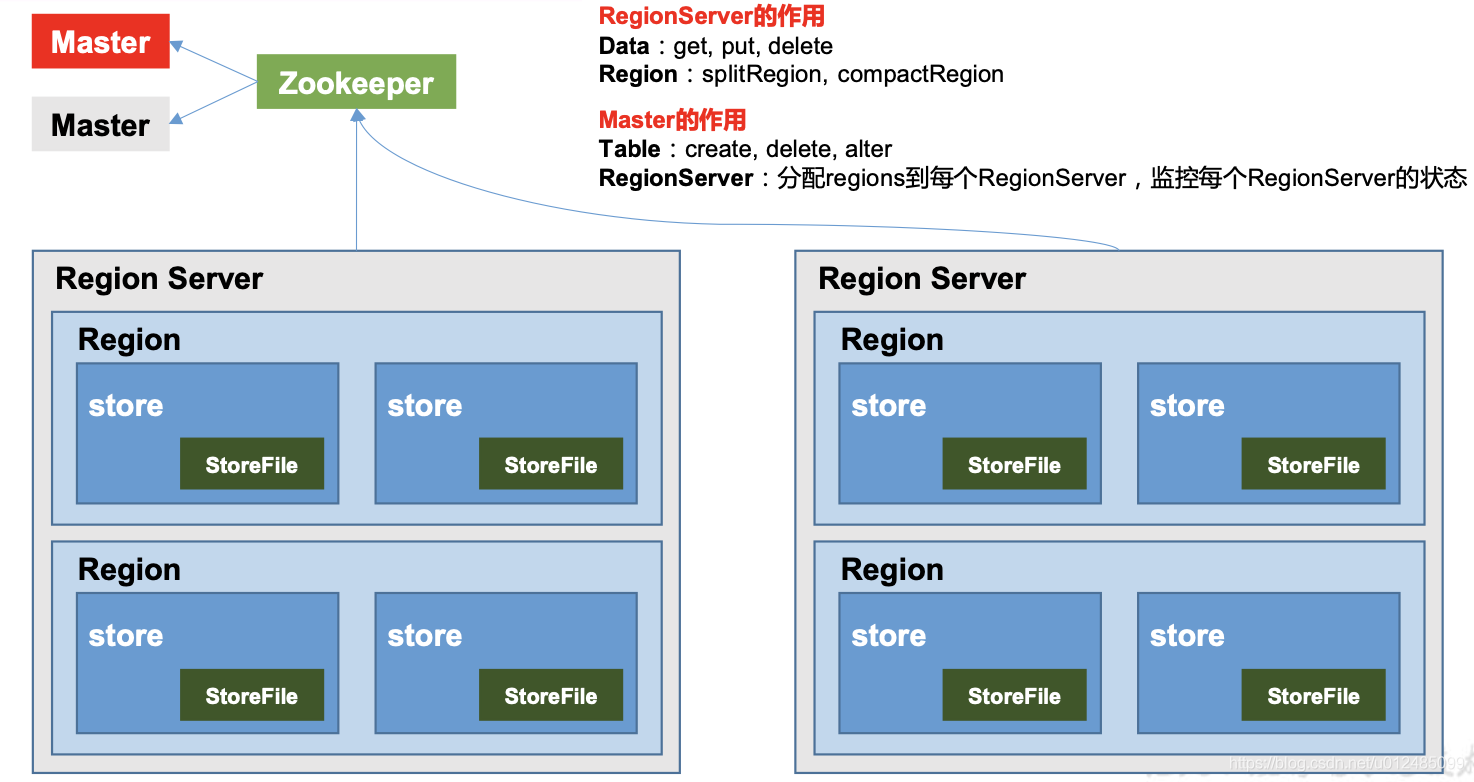
这里写目录标题
- 函数模板
- 1.2.2 函数模板注意事项
- 1.2.3 函数模板案例
- 调用规则
- 类模板与函数模板区别
- 类模板与继承
- 类模板成员函数类外实现
- #pragma once
- 类模板与友元
- 案例
- 重新定义【】
- stl
- 2.2 STL基本概念
- STL六大组件
- 容器算法迭代器初识
- vector
- vector容器嵌套容器
- string容器
- string赋值操作
- 查找
- 比较
- string字符存取
- 插入
- 字串
- vector容器
- vector插入和删除
- vector数据存取
- vector 互换容器
- vector 预留空间
- deque容器
- deque赋值操作
- 大小操作
- 3.3.6 deque 数据存取
- 案例 评委打分
- stack
- 常用接口
- queue
- list 容器
- list函数构造
- list 大小操作
- list 插入和删除
- 排序
- 排序案例
- set / multiset
- set插入和删除
- pair对组创建
- 仿函数
- map
- 大小和交换
- 插入和删除
- 案例员工分组
- 容器总结
- 函数对象
- 谓词
- 内建函数对象
函数模板
C++另一种编程思想称为 泛型编程 ,主要利用的技术就是模板
C++提供两种模板机制:函数模板和类模板
template
函数声明或定义
template — 声明创建模板
typename — 表面其后面的符号是一种数据类型,可以用class代替
T — 通用的数据类型,名称可以替换,通常为大写字母
void aa(int a)
可以把void返回类型和 int 形参也范式化
//利用模板提供通用的交换函数
template<typename T> 声明一个模板 告诉编译器后面代码中紧跟着的T不要报错,T是一个通用的数据类型
void mySwap(T& a, T& b)
{
T temp = a;
a = b;
b = temp;
}
总结:
函数模板利用关键字 template
使用函数模板有两种方式:自动类型推导、显示指定类型
模板的目的是为了提高复用性,将类型参数化
交换逻辑是一样的,只是传入参数类型不一样
自动类型推导
显示指定类型
1.2.2 函数模板注意事项
注意事项:
自动类型推导,必须推导出一致的数据类型T,才可以使用
模板必须要确定出T的数据类型,才可以使用
/利用显示指定类型的方式,给T一个类型,才可以使用该模板
typename 照他的说法 全写成class就行
有人是做了区分,但实际效果是一致的
1.2.3 函数模板案例
自动类型推导 mySwap(a, b); 必须推导出一致的数据类型T,才可以使用
显示指定类型 mySwap(a, b); 模板必须要确定出T的数据类型,才可以使用
使用函数模板时,如果用自动类型推导,不会发生自动类型转换,即隐式类型转换
myAdd02(a, c); //正确,如果用显示指定类型,可以发生隐式类型转换
//myAdd02(a, c); // 报错,使用自动类型推导时,不会发生隐式类型转换
总结:建议使用显示指定类型的方式,调用函数模板,因为可以自己确定通用类型T
调用规则
可以通过空模板参数列表来强制调用函数模板
myPrint<>(a, b); //调用函数模板
//4、 如果函数模板可以产生更好的匹配,优先调用函数模板
总结:既然提供了函数模板,最好就不要提供普通函数,否则容易出现二义性
/内置数据类型可以直接使用通用的函数模板
在上述代码中,如果T的数据类型传入的是像Person这样的自定义数据类型,也无法正常运行
因此C++为了解决这种问题,提供模板的重载,可以为这些特定的类型提供具体化的模板
编译器运行时不会报错 函数运行时报错,不知道person类怎么进行比较
一种方法是运算符重载 但是方法太麻烦
利用具体化person的版本实现代码,具体化优先调用
template<> bool myCompare(Person &p1, Person &p2)
告诉这是一个模板化的重载版本, T变成了person
总结:
利用具体化的模板,可以解决自定义类型的通用化
学习模板并不是为了写模板,而是在STL能够运用系统提供的模板
template<class NameType, class AgeType>
class Person
{
public:
Person(NameType name, AgeType age)
{
this->mName = name;
this->mAge = age;
}
void showPerson()
{
cout << "name: " << this->mName << " age: " << this->mAge << endl;
}
public:
NameType mName;
AgeType mAge;
};
// 指定NameType 为string类型,AgeType 为 int类型
Person<string, int>P1(“孙悟空”, 999); 模板的参数列表
总结:类模板和函数模板语法相似,在声明模板template后面加类,此类称为类模板
类模板与函数模板区别
类模板在模板参数列表中可以有默认参数
Person p(“猪八戒”, 999); //类模板中的模板参数列表 可以指定默认参数
类模板使用只能用显示指定类型方式
类模板中的模板参数列表可以有默认参数
template<class NameType, class AgeType = int>
普通类中的成员函数一开始就可以创建
类模板中的成员函数在调用时才创建 即使没有声明 他也会编译通过
typeid(T1).name()以字符串化的方式告诉你名字

类模板与继承
当类模板碰到继承时,需要注意一下几点:
当子类继承的父类是一个类模板时,子类在声明的时候,要指定出父类中T的类型
如果不指定,编译器无法给子类分配内存
如果想灵活指定出父类中T的类型,子类也需变为类模板
父类T子类继承,子类不知道继承的父类属性类型,无法计算相应的内存空间
template<class T1, class T2>
class Son2 :public Base<T2>
{
public:
Son2()
{
cout << typeid(T1).name() << endl;
cout << typeid(T2).name() << endl;
}
T1 obj;
};
Son2<int, char> child1; char给t2 t2进一步传给父类的属性
类模板成员函数类外实现
总结:类模板中成员函数类外实现时,需要加上模板参数列表
void showPerson() 需要为其加上person作用域与模板参数列表,为了让编译器知道模板
再加上 template<class T1, class T2>
构造函数,没有返回值也不写void
一开始include person.h文件 成员函数不会被创建
但是如果你include person.cpp 就可以看到相关代码,同时cpp文件中又有xxx.h文件
由此,编译器看到了所有的代码
还有一个方法就是hpp 不用分开写。分开写导致创建时机的问题引发错误
//#include "person.h"
#include "person.cpp" //解决方式1,包含cpp源文件
//解决方式2,将声明和实现写到一起,文件后缀名改为.hpp
#include "person.hpp"
#pragma once
https://blog.csdn.net/weixin_41055260/article/details/122994997
类模板与友元
//1、全局函数配合友元 类内实现
friend void printPerson(Person<T1, T2> & p) 参数模板化传参
{
cout << "姓名: " << p.m_Name << " 年龄:" << p.m_Age << endl;
}
template<class T1, class T2>
void printPerson2(Person<T1, T2> & p) 全局函数类外实现无需加作用域
//全局函数配合友元 类外实现
friend void printPerson2(Person<T1, T2> & p);
这里只是普通函数的声明
然后类外函数模板的实现,导致两者不对应
friend void printPerson2<>(Person<T1, T2> & p);
需要加上空模板的参数列表
此外,如果全局函数是类外实现,需要让编译器提前知道这个函数的存在
这里就需要
提前声明,让编译器知道person的存在
template<class T1, class T2> class Person;
然后实现函数功能
template<class T1, class T2>
void printPerson2(Person<T1, T2> & p)
{
cout << "类外实现 ---- 姓名: " << p.m_Name << " 年龄:" << p.m_Age << endl;
}
案例
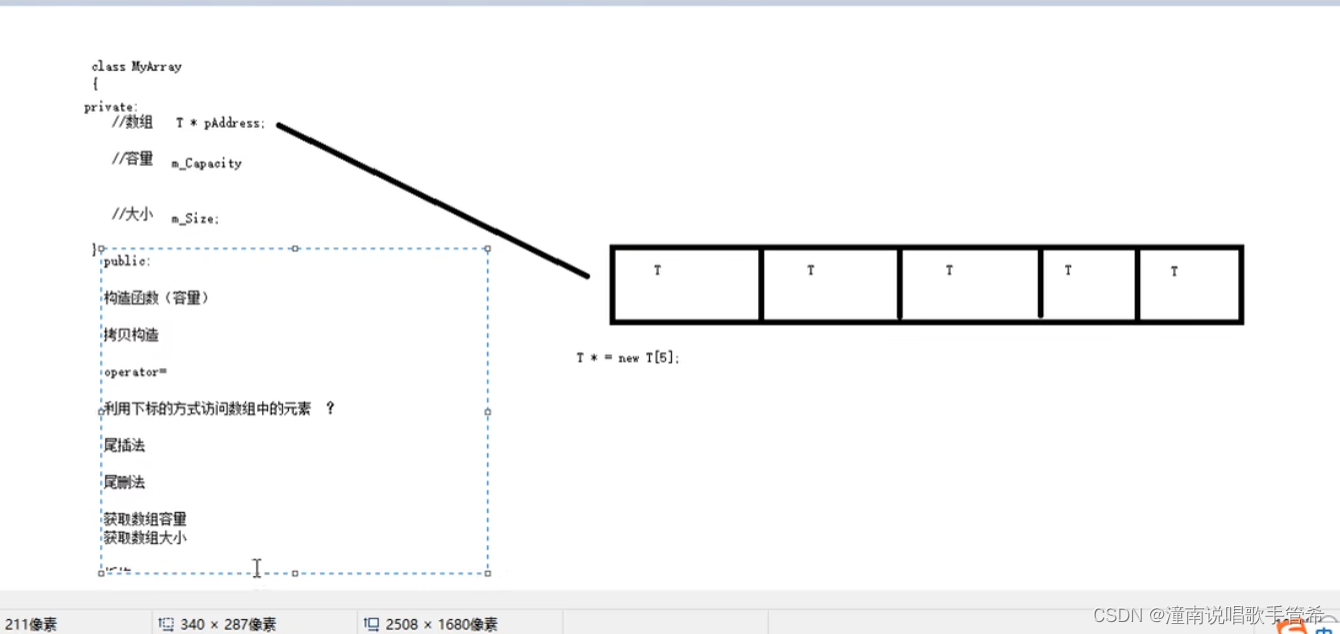
重新定义【】
通过下标访问访问不到,
因为自己定义的对象是不认识【】的
同时考虑到 arr[0] = 0 可以作为等号左值
应该是返回自身 所以这里是引用
T& operator [](int index)
{
return this->pAddress[index]; //不考虑越界,用户自己去处理
}
类模板传入参数
//1、指定传入的类型
void printIntArray(MyArray<int>& arr) {
for (int i = 0; i < arr.getSize(); i++) {
cout << arr[i] << " ";
}
cout << endl;
}
//2、参数模板化
//3、整个类模板化
template<class T>
void printPerson3(T & p)
{
cout << "T的类型为: " << typeid(T).name() << endl;
p.showPerson();
}
stl
为了提高代码的复用性 提供一套标准的数据结构和算法
2.2 STL基本概念
STL六大组件
容器算法迭代器初识
vector
vector存放内置数据类型
STL中最常用的容器为Vector,可以理解为数组,下面我们将学习如何向这个容器中插入数据、并遍历这个容器
Person <string, int >p("猪八戒", 90);
vector<int> v;
//通过迭代器访问容器中的数据
//起始迭代器 指向第一个元素
//结束迭代器 指向容器中最后一个元素的下一个位置
vector<int>::iterator pBegin = v.begin();
vector<int>::iterator pEnd = v.end();
for (vector<int>::interator it = v.begin();it!=end();it++)
for_each
it当作迭代器,相当于指针,解引用得出的person数据类型·
这里也可以 it->属性 的方式获取属性
存放自定义数据类型指针
v.push_back(&p1); 传入地址
vector<Person>::iterator vector<Person>::iterator
vector<Person*>::iterator 注意这里 指针 (*it)->mAge
vector容器嵌套容器
vector< vector<int> > v;
vector<int> v1;
for (vector<vector<int>>::iterator it = v.begin(); it != v.end(); it++) {
*it本身还是一个容器 需要再一次
for (vector<int>::iterator vit = (*it).begin(); vit != (*it).end(); vit++)
string容器
string是一个类,类内部封装了char*,管理这个字符串,是一个char*型的容器。
void test01()
{
string s1; //创建空字符串,调用无参构造函数
cout << "str1 = " << s1 << endl;
const char* str = "hello world";
string s2(str); //把c_string转换成了string
cout << "str2 = " << s2 << endl;
