前言
嗨喽,大家好呀~这里是爱看美女的茜茜呐

环境使用:
-
Python 3.8
-
Pycharm
-
专业版是付费的 <文章下方名片可获取魔法永久用~>
-
社区版是免费的
-
模块使用:
第三方模块 需要安装的
-
requests >>> pip install requests
-
parsel >>> pip install parsel
-
csv
代码展示
导入模块
# 导入数据请求模块 <第三方模块, 需要安装 pip install requests>
import requests
# 导入数据解析模块 <第三方模块, 需要安装 pip install parsel>
import parsel
# 导入csv
import csv
open内置函数 --> 创建文件
f = open('data1.csv', mode='w', encoding='utf-8', newline='')
调用csv模块里面字典写入DictWriter f文件对象 fieldnames 字段名 <表头>
csv_writer = csv.DictWriter(f, fieldnames=[
'标题'
'年份',
'里程',
'城市',
'价格',
'标签',
'保修',
'详情页',
])
写入表头
csv_writer.writeheader()
“”"
- 发送请求, 模拟浏览器对于url地址发送请求
“”"
for page in range(1, 51):
try:
# 请求链接
url = f'https://****/all/?page={page}'
# 模拟浏览器 < headers请求头 >
headers = {
# User-Agent 用户代理, 表示浏览器基本身份信息
'User-Agent': ' Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
发送请求
通过requests模块里面get请求方法对于url地址发送请求, 并且携带上headers请求头伪装, 最后用自定义变量名接受返回数据
response = requests.get(url=url, headers=headers)
<Response [200]> 响应对象 200 状态码表示请求成功
print(response)
“”"
-
获取数据, 获取网页源代码 <服务器返回响应数据>
response.text 获取响应的文本数据 <获取网页源代码>
-
解析数据, 提取我们想要的数据内容
解析方法: 都要掌握, 那个方便用那个
re : 直接提取字符串数据
css : 根据标签属性提取数据内容
xpath: 根据标签节点提取数据内容 -
查看车次信息, 所对应标签位置是什么
“”"
转换数据, 把获取到 html字符串数据 <response.text>, 转成可解析对象
selector = parsel.Selector(response.text) # <Selector xpath=None data='<html lang="en">\n<head>\n <meta cha...'>
print(selector)
获取所有li标签 --> 获取多个数据, 返回列表
lis = selector.css('.Content_left .gongge_ul .li')
for循环遍历, 把列表里面元素一个一个提取出来
for li in lis:
“”"
根据具体数据所对应标签进行提取
语法规定:
-
get 提取第一个标签数据 字符串
-
getall 提取所有标签数据 列表
“”"
标题
title = li.css('a.title span::text').get()
信息
info = li.css('.gongge_main p i::text').getall()
year = info[0].replace('年', '')# 年份
km = info[1].replace('万公里', '') # 里程
city = info[2].strip() # 城市
价格
price = li.css('.price .Total::text').get()
tag = li.css('.car_tag em::text').get().strip() # 标签
label = li.css('.tc_label::text').get() # 是否保修
href = li.css('a.title::attr(href)').get() # 详情页
dit = {
'标题': title,
'年份': year,
'里程': km,
'城市': city,
'价格': price,
'标签': tag,
'保修': label,
'详情页': href,
}
写入数据
csv_writer.writerow(dit)
print(title, year, km, city, price, tag, label, href)
except:
