Chapter 3. Watermarks
GIthub链接,欢迎志同道合的小伙伴一起翻译
到目前为止,我们一直从pipeline设计者或数据科学家的角度来研究流处理。第二章介绍了水印,对事件时间处理中发生的位置和处理时间中结果何时输出的基本问题做了一部分回答。在本章中,我们将从流处理系统的底层机制的角度来探讨相同的问题。研究这些机制将有助于我们motivate, understand, and apply与水印相关的概念。我们将讨论如何在数据入口点创建水印,它们如何通过data processing pipeline传播,以及它们如何影响output timestamps。我们还将演示在处理无界数据时,水印如何保持必要的保证,以回答在事件时间数据的何处被处理以及何时materialized的问题。
Definition
考虑任何连续接受数据和输出结果的pipeline。我们希望解决一般的问题,即什么时候调用事件时间窗口关闭是安全的,窗口结束之后,不会再有这个窗口的数据到来。为了做到这一点,我们想描述一下pipeline相对于它的无界输入所取得的进展。
解决事件时间窗口问题的一种简单方法是简单地将事件时间窗口建立在当前处理时间的基础上。正如我们在第一章中看到的,我们很快就会遇到麻烦——数据处理和传输不是瞬时的,所以处理和事件时间几乎从不相等。管道中的任何停顿或尖峰都可能导致我们不正确地将消息分配给窗口。最终,这个策略失败了,因为我们没有强有力的方法来保证这些窗口。
另一种直观但最终不正确的方法是考虑管道处理的消息的速率。尽管这是一个有趣的度量标准,但速率可以随输入的变化、预期结果的可变性、可供处理的资源等任意变化。更重要的是,速率并不能帮助回答完整性的基本问题。具体来说,rate并不告诉我们什么时候看到了特定时间间隔内的所有消息。在真实的系统中,会有消息不能通过系统进行处理的情况。这可能是暂时性错误(如崩溃、网络故障、机器停机)的结果,也可能是持久性错误(如需要更改应用程序逻辑或其他手动干预才能解决的应用程序级错误)的结果。当然,如果出现大量故障,处理速度指标可能是检测故障的很好的代理。然而,速率指标永远不会告诉我们,单个消息无法通过我们的管道取得进展。然而,即使是一条这样的消息,也可能会任意地影响输出结果的正确性。
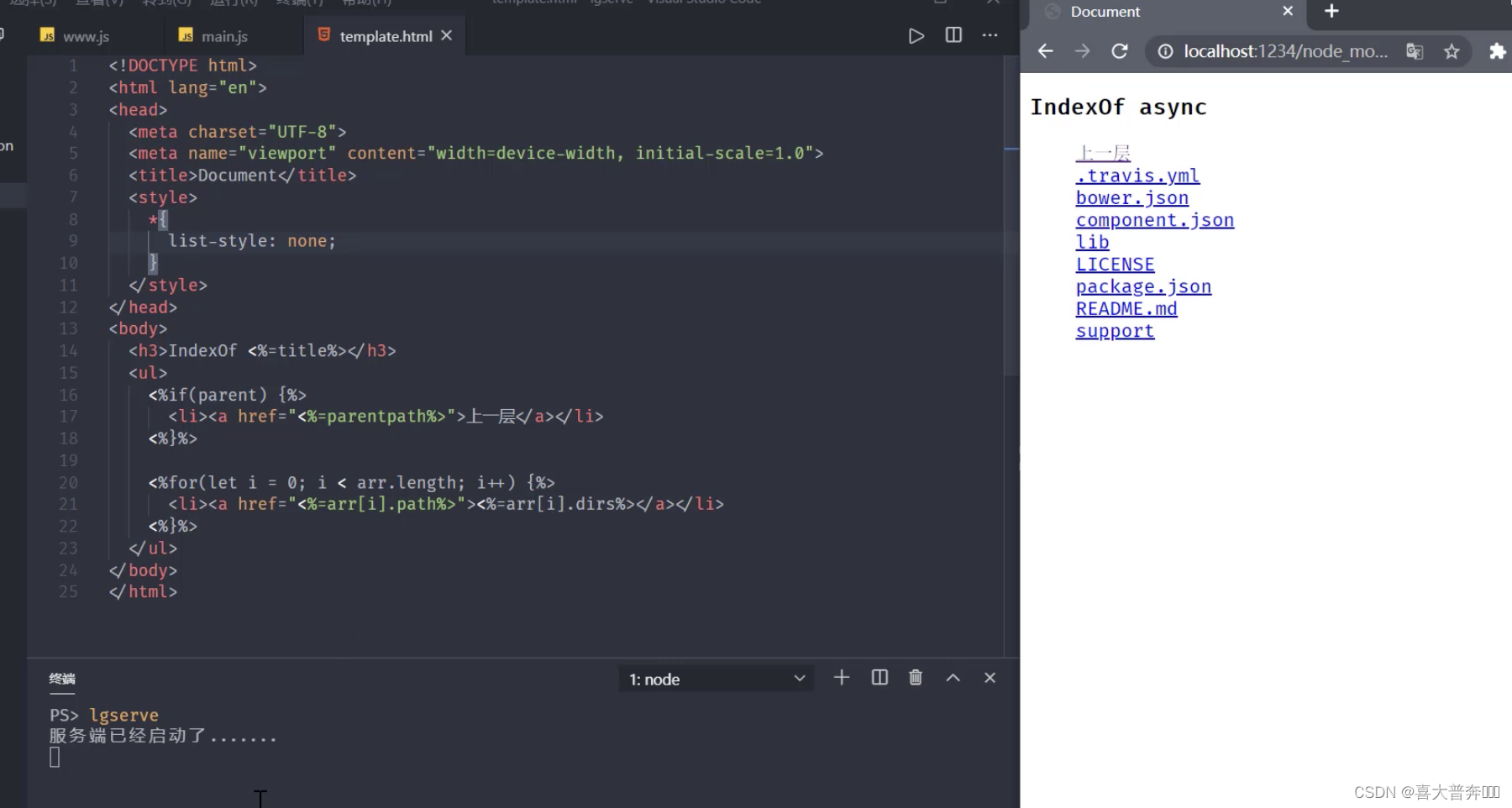
我们需要一种更鲁棒和合理的方式,来判断无界数据流的窗口结束时间。在此,我们做一个假设:假设无界数据流中的数据都有一个事件时间(即事件发生的事件)。基于这个假设,我们研究一下事件时间在计算管道(pipeline)中的假设。在分布式系统中,这个管道可能在多个计算节点(agent)上执行,多个agents同时消费源头数据,并不能保证数据的有序,其事件时间的分布如下:
上图表示了:流计算中,在eventtime上等待处理和处理完成的消息的分布。新消息进入流计算系统时,是待处理状态(in-fligt),被处理完成后,变成处理完成(completed)状态。这个分布图的关键点,是待处理消息最左边的那条边界线(即红色和蓝色部分中间的边界线),这条线代表了管道中待处理数据的最早时间戳。我们用这条线来定义watermark:
