在Kubernetes平台上,我们很少会直接创建一个Pod,在大多数情况下会通过控制器完成对一组Pod副本的创建、调度 及全生命周期的自动控制任务,如:RC、Deployment、DaemonSet、Job 等。
本文主要举例常见的Pod调度。
1
全自动调度
功能:Deployment或RC的主要功能之一就是自动部署一个容器应用的多份副本,以及持续监控副本的数量,在集群内始终维持用户指定的副本数量。
举例:使用配置文件可以创建一个ReplicaSet,这个ReplicaSet会创建3个Nginx应用的Pod:
apiversion: apps/v1kind: Deploymentmetadata: name: nginx-deploymentspec: selector: matchLabels: app: nginx replicas: 3 template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.7.9 ports: - containerPort: 80通过运行 kubectl get rs 和 kubectl get pods 可以查看已创建的ReplicaSet (RS)和Pod的信息:

从调度策略上来说,这3个Nginx Pod由系统全自动完成调度。它们各自最终运行在哪个节点上,完全由Master的Scheduler经过一系列算法计算得出,用户无法干预调度过程和结果。
2
定向调度
功能:将Pod调度到指定的一些Node上,通过Node的标签(Label)和Pod的nodeSelector属性相匹配。
举例:
如果要实现定向调度,首先的第一步就是要为Node节点搭上标签(Label),可以使用kubectl label命令:
kubectl label nodes <node-name><label-key>=<label-value>这里为k8s-node-1节点打上一个zone=north标签,表明它是“北方”的一个节点:

然后,在Pod的定义中加上nodeSelector的设置,以redis-master- controller.yaml为例:
apiVersion: v1kind: ReplicationControllermetadata: name: redis-master labels: name: redis-masterspec: replicas: 1 selector: name: redis-master template: metadata: labels: name: redis-master spec: containers: - name: master image: kubeguide/redis-master ports: - containerPort: 6379 nodeSelector: zone: north运行kubectl create -f命令创建Pod,scheduler就会将该Pod调度到拥有 “zone=north” 标签的Node上。
使用kubectl get pods-o wide命令可以验证Pod所在的Node:

需要注意的是,如果我们指定了Pod的nodeSelector条件,且在集群中不存在包含相应标签的Node,则即使在集群中还有其他可供使用的Node,这个Pod也无法被成功调度。
3
Node亲和性调度
功能:目前有两种节点亲和性表达
表达式 | 含义 |
RequiredDuringSchedulingIgnoredDuringExecution | 必须满足指定的规则才可以调度Pod到Node上(功能与nodeSelector很像,但是使用的是不同的语法),相当于限制 |
PreferredDuringSchedulingIgnoredDuringExecution | 强调优先满足指定规则,调度器会尝试调度Pod到Node上,但并不强求,相当于软限制 |
举例:
有如下要求:
requiredDuringSchedulingIgnoredDuringExecution:要求只运行在amd64的节点上(beta.kubernetes.io/arch In amd64);
preferredDuringSchedulingIgnoredDuringExecution:要求尽量运行在磁盘类型为ssd(disk-type In ssd)的节点上;
源文件定义如下:
apiVersion:vlkind:Podmetadata: name:with-node-affinityspec: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms - matchExpressions: - key:beta.kubernetes.io/arch operator:In values: - amd64 preferredDuringSchedulingIgnoredDuringExecution: - weight:1 preference: matchExpressions: - key:disk-type operator:In values: - ssd containers: - name:with-node-affinity image:gcr.io/google containers/pause:2.0从上面的配置中可以看到 In操作符,NodeAffinity语法支持的操作符包括In、NotIn、Exists、DoesNotExist、Gt、Lt。虽然没有节点排斥功能,但是用NotIn 和DoesNotExist就可以实现排斥的功能了。
4
亲和性与互斥性调度
功能:亲和性与互斥性可以理解为就是相关联的两种或多种Pod是否可以在同一个拓扑域中共存或者互斥。
举例:
首先,创建一个名为pod-flag的Pod,带有标签security=S1和app=nginx,后面的例子将使用pod-flag作为Pod亲和与互斥的目标Pod:
apiversion:v1kind:Podmetadata: name:pod-flag labels: security:"S1" app:"nginx"spec: containers: -name:nginx image:nginx下面创建第2个Pod来说明Pod的亲和性调度,这里定义的亲和标签是 “security=S1”,对应上面的Pod “pod-flag”,topologyKey的值被设置为 “kubernetes.io/hostname“:
apiVersion:vlkind:Podmetadata: name:pod-affinityspec: affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key:security operator:In values: -S1 topologyKey:kubernetes.io/hostname containers: - name:with-pod-affinity image:gcr.io/google_containers/pause:2.0创建Pod之后,使用kubectl get pods -o wide命令可以看到,这两个Pod在同一个Node上运行。
创建第3个Pod,我们希望它不与目标Pod运行在同一个Node上:
apiversion:v1kind:Podmetadata: name:anti-affinityspec: affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key:security operator:In values: -S1 topologyKey:topology.kubernetes.io/zone podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key:app operator:In values: -nginx topologyKey:kubernetes.io/hostname containers: - name:anti-affinity image:gcr.io/google_containers/pause:2.0这里要求这个新Pod与security=S1的Pod为同一个zone,但是不与app=nginx 的Pod为同一个Node。
创建Pod之后,同样用kubectl get pods -o wide来查看,会看到新的Pod被调度到了同一Zone内的不同Node上。
5
污点与容忍
功能:Taint(污点) 它让Node拒绝Pod的运行。简单地说,被标记为Taint的节点就是存在问题的节点,比 如磁盘要满、资源不足、存在安全隐患要进行升级维护,希望新的Pod不会被调度过来。但被标记为Taint的节点并非故障节点,仍是有效的工作节点,所以仍需将某些Pod调度到这些节点上时,可以通过使用Toleration属性来实现。
举例:Taint和Toleration是一种处理节点并且让Pod进行规避或者驱逐Pod的弹性处理方式,下面列举一些常见的用例。
举例一(独占节点):如果想要拿出一部分节点专门给一些特定应用使用,则可以为节点添加这样Taint:
kubectl taint nodes nodename dedicated=groupName:NoSchedule然后给这些应用的Pod加入对应的Toleration,这样,带有合适Toleration的Pod就会被允许同使用其他节点一样使用有Taint的节点。