print('如有bug + V:Pytho8987')
数据分析
import pandas as pd
from pyecharts.globals import CurrentConfig, NotebookType
CurrentConfig.NOTEBOOK_TYPE = NotebookType.JUPYTER_LAB
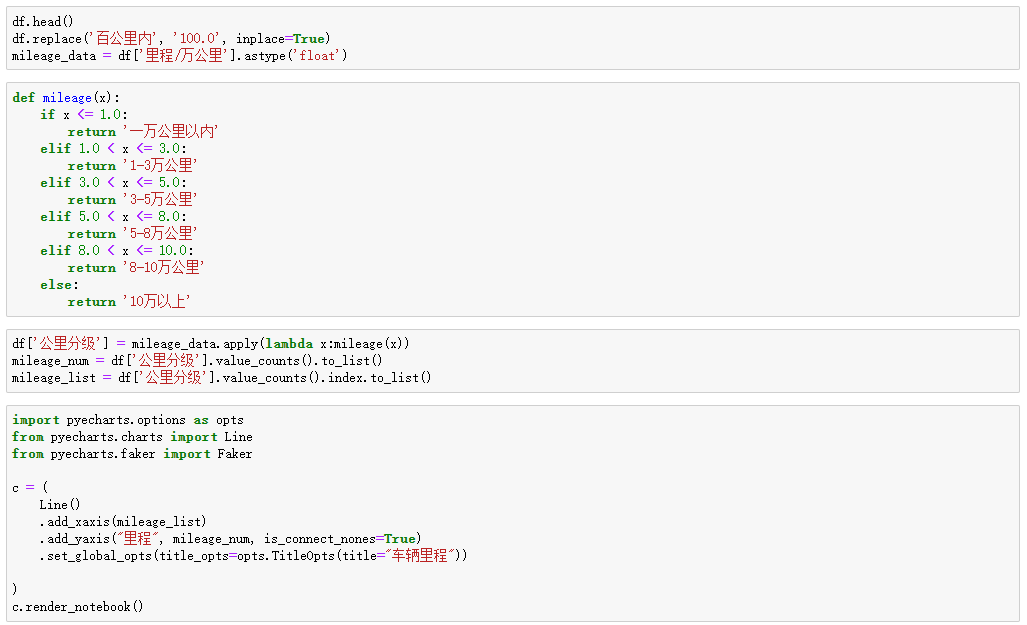
df = pd.read_csv('二手车.csv')
df.head()
year_num = df['年份'].value_counts().to_list()
year_type = df['年份'].value_counts().index.to_list()
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.faker import Faker
c = (
Pie()
.add("", [list(z) for z in zip(year_type, year_num)])
.set_colors(["blue", "green", "yellow", "red", "pink", "orange", "purple"])
.set_global_opts(title_opts=opts.TitleOpts(title="年份分布"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
# .render("pie_set_color.html")
)
c.load_javascript()
lable_num = df['标签'].value_counts().to_list()
lable_type = df['标签'].value_counts().index.to_list()
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.faker import Faker
c = (
Pie()
.add("", [list(z) for z in zip(lable_type, lable_num)])
.set_colors(["blue", "green", "yellow", "red", "pink", "orange", "purple"])
.set_global_opts(title_opts=opts.TitleOpts(title="标签分布"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
# .render("pie_set_color.html")
)
c.render_notebook()
city_num = df['城市'].value_counts().to_list()[:10]
city_type = df['城市'].value_counts().index.to_list()[:10]
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.faker import Faker
c = (
Pie()
.add("", [list(z) for z in zip(city_type, city_num)])
.set_colors(["blue", "green", "yellow", "red", "pink", "orange", "purple"])
.set_global_opts(title_opts=opts.TitleOpts(title="城市前十"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
# .render("pie_set_color.html")
)
c.render_notebook()
from pyecharts import options as opts
from pyecharts.charts import Bar
from pyecharts.faker import Faker
c = (
Bar()
.add_xaxis(city_type)
.add_yaxis("城市", city_num, color=Faker.rand_color())
.set_global_opts(
title_opts=opts.TitleOpts(title="城市分布"),
datazoom_opts=[opts.DataZoomOpts(), opts.DataZoomOpts(type_="inside")],
)
)
c.render_notebook()
df.head()
尾语
大家觉得有用的话可以来个免费的点赞+收藏+关注,
防止下次我悄悄更新了好东西你却不知道 !!!
希望本篇文章有对你带来帮助 🎉,有学习到一点知识~
躲起来的星星🍥也在努力发光,你也要努力加油(让我们一起努力叭)。