一、Spark

Apache Spark 是一个快速的,多用途的集群计算系统, 相对于 Hadoop MapReduce 将中间结果保存在磁盘中, Spark 使用了内存保存中间结果, 能在数据尚未写入硬盘时在内存中进行运算。
Spark 只是一个计算框架, 不像 Hadoop 一样包含了分布式文件系统和完备的调度系统, 如果要使用 Spark, 需要搭载其它的文件系统。
Hadoop 之父 Doug Cutting 指出:Use of MapReduce engine for Big Data projects will decline, replaced by Apache Spark (大数据项目的 MapReduce 引擎的使用将下降,由 Apache Spark 取代)。
当然现在有了更为发展趋势,更好处理流式数据的 Flink ,但 Spark 在大数据处理领域仍有一席之地。
1. Spark的优点:
-
速度快:
Spark在内存时的运行速度是Hadoop MapReduce的100倍,基于硬盘的运算速度大概是Hadoop MapReduce的10倍,并且Spark实现了一种叫做RDDs的DAG执行引擎, 其数据缓存在内存中可以进行迭代处理。 -
易上手:
Spark支持Java、Scala、Python、R,、SQL等多种语言的API,并且支持超过80个高级运算符使得用户非常轻易的构建并行计算程序,同时Spark也可以使用基于Scala, Python, R, SQL的Shell交互式查询。 -
通用性强:
Spark提供一个完整的技术栈,,包括SQL执行,Dataset命令式API, 机器学习库MLlib, 图计算框架GraphX, 流计算SparkStreaming等。 -
兼容性好:
Spark可以运行在Hadoop Yarn、Apache Mesos、 Kubernets、 Spark Standalone等集群中,可以访问HBase、 HDFS、Hive、 Cassandra在内的多种数据库。
2. Spark中的组件
-
Spark-Core:整个
Spark的基础,,提供了分布式任务调度和基本的I/O功能,并且Spark最核心的功能是RDDs,RDDs就存在于这个包内。同时RDDs简化了编程复杂性,操作RDDs类似Jdk8的Streaming操作本地数据集合。 -
Spark SQL:在
spark-core基础之上带出了DataSet和DataFrame的数据抽象化的概念,提供了在Dataset和DataFrame之上执行SQL的能力,提供了DSL, 可以通过Scala, Java, Python等语言操作DataSet和DataFrame,还支持使用JDBC/ODBC服务器操作SQL语言。 -
Spark Streaming:利用
spark-core的快速调度能力来运行流分析,通过时间窗口截取小批量的数据并可以对之运行RDD Transformation。 -
MLlib:分布式机器学习的框架,可以使用许多常见的机器学习和统计算法,例如:支持向量机、 回归、 线性回归、 逻辑回归、 决策树、 朴素贝叶斯、汇总统计、相关性、分层抽样、 假设检定、随机数据生成等,简化大规模机器学习。
-
GraphX:分布式图计算框架, 提供了一组可以表达图计算的
API,还对这种抽象化提供了优化运行。
3. Spark 和 Hadoop 对比
| 对比项 | Spark | hadoop |
|---|---|---|
| 类型 | 分布式计算工具 | 基础平台, 包含计算, 存储, 调度 |
| 延迟 | 中间运算结果存在内存中,延迟小 | 中间计算结果存在 HDFS 磁盘上,延迟大 |
| 场景 | 迭代计算, 交互式计算, 流计算 | 大规模数据集上的批处理 |
| 易用性 | RDD 组成 DAG 有向无环图, API 较为顶层, 方便使用 | Map+Reduce, API 较为底层, 算法适应性差 |
| 硬件要求 | 对内存有要求 | 对机器要求低 |
4. Spark 运行模式
同 Hadoop 的 Mapreduce 类似,Spark 也有本地模式,和线上集群模式,不过不同的是,Spark 有自己的调度集群 standalone,并且支持 Hadoop 的 yarn,一般情况下本地开发使用 local 本地模式,生产环境可以使用 standalone-HA 或者 on yarn 。
二、Spark WordCount 演示
WordCount 是大数据中的 和 hello word ,前面在学习 Hadopp Mapreduce 时,使用 Mapreduce 的方式进行了实现,下面我们基于 Spark 分别从 Scala语言、Java语言、Python语言进行实现,下面是 Mapreduce 讲解时的实现文章:
https://blog.csdn.net/qq_43692950/article/details/127195121
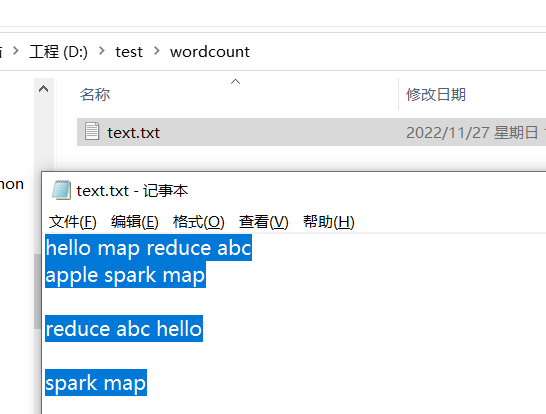
下面我在本地 D:/test/input 下,创建了一个 txt 文件,内容如下:
