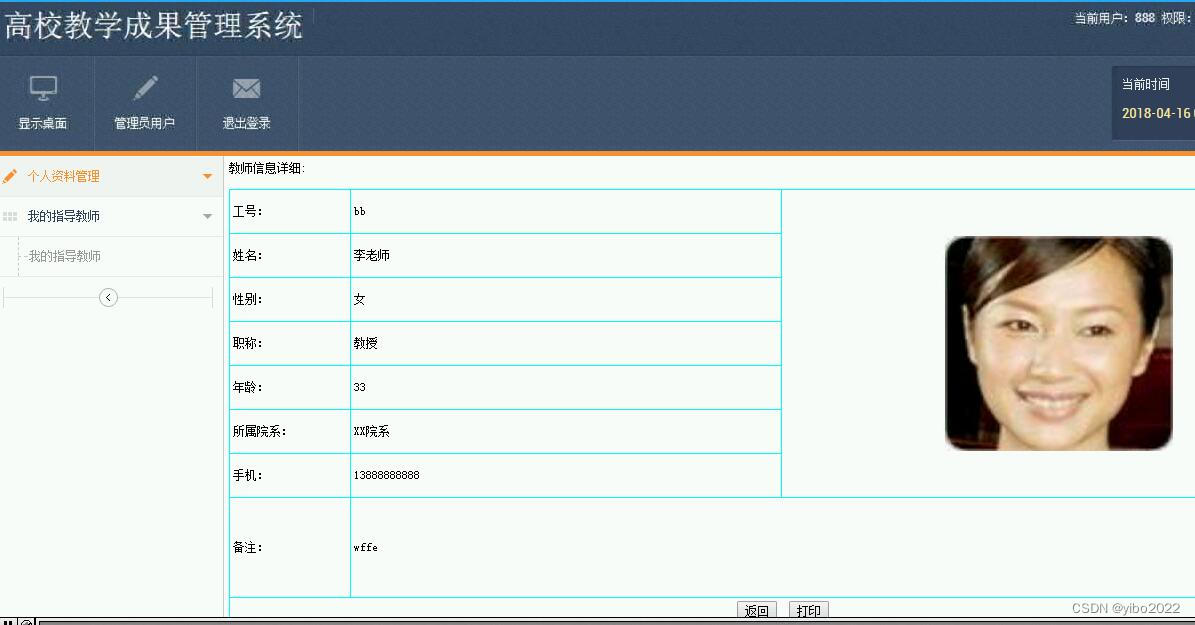
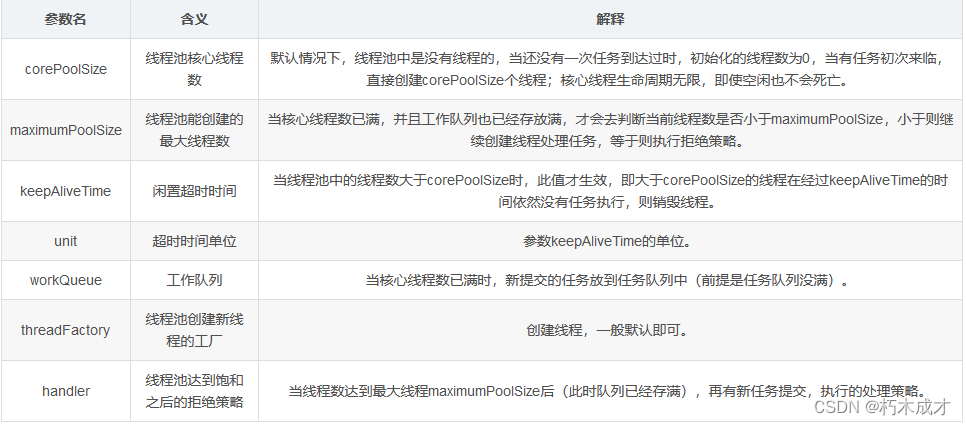
Python实现Imagenet数据集的合并和拆分

1. 合并Imagenet
任务需求
文件夹形式为一个数据集MyImagenet,路径为/home/lihuanyu/code/03AdaBins/img_data/MyImagenet/val,val文件夹又有若干的类别子文件夹,子文件夹是每一个类别的图片,我们要将所有的文件都移动到/home/lihuanyu/code/03AdaBins/MyImagenet_disorganize/val这一个文件夹下面,不设定各种子文件夹。
要求点
- 输入文件夹路径为
/home/lihuanyu/code/03AdaBins/img_data/MyImagenet/val,输出文件夹的路径为/home/lihuanyu/code/03AdaBins/MyImagenet_disorganize/val,如果没有该文件夹则进行创建。 - 将
/home/lihuanyu/code/03AdaBins/img_data/MyImagenet/val下所有子文件夹下图片,都复制到/home/lihuanyu/code/03AdaBins/MyImagenet_disorganize/val这个文件夹中。 - 要有用python语言
- 需要打印处理流程:处理到那一张图片(要计数)和处理完成的标志。
代码实现
这段代码的作用是将指定文件夹下的所有文件(包括子文件夹中的文件)复制到另外一个目录中。
首先,定义了两个变量src_path和dst_path,分别代表源文件夹路径和目标文件夹路径。然后,判断目标文件夹是否存在,若不存在则使用os.mkdir()函数创建该目录。