Watermark是单调递增的,管道中最早的待处理数据的事件时间戳。
Watermark两个基本属性:
- 完整性(completeness):单调递增,表示如果watermark经过了事件点T,那么T之前的数据已经到齐,T之前的窗口可以关闭了。
- 可视性(vilibility):如果管道中消息由于某个原因被堵住了,则这个管道的watermark也就停止了。需要找到阻止watermark更新的消息才能处理问题。
Source Watermark Creation
这些水印从何而来?要为数据源建立水印,我们必须为从该数据源进入管道的每个消息分配一个逻辑事件时间戳。正如第2章告诉我们的,所有的水印创建都可以分为两大类:完美或启发式。为了提醒我们完美水印和启发式水印之间的区别,让我们看看图3-2,它展示了第二章中的窗口求和示例。
在这个窗口求和例子中,左边是完美型watermark,右边是启发式watermark。从这个例子里可以看出,完美型watermark能100%保证没有late event(晚到数据),而启发式watermark允许有late event(晚到数据)出现。watermark创建后,在pipeline下游会一直存在。至于创建完美型还是启发式watermark,完全跟数据源有关。接下来通过一些例子来说明。
创建完美式watermark
完美型watermark能严格保证窗口不需要处理晚到数据(late event),也就是当watermark通过某个eventtime时,不会再有这个event time之前的数据。真实世界的分布式系统数据源是无法保证的。一些可以使用perfect watermark的例子:
- 入口时间戳(Ingress Timestamping) : 将数据进入系统的时间(即处理时间)当作数据的事件事件。2016年前几乎所有的流计算系统都是这样做的,这种方式非常简单,能保证数据单调递增,但是坏处是处理时间与数据真正的事件事件没有关系,数据真正的事件时间在计算过程中被抛弃了。
- 按时间排序的静态日志集(Static sets of time-ordered logs):按时间排序的日志,且大小固定的数据源(比如某个kafka topic中,有固定数量的partition,且每个partition中数据的event time严格单调递增)。这种场景中,只需要知道有几个partition,和每个partition中待处理数据中eventtime最早的事件即可得出watermark。
所以使用perfect watermark的关键是保证数据源数据在event time上单调递增
创建启发式watermark
与完美型watermark相反,启发式watermark假设event time在watermark之前的数据已经到齐。当然,使用启发式watermark的管道难免会遇到late event。但是只要方式得当,是可以得到一个比较合理的启发式watermark的。系统需要提供一种方式来处理late event来保证正确性。使用启发式watermark的例子如下:
- 按事件排序的动态日志集:一系列动态结构化日志文件(比如:每个日志文件内部的数据在event time上单调递增,但是文件之间时间没有关系)。所有文件的数据进入Kafka后,在event time上就不能保证单调递增了。在这种场景下,可以通过跟踪最早的待处理数据的event time,数据增长率,网络拓扑,可用带宽等信息,来得到一个相比之下非常精确的watermark。
创建启发式watermark时,没有一个统一的方式,需要根据数据源类型,数据分布等信息 case by case的看。一旦watermark被创建,其就会在pipeline中被传递下去,且类型不会变。这样整个计算管道数据完整性的问题就在数据源头被解决了。
Watermark Propagation
到目前为止,我们只考虑了单个操作或阶段上下文中输入的水印。然而,大多数真实的管道由多个阶段组成。理解水印如何在独立的阶段传播,对于理解它们如何影响整个管道和观察其结果的延迟是很重要的。
正如前一节所讨论的,在输入源处创建水印。然后,它们在概念上随着数据在系统中流动。您可以在varying levels of granularity上跟踪水印。对于包含多个不同阶段的管道,每个阶段可能跟踪自己的水印,其值是在它之前的所有输入和阶段的函数。因此,管道中较晚出现的阶段将具有更早以前的水印(因为它们看到的总体输入更少)。
我们可以在流水线中任何单个操作或阶段的边界上定义水印。这不仅有助于理解管道中每个阶段所取得的相对进展,而且有助于为每个单独的阶段独立地、尽快地及时发送结果。我们对阶段边界上的水印给出如下定义:
- 输入watermark(An input watermark):捕捉上游各阶段数据处理进度。对源头算子,input watermark是个特殊的function,对进入的数据产生watermark。对非源头算子,input watermark是上游stage中,所有shard/partition/instance产生的最小的watermark
-输出watermark(An output watermark):捕捉本stage的数据进度,实质上指本stage中,所有input watermark的最小值,和本stage中所有非late event的数据的event time。比如,该stage中,被缓存起来等待做聚合的数据等。
为特定阶段定义输入和输出水印的一个很好的特性是,我们可以使用它们来计算由某个阶段引入的事件时间延迟量。用stage的输入水印值减去stage的输出水印值,就得到了stage引入的event-time latency or lag。这个延迟指的是每一阶段的输出会在实时时间之后延迟多久。例如,执行10秒窗口聚合的阶段将有10秒或更长时间的延迟,这意味着该阶段的输出将至少比输入和实时延迟那么久。输入和输出水印的定义提供了整个管道中水印的递归关系。流水线中的每个后续阶段根据事件时间延迟水印。
每个stage内的操作并不是线性递增的。概念上,每个stage的操作都可以被分为几个组件(components),每个组件都会影响pipeline的输出watermark。每个组件的特性与具体的实现方式和包含的算子相关。理论上,这类算子会缓存数据,直到触发某个计算。比如缓存一部分数据并将其存入状态(state)中,直到触发聚合计算,并将计算结果写入下游stage。如图3-3所示。
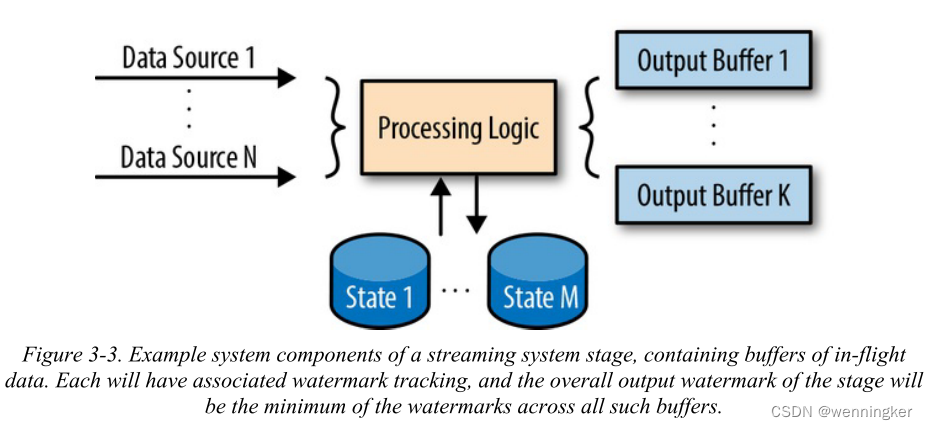
我们可以用自己的水印跟踪每个这样的缓冲区。每个阶段缓冲器上的最小水印构成该阶段的输出水印。因此,输出水印可以是以下值的最小值:
- 每个发送阶段的源水印。
- 外部输入水印——用于管道外部的源
- 每状态组件水印——针对每一种可以写入的状态
- 每个接收阶段的输出缓冲水印
这种精度的watermark能够更好的描述系统内部状态。能够更简单的跟踪数据在系统各个buffer中的流转状态,有助于排查数据堵塞问题。
Understanding Watermark Propagation
为了更好地理解输入和输出水印之间的关系以及它们如何影响水印的传播,让我们看一个例子。我们将尝试衡量用户粘性水平。我们将首先计算每个用户的会话长度,假设用户在游戏中停留的时间代表着他们对游戏的粘性。在回答完四个问题以计算会话长度之后,我们将回答它们以计算固定时间段内的平均会话长度。
为了让我们的例子更有趣,让我们假设我们正在使用两个数据集,一个是手机分数,一个是主机分数。我们希望通过这两个独立的数据集并行的整数求和来执行相同的分数计算。一种渠道是计算在移动设备上玩游戏的用户的分数,而另一种渠道是计算在家庭游戏机上玩游戏的用户的分数,这可能是因为不同平台采用了不同的数据收集策略。重要的是,这两个阶段是在执行相同的操作,但对不同的数据,因此有非常不同的输出水印。
首先,让我们看看例3-1,看看这个管道的第一部分的缩写代码是什么样子的。

在这里,我们独立地读取每个输入,而以前我们按团队输入集合,在这个例子中我们按用户输入集合。之后,对于每个管道的第一阶段,我们将窗口设置为会话,然后调用一个名为CalculateWindowLength的自定义PTransform。这个PTransform简单地按键(即User)分组,然后通过将当前窗口的大小作为该窗口的值来计算每个用户的会话长度。在本例中,我们可以使用默认触发器(AtWatermark)和累加模式(discardingfiredpane)设置,但为了完整性,我显式地列出了它们。两个特定用户的每个管道的输出可能如图3-4所示。
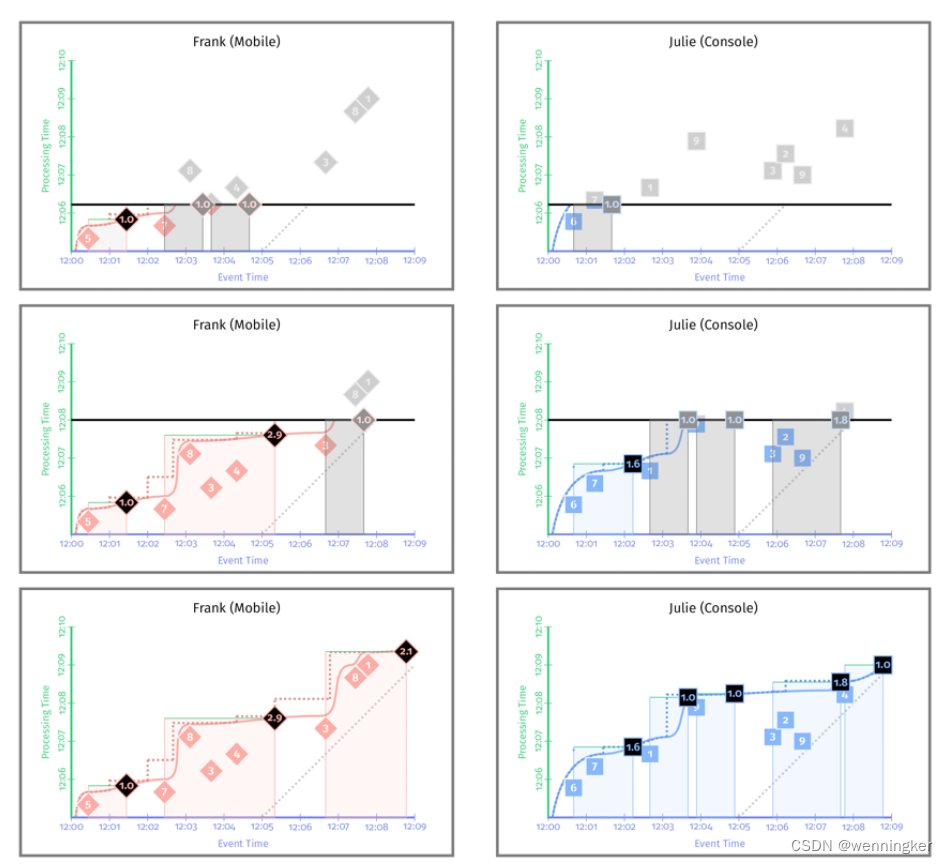
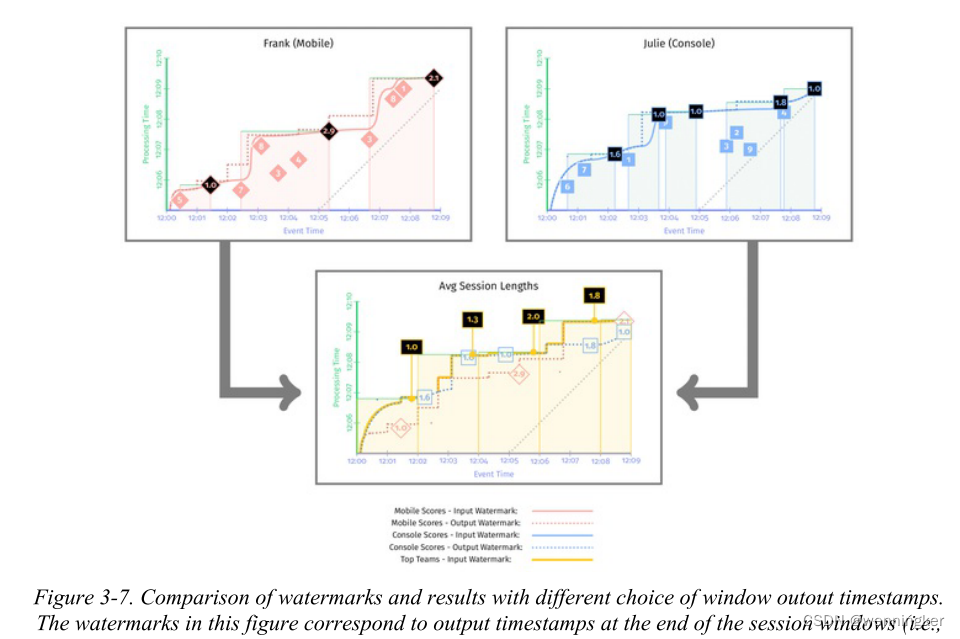
因为我们需要跨越多个阶段跟踪数据,所以我们将所有与手机分数相关的内容用红色表示,与主机分数相关的内容用蓝色表示,而图3-5中平均会话长度的水印和输出则是黄色的。
我们已经回答了四个问题:什么、在哪里、何时和如何计算单个会话长度。接下来,我们将再次回答它们,将这些会话长度转换为固定时间窗口内的全局会话长度平均值。这要求我们首先将两个数据源扁平化为一个,然后将窗口重新设置为固定窗口;我们已经在我们计算的会话长度值中捕获了会话的重要本质,现在我们想在一天中一致的时间窗口中计算这些会话的全局平均值。例3-2显示了这个代码。

如果我们看到这个管道的实际运行情况,它将如图3-5所示。与之前一样,这两个输入管道是为手机和主机玩家计算各自的会话长度。这些会话长度然后输入到管道的第二阶段,在那里,全局会话长度的平均值是在固定窗口中计算的。
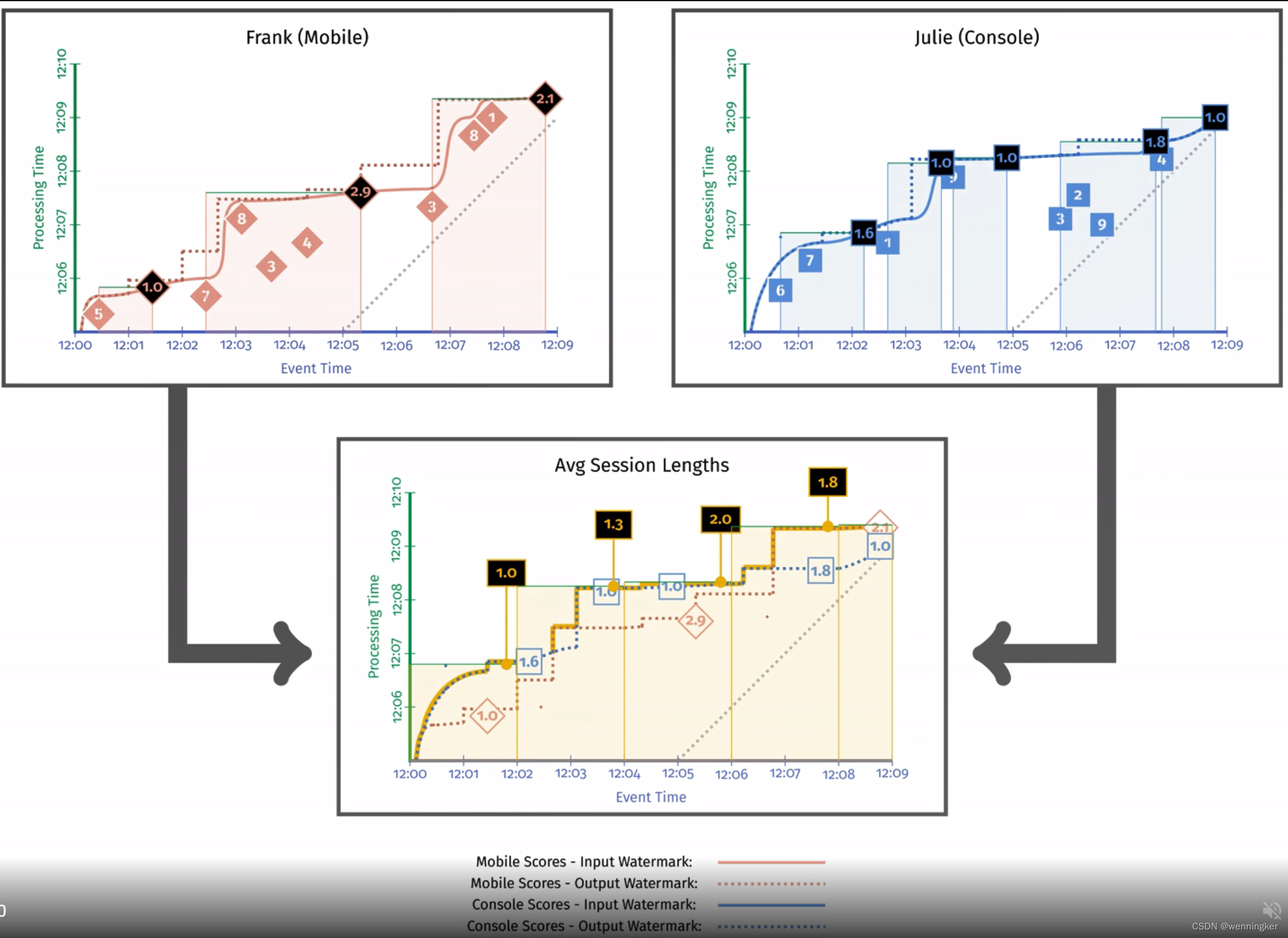
假设有很多事情要做,让我们来看一下这个例子。这里的两个要点是:
- 输出watermark一定比输入watermark早。
- 这个例子中,求平均时长的stage的watermark是两个输入中watermark较早的那个。
pipeline中,下游各stage的watermark一定比上游小(早)。这个例子中,pipeline的逻辑修改起来非常简单,通过研究这个pipeline,我们再看研究watermark的另一个问题:输出时间戳(output timestamp)
Watermark Propagation and Output Timestamps
这个例子中,第二个求平均时长的stage的输出结果中的每条输出数据都带了个时间戳。由上文所述,watermark是单调递增的,不允许回退,那么窗口的输出数据的时间戳有以下几种赋值方式:
- 窗口结束时间:将窗口结束时间作为这个窗口输出数据的时间戳。这种方式系统的性能最好。
- 窗口中第一个非迟到数据的时间戳:用窗口中第一个非late event的数据的时间戳,作为窗口所有输出数据的时间戳是一种非常保守的方式,并会对系统性能有一定影响
- 用窗口中某个元素的时间戳:在某种用例中,比如一个查询流join一个点击流,有时希望用查询流的时间戳做watermark,有时又希望用点击流的时间戳做watermark。
接下来我们用个例子来说明输出时间戳在整个pipeline中的作用,用窗口中第一个非late event数据的时间戳作为窗口输出数据的时间戳的伪代码如下:

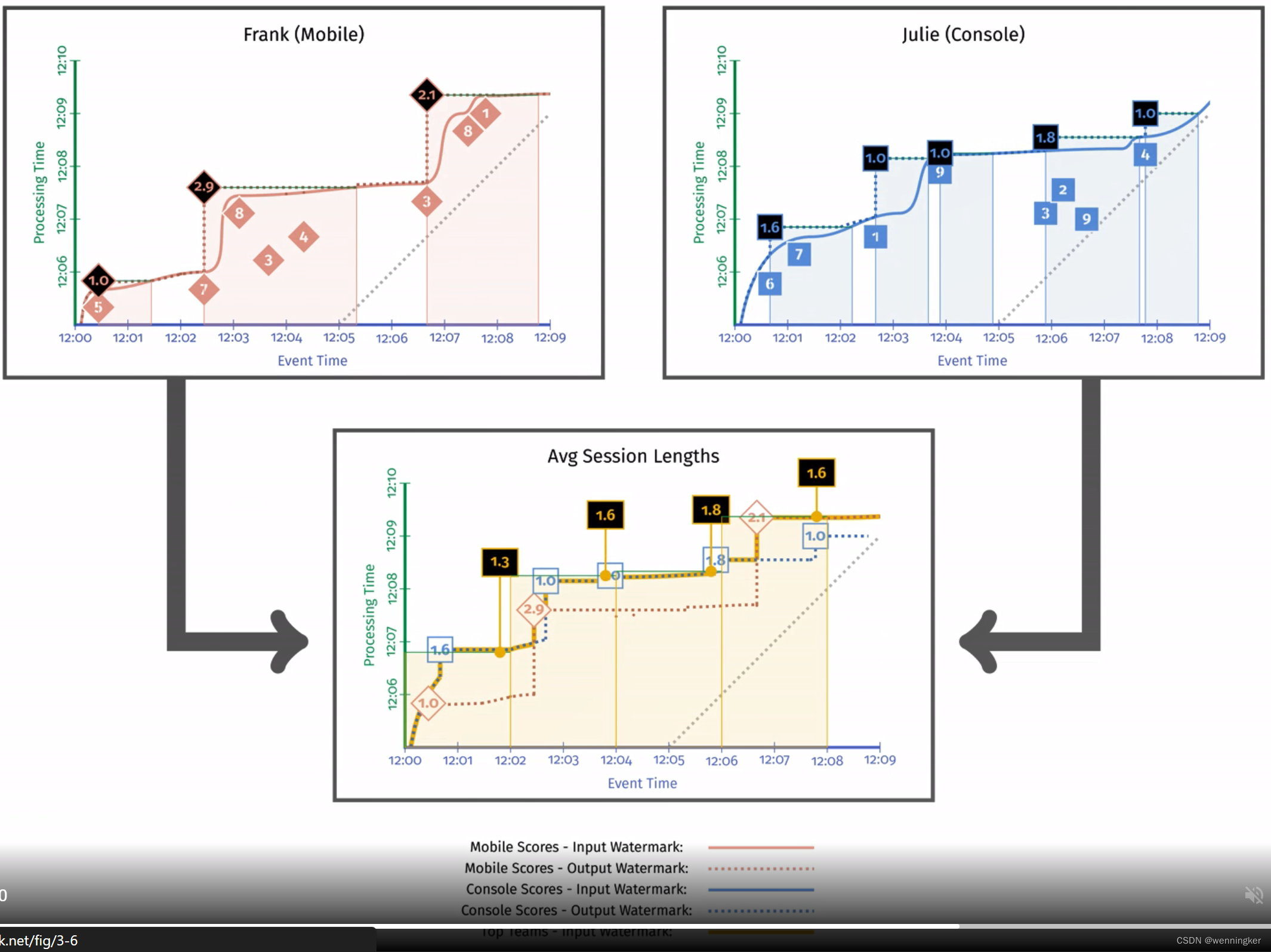
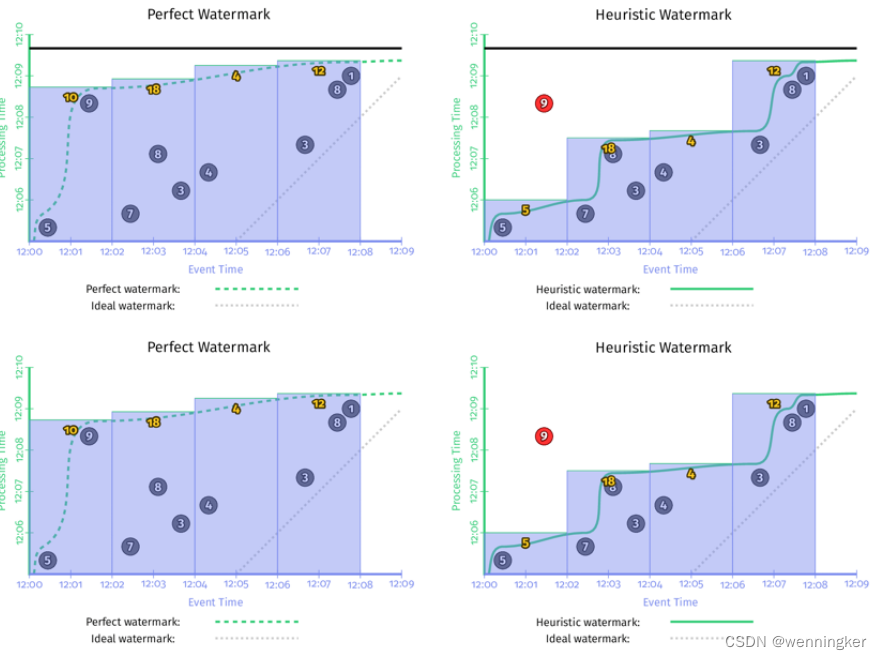
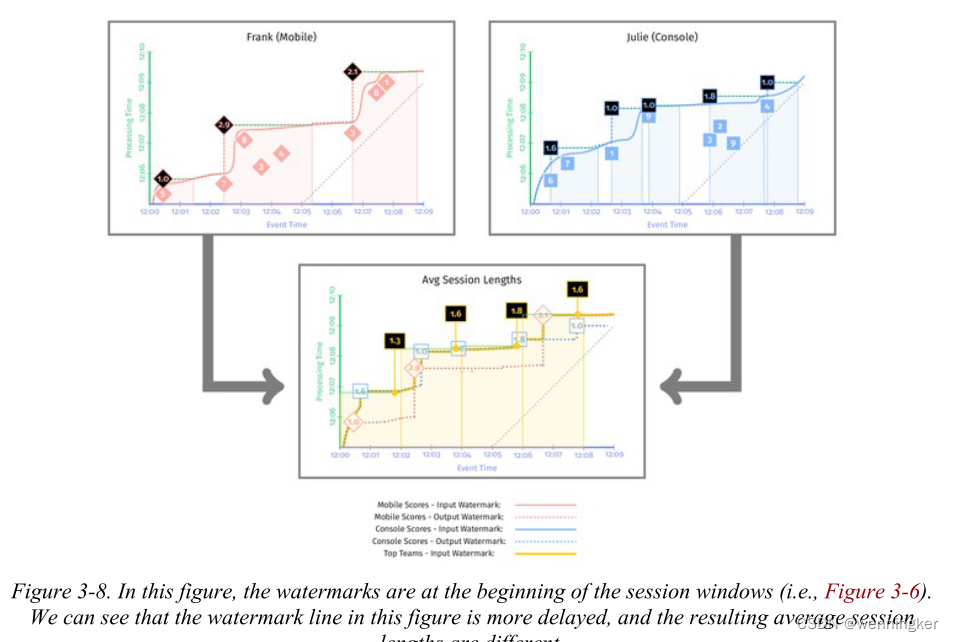
为了帮助显示输出时间戳选择的影响,请查看第一阶段中的虚线,其中显示了每个阶段的输出水印保持在什么位置。与图3-7和图3-8中选择输出时间戳作为窗口的结束相比,我们选择的时间戳延迟了输出水印。从图中可以看出,第二阶段的输入水印随后也被延迟了。
Watermark delay
与图3-5相比,图3-6中的水印处理速度要慢得多。这是因为第一阶段的输出水印被保留到每个窗口中第一个元素的时间戳,直到该窗口的输入完成。只有在给定的窗口被物化后,输出水印(以及下游输入水印)才被允许向前移动。
Semantic differences
watermark被定为第一个非late event数据的时间戳,在本例子中,同一个session可能落在不同的固定窗口中。这两种方式没有谁对谁错,但是在用之前,需要明确知道内部原理才能正确使用watermark
The Tricky Case of Overlapping Windows
关于输出时间戳的另一个微妙但重要的问题是如何处理滑动窗口。将输出时间戳设置为最早的元素的简单方法很容易导致下游的延迟,因为水印被(正确地)阻止了。要了解原因,请考虑一个有两个阶段的示例管道,每个阶段都使用相同类型的滑动窗口。假设每个元素在三个连续的窗口中结束。随着输入水印的增加,这种情况下滑动窗口的期望语义如下:
- 第一个窗口在第一阶段完成,并输出到下游。
- 第一个窗口然后在第二阶段完成,也输出到下游。
- 一段时间后,第二个窗口在第一阶段完成……以此类推。
然而,如果输出时间戳被选择为该窗格中第一个非延迟元素的时间戳,实际发生的情况如下:
- 第一个窗口在第一个stage结束,并输出到下游
- 第一个窗口在第二个stage无法输出,因为其输入watermark被第二个和第三个窗口拖住了,因为用了窗口中最早数据的时间戳作为窗口输出时间戳
- 第二个窗口在第一个stage结束,并输出到下游
- 第一个窗口和第二个窗口在第二个stage仍然不能输出,被上游第三个窗口拖住
- 第三个窗口在第一个stage结束,并输出到下游
- 第一/二/三个窗口在第二个stage同时输出
Percentile Watermarks
我们可以分析event time的分布来得到窗口更好的触发时间。也就是说,在某个时间点,我已经处理了某个event time之前百分之多少的数据,示意图如下:
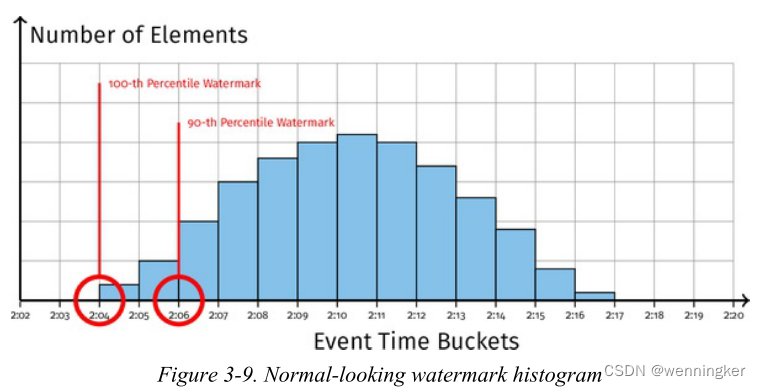
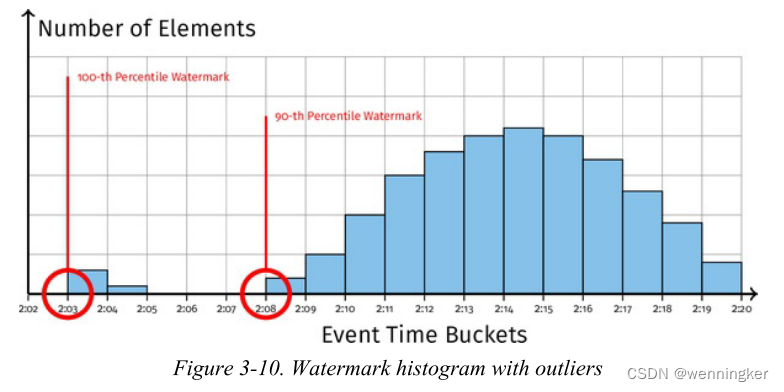
这个计划的好处是什么?如果业务逻辑“大部分”正确就足够了,百分位水印提供了一种机制,通过这种机制,水印可以比我们通过丢弃来自水印的分布的长尾中的离群值来跟踪最小事件时间更快、更平稳地前进。图3-9显示了事件时间的紧凑分布,其中90%的水印接近100的百分比。图3-10展示了一个离群值远远落后的情况,因此90%的水印显著领先于100的百分比。通过丢弃水印中的离群数据,百分位水印仍然可以跟踪分布的大部分,而不会因离群数据而延迟。图3-9。图3-10正常水印直方图带离群值的水印直方图图3-11显示了一个用于绘制两分钟固定窗口窗口边界的百分位数水印的例子。我们可以根据百分比水印跟踪的到达数据的时间戳百分比绘制早期边界。
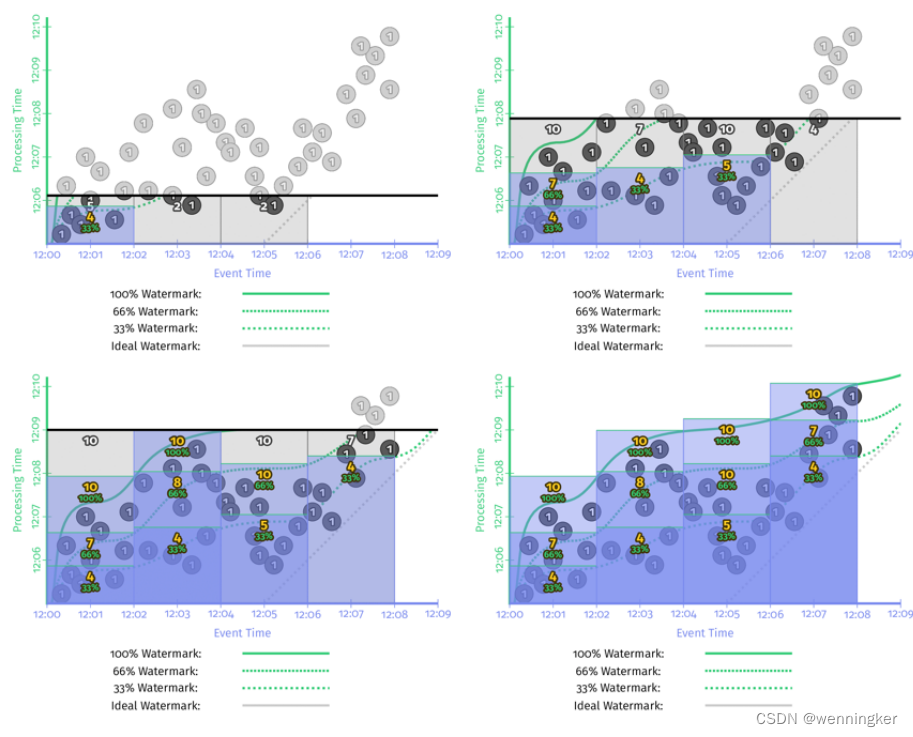
该图展示了33%,66%和100% watermark。33%和66%的watermark使窗口更早输出,当然后果是更多的数据成了late event。比如[12:00,12:02)的窗口中,33%的watermark,只有4个元素会被计算,其他元素都是late event,但是窗口在处理时间的12:06就会输出。66%的watermark有7个元素,在12:07输出,而100% watermark有10个元素,窗口要在12:08才会输出。百分比watermark为我们提供了一种平衡输出延时和结果正确性的方式。
Processing-Time Watermarks
event time上的watermark解决了处理的输入与当前时间差别的问题,但不能解决这个延时到底是由于系统问题还是数据问题导致的。由此我们引入process time上的watermark。
process time上的watermark的定义与event time watermark定义完全相同,使用最早的还未完成的算子的时间作为process time上的watermark,其与当前时间的延时,有几种原因:从一个stage到另一个stage的数据发送被堵住了,访问state的IO被堵住了,处理过程中有异常。
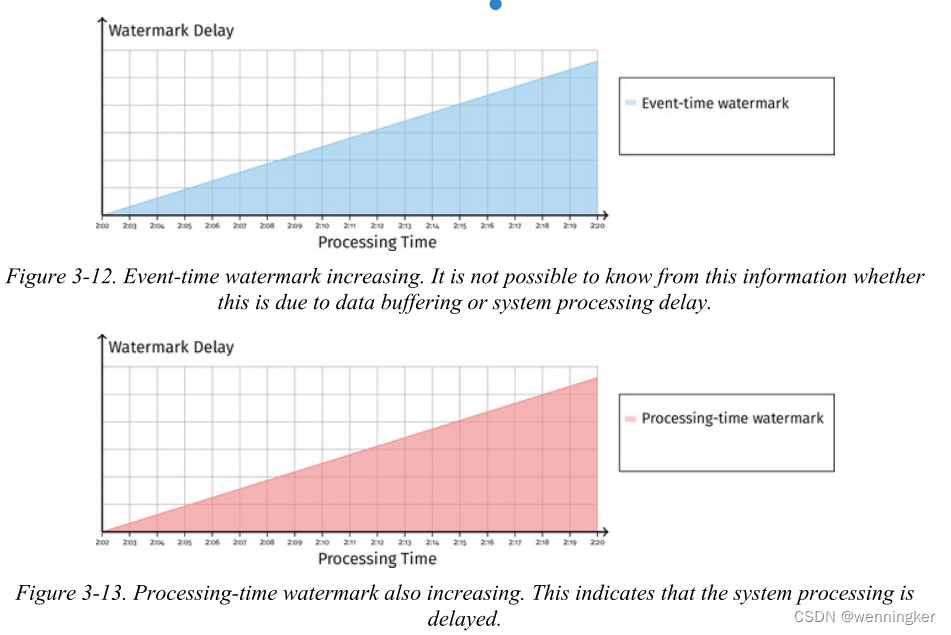
在第一种情况下(图3-12),当我们检查处理时间水印延迟时,我们看到它也在增加。这告诉我们,系统中的一个操作被卡住了,而且这种卡住还会导致数据延迟。在现实世界中,可能会出现这种情况的一些例子是:在管道的各个阶段之间出现了阻止消息传递的网络问题,或者出现了故障并正在重试。一般来说,不断增长的处理时间水印表示一个问题,该问题阻止了对系统功能来说必要的操作的完成,并且通常需要用户或管理员的干预才能解决。
在第二种情况下,如图3-14所示,处理时间水印延时很小。这告诉我们没有卡住的操作。事件时间水印延迟仍然在增加,这表明我们有一些缓冲状态,我们正在等待耗尽。这是可能的,例如,如果我们在等待窗口边界发出聚合时缓冲一些状态,并对应于管道的正常操作,如图3-15所示。
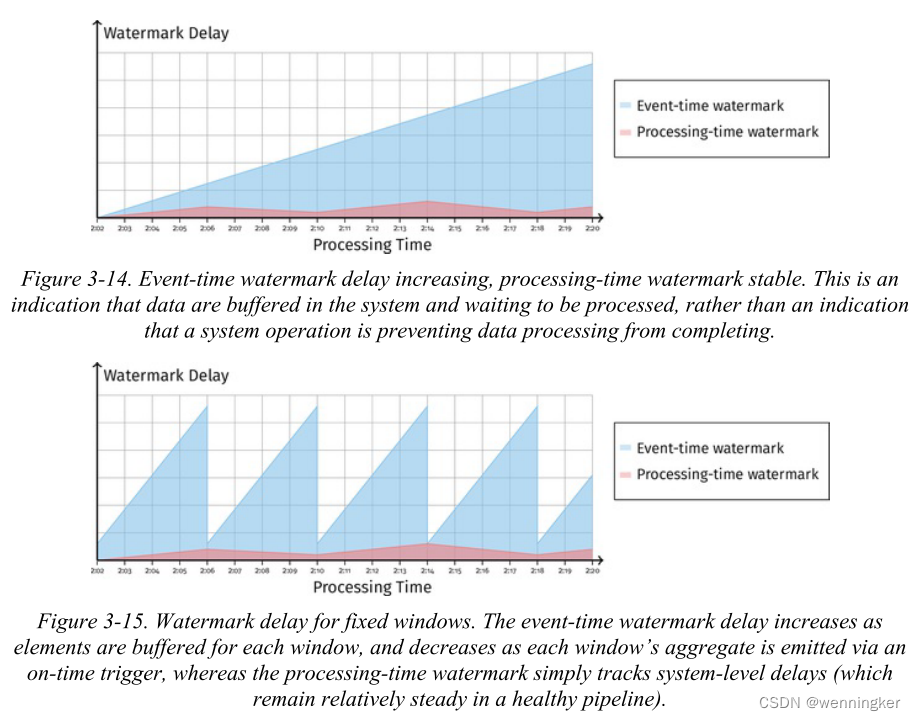
因此,处理时间水印是区分系统延迟和数据延迟的有效工具。除了可见性之外,我们还可以在系统实现级使用处理时间水印来处理临时状态的垃圾收集等任务(Reuven在第5章中详细讨论了这个例子)。
Case Studies
既然我们已经为水印应该如何工作奠定了基础,现在就来看看一些实际的系统,了解不同的水印机制是如何实现的。我们希望这些能够帮助我们了解真实系统中水印的延迟和正确性以及可伸缩性和可用性之间的权衡。
Case Study: Watermarks in Google Cloud Dataflow
在流处理系统中实现水印有许多可能的方法。在这里,我们简要介绍了谷歌Cloud Dataflow中的实现,这是一个完全托管的服务,用于执行Apache Beam管道。数据流包括用于定义数据处理工作流的sdk,以及用于在谷歌云平台资源上运行这些工作流的云平台托管服务。
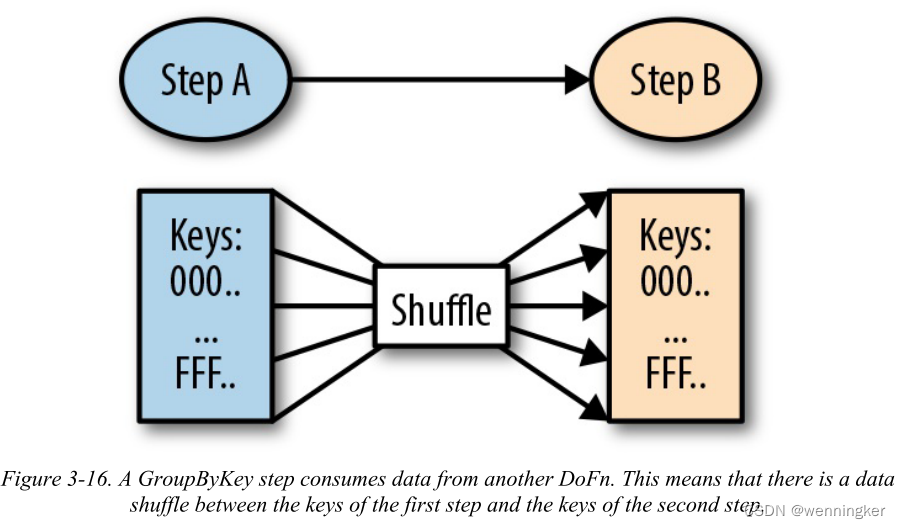
数据流分条(shards)数据处理图中的每个数据处理步骤跨越多个物理工作者,方法是将每个工作者的可用键空间分割成键范围,并将每个键范围分配给一个工作者。每当遇到具有不同键的GroupByKey操作时,必须将数据打乱到相应的键。
图3-16为带有GroupByKey的处理图的逻辑表示。
而工人的关键范围的物理分配可能如图3-17所示。
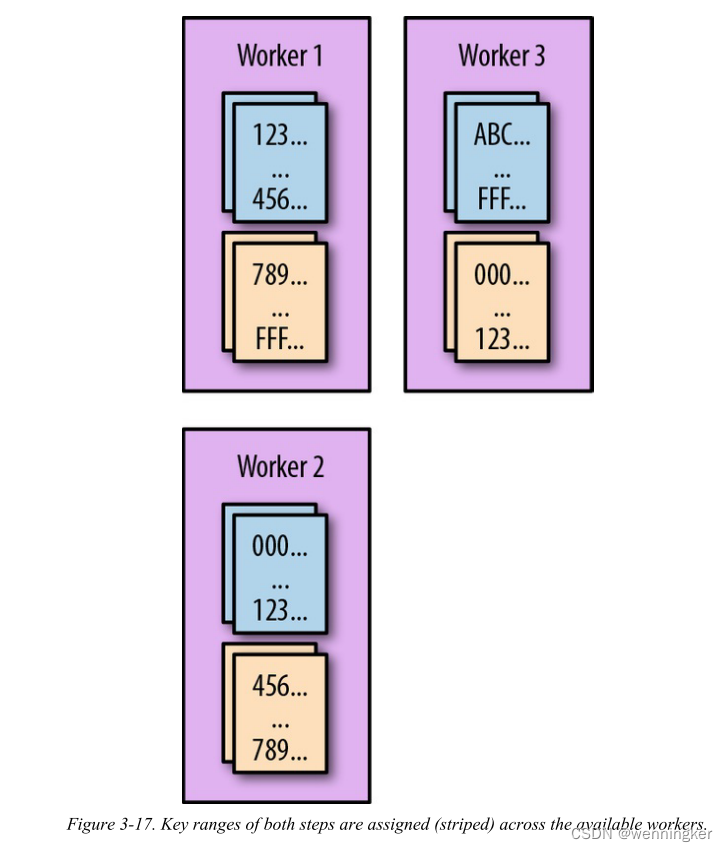
在水印传播一节中,我们讨论了为每个步骤的多个子组件维护水印。Dataflow跟踪每个组件的每个范围的水印。然后,水印聚合涉及到计算所有范围内每个水印的最小值,确保满足以下保证:
- 所有范围必须报告水印。如果一个范围没有水印,我们就不能推进水印,因为没有报告的范围必须被视为未知。
- 请确保水印是单调递增的。因为后期数据是可能的,所以如果更新水印会导致水印向后移动,我们就不能更新水印。
谷歌云数据流通过一个集中的聚合器代理执行聚合。为了提高效率,我们可以分割这个代理。从正确的角度来看,水印聚合器可以作为关于水印的“单一真相来源”。
确保分布式水印聚合的正确性是一个挑战。最重要的是不提前水印,因为提前水印会将准时数据转化为延迟数据。具体来说,当物理分配被激活给工人时,工人维护了绑定到键范围的持久状态的租约,确保只有一个工人可以改变键的持久状态。为了保证水印的正确性,我们必须确保每个来自工作进程的水印更新只有在工作进程仍然保持其持久状态的租约的情况下才被允许进入聚合;因此,水印更新协议必须考虑到国家所有权租赁的有效性。
Case Study: Watermarks in Apache Flink
Apache Flink是一个开源流处理框架,用于分布式、高性能、始终可用和精确的数据流应用程序。使用Flink runner运行Beam程序是可能的。在这样做的过程中,Beam依赖于流处理概念的实现,比如Flink中的水印。与谷歌Cloud Dataflow通过集中的水印聚合代理实现水印聚合不同,Flink执行的是带内水印跟踪和聚合。
为了理解这是如何工作的,让我们来看看Flink管道,如图3-18所示。
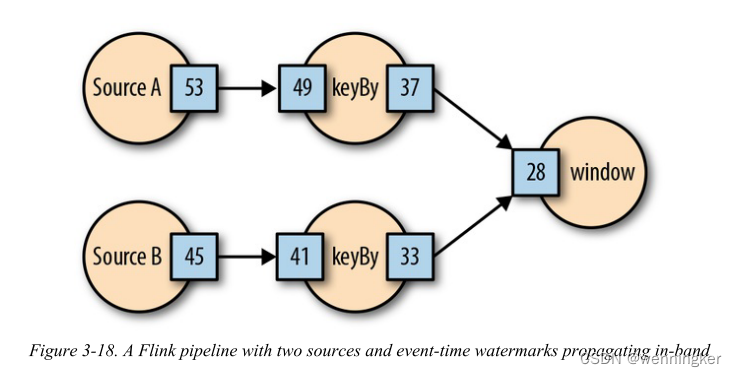
在这个管道中,数据由两个源生成。这些源也都生成水印“检查点”,并在带内与数据流同步发送。这意味着,当源a发出时间戳为“53”的水印检查点时,它保证源a不会发出时间戳为“53”的非延迟数据消息。下游的“keyBy”操作符使用输入数据和水印检查点。随着新的水印检查点被消耗,下游操作人员的水印视图被提升,并且可以为下游操作人员发出新的水印检查点。
这种在数据流的带内发送水印检查点的选择与云数据流方法不同,云数据流方法依赖于中心聚合,并导致了一些有趣的权衡。带内水印的一些优点如下:
降低水印传播延迟,以及极低延迟水印
-因为没有必要让水印数据遍历多个跳点并等待中心聚合,所以使用带内方法可以更容易地实现非常低的延迟。
水印聚合没有单点故障
中心水印聚合代理的不可用性将导致整个流水线上的水印延迟。在带内方法中,部分通道的不可用不会导致整个通道的水印延迟。
固有的可扩展性
尽管云数据流在实践中可以很好地扩展,但与带内水印的隐式可伸缩性相比,通过集中式水印聚合服务实现可伸缩性需要更高的复杂度。
下面是带外水印聚合的一些优点:
Single source of “truth”
对于可调试性、监视和其他应用程序(比如基于管道进度的输入节流)来说,拥有一个可以出售水印值的服务比拥有隐含在流中的水印更有优势,系统的每个组件都有自己的部分视图。
Source watermark creation
一些源水印需要全局信息。例如,源可能暂时处于空闲状态,具有较低的数据速率,或者需要关于源或其他系统组件的带外信息来生成水印。这在中央服务中更容易实现。有关示例,请参见下面关于谷歌云Pub/Sub的源水印的案例研究。