举例二(具有特殊硬件设备的节点):在集群里可能有一小部分节点安装了特殊的硬件设备(如GPU芯片),用户自然会希望把不需要占用这类硬件的Pod排除在外,以确保对这类硬件有需求的Pod能够被顺利调度到这些节点上。
可以用下面的命令为节点设置Taint:
kubectl taint nodes nodename special=true:NoSchedule kubectl taint nodes nodename special=true:PreferNoSchedule6
优先级调度
功能:提高资源利用率的常规做法是采用优先级方案,即不同类型的负载对应不同的优先级,同时允许集群中的所有负载所需的资源总量超过集群可提供的资源,在这种情况下,当发生资源不足的情况时,系统可以选择释放一些不重要的负载(优先级最低的),保障最重要的负载能够获取足够的资源稳定运行。
举例:
首先,由集群管理员创建PriorityClass(PriorityClass不属于任何命名空间):
apiversion:scheduling.k8s.io/vlbetal kind:Priorityclassmetadata:name:high-priorityva1ue:1000000globalDefault:falsedescription:"This priority class should be used for XYZ service pods only."上述YAML文件定义了一个名为high-priority的优先级类别,优先级为 100000,数字越大,优先级越高,超过一亿的数字被系统保留,用于指派给系统组件。
可以在任意Pod上引用上述Pod优先级类别:
apiVersion: v1kind: Podmetadata:name: nginx labels:env: testspec:containers:-name: nginximage: nginximagePullPolicy: IfNotPresent priorityclassName: high-priority如果发生了需要抢占的调度,高优先级Pod就可能抢占节点N,并将其低优先级Pod驱逐出节点N,高优先级Pod的status信息中的nominatedNodeName字段会记录目标节点的名称。
需要注意,高优先级Pod仍然无法保证最终被调度到节点N上,在节点N上低优先级Pod被驱逐的过程中,如果有新的节点满足高优先级Pod的需求,就会把它调度到新的Node上。
而如果在等待低优先级的Pod退出的过程中,又出现了优先级更高的Pod,调度器就会调度这个更高优先级的Pod到节点N上,并重新调度之前等待的高优先级Pod。
7
DaemonSet
每个Node上只调度一个pod
功能:DaemonSet是 Kubernetes1.2 版本新增的一种资源对象,用于管理在集群中的每个Node上仅运行一份Pod的副本实例。
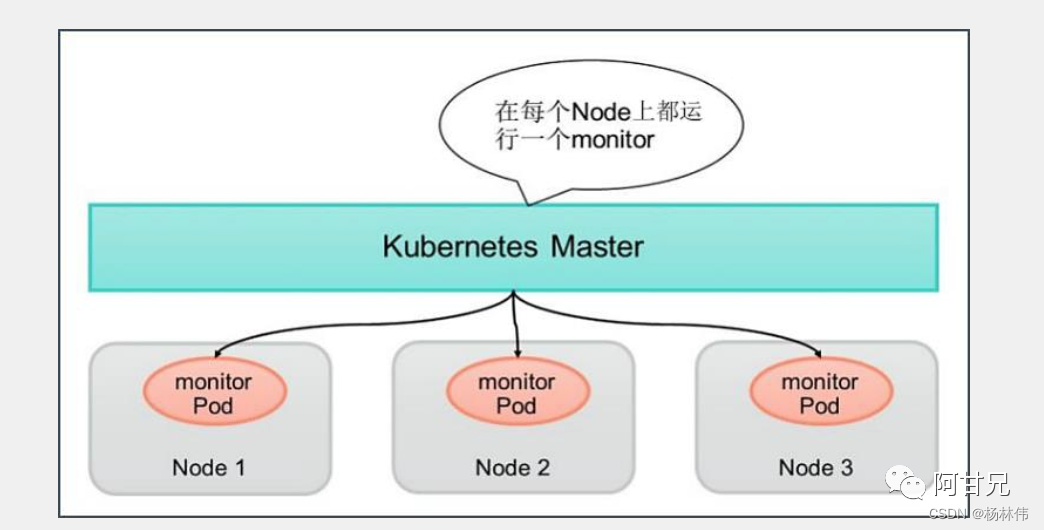
举例:下面的例子定义了为在每个Node上都启动一个fluentd容器,配置文件 fluentd-ds.yaml的内容如下 (其中挂载了物理机的两个目录"/var/log"和 “/var/lib/docker/containers”):
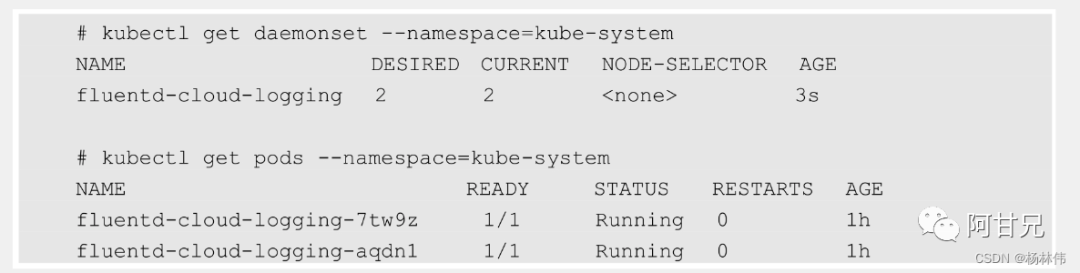
apiVersion: apps/v1kind: DaemonSetmetadata:name: fluentd-cloud-logging namespace: kube-system labels:k8s-app: fluentd-cloud-loggingspec:template:metadata:namespace: kube-system labels:k8s-app: fluentd-cloud-loggingspec:containers:-name: fluentd-cloud-loggingimage: gcr.io/google containers/fluentd-elasticsearch:1.17 resources:limits:cpu: 100mmemory: 200Mienv:-name: FLUENTD ARGS value: -qvolumeMounts-name: varlogmountPath: /var/logreadOnly: false-name: containersmountPath: /var/lib/docker/containers readonly: falsevolumes:-name: containershostPath:path: /var/lib/docker/containers -name: varloghostPath:path: /var/log查看创建好的DaemonSet和Pod,可以看到在每个Node上都创建了一个Pod:
8
批处理调度
功能:批处理任务通常并行(或者串行) 启动多个计算进程去处理一批工作项(Work item),处理完成后,整个批处理任务结束。Kubernetes从1.2版本开始支持批处理类型的应用,我们可以通过Kubernetes Job资源对象来定义并启动一个批处理任务。
举例(Job Template Expansion案例):首先是Job Template Expansion模式,由于在这种模式下每个Work item都对应一个Job实例,所以这种模式首先定义一个Job模板,模板里的主要参数是Work item的标识,因为每个Job都处理不同的Work item。
如下所示的Job模板(文件名为job.yaml.txt)中的 $ITEM 可以作为任务项的标识:
apiVersion: batch/v1kind: Jobmetadata:name: process-item-$ITEM labels:jobgroup: jobexamplespec:template:metadata:name: jobexamplelabels:jobgroup: jobexamplespec:containers:-name: cimage: busyboxcommand: ["sh","-c","echo Processing item $ITEM &sleep 5"] restartPolicy: Never通过下面的操作,生成了3个对应的Job定义文件并创建Job:
>for i in apple banana cherry >do> cat job.yaml.txt | sed "s/\$ITEM/$i/" > ./jobs/job-$i.yaml >done# ls jobsjob-apple.yaml job-banana.yaml job-cherry.yaml # kubectl create -f jobsjob "process-item-apple"created job "process-item-banana"created job "process-item-cherry"created观察Job的运行情况:
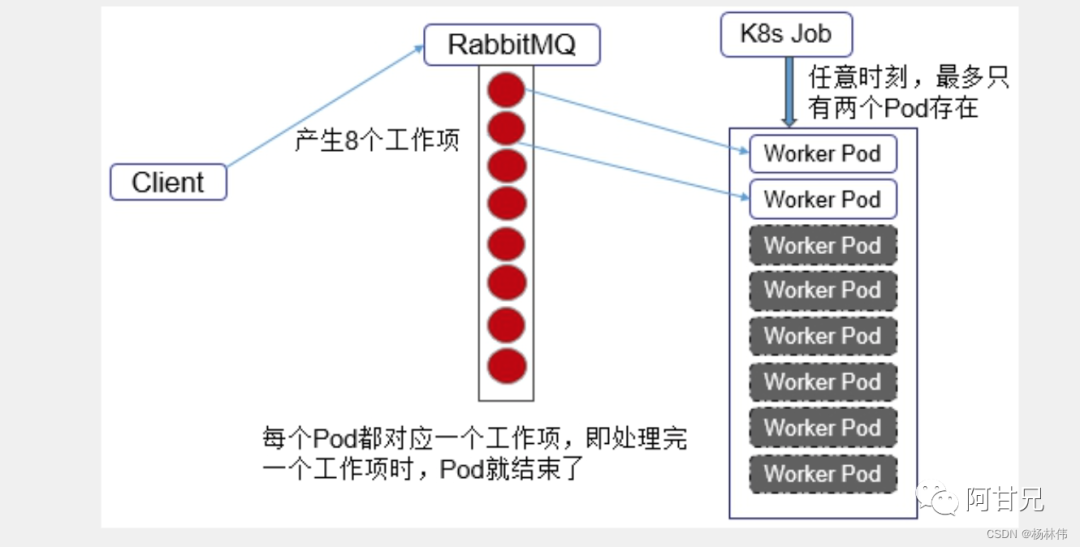
$ kubect1 get jobs -l jobgroup=jobexampleNAME DESIRED SUCCESSFUL AGEprocess-item-apple 1 1 4mprocess-item-banana 1 1 4mprocess-item-cherry 1 1 4m举例(Queue with Pod Per Work Item案例):在这种模式下需要一个任务队列存放Work item,比如RabbitMQ客户端程序先把要处理的任务变成Work item放入任务队列,然后编写Worker程序、打包镜像并定义成为Job中的Work Pod。
Worker程序的实现逻辑是从任务队列中拉取一个Work item并处理, 在处理完成后结束进程。并行度为2的Demo如下图所示:
举例(Queue with Variable Pod Count案例):由于这种模式下,Worker程序需要知道队列中是否还有等待处理的Work item,如果有就取出来处理,否则就认为所有工作完成并结束进程,所以任务队列通常要采用Redis或者数据库来实现:

9
定时任务
功能:Kubernetes从1.5版本开始增加了一种新类型的Job,即类似Linux Cron的定时任务Cron Job。
举例:比如,我们要每隔1min执行一次任务,则Cron表达式如下
*/1 * * * *编写一个Cron Job的配置文件(cron.yaml):
apiversion: batch/vl beta kind: CronJobmetadata:name: hellospec:schedule: "*/1 * * * *"jobTemplate:spec:template:spec:containers:-name:helloimage:busyboxargs:-/bin/sh--C-date;echo Hello from the Kubernetes cluster restartPolicy:OnFailure该例子定义了一个名为hello的Cron Job,任务每隔1min执行一次,运行的镜像是busybox,运行的命令是Shell脚本,脚本运行时会在控制台输出当前时间和字符串"Hello from the Kubernetes cluster".
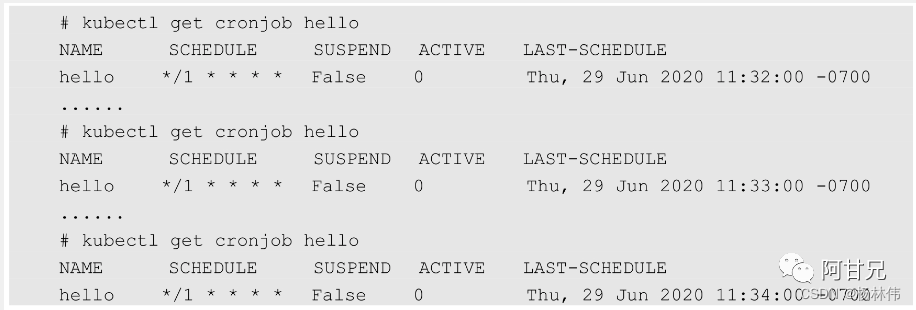
然后每隔1min运行kubectl get cronjob hello查看任务状态,发现的确每分钟调度了一次:
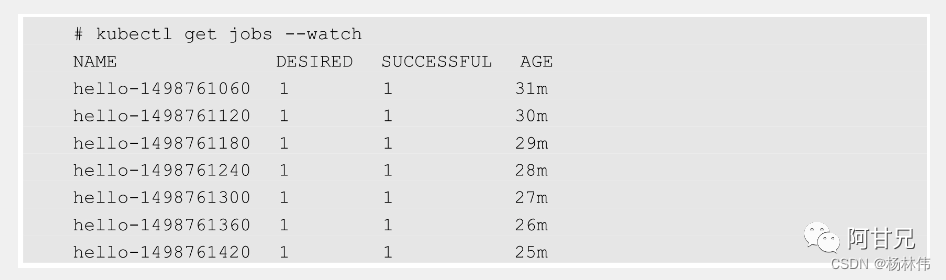
运行下面的命令,可以更直观地了解Cron Job定期触发任务执行的历史和现状:
10
容灾调度
功能:我们可以将Pod的各种常规调度策略认为是将整个集群视为一个整体,然后进行 “打散或聚合” 的调度。当我们的集群是为了容灾而建设的跨区域的多中心(多个Zone)集群,即集群中的节点位于不同区域的机房时,比如:
北京、上海、广 州、武汉,要求每个中心的应用相互容灾备份,又能同时提供服务,此时最好的调度策略就是将需要容灾的应用均匀调度到各个中心,当某个中心出现问题时, 又自动调度到其他中心均匀分布,
举例:假如我们的集群被划分为多个Zone,我们有一个应用(对应的Pod标签为 app=foo)需要在每个Zone均匀调度以实现容灾,则可以定义YAML文件如下:
spec: topologySpreadConstraints: -maxSkew: 1whenUnsatisfiable: DoNotScheduletopologyKey: topology.kubernetes.io/zoneselector:matchLabels: app: foo在以上YAML定义中,关键的参数是maxSkew,用于指定Pod在各个Zone上调度时能容忍的最大不均衡数:
值越大,表示能接受的不均衡调度越大;
值越小,表示各个Zone的Pod数量分布越均匀。