接下来使用os.walk()函数遍历源目录下的所有子目录和文件,得到每个文件的完整路径。对于每个文件,执行shutil.copy()函数将其复制到目标文件夹中,并打印处理进度信息。计数器count会随着处理文件的数量逐渐累加。
最后,当源目录下所有文件都处理完成后,输出处理完成的标志信息。
需要注意的是,目标文件夹中有相同命名的文件时,shutil.copy()函数会自动覆盖原文件。如果在复制过程中需要保留原文件,请使用shutil.copy2()函数。
import os
import shutil
# 输入文件夹路径和输出文件夹路径
src_path = '/home/lihuanyu/code/03AdaBins/img_data/MyImagenet/val'
dst_path = '/home/lihuanyu/code/03AdaBins/MyImagenet_disorganize/val'
# 如果目标文件夹不存在,则创建
if not os.path.exists(dst_path):
os.mkdir(dst_path)
# 计数器初始化
count = 0
# 遍历源目录下的所有子目录和文件
for root, dirs, files in os.walk(src_path):
# 处理当前目录下的所有文件
for file in files:
# 构造源文件和目标文件的完整路径
src_file = os.path.join(root, file)
dst_file = os.path.join(dst_path, file)
# 复制文件到目标目录
shutil.copy(src_file, dst_file)
# 计数器加1
count += 1
# 打印处理进度
print('正在处理第{}张图片: {}'.format(count, src_file))
# 处理完成的标志
print('所有图片已处理完成!')
