目录
一、IDEA操作HBase数据库
(一)添加依赖
(二)配置log4j
(三)IDEA连接HBase并插入数据
1.代码实现
2.查看命名空间的表
(四)java操作HBase数据库——单元测试
1.导包
2.初始化
3.关闭连接
4.创建命名空间
5.创建表
6.删除命名空间下的指定表
7.查看所有的命名空间
8.往表中新增数据
9.get查询数据
10.全表扫描
二、HBase与 Hive 的集成
(一)停止hive服务并配置hive-site.xml
(二)将HBase的lib目录下所有的文件复制到Hive的lib目录下
(三)不覆盖路径复制
(四)删除HBase/lib目录下低版本的guava
(五)继续配置hive-site.xml
(六)重新启动Hive
(七)HQL创建表
1.student表
2.kb21_student表
3.car表
一、IDEA操作HBase数据库
(一)添加依赖
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.3.5</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>2.3.5</version>
</dependency>(二)配置log4j
hadoop.root.logger=DEBUG, console
log4j.rootLogger = ERROR, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.out
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{2}: %m%n(三)IDEA连接HBase并插入数据
1.代码实现
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HConstants;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
public static void main( String[] args )
{
// 配置HBase信息,连接HBase数据库
Configuration conf = new Configuration();
// 2. 添加配置参数
conf.set(HConstants.HBASE_DIR,"hdfs://lxm147:9000/hbase");
conf.set(HConstants.ZOOKEEPER_QUORUM,"lxm147");
conf.set(HConstants.CLIENT_PORT_STR,"2181");
try {
Connection conn = ConnectionFactory.createConnection(conf);
System.out.println(conn);// hconnection-0x55182842
Table stuTb = conn.getTable(TableName.valueOf("bigdata:student"));
// 打印表名
System.out.println(stuTb.getName());// bigdata:student
// 插入数据
Put put = new Put(Bytes.toBytes("rowkey11"));
put.addColumn("baseinfo".getBytes(),"name".getBytes(),"zhangsan".getBytes());
put.addColumn("baseinfo".getBytes(),"age".getBytes(),"20".getBytes());
put.addColumn("baseinfo".getBytes(),"birthday".getBytes(),"2003-01-01".getBytes());
put.addColumn("schoolinfo".getBytes(),"schoolname".getBytes(),"清华大学".getBytes());
put.addColumn("schoolinfo".getBytes(),"address".getBytes(),"北京".getBytes());
stuTb.put(put);
conn.close();
} catch (IOException e) {
e.printStackTrace();
}
}2.查看命名空间的表
插入成功

(四)java操作HBase数据库——单元测试
1.导包
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import static org.junit.Assert.assertTrue;2.初始化
public class AppTest {
static Configuration config = null;
private Connection conn = null;
private Admin admin = null;
@Before
public void init() throws Exception {
System.out.println("执行init()方法");
config = HBaseConfiguration.create();
config.set(HConstants.HBASE_DIR, "hdfs://lxm147:9000/hbase");
config.set(HConstants.ZOOKEEPER_QUORUM, "lxm147");
config.set(HConstants.CLIENT_PORT_STR, "2181");
conn = ConnectionFactory.createConnection(config);
admin = conn.getAdmin();
}
@Test
public void test1() {
System.out.println(conn);
System.out.println("执行test1方法");
}
}3.关闭连接
@After
public void close() throws IOException {
System.out.println("执行close()方法");
if (admin != null)
admin.close();
if (conn != null)
conn.close();
}4.创建命名空间
@Test
public void createNameSpace() throws IOException {
NamespaceDescriptor kb21 = NamespaceDescriptor.create("kb21").build();
try {
admin.createNamespace(kb21);
} catch (IOException e) {
e.printStackTrace();
}
}
5.创建表
@Test
public void createTable() throws IOException {
// 创建表的描述类
TableName tableName = TableName.valueOf("kb21:student");
HTableDescriptor desc = new HTableDescriptor(tableName);
// 创建列族的描述类
HColumnDescriptor family1 = new HColumnDescriptor("info1");
HColumnDescriptor family2 = new HColumnDescriptor("info2");
desc.addFamily(family1);
desc.addFamily(family2);
admin.createTable(desc);
}6.删除命名空间下的指定表
@Test
public void deleteTable() throws IOException {
admin.disableTable(TableName.valueOf("kb21:student"));
admin.deleteTable(TableName.valueOf("kb21:student"));
}7.查看所有的命名空间
@Test
public void getAllNamespace() throws IOException {
String[] nps = admin.listNamespaces();
String s = Arrays.toString(nps);
System.out.println(s);
// 获取命名空间下的表
List<TableDescriptor> tableDesc = admin.listTableDescriptorsByNamespace("kb21".getBytes());
System.out.println(tableDesc.toString());
}
8.往表中新增数据
@Test
public void insertData() throws IOException {
Table table = conn.getTable(TableName.valueOf("kb21:student"));
Put put = new Put(Bytes.toBytes("student1"));
put.addColumn("info1".getBytes(), "name".getBytes(), "zs".getBytes());
put.addColumn("info2".getBytes(), "school".getBytes(), "fudan".getBytes());
table.put(put);
Put put2 = new Put(Bytes.toBytes("student2"));
put2.addColumn("info1".getBytes(), "name".getBytes(), "zs111".getBytes());
put2.addColumn("info2".getBytes(), "school".getBytes(), "fudan111".getBytes());
Put put3 = new Put(Bytes.toBytes("student3"));
put3.addColumn("info1".getBytes(), "name".getBytes(), "zs222".getBytes());
put3.addColumn("info2".getBytes(), "school".getBytes(), "fudan222".getBytes());
List<Put> list = new ArrayList<>();
list.add(put2);
list.add(put3);
table.put(list);
}9.get查询数据
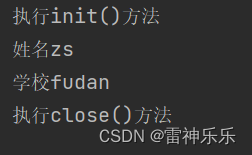
@Test
public void queryData() throws IOException {
Table table = conn.getTable(TableName.valueOf("kb21:student"));
Get get = new Get(Bytes.toBytes("student1"));
Result result = table.get(get);
byte[] value = result.getValue(Bytes.toBytes("info1"), Bytes.toBytes("name"));
System.out.println("姓名" + Bytes.toString(value));
value = result.getValue(Bytes.toBytes("info2"), Bytes.toBytes("school"));
System.out.println("学校" + Bytes.toString(value));
}
10.全表扫描
@Test
public void scanData() throws IOException {
Table table = conn.getTable(TableName.valueOf("kb21:student"));
Scan scan = new Scan();
ResultScanner scanner = table.getScanner(scan);
for (Result result :
scanner) {
// 打印表名
System.out.println(Bytes.toString(result.getRow()));
// 打印表数据
byte[] value = result.getValue(Bytes.toBytes("info1"), Bytes.toBytes("name"));
System.out.println("姓名" + Bytes.toString(value));
value = result.getValue(Bytes.toBytes("info2"), Bytes.toBytes("school"));
System.out.println("学校" + Bytes.toString(value));
System.out.println("-----------------------");
}
}
二、HBase与 Hive 的集成
(一)停止hive服务并配置hive-site.xml
[root@lxm147 ~]# vim /opt/soft/hive312/conf/hive-site.xml
<property>
<name>hive.zookeeper.quorum</name>
<value>192.168.180.147</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>192.168.180.147</value>
</property>
(二)将HBase的lib目录下所有的文件复制到Hive的lib目录下
[root@lxm147 conf]# cp /opt/soft/hbase235/lib/* /opt/soft/hive312/lib/(三)不覆盖路径复制

(四)删除HBase/lib目录下低版本的guava
如果hive的lib目录下有两个guava,需要删除低版本guava
rm -rf /opt/soft/hive312/lib/guava-11.0.2.jar
将Hive/lib的guava复制到HBase/lib目录下
cp /opt/soft/hive312/lib/guava-27.0-jre.jar /opt/soft/hbase235/lib(五)继续配置hive-site.xml
[root@lxm147 ~]# vim /opt/soft/hive312/conf/hive-site.xml
<property>
<name>hive.aux.jars.path</name>
<value>file:///opt/soft/hive312/lib/hive-hbase-handler-3.1.2.jar,file:///opt/soft/hive312/lib/zookeeper-3.4.6.jar,file:///opt/soft/hive312/lib/hbase-client-2.3.5.jar,file:///opt/soft/hive312/lib/hbase-common-2.3.5-tests.jar,file:///opt/soft/hive312/lib/hbase-server-2.3.5.jar,file:///opt/soft/hive312/lib/hbase-common-2.3.5.jar,file:///opt/soft/hive312/lib/hbase-protocol-2.3.5.jar,file:///opt/soft/hive312/lib/htrace-core-3.2.0-incubating.jar</value>
(六)重新启动Hive
刷新DataGrip,不报错就说明HBase映射到Hive成功!
(七)HQL创建表
1.student表
use default;
drop table if exists student;
create external table student(
id string,
name string,
age int,
birthday string,
schoolname string,
address string
)stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with
serdeproperties ("hbase.columns.mapping"=":key,baseinfo:name,baseinfo:age,baseinfo:birthday,schoolinfo:schoolname,schoolinfo:address")
tblproperties ("hbase.table.name"="bigdata:student");
select * from student;

2.kb21_student表
drop table if exists kb21_student;
create external table kb21_student(
id string,
name string,
school string
)stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with
serdeproperties ("hbase.columns.mapping"=":key,info1:name,info2:school")
tblproperties ("hbase.table.name"="kb21:student");
select * from kb21_student;
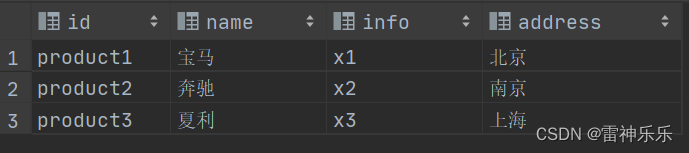
3.car表
Xshell端
create 'bigdata:car','product'
put 'bigdata:car','product1','product:name','宝马'
put 'bigdata:car','product1','product:info','x1'
put 'bigdata:car','product1','product:address','北京'
put 'bigdata:car','product2','product:name','奔驰'
put 'bigdata:car','product2','product:info','x2'
put 'bigdata:car','product2','product:address','南京'
put 'bigdata:car','product3','product:name','夏利'
put 'bigdata:car','product3','product:info','x3'
put 'bigdata:car','product3','product:address','上海'
scan 'bigdata:car'
ROW COLUMN+CELL
product1 column=product:address, timestamp=2023-03-08T14:23:46.731, value=\xE5\x8C\x97\xE4\xBA\xAC
product1 column=product:info, timestamp=2023-03-08T14:18:12.235, value=x1
product1 column=product:name, timestamp=2023-03-08T14:22:49.590, value=\xE5\xAE\x9D\xE9\xA9\xAC
product2 column=product:address, timestamp=2023-03-08T14:23:58.666, value=\xE5\x8D\x97\xE4\xBA\xAC
product2 column=product:info, timestamp=2023-03-08T14:18:34.899, value=x2
product2 column=product:name, timestamp=2023-03-08T14:23:13.930, value=\xE5\xA5\x94\xE9\xA9\xB0
product3 column=product:address, timestamp=2023-03-08T14:24:16.804, value=\xE4\xB8\x8A\xE6\xB5\xB7
product3 column=product:info, timestamp=2023-03-08T14:19:12.294, value=x3
product3 column=product:name, timestamp=2023-03-08T14:19:03.873, value=\xE5\xA4\x8F\xE5\x88\xA9DataGrip中建表
create database bigdata;
USE bigdata;
drop table if exists car;
create external table car(
id string,
name string,
info string,
address string
)stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with
serdeproperties ("hbase.columns.mapping"=":key,product:name,product:info,product:address")
tblproperties ("hbase.table.name"="bigdata:car");
select * from car;