hello map reduce abc
apple spark map
reduce abc hello
spark map
1. Scala 语言
Spark 源码是使用 Scala 语言开发的,因此使用 Scala 开发是首选方案,如果对 Scala 语言还不是很了解的,可以看下下面的教程学习下:
https://www.cainiaojc.com/scala/scala-tutorial.html
下面创建一个 Maven 项目,在 pom 中加入 scala 和 spark 的依赖:
<!--依赖Scala语言-->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.12.11</version>
</dependency>
<!--SparkCore依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.1</version>
</dependency>
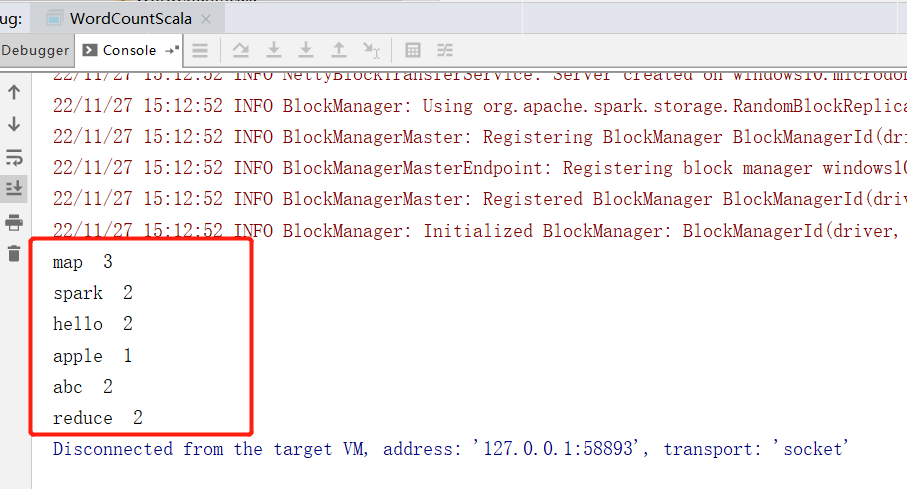
创建 object WordCountScala:
object WordCountScala {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("spark").setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
//读取数据
val textFile = sc.textFile("D:/test/wordcount/")
//处理统计
textFile.filter(StringUtils.isNotBlank) //过滤空内容
.flatMap(_.split(" ")) //根据空格拆分
.map((_, 1)) // 构建减值,value 固定 1
.reduceByKey(_ + _) // 同一个 key 下面的 value 相加
.foreach(s => println(s._1 + " " + s._2))
}
}
直接运行查看结果:
2. Java 语言
由于 Java 和 Scala 都是运行在 JVM 之上的编程语言,这里可以直接在上面 Scala 的项目中创建 Java 类进行测试:
创建 WordCountJava 测试类:
public class WordCountJava {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("spark").setMaster("local[*]");
JavaSparkContext sc = new JavaSparkContext(conf);
sc.setLogLevel("WARN");
//读取数据
JavaRDD<String> textFile = sc.textFile("D:/test/wordcount/");
//处理统计
textFile.filter(StringUtils::isNoneBlank) //过滤空内容
.flatMap(s -> Arrays.asList(s.split(" ")).iterator())//根据空格拆分
.mapToPair(s -> new Tuple2<>(s, 1))// 构建减值,value 固定 1
.reduceByKey(Integer::sum) // 同一个 key 下面的 value 相加
.foreach(s-> System.out.println(s._1 + " " + s._2));
}
}
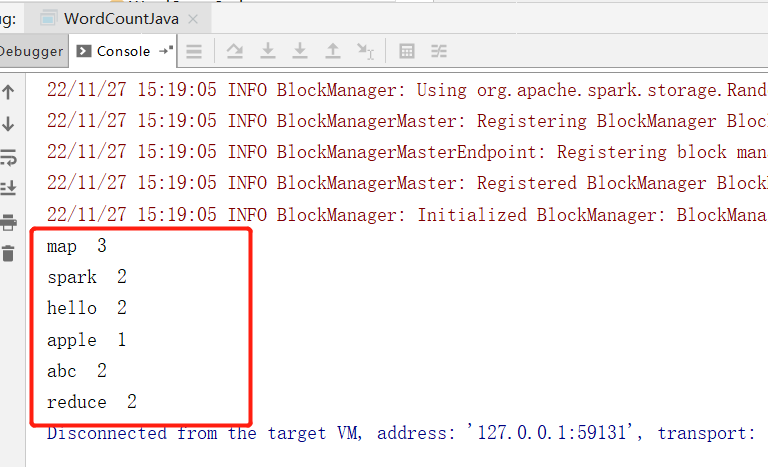
直接运行查看结果:
3. Python 语言
使用 pyspark 前,先安装相关依赖:
pip install pyspark
pip install psutil
pip install findspark
创建 WordCountPy 测试脚本:
from pyspark import SparkConf, SparkContext
import findspark
if __name__ == '__main__':
findspark.init()
conf = SparkConf().setAppName('spark').setMaster('local[*]')
sc = SparkContext(conf=conf)
sc.setLogLevel("WARN")
# 读取数据
textFile = sc.textFile("D:/test/wordcount/")
# 处理统计
textFile.filter(lambda s: s and s != '') \
.flatMap(lambda s: s.split(" ")) \
.map(lambda s: (s, 1)) \
.reduceByKey(lambda v1, v2: v1 + v2) \
.foreach(lambda s: print(s[0] + " " + str(s[1])))
运行查看结果: