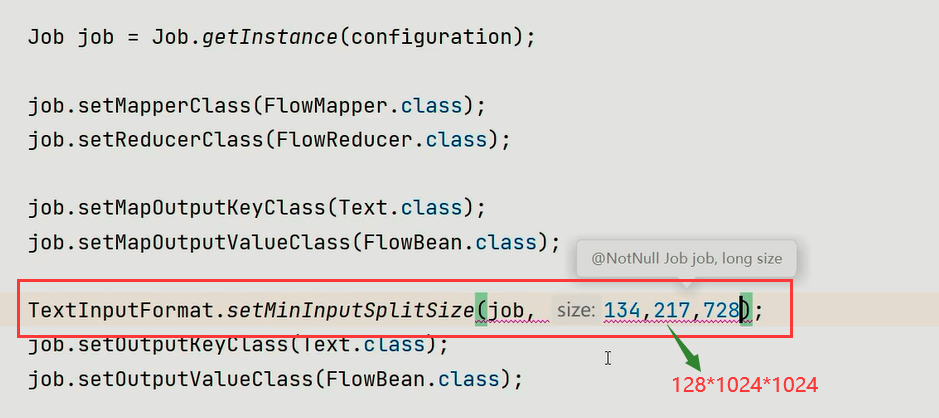
场景2:文件块(block size)太小,导致map和reduce的 数量太多,跑的太慢
办法:在jar包的源码中改变最小切片大小,改为128M
4.shell练习
考察的是输入两个参数,完成分支与循环结构的练习
例题:编写一个脚本func.sh,实现以下功能:
1. ‘func.sh jiahe N’,N为整数,返回1+...+N的和
2. ‘func.sh jiecheng N’,N为整数,返回N的阶乘
3. ‘func.sh xxx N’,xxx为任意字符串,N为整数,输出N行xxx
(1)创建脚本并打开
vim func.sh
cat func.sh (2)在脚本中输入以下内容
case $1 in
"jiahe")
s=0
for((i=1;i<=$2;i++))
do
s=$[$s+$i]
done
echo $s
;; //两个分号不要忘记
"jiecheng")
s=1
for((i=1;i<=$2,i++))
do
s=$[$s*$i]
done
echo $s
;;
*) // *代表其他情况
for((i=1;i<=$2,i++))
do echo $1
done
;;
esac(3)修改脚本权限
chmod +x func.sh(4) 测试
// 执行加和命令
./func.sh jiahe 12
// 执行阶乘命令
./func.sh jiecheng 5
// 输出5行结果
./func.sh qita 5