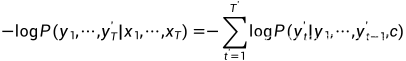用GRU实现情感分析:不需要长记忆,也能看懂你的心情
长短时记忆网络(LSTM)是一种经典的循环神经网络,用于解决序列建模问题。然而,LSTM的记忆单元需要长期记忆,这在某些任务中可能会导致过度拟合或记忆问题。为了解决这个问题,Cho等人在2014年提出了门控循环单元(GRU)。
GRU的结构比LSTM更简单,只有两个门(更新门和重置门),可以学习相对较短的依赖关系。在某些情况下,GRU的性能甚至优于LSTM。在本文中,我们将介绍GRU的结构和优势,并使用Python代码实现情感分析模型。
1. GRU原理
GRU结构相对简单,只包含两个门和一个重置门。假设$ h_{t-1} 是 t − 1 时刻的隐藏状态, 是t-1时刻的隐藏状态, 是t−1时刻的隐藏状态, x_t 是 t 时刻的输入, 是t时刻的输入, 是t时刻的输入, h_t 是 t 时刻的输出, 是t时刻的输出, 是t时刻的输出, z_t 是更新门的状态, 是更新门的状态, 是更新门的状态, r_t 是重置门的状态, 是重置门的状态, 是重置门的状态, n $是隐藏单元数量,则GRU结构的计算公式如下:
首先,我们定义重置门 r t r_t rt和更新门 z t z_t zt:
z t = σ ( W z x t + U z h t − 1 + b z ) z_t = \sigma(W_z x_t + U_z h_{t-1} + b_z) zt=σ(Wzxt+Uzht−1+bz)
r t = σ ( W r x t + U r h t − 1 + b r ) r_t = \sigma(W_r x_t + U_r h_{t-1} + b_r) rt=σ(Wrxt+Urht−1+br)
其中, x t x_t xt是输入向量, h t − 1 h_{t-1} ht−1是前一时刻的隐状态向量, σ \sigma σ是sigmoid函数, W r , U r , W z , U z W_r, U_r, W_z, U_z Wr,Ur,Wz,Uz是可训练的权重矩阵。
然后,我们定义候选隐状态 h t ~ \tilde{h_t} ht~:
h t ^ = t a n h ( W h x t + U h ( r t ⊙ h t − 1 ) + b h ) \hat{h_t} = tanh(W_h x_t + U_h(r_t \odot h_{t-1}) + b_h) ht^=tanh(Whxt+Uh(rt⊙ht−1)+bh)
其中, W , U W, U W,U是可训练的权重矩阵, ⊙ \odot ⊙表示元素级别的乘法。
最后,我们定义输出 h t h_t ht:
h
t
=
z
t
⊙
h
t
−
1
+
(
1
−
z
t
)
⊙
h
t
^
h_t = z_t \odot h_{t-1} + (1-z_t) \odot \hat{h_t}
ht=zt⊙ht−1+(1−zt)⊙ht^
这个公式可以让我们决定我们将保留多少上一时刻的信息,并更新我们将保留的信息。
2. GRU优劣势
优势
- GRU通过重置门和更新门的使用可以更好地捕获序列中的长期依赖关系。
- GRU比LSTM更简单,计算量更小,训练速度更快。
- GRU对于一些序列建模任务的性能和LSTM相当。
劣势
- GRU可能不如LSTM能够捕获序列中的更复杂的依赖关系。
- GRU对于某些序列任务的性能可能会略微劣于LSTM。
3. GRU实现情感分析
下面我们使用Python代码实现一个情感分析模型,该模型使用GRU作为其循环层。我们将使用IMDB数据集进行训练和测试,该数据集包含50,000个电影评论,每个评论都有一个正面或负面的标签。
首先,我们导入必要的库并加载数据集:
import numpy as np
from keras.models import Sequential
from keras.layers import Embedding, GRU, Dense, Dropout
from keras.preprocessing.sequence import pad_sequences
from keras.datasets import imdb
# 加载IMDB数据集
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=10000)
我们使用Embedding层将文本转换为向量表示:
# 将文本转换为向量表示
max_len = 100
x_train = pad_sequences(x_train, maxlen=max_len)
x_test = pad_sequences(x_test, maxlen=max_len)
model = Sequential()
model.add(Embedding(input_dim=10000, output_dim=128, input_length=max_len))
然后,我们添加一个GRU层:
model.add(GRU(units=64, dropout=0.2, recurrent_dropout=0.2))
接下来,我们添加一个全连接层和一个dropout层:
model.add(Dense(units=1, activation='sigmoid'))
model.add(Dropout(0.2))
最后,我们编译模型并训练:
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy'])
model.fit(x_train, y_train, epochs=10, batch_size=32, validation_data=(x_test, y_test))






![[Web]——限流](https://img-blog.csdnimg.cn/img_convert/fc94ba8c12c51bcb55cf9cc82e3fd80e.webp?x-oss-process=image/format,png)