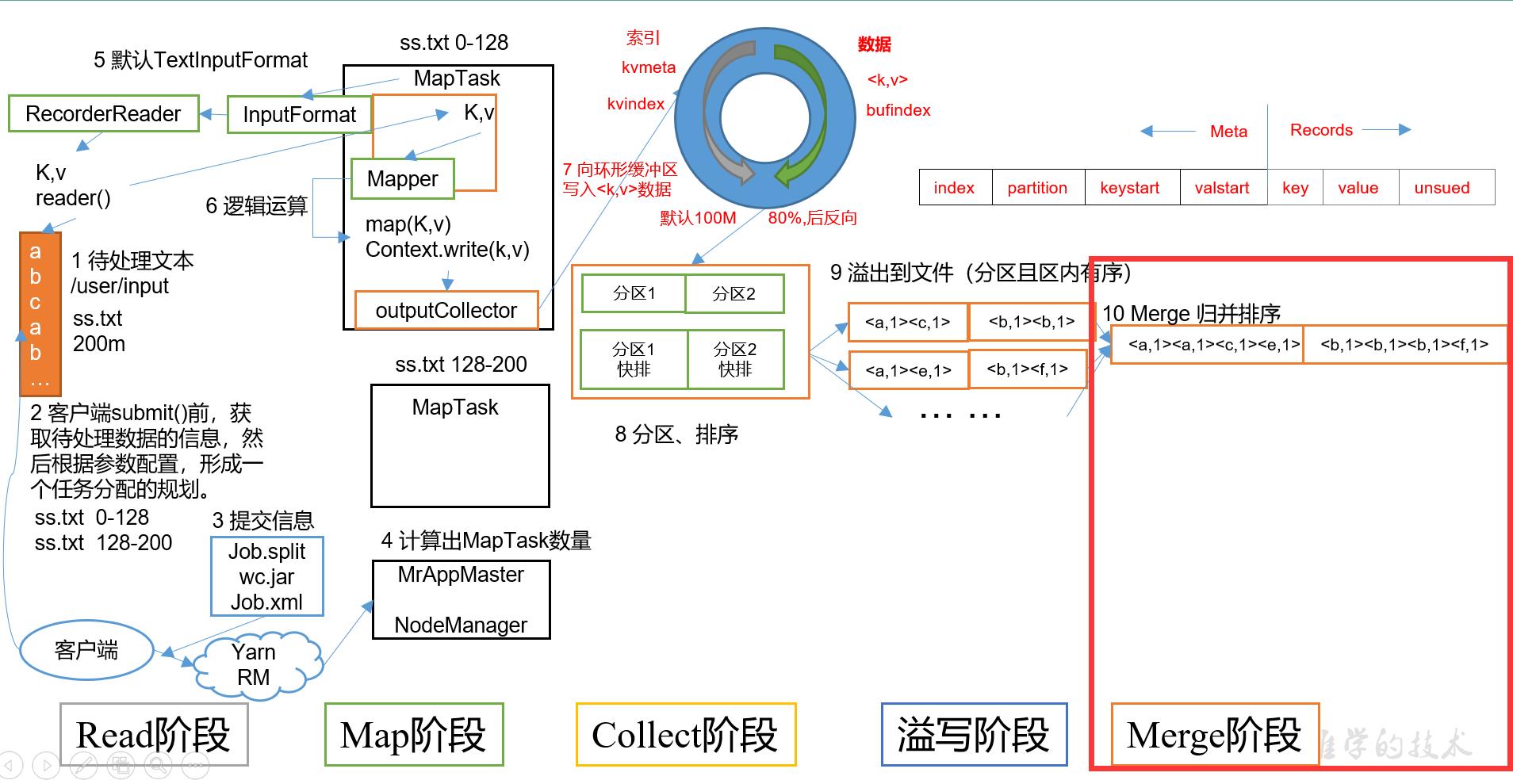
文章目录
- 进程间通信介绍
- 进程间通信的本质
- 进程间通信的目的
- 进程间通信的分类
- 管道
- 匿名管道
- 匿名管道原理
- pipe函数
- 匿名管道通信的4情况5特点
- 读取堵塞
- 写入堵塞
- 写端关闭
- 读端关闭
- 总结
进程间通信介绍
进程间通信简称IPC(Interprocess communication):进程间通信就是在不同进程之间传播或交换信息
为什么要有进程通信?
因为进程具有独立性,一个进程看不到另一个进程的资源和信息, 那么它们直接交互数据成本很高!操作系统需要设计特定的通信方式来解决这个问题!
进程间通信的本质
两个进程需要相互通信, 首先它们就需要看到一份 公共的资源, 这个资源不属于二者任意一个进程,因为如果属于它们,进程时具有独立性的,那这就不叫公共资源了,这份资源由OS提供,属于OS.
所谓通信,实际就是一个进程往里面放数据,一个进程从里面取出数据, 这里所谓的资源就要有缓存的功能, 本质上,这就是一段内存. 这段内存可以由不同的结构提供, 如:文件方式(管道), 消息队列,…
正是因为提供的方式有很多种,所以通信方式有很多种
结论: 进程间通信的前提是: 由OS参与并提供一份所有通信进程都能看到的公共资源 进程间通信的本质就是让不同的进程看到同一份资源
进程间通信的目的
进程之间会存在特定的协同工作的场景
- 数据传输:一个进程要把自己的数据交给另一个进程,让其继续进行处理
- 资源共享:多个进程之间共享同样的资源
- 通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件(如进程终止时要通知父进程)
- 进程控制:有些进程希望完全控制另一个进程的执行(如Debug进程),此时控制进程希望能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变
进程间通信的分类
资源组织形式不同,也就造成了存在很多种通信方式
-
管道
- 匿名管道 命名管道
-
System V IPC
- System V 消息队列 System V 共享内存 System V 信号量
-
POSIX IPC
- 消息队列 共享内存 信号量 互斥量 条件变量 读写锁
管道
什么是管道
管道是Unix中最古老的进程间通信的形式,我们把从一个进程连接到另一个进程的数据流称为一个“道
例子: 统计目前云服务器有多少个用户在使用了
who命令:查看当前云服务器的登录用户 (一行显示一个用户) wc -l:统计当前的行数

其中who和wc命令都是程序,当它们运行起来的时候就变成了两个进程
那上面的原理是什么呢?
who进程通过标准输出 把数据打包到"管道中" (把本来应该写到标准输出的东西写到管道中),wc进程通过标准输入从"管道"当中读取数据, 这样就完成了数据的传输,然后再对数据进行处理

再例如:

一个进程先把数据写到文件tmp.txt, 然后再由另一个进程读取,此时也可以认为echo和cat进行了进程间通信
匿名管道
匿名管道可以用于进程间通信,但是仅限于本地父子进程之间的通信
因为进程间通信的本质就是让不同的进程看到同一份资源 ,所以匿名管道实现父子间相互通信,原理就是让这两个父子进程先看到同一份资源! 然后父子进程就可以对该文件进行写入或者读取,从而实现父子间进程通信
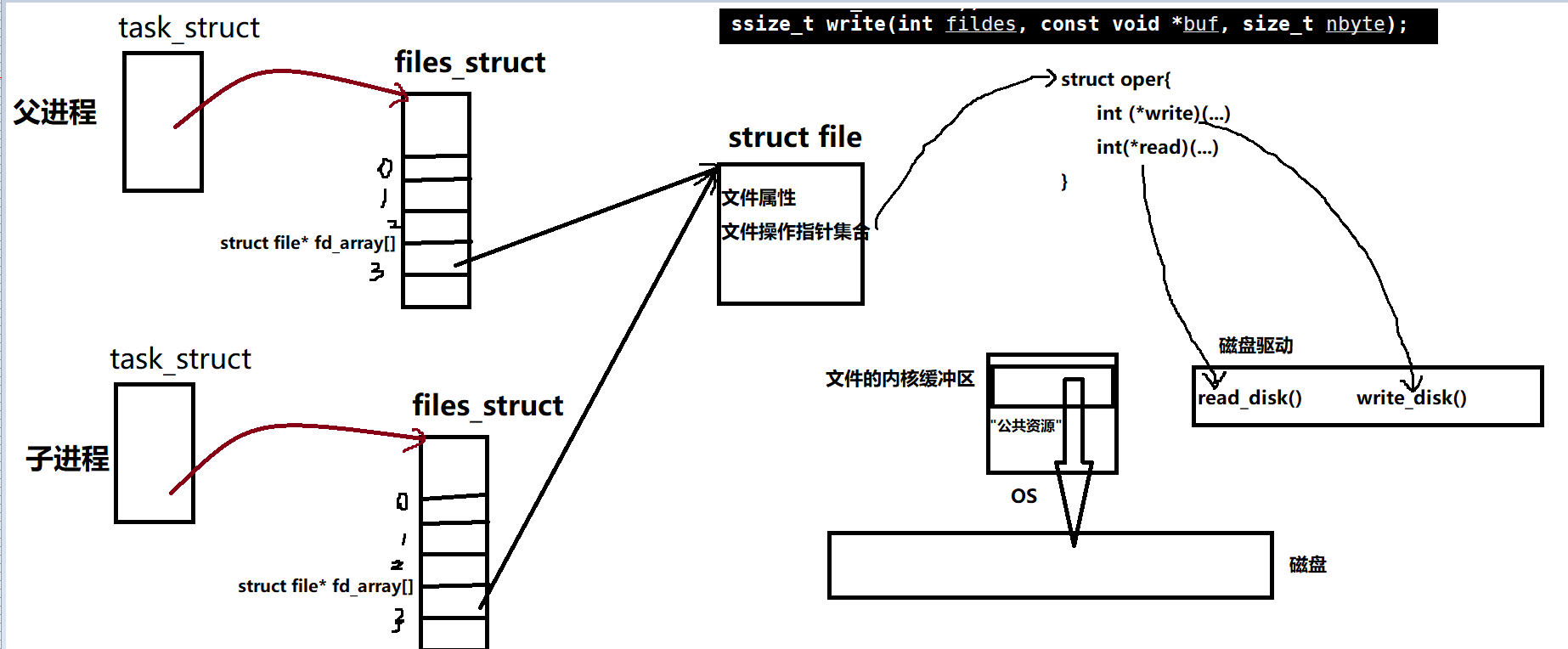
问:子进程和父进程是不是共享一个文件描述符数组?
子进程单独拷贝一份!因为这个结构是属于文件的还是进程的? 属于进程的,因为是为了让我这个进程能看到打开了多少个已经打开的文件 进程和文件建立映射关系的结构, 既然属于进程,那子进程也要有自己的一份,因为进程具有独立性
创建子进程的时候,父进程和子进程各自都有自己的一套结构,即子进程要有自己的PCB 和文件描述符表结构
那我父进程指向的文件,子进程要不要拷贝一份、
不需要! 这个文件和创建进程没有关系
父子进程是两个相互独立的进程, 子进程是以父进程为模板初始化自己的files_struct, 但是并不是和父进程共用同一个files_struct! 但是struct file这个结构并不会拷贝, 父子进程指向同一个, 因为打开的文件和进程无关
- 创建子进程会拷贝父进程的 files_struct 结构体,也就是继承父进程的文件数组(文件描述符表),子进程也会默认打开父进程打开的文件
父子进程指向同一份文件,文件读写会经过内核缓冲区,同时避免触发缓冲区的刷新机制,使得数据只停留在缓冲区内,父子进程就可以读写缓冲区的内容了 ,该缓冲区就是操作系统提供给进程通信用的公共资源
write这个系统调用函数,实际上干了两件事: 1.将数据拷贝到内核缓冲区 2.触发底层的写入函数,在合适的时候刷新到外设 此时父子进程就可以看到同一份公共资源"struct file":同一个文件
注意:
- 这里父子进程看到的同一份文件资源是由操作系统来维护的,当父子进程对该文件进行写入操作时,该文件缓冲区当中的数据并不会进行写时拷贝
- 此时管道虽然用的是文件的方案,但操作系统一定不会把进程进行通信的数据刷新到磁盘当中,因为这样做有IO参与会降低效率
- 即:这种文件是一批不会把数据写到磁盘当中的文件
- 磁盘文件和内存文件不一定是一一对应的,有些文件只会在内存当中存在,不会在磁盘当中存在
匿名管道原理
1)父进程创建管道,对同一个文件分别以读和写的方式打开
2)fork创建子进程
- 子进程继承父进程资源,同样会以读写的方式打开文件, 所以双方进程看到同一份资源
3)因为管道是一个只能单向通信的信道,父子进程需要关闭对应读写端 ,需要确认父子进程谁读谁写
- 父进程关闭写端,子进程关闭读端 || 父进程关闭读端,子进程关闭写端
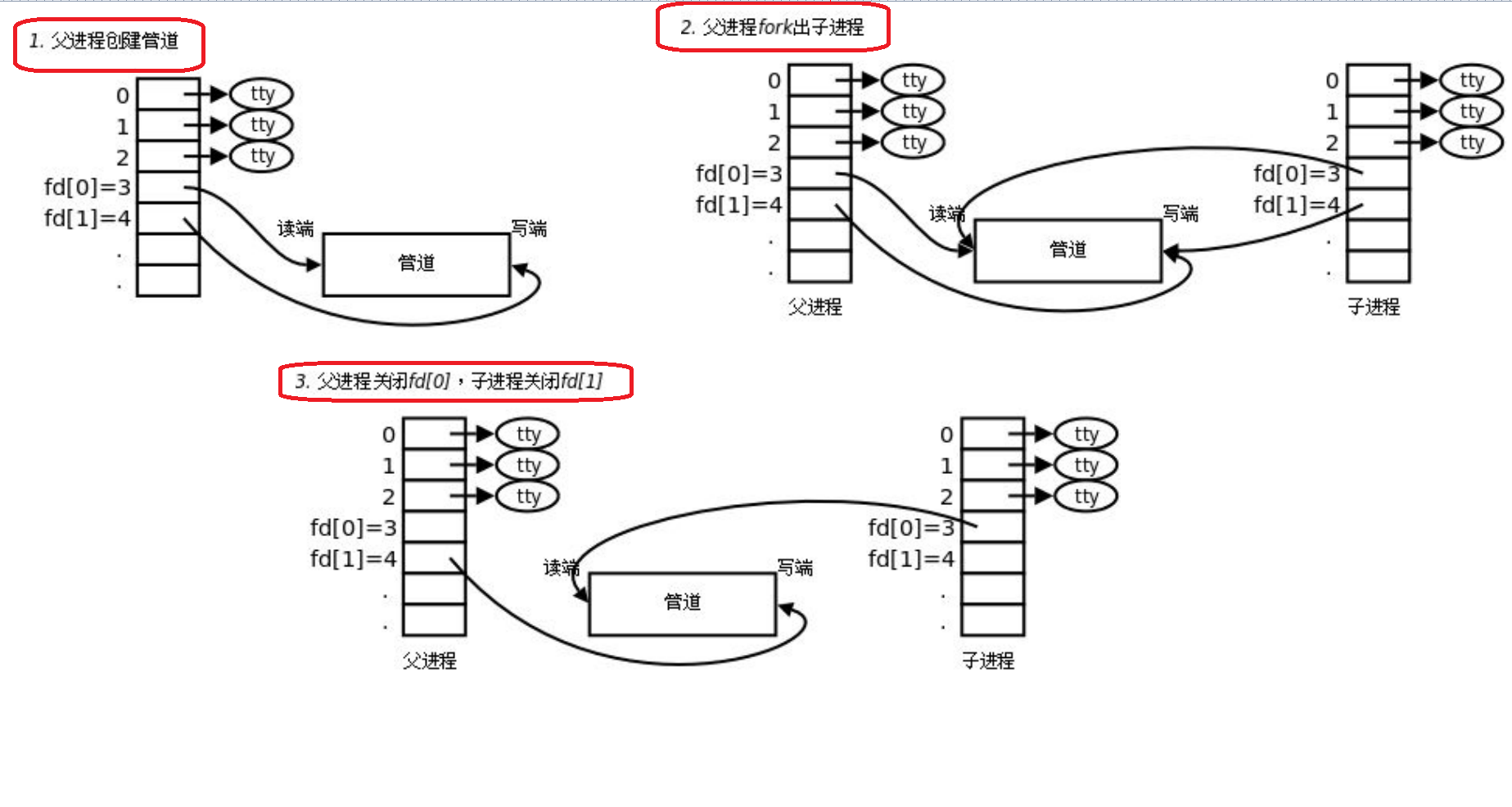
注意:从管道写端写入的数据会被内核缓冲, 直到从管道的读端被读取
pipe函数
作用:创建匿名管道
#include <unistd.h>
int pipe(int fildes[2]);
1)参数 : 一个输出型参数, 数组fildes用于返回两个指向管道读端和写端的文件描述符
| 含义: | |
|---|---|
| fildes[0] | 管道读端的文件描述符 |
| fildes[1] | 管道写端的文件描述符 |
如何记忆呢? 0是嘴:读取端 1是一支笔:写入端
2)返回值: 管道创建成功返回0,失败返回-1
我们来搞一个例子: 父进程读取,子进程写入
首先我们先贴出我们之后要使用的函数:
| 函数 | 头文件 | 函数原型 |
|---|---|---|
| fork | #include <unistd.h> | pid_t fork(void); |
| close | #include <unistd.h> | int close(int fd); |
| exit | #include <stdlib.h> | void exit(int status); |
| write | #include <unistd.h> | ssize_t write(int fd, const void *buf, size_t count); |
| read | #include <unistd.h> | ssize_t read(int fd, void *buf, size_t count); |
| sleep | #include <unistd.h> | unsigned int sleep(unsigned int seconds); |
| waitpid | #include<sys/wait.h> | pid_t waitpid(pid_t pid, int *status, int options); |
步骤:1.创建管道 2.创建子进程 3.关闭对应的读写端
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
int main()
{
//1.创建管道
int pipefd[2] = {0};
if(pipe(pipefd) <0)
{
perror("pipe error:");
return 1;
}
printf("pipefd[0]:%d\n",pipefd[0]);
printf("pipefd[1]:%d\n",pipefd[1]);
//2.创建子进程
//3.关闭对应的读写端,创建单向信道->这里我们选择父进程读取,子进程写入
//父进程关闭pipefd[1] 子进程关闭pipefd[0]
if(fork() == 0)
{
//child
close(pipefd[0]);
exit(0);
}
//father
close(pipefd[1]);
return 0;
}

在上述的代码中,我们就实现了让双方进程看到同一份资源了
在此基础上,我们就要进行通信了,实际上,这个和文件操作,向某个fd对应的文件读写没有本质的区别!
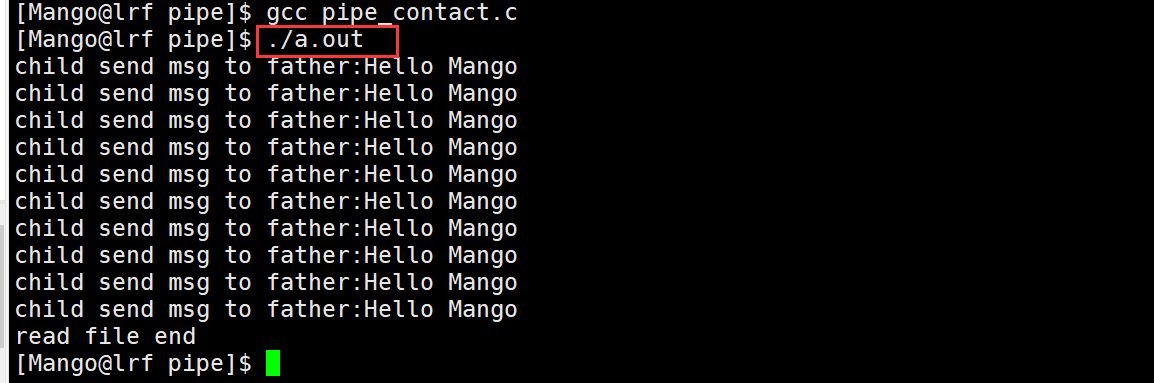
例子: 子进程向管道中写入10行数据,父进程全部读取出来
#include<stdio.h>
#include<string.h>
#include<unistd.h>
#include<stdlib.h>
int main()
{
//1.创建管道
int pipefd[2] = {0};
if(pipe(pipefd) <0)
{
perror("pipe error:");
return 1;
}
//2.创建子进程
//3.关闭对应的读写端,创建单向信道->这里我们选择父进程读取,子进程写入
//父进程关闭pipefd[1] 子进程关闭pipefd[0]
if(fork() == 0)
{
//child
close(pipefd[0]);//子进程关闭读端
//子进程向管道中写入数据
const char* msg = "Hello Mango";
int count = 10;
while(count--)
{
write(pipefd[1],msg,strlen(msg));
}
close(pipefd[1]);//子进程写入完毕,关闭写端
exit(0);
}
//father
close(pipefd[1]);//父进程关闭写端
//父进程从管道读取数据
while(1)
{
char buffer[64] = {0};//清空字符串
ssize_t s= read(pipefd[0],buffer,sizeof(buffer));
if(s>0){ //s:返回读取的字节数
buffer[s] = '\0';//在最后加一个\0
printf("child send msg to father:%s\n",buffer);
}
else if(s == 0){
printf("read file end\n");//写端关闭了
break;
}
else{
printf("read error\n");
break;
}
}
close(pipefd[0]);//父进程读取完成,关闭读端
return 0;
}
匿名管道通信的4情况5特点
接下来.我们以 父进程读取,子进程写入为例,演示下面的4种场景
读取堵塞
父进程读取,子进程写入: 子进程sleep上3s后再进行写入, 父进程不sleep读取
#include<stdio.h>
#include<string.h>
#include<unistd.h>
#include<stdlib.h>
int main()
{
//1.创建管道
int pipefd[2] = {0};
if(pipe(pipefd) <0)
{
perror("pipe error:");
return 1;
}
//2.创建子进程
//3.关闭对应的读写端,创建单向信道->这里我们选择父进程读取,子进程写入
//父进程关闭pipefd[1] 子进程关闭pipefd[0]
if(fork() == 0)
{
//child
close(pipefd[0]);//子进程关闭读端
//子进程向管道中写入数据
const char* msg = "Hello Mango";
int count = 10;
while(1)
{
write(pipefd[1],msg,strlen(msg));
sleep(3); //子进程间隔3s再写入
}
close(pipefd[1]);//子进程写入完毕,关闭写端
exit(0);
}
//father
close(pipefd[1]);//父进程关闭写端
//父进程从管道读取数据
while(1)
{
char buffer[64] = {0};//清空缓冲区
ssize_t s= read(pipefd[0],buffer,sizeof(buffer));
if(s>0){ //s:返回读取的字节数
buffer[s] = '\0';//在字符串末尾最后加一个\0
printf("child send msg to father:%s\n",buffer);
}
else if(s == 0){
printf("child quit\n");//写端关闭了
break;
}
else{
printf("read error\n");
break;
}
}
close(pipefd[0]);//父进程读取完成,关闭读端
return 0;
}
写的慢,读的快, 读端就会等待写端
写入堵塞
父进程读取,子进程写入: 子进程不断写入, 父进程间隔1s读取一下
#include<stdio.h>
#include<string.h>
#include<unistd.h>
#include<stdlib.h>
int main()
{
//1.创建管道
int pipefd[2] = {0};
if(pipe(pipefd) <0)
{
perror("pipe error:");
return 1;
}
//2.创建子进程
//3.关闭对应的读写端,创建单向信道->这里我们选择父进程读取,子进程写入
//父进程关闭pipefd[1] 子进程关闭pipefd[0]
if(fork() == 0)
{
//child
close(pipefd[0]);//子进程关闭读端
//子进程向管道中写入数据
const char* msg = "Hello Mango";
int count = 10;
while(1)
{
write(pipefd[1],msg,strlen(msg));
}
close(pipefd[1]);//子进程写入完毕,关闭写端
exit(0);
}
//father
close(pipefd[1]);//父进程关闭写端
//父进程从管道读取数据
while(1)
{
sleep(1);//父进程间隔1s再进行读取
char buffer[64] = {0};//清空缓冲区
ssize_t s= read(pipefd[0],buffer,sizeof(buffer) -1 );//少读取一个
if(s>0){ //s:返回读取的字节数
buffer[s] = '\0';//在最后加一个\0
printf("child send msg to father:%s\n",buffer);
}
else if(s == 0){
printf("child quit\n");//写端关闭了
break;
}
else{
printf("read error\n");
break;
}
}
close(pipefd[0]);//父进程读取完成,关闭读端
return 0;
}
//注意:读取的时候少读取一个,为了避免buffer读满之后,我们在字符串末尾置\0的时候发生越界!

这种情况下,会一下子读取出很多字符,为什么呢?
因为pipe管道里面只要有空间就一直写入, 读取端只要有东西就会一直去读, 管道是面向字节流的,究竟读成什么样子也无法保证, 所以父子进程通信是需要定制协议的!
如果此时我们: 子进程一个字符一个字符的写入,并定义一个计数器进行计数,父进程不去读写会发生什么?
#include<stdio.h>
#include<string.h>
#include<unistd.h>
#include<stdlib.h>
int main()
{
//1.创建管道
int pipefd[2] = {0};
if(pipe(pipefd) <0)
{
perror("pipe error:");
return 1;
}
//2.创建子进程
//3.关闭对应的读写端,创建单向信道->这里我们选择父进程读取,子进程写入
//父进程关闭pipefd[1] 子进程关闭pipefd[0]
if(fork() == 0)
{
//child
int count = 0;//计数器
close(pipefd[0]);//子进程关闭读端
//子进程向管道中写入数据
const char* msg = "a";
while(1)
{
write(pipefd[1],msg,strlen(msg));
count ++;
printf("count:%d\n",count);
}
close(pipefd[1]);//子进程写入完毕,关闭写端
exit(0);
}
//father
close(pipefd[1]);//父进程关闭写端
//父进程从管道读取数据
while(1)
{
sleep(1);//父进程间隔1s再进行读取
//不干任何事情
}
close(pipefd[0]);//父进程读取完成,关闭读端
return 0;
}
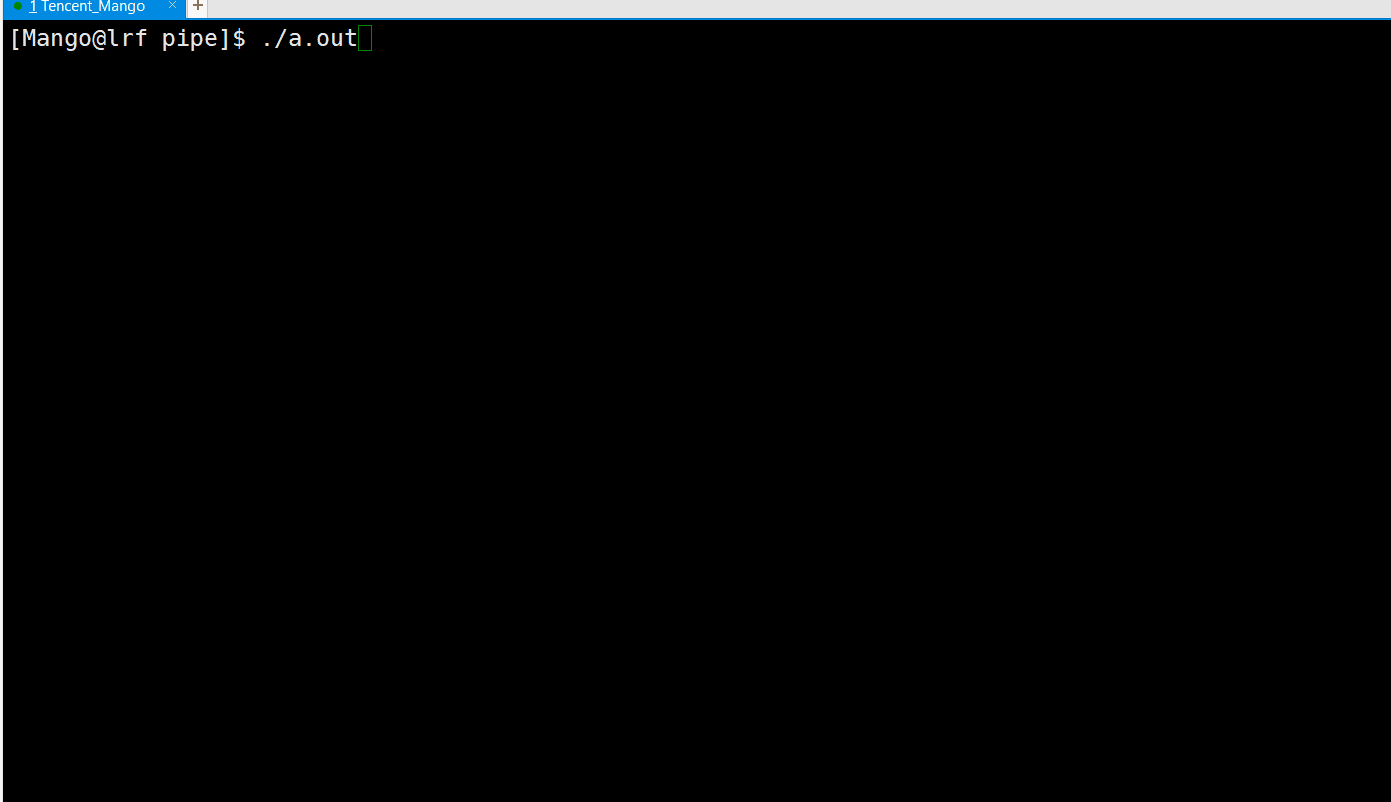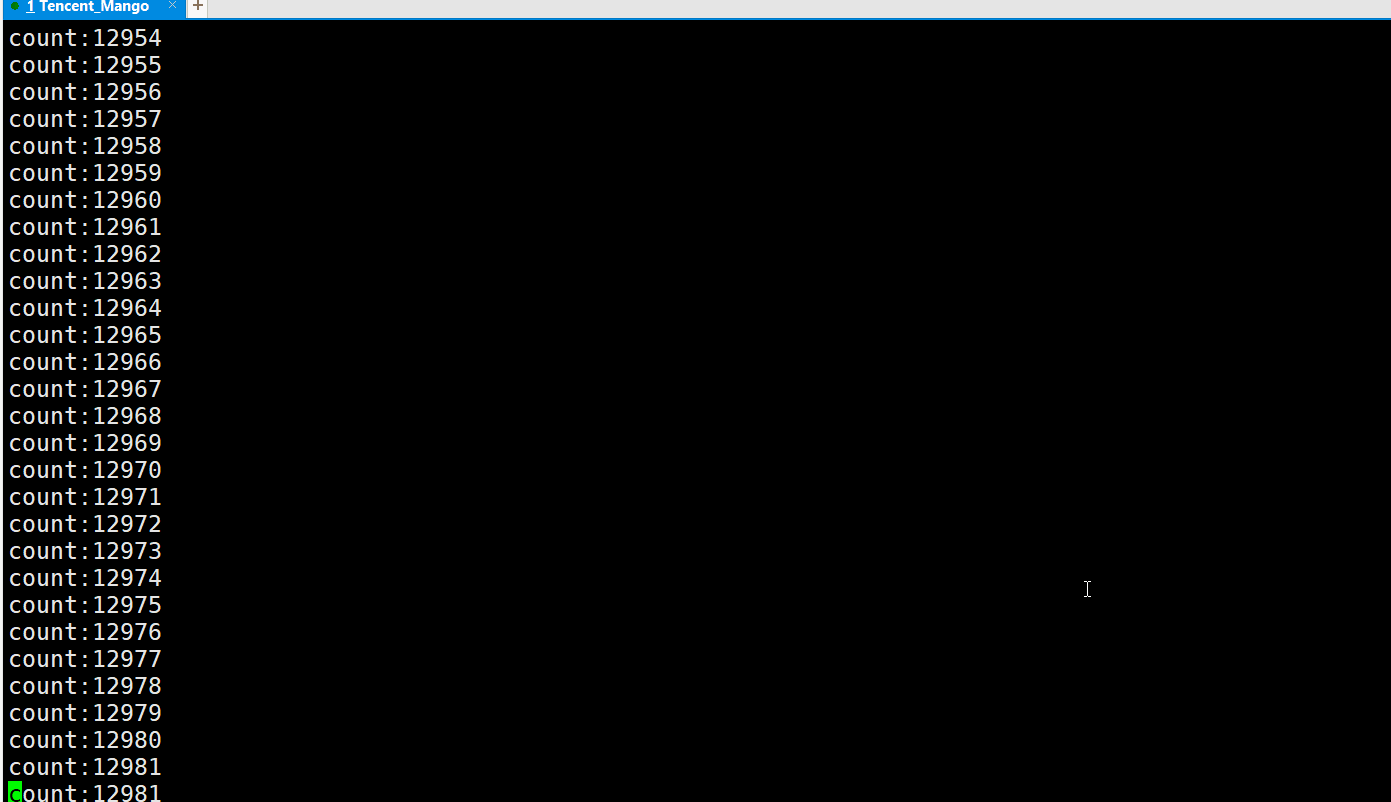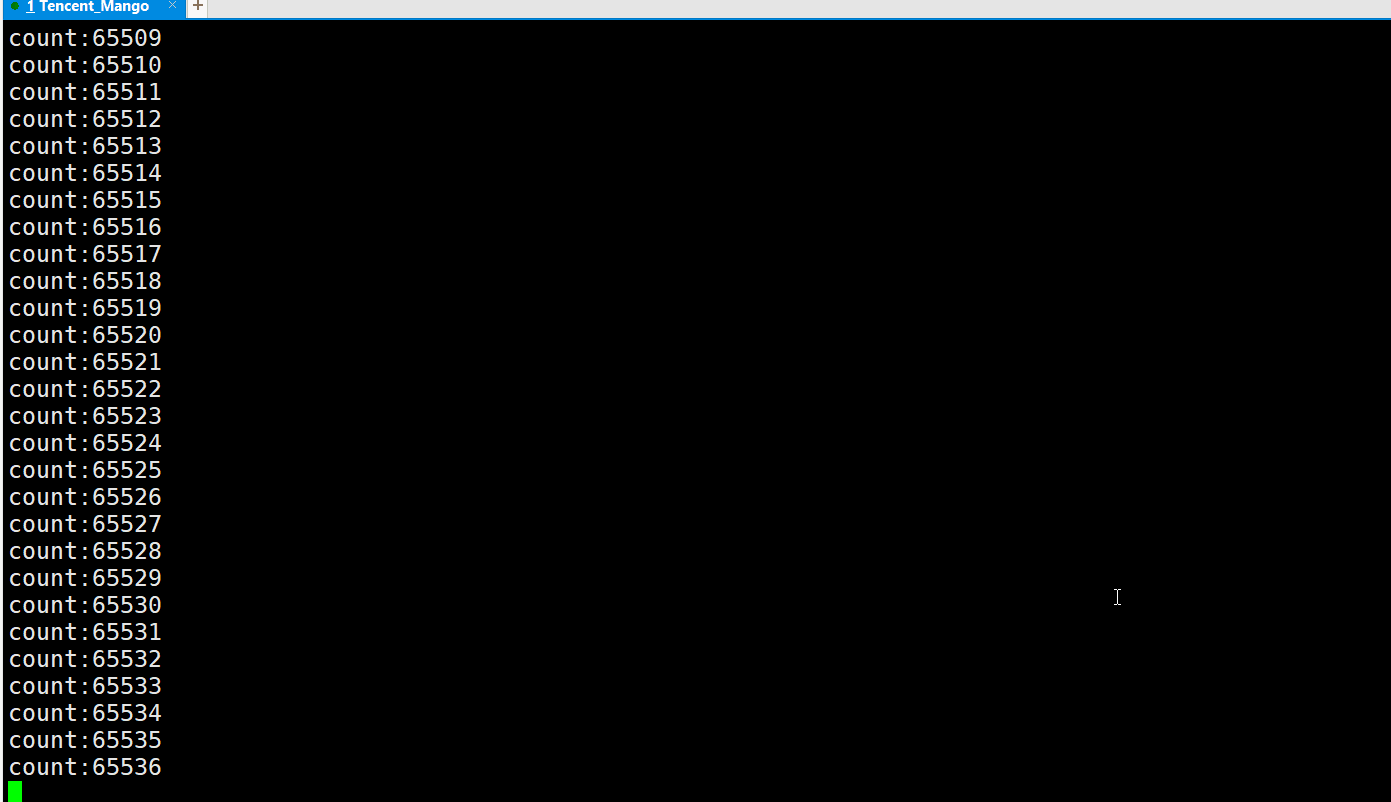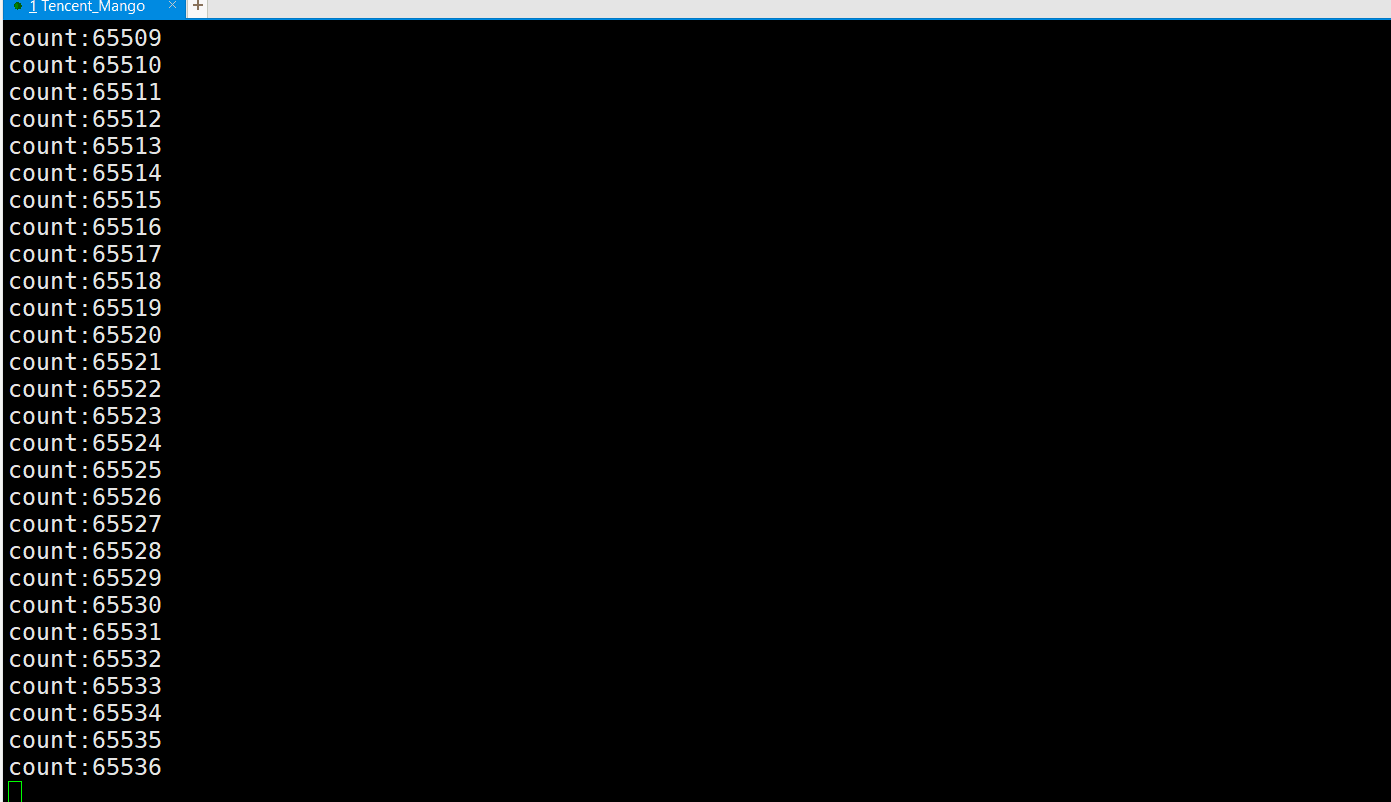
在读端进程不进行读取的情况下,写端进程最多写65536字节的数据就被操作系统挂起了,
最终程序卡在65536这个数值上, 此时写端就不再继续写入了 ,这也说明了管道是有大小的!而我们在这里也验证了当前Linux版本中管道的最大容量是65536字节. 也就是我们云服务的管道容量是64KB
问:为什么write写满了之后就不再写入了呢?为什么不可以覆盖原来的数据继续写入呢?
因为要等读取端进行读取, 覆盖等其它继续写入的做法违背了进程通信的目的, 管道是自带同步机制的,也就是父子进行读写会互相等待合适的时机
上述的代码, 如果我们读取端读走一部分后,写端是否会继续写入呢?
是! 实际上,读取端如果读取较少字节的时候,并不会触发对端写入,而是要读取一批数据之后(4kb左右),才会唤醒写端写入
#include<stdio.h>
#include<string.h>
#include<unistd.h>
#include<stdlib.h>
int main()
{
//1.创建管道
int pipefd[2] = {0};
if(pipe(pipefd) <0)
{
perror("pipe error:");
return 1;
}
//2.创建子进程
//3.关闭对应的读写端,创建单向信道->这里我们选择父进程读取,子进程写入
//父进程关闭pipefd[1] 子进程关闭pipefd[0]
if(fork() == 0)
{
//child
int count = 0;//计数器
close(pipefd[0]);//子进程关闭读端
//子进程向管道中写入数据
const char* msg = "a";
while(1)
{
write(pipefd[1],msg,strlen(msg));
count ++;
printf("count:%d\n",count);
}
close(pipefd[1]);//子进程写入完毕,关闭写端
exit(0);
}
//father
close(pipefd[1]);//父进程关闭写端
//父进程从管道读取数据
while(1)
{
sleep(1);//父进程间隔1s再进行读取
char buffer[1024*4]={0}; //4kb
ssize_t s = read(pipefd[0],buffer,sizeof(buffer));
printf("父进程读取4KB数据\n");
}
close(pipefd[0]);//父进程读取完成,关闭读端
return 0;
}

这个也是为了保护写入的原子性:
- 当要写入的数据量不大于PIPE_BUF时,Linux将保证写入的原子性
- 当要写入的数据量大于PIPE_BUF时,Linux将不再保证写入的原子性
写端关闭
父进程读取,子进程写入: 5s后,写端关闭文件描述符,此时读端会发生什么?
#include<stdio.h>
#include<string.h>
#include<unistd.h>
#include<stdlib.h>
int main()
{
//1.创建管道
int pipefd[2] = {0};
if(pipe(pipefd) <0)
{
perror("pipe error:");
return 1;
}
//2.创建子进程
//3.关闭对应的读写端,创建单向信道->这里我们选择父进程读取,子进程写入
//父进程关闭pipefd[1] 子进程关闭pipefd[0]
if(fork() == 0)
{
//child
close(pipefd[0]);//子进程关闭读端
//子进程向管道中写入数据
const char* msg = "a";
while(1)
{
write(pipefd[1],msg,strlen(msg));
//5s之后退出,关闭写端
sleep(5);
break;
}
close(pipefd[1]);//子进程写入完毕,关闭写端
exit(0);
}
//father
close(pipefd[1]);//父进程关闭写端
//父进程从管道读取数据
while(1)
{
char buffer[64] = {0};//清空缓冲区
ssize_t s = read(pipefd[0],buffer,sizeof(buffer)-1);
if(s == 0){
printf("writer quit!\n");
break;
}
else if(s>0){
buffer[s] = '\0';
printf("child says to father:%s\n",buffer);
}
else{
printf("read error\n");
break;
}
}
close(pipefd[0]);//父进程读取完成,关闭读端
return 0;
}

此时读端会直接拿到返回值0退出
读端关闭
父进程读取,子进程写入: 写端不断的写, 5s后,读端退出,此时写端会发生什么
#include<stdio.h>
#include<string.h>
#include<unistd.h>
#include<stdlib.h>
int main()
{
//1.创建管道
int pipefd[2] = {0};
if(pipe(pipefd) <0)
{
perror("pipe error:");
return 1;
}
//2.创建子进程
//3.关闭对应的读写端,创建单向信道->这里我们选择父进程读取,子进程写入
//父进程关闭pipefd[1] 子进程关闭pipefd[0]
if(fork() == 0)
{
//child
close(pipefd[0]);//子进程关闭读端
//子进程向管道中写入数据
const char* msg = "hello Mango";
while(1)
{
write(pipefd[1],msg,strlen(msg));
}
close(pipefd[1]);//子进程写入完毕,关闭写端
exit(0);
}
//father
close(pipefd[1]);//父进程关闭写端
//父进程从管道读取数据
while(1)
{
char buffer[64] = {0};//清空缓冲区
ssize_t s = read(pipefd[0],buffer,sizeof(buffer)-1);
if(s == 0){
printf("writer quit!\n");
break;
}
else if(s>0){
buffer[s] = '\0';
printf("child says to father:%s\n",buffer);
}
else{
printf("read error\n");
break;
}
//读取一条信息后休眠5s就退出
printf("reading is leaving\n");
sleep(5);
break;
}
close(pipefd[0]);//父进程读取完成,关闭读端
return 0;
}
我们这里写一个监视脚本:
while :; do ps axj | grep pipe_contact | grep -v grep; sleep 1; echo
"===================================================================="; done
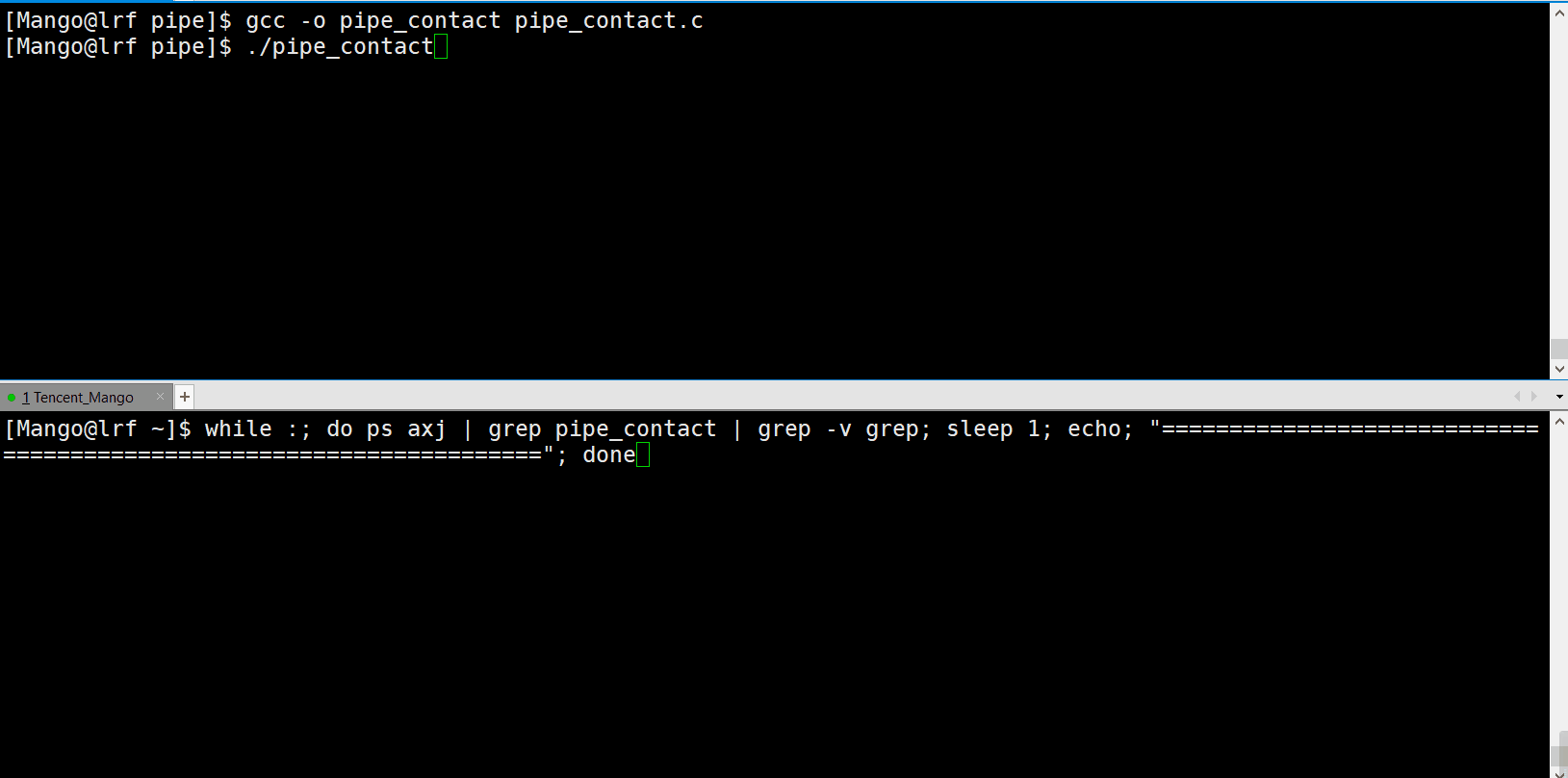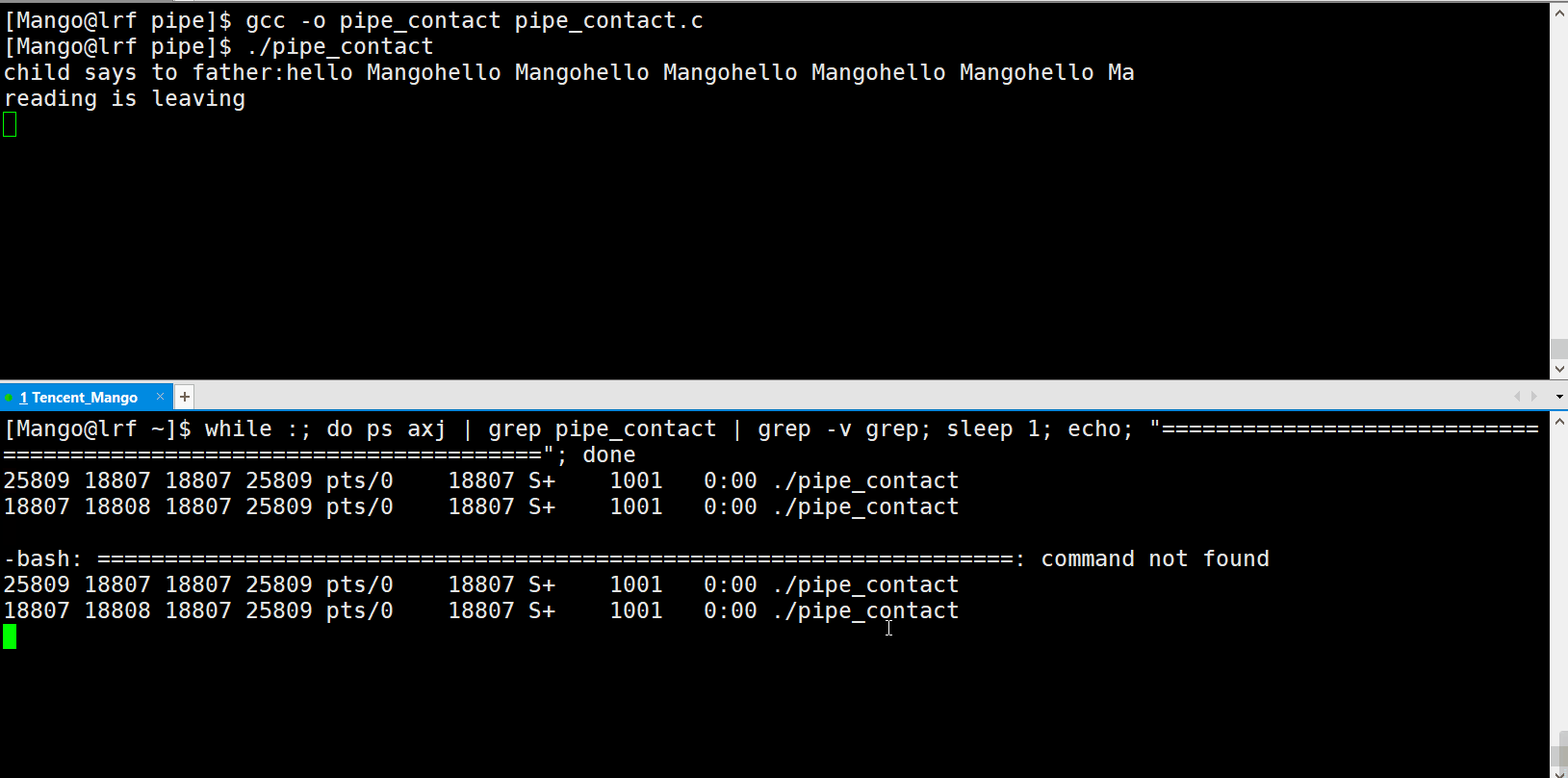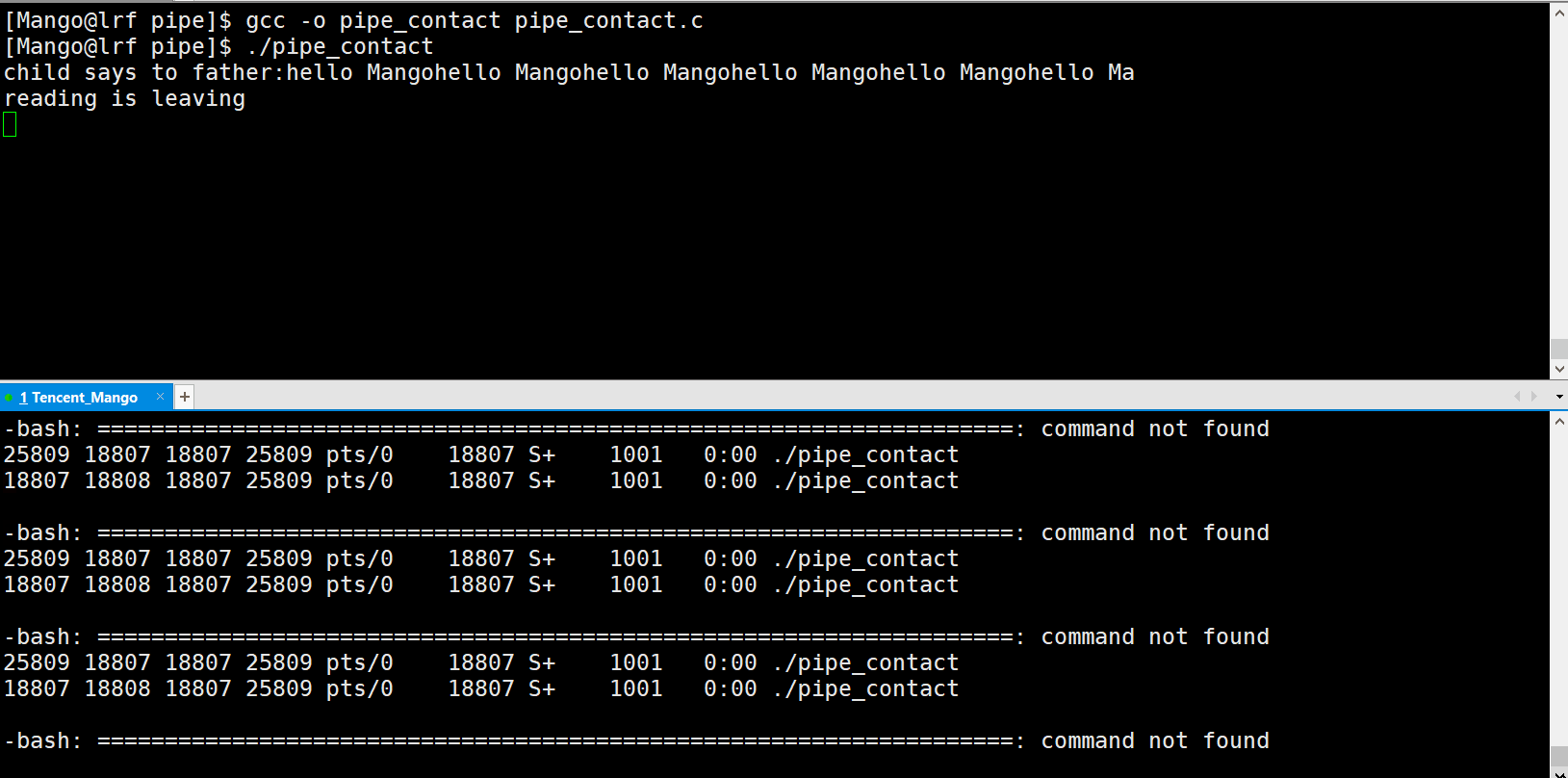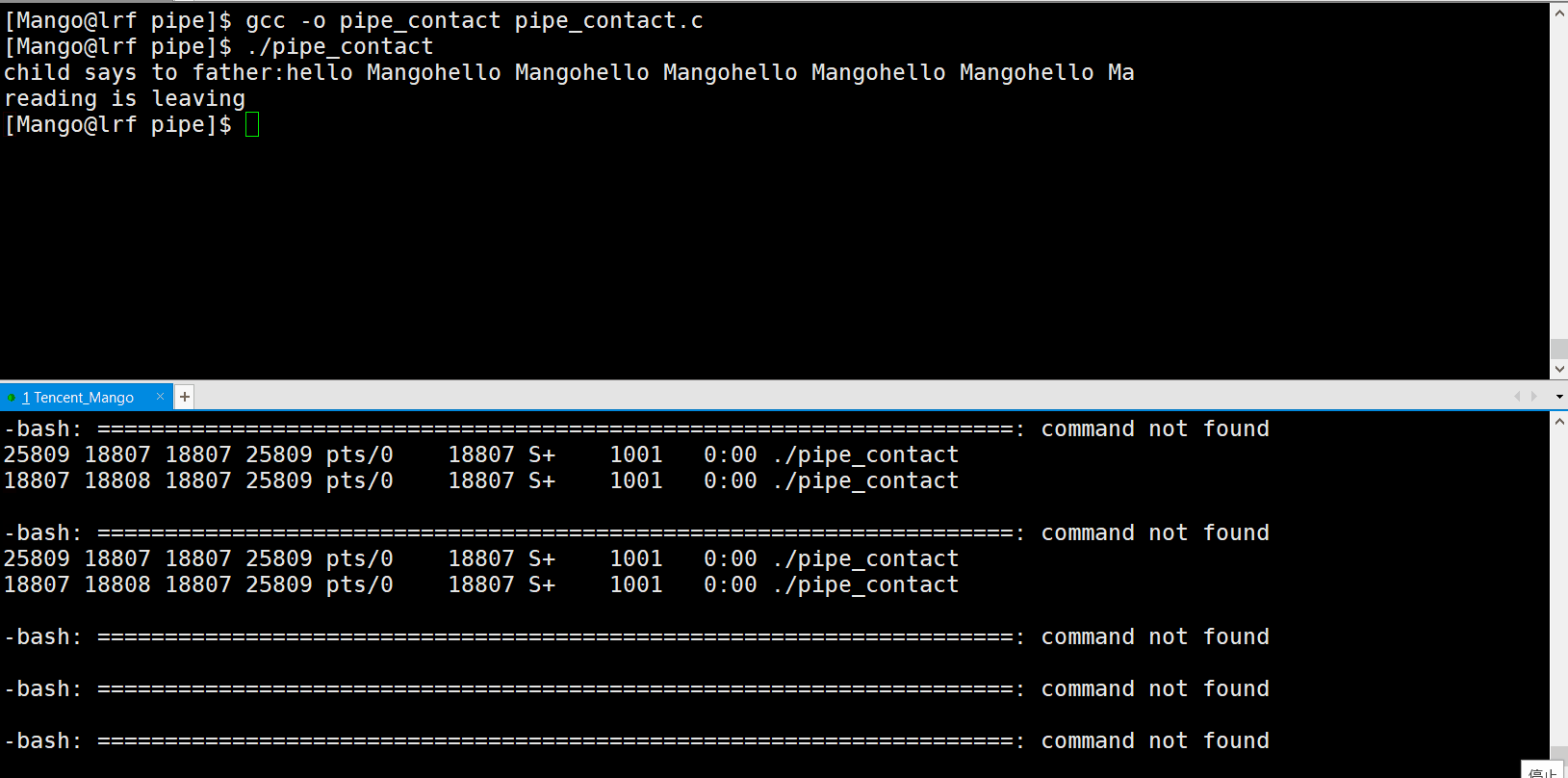
我们可以发现:读端退出后,写端也随即退出了!这是为什么呢?
因为当我们的读端关闭之后, 已经没有人读取了, 而写端还在写入,在OS角度上看,这是严重不合理的! 因为这是在浪费OS的资源 所以OS会直接终止写入进程, OS会发送13号信号SIGPIPE信号杀掉进程
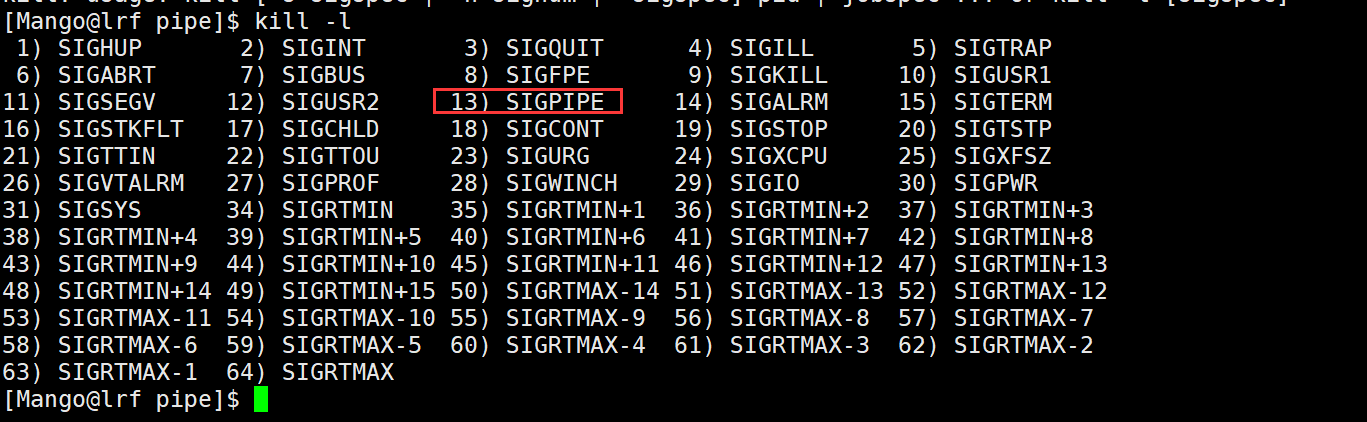
验证:我们把进程的退出码打印出来
进程异常终止会设置status的退出信号,我们可以通过让父进程通过waitpid让父进程获取子进程的退出信息 !
#include<stdio.h>
#include<string.h>
#include<unistd.h>
#include<stdlib.h>
#include<sys/wait.h>
int main()
{
//1.创建管道
int pipefd[2] = {0};
if(pipe(pipefd) <0)
{
perror("pipe error:");
return 1;
}
//2.创建子进程
//3.关闭对应的读写端,创建单向信道->这里我们选择父进程读取,子进程写入
//父进程关闭pipefd[1] 子进程关闭pipefd[0]
if(fork() == 0)
{
//child
close(pipefd[0]);//子进程关闭读端
//子进程向管道中写入数据
const char* msg = "hello Mango";
while(1)
{
write(pipefd[1],msg,strlen(msg));
}
close(pipefd[1]);//子进程写入完毕,关闭写端
exit(0);
}
//father
close(pipefd[1]);//父进程关闭写端
//父进程从管道读取数据
while(1)
{
char buffer[64] = {0};//清空缓冲区
ssize_t s = read(pipefd[0],buffer,sizeof(buffer)-1);
if(s == 0){
printf("writer quit!\n");
break;
}
else if(s>0){
buffer[s] = '\0';
printf("child says to father:%s\n",buffer);
}
else{
printf("read error\n");
break;
}
//读取一条信息后休眠5s就退出
printf("reading is leaving\n");
sleep(5);
break;
}
close(pipefd[0]);//父进程读取完成,关闭读端
//获取子进程的退出信息
int status = 0;
waitpid(-1,&status,0);//需要引用#include<sys/wait.h>头文件
printf("exit code:%d\n",(status>>8)&0xFF);
printf("signal:%d\n",status&0x7F);
return 0;
}

总结
4种场景:
- 写端不写或写得慢的情况下 ,读端进程一直读: 此时会因为管道里面没有数据可读,对应的读端进程会被挂
起,直到管道里面有数据后,读端进程才会被唤醒 - 读端不读或者读得慢的情况下 , 写端进程一直写: 那么当管道被写满后,对应的写端进程会被挂起,直到管道当中的数据被读端进程读取后,写端进程才会被唤醒
- 写端关闭: 读端进程将管道当中的数据读完后会读到0,表示读到文件结尾!就会继续执行该进程之后的代码逻辑, 而不会被挂起
- 读端进程已经将管道当中的所有数据都读取出来了,而且此后也不会有写端再进行写入了,那么此时读端进程也就可以执行该进程的其他逻辑了,而不会被挂起
- 读端关闭: 写端进程还在一直向管道写入数据,操作系统会将写端进程杀掉 ->写端收到SIGPIPE信号直接终止
- 既然管道当中的数据已经没有进程会读取了,那么写端进程的写入将没有意义,因此操作系统直接将写端进程杀掉, 而此时子进程代码都还没跑完就被终止了,属于异常退出,那子进程必然收到了某种信号
匿名管道的5个特点 :
-
管道是一个单向通信的通信管道
-
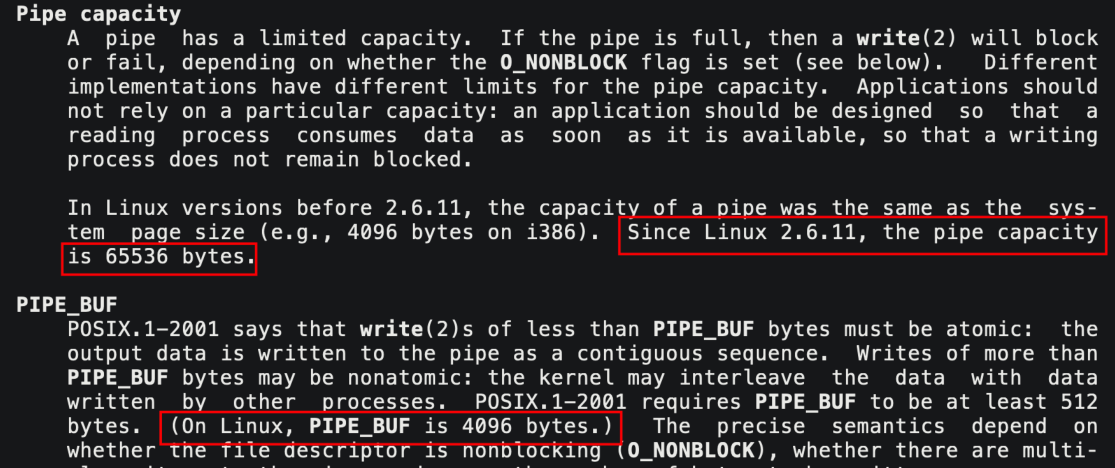
管道是面向字节流的 管道的大小是 65536 65536 字节即 64 KB
-
-
管道适用于具有“血缘关系”的进程进行通信,常用于父子通信
-
管道自带互斥同步机制,且原子性写入
- 上述的情况1和情况2:很好的说明管道是自带同步与互斥机制的,读端进程和写端进程是有一个步调协调的过程的,不会说当管道没有数据了读端还在读取,而当管道已经满了写端还在写入
- 读取数据的条件是管道里面有数据,写端进程写入数据的条件是管道当中还有空间,若是条件不满足则相应的进程就会被挂起,直到条件满足后才会被再次唤醒
-
管道的生命周期是随进程的
-
即:管道也是文件,管道依赖于文件系统,当所有打开该文件的进程都退出后, 被打开的文件会被OS自动关闭,所以说管道的生命周期随进程
-
管道是文件吗?
是!如果一个文件只被当前进程打开,相关进程退出了(会自动递减struct file的ref引用计数变量),当ref为0时,被打开的文件会被OS自动关闭
-
-