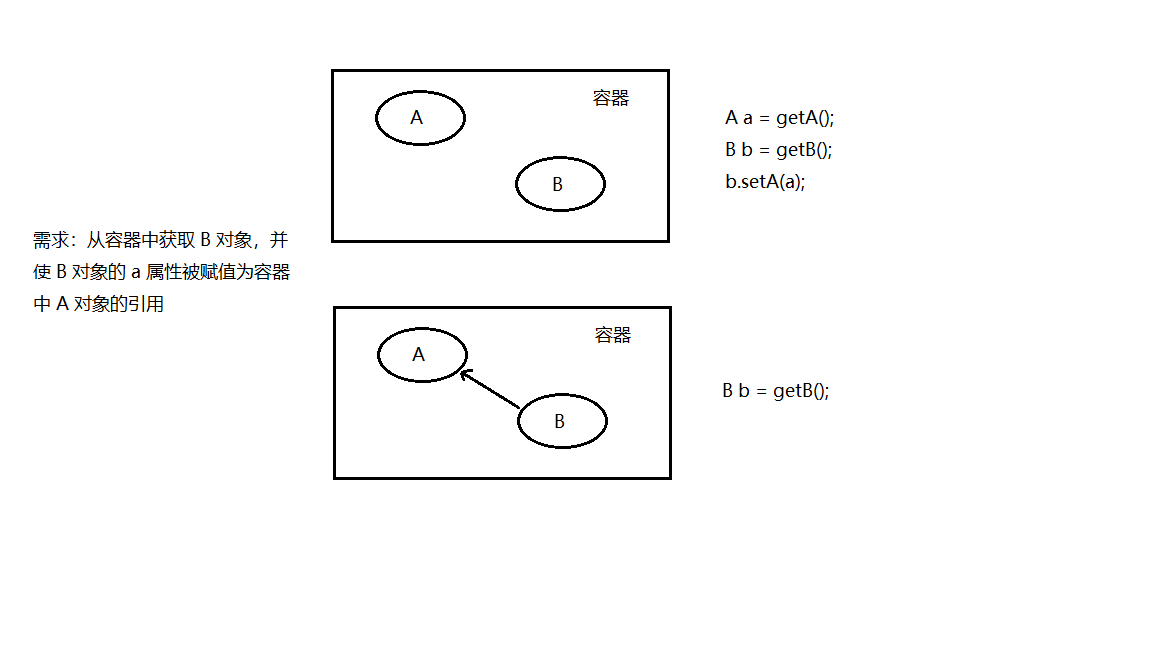
日志是软件开发的重要组成部分。一个精心编写的日志代码提供快速的调试,维护方便,以及应用程序的运行时信息结构化存储。日志记录确实也有它的缺点。它可以减缓的应用程序
Log4j
Log4j是Apache的一个开放源代码项目,通过使用Log4j,
我们可以控制日志信息输送的目的地是控制台、文件、GUI组件、甚至是套接口服务 器、NT的事件记录器、UNIX Syslog守护进程等;
我们也可以控制每一条日志的输出格式;通过定义每一条日志信息的级别,我们能够更加细致地控制日志的生成过程。
日志级别
DEBUG < INFO < WARN < ERROR < FATAL,分别用来指定这条日志信息的重要程度
如下定义日志级别为info级别,那么error和warn的日志可以显示而比他优先级低的debug信息就不显示了
log4j.rootLogger=info,A1,B2,C3 log4j.properties
lg4j使用:第⼀步,在 pom.xml ⽂件中引⼊ Log4j 包:
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>第⼆步,在 resources ⽬录下创建 log4j.properties ⽂件
这个配置文件告 诉Log4J以什么样的格式、把什么样的信息、输出到什么地方。
log4j.rootLogger = info,stdout
### 输出信息到控制台 ###
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern = [%-5p] %d{yyyy-MM-dd HH:mm:ss,SSS} method:%l%n%m%nLog4j有三个主要的组件:Loggers(记录器),Appenders(输出源)和Layouts(布局),这里可简单理解为日志类别,日志要输出的地方和日志以何种形式输出
Appenders 输出源
Log4j日志系统允许把日志输出到不同的地方,如控制台(Console)、文件(Files)、根据天数或者文件大小产生新的文件、以流的形式发送到其它地方等等。
org.apache.log4j.ConsoleAppender(控制台)
org.apache.log4j.FileAppender(文件)
org.apache.log4j.DailyRollingFileAppender(每天产生一个日志文件)
org.apache.log4j.RollingFileAppender(文件大小到达指定尺寸的时候产生一个新的文件)
org.apache.log4j.WriterAppender(将日志信息以流格式发送到任意指定的地方)
配置时语法如下:
log4j.appender.appenderName = fully.qualified.name.of.appender.class
log4j.appender.appenderName.option1 = value1
…
log4j.appender.appenderName.option = valueN第一次看,我就很懵。这option1、value1啥玩意???