2. 拆分Imagenet
在数据集合并加工完毕后,我们将处理好的图像保存在一个文件夹中,例如/home/lihuanyu/code/03AdaBins/MyImagenet_disorganize/val。不过,在后续的模型预训练中,我们需要重新组织数据集,将所有图片按照标签分类,并分别存储在以标签命名的文件夹中。
构建类别名称和类别编号关系字典
要求点1
- 以
/home/lihuanyu/code/03AdaBins/img_data/MyImagenet/val文件夹为例,它的每个文件夹名字都代表了类别名称,而文件夹下的文件是图片,我们从每个类别文件夹随机抽取一个图片,假设抽到n02009912_197.JPEG为例,其中字符串下划线_之前的字符串n02009912是代表类别的编号。 - 基于此可以构建图片类别名称与类别编号对应的关系字典。
- Python代码实现。
- 要求打印出来。
代码实现
import os
import random
# 定义数据集路径和每个子目录下需要随机选择的图片数量
data_path = '/home/lihuanyu/code/03AdaBins/img_data/MyImagenet/val'
num_images_per_class = 1
# 构建图片类别名称与类别编号对应的关系字典
image_dict = {}
for label_name in os.listdir(data_path):
# 获取该类别的编号
label_idx = os.listdir(os.path.join(data_path, label_name))[0].split('_')[0]
image_dict[label_name] = label_idx
print(image_dict)
这段代码用于构建图片类别名称与类别编号对应的关系字典,具体解释如下:
data_path:定义数据集路径。num_images_per_class:定义每个子目录下需要随机选择的图片数量,此处设置为1。image_dict:定义一个字典,用于存储图片类别名称与类别编号之间的对应关系。for label_name in os.listdir(data_path)::遍历数据集目录下的所有子目录(即类别名称)。os.listdir(os.path.join(data_path, label_name)):获取当前类别文件夹下的所有文件(即图片),并返回一个列表。[0]:获取该列表中的第一个元素,即选取一个随机的图片。.split('_')[0]:将该图片的文件名按照下划线分隔成两部分,然后取第一部分作为该图片的类别编号。image_dict[label_name] = label_idx:将该图片的类别名称作为字典的键,将该图片的类别编号作为字典的值。
该段代码的主要作用是在不知道每个类别文件夹下有多少张图片的情况下,随机选取每个类别文件夹下的一张图片,并将其所属的类别编号与类别名称存储到字典中,方便后续的分类模型训练和评估。
结果呈现
{'rule': 'n04118776', 'gartersnake': 'n01735189', 'mobilehome': 'n03776460', 'schoolbus': 'n04146614', 'pooltable': 'n03982430', 'washer': 'n04554684', 'wool': 'n04599235', 'ModelT': 'n03777568', 'beerbottle': 'n02823428', 'whitefox': 'n02120079', 'birdhouse': 'n02843684', 'Bread': 'n07684084', 'warplane': 'n04552348', 'web': 'n06359193', 'trimaran': 'n04483307', 'chickadee': 'n01592084', 'cucumber': 'n07718472', 'Siamese': 'n02123597', 'carton': 'n02971356', 'missile': 'n03773504', 'wolfspider': 'n01775062', 'husky': 'n02109961', 'catamaran': 'n02981792', 'Oriole': 'n01531178', 'recreationalvehicle': 'n04065272', 'digitalclock': 'n03196217', 'watertower': 'n04562935', 'butternutsquash': 'n07717556', 'ostrich': 'n01518878', 'radiotelescope': 'n04044716', 'Grasshopper': 'n02226429', 'reflexcamera': 'n04069434', 'moped': 'n03785016', 'coffeepot': 'n03063689', 'firetruck': 'n03345487', 'matchstick': 'n03729826', 'revolver': 'n04086273', 'artichoke': 'n07718747', 'tileroof': 'n04435653', 'Tram': 'n04335435', 'chimpanzee': 'n02481823', 'gorilla': 'n02480855', 'hourglass': 'n03544143', 'thatch': 'n04417672', 'Persiancat': 'n02123394', 'hyaena': 'n02117135', 'tank': 'n04389033', 'badger': 'n02447366', 'rocker': 'n04099969', 'horn': 'n03394916', 'trifle': 'n07613480', 'convertible': 'n03100240', 'piano': 'n04515003', 'butterfly': 'n02281787', 'bottlecap': 'n02877765', 'keypad': 'n03085013', 'stonewall': 'n04326547', 'leatherbackturtle': 'n01665541', 'streetsign': 'n06794110', 'goldfish': 'n01443537', 'soapdispenser': 'n04254120', 'cassetteplayer': 'n02979186', 'golfball': 'n03445777', 'Recordsheet': 'n03841143', 'measuringcup': 'n03733805', 'malamute': 'n02110063', 'Americanegret': 'n02009912', 'dustcart': 'n03417042', 'lizard': 'n01675722', 'desktopcomputer': 'n03180011', 'projector': 'n04009552', 'gibbon': 'n02483362', 'Rottweiler': 'n02106550', 'stoplight': 'n06874185', 'SaintBernard': 'n02109525', 'vase': 'n04522168', 'monitor': 'n03782006', 'tabby': 'n02123045', 'tablelamp': 'n04380533', 'carrier': 'n02687172', 'dishrag': 'n03207743', 'runningshoe': 'n04120489', 'crocodile': 'n01697457', 'person': 'n03450230', 'suspensionbridge': 'n04366367', 'limpkin': 'n02013706', 'numbfish': 'n01496331', 'fly': 'n02190166', 'carwheel': 'n02974003', 'freightcar': 'n03393912', 'submarine': 'n04347754', 'mask': 'n03724870', 'minibus': 'n03769881', 'jeep': 'n03594945', 'daybed': 'n04344873', 'chiffonier': 'n03016953', 'greatgreyowl': 'n01622779', 'taxi': 'n02930766', 'yurt': 'n04613696', 'leopard': 'n02128385'}
基于要求点1实现合并数据集的拆分
要求点2
- 通过要点1获得的图片类别名称与类别编号对应的关系字典
image_dict,读取字典的键,在该路径下/home/lihuanyu/code/03AdaBins/MyImagenet_merge/val,以键名创建对应文件夹。 - 遍历
/home/lihuanyu/code/03AdaBins/img_data/MyImagenet/val的图片文件名,假设文件名为n02009912_197.JPEG,截取_前面的字符串,并判断字符串属于那个那个键对应的键值,匹配成功后,将图片复制到对应的文件夹。
代码实现
这段代码实现了将一个数据集中的各个子文件夹下的一定数量的图片(num_images_per_class)随机选择后合并到同一个文件夹下的相应子文件夹里。具体来说,代码首先指定了数据集所在的路径 data_path 和每个子目录下需要随机选择的图片数量 num_images_per_class,接着用 get_key_by_value 函数通过图像 ID 在 image_dict 字典中查找对应的类别名称,然后根据该名称创建相应的文件夹,建立好文件夹和文件之间的映射关系后,用 shutil 库的 copy 函数将指定的图片从原数据集路径 data_path 复制到新路径(即将所有子文件夹的图片复制到同一文件夹下相应子文件夹里)。整个过程会输出完成复制的图片数量。
import os
import shutil
# 定义图片数据集路径和每个子目录下需要随机选择的图片数量
type = 'val'
data_path = '/home/lihuanyu/code/03AdaBins/MyImagenet_disorganize/{}'.format(type) #未合并的文件夹位置
num_images_per_class = 1
def get_key_by_value(dict_obj, value):
"""
返回一个字典中某个值对应的键
:param dict_obj: 字典对象
:param value: 字典中的值
:return: 与给定值对应的键,若未找到则返回 None """ for k, v in dict_obj.items():
if v == value:
return k
return None
i = 0
# 根据字典的键名创建对应的文件夹
for label_name in image_dict.keys():
if not os.path.exists(os.path.join('/home/lihuanyu/code/03AdaBins/MyImagenet_merge/{}'.format(type), label_name)): #合并的文件夹位置
os.makedirs(os.path.join('/home/lihuanyu/code/03AdaBins/MyImagenet_merge/{}'.format(type), label_name)) #合并的文件夹位置
for filename in os.listdir(os.path.join('/home/lihuanyu/code/03AdaBins/MyImagenet_process/{}'.format(type),label_name)):
label_idx = filename.split('_')[0]
key_idx = get_key_by_value(image_dict,label_idx)
src_path = os.path.join(data_path, filename)
dst_path = os.path.join('/home/lihuanyu/code/03AdaBins/MyImagenet_merge/{}'.format(type), key_idx, filename)
shutil.copy(src_path, dst_path)
i = i + 1
print("完成第{}个图片{}".format(i,filename))
结果呈现