Layouts 布局
有时用户希望根据自己的喜好格式化自己的日志输出。Log4j可以在Appenders的后面附加Layouts来完成这个功能。
Log4j 提供的格式有下⾯ 4 种:
org.apache.log4j.HTMLLayout:HTML 表格
org.apache.log4j.PatternLayout:⾃定义
org.apache.log4j.SimpleLayout:包含⽇志信息的级别和信息字符串
org.apache.log4j.TTCCLayout:包含⽇志产⽣的时间、线程、类别等等信息
配置时语法如下:
log4j.appender.appenderName.layout = fully.qualified.name.of.layout.class
log4j.appender.appenderName.layout.option1 = value1
…
log4j.appender.appenderName.layout.option = valueN⾃定义格式的参数
%m:输出代码中指定的消息
%p:输出优先级
%r:输出应⽤启动到输出该⽇志信息时花费的毫秒数
%c:输出所在类的全名
%t:输出该⽇志所在的线程名
%n:输出⼀个回⻋换⾏符
%d:输出⽇志的时间点
%l:输出⽇志的发⽣位置,包括类名、线程名、⽅法名、代码⾏数
[%-5p] %d{yyyy-MM-dd HH:mm:ss,SSS} method:%l%n%m%n
Log4j程序中使用
在对Logger实例进行命名时,没有限制,可以取任意自己感兴趣的名字。一般情况下建议以类的所在位置来命名Logger实例,这是目前来讲比较有效的Logger命名方式。这样可以使得每个类建立自己的日志信息,便于管理。比如:
Logger.getLogger(Log4jExample.class.getName ())
import org.apache.log4j.Logger;
/**
* @Description:
* @Author: 小羽毛
* @Date: 2023/3/7 20:41
*/
public class Log4jExample {
static Logger logger = Logger.getLogger(Log4jExample.class.getName ()) ;
public static void main(String[] args) {
// 记录debug级别的信息
logger.debug("debug.");
// 记录info级别的信息
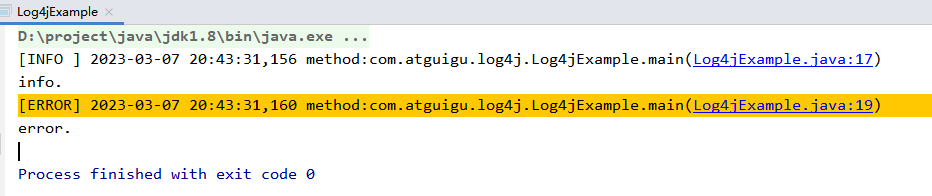
logger.info("info.");
// 记录error级别的信息
logger.error("error.");
}
}因为配置了日志级别是info级别,所以debug级别的信息不会打印到控制台
Log4j使用注意点
在打印 DEBUG 级别的⽇志时,切记要使⽤ isDebugEnabled()
如果⽇志系统的级别不是 DEBUG,就会多执⾏了字符串拼接的操作,⽩⽩浪费了性能。
if(logger.isDebugEnabled()) {
logger.debug("⽤户名是:" + getName());
}2、在打印⽇志的时候带上类的全名和线程名,在多线程环境下,这点尤为重要,否则定位问题的时候就太难了
SLF4J
为什么让你用slf4j
在使⽤⽇志系统的时候,⼀定要使⽤ SLF4J 作为⻔⾯担当
SLF4J 可以统⼀⽇志系统,作为上层的抽象接⼝,不需要关注底层的⽇志实现,可以是 Log4j,也可
以是 Logback,或者 JUL、JCL。
3.使用slf4j后不再需要 isDebugEnabled() 先进⾏判断
slf4j是如何将自己的通用日志格式转成不同的日志系统的格式的呢?
不同日志系统包都会有一个Adapter,用来在slf4j和不同日志系统之间做转换
第⼀步,把 log4j 的依赖替换为 slf4j-log4j12
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.25</version>
</dependency>第⼆步,在 resources ⽬录下创建 log4j.properties ⽂件,内容和上面⼀篇完全相同
SLF4J 参数化日志消息
SLF4J 在打印⽇志的时候使⽤了占位符 {} 。
解决锚点:字符串拼接会创建很多不必要的字符串对象,极⼤的消耗了内存空间.如下
String name = "小羽毛";
int age = 8;
logger.debug(name + ",年纪:" + age + ",阿姨有糖吃吗");
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class SLF4jExample {
static Logger logger = LoggerFactory.getLogger(SLF4jExample.class.getName ()) ;
public static void main(String[] args) {
logger.info("{},想问问阿姨有糖吃吗","小羽毛");
}
}
还可以在消息中使用两个参数 -
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class SLF4jExample {
static Logger logger = LoggerFactory.getLogger(SLF4jExample.class.getName ()) ;
public static void main(String[] args) {
logger.info("颜值:{} 分, 天赋 {}分", 100, 99);
}
}
Logback
Spring Boot 的默认⽇志框架使⽤的是 Logback。
第⼀步,在 pom.xml ⽂件中添加 Logback 的依赖:
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.3</version>
</dependency>Maven 会⾃动导⼊另外两个依赖:

logback-core 是 Logback 的核⼼,logback-classic 是 SLF4J 的实现
Log4j 2
Log4j、SLF4J、Logback 是⼀个爹——Ceki Gulcu,但 Log4j 2 却是例外,它是 Apache 基⾦会的产
品。