string s3(s2); //调用拷贝构造函数
cout << "str3 = " << s3 << endl;
string s4(10, 'a');
cout << "str3 = " << s3 << endl;
}
string赋值操作
string的赋值方式很多,operator= 这种方式是比较实用的
查找
一个从左往右查 find
一个从右往左找 rfind
string str1 = "abcdefgde";
str1.replace(1, 3, "1111"); 从1号位置起3个字符替换为1111
比较
string字符存取
str.size() 返回字符串长度
cout << str.at(i) << " ";
cout << str[i] << " ";
//字符修改
str[0] = ‘x’;
str.at(1) = ‘x’;
cout << str << endl;
插入
hello
str.insert(1,‘111’)
h111ello
string& insert(int pos, int n, char c); //在指定位置插入n个字符c
**总结:**插入和删除的起始下标都是从0开始
字串
从字符串中获取想要的子串
string substr(int pos = 0, int n = npos) const; //返回由pos开始的n个字符组成的字符串
abcdef 1,3 返回bcd
hello@sina.com find@
从0开始截取多少个
**总结:**灵活的运用求子串功能,可以在实际开发中获取有效的信息
vector容器
动态扩展
把数去拷贝至新空间 释放原有空间
**总结:**vector的多种构造方式没有可比性,灵活使用即可
cout << "v1的容量 = " << v1.capacity() << endl; 容量动态扩展 大于等于size大小
判断是否为空 — empty
返回元素个数 — size
返回容器容量 — capacity
重新指定大小 — resize
vector插入和删除
插入的时候注意第一个数是迭代器
vector数据存取
除了用迭代器获取vector容器中元素,[ ]和at也可以
front返回容器第一个元素
back返回容器最后一个元素
vector 互换容器
v1.swap(v2);
巧用swap可以收缩内存空间
resize重新指定后 空间还是那么大
vector(v).swap(v); //匿名对象 此时自身调用 巧妙收缩内存空间
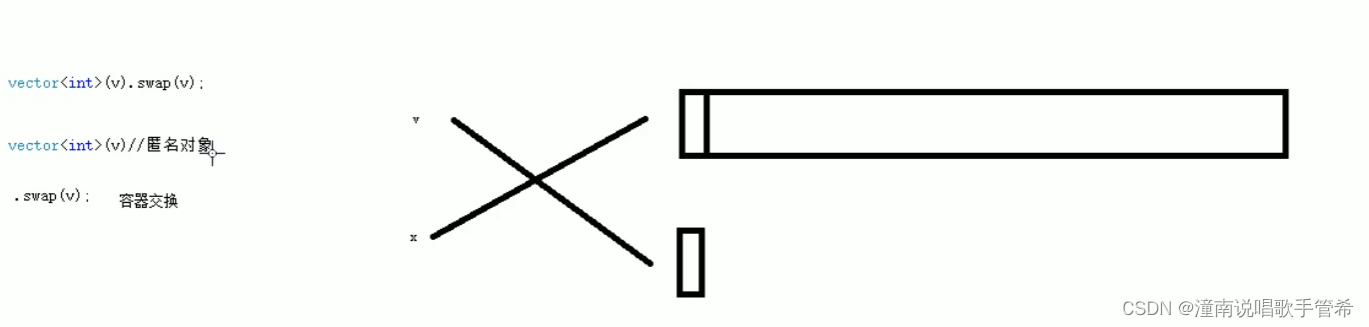
交换后匿名对象直接被回收了
vector 预留空间
减少vector在动态扩展容量时的扩展次数
如果一开始不预留空间,他视频里显示开辟了30次空间
他每开辟一次空间,都会有新的首地址,这个时候就要重新设置p指向新的首地址
deque容器
双端数据 可以对头端进行插入和删除操作
vector对于头部的插入删除效率低,数据量越大,效率越低
deque相对而言,对头部的插入删除速度回比vector快
vector访问元素时的速度会比deque快,这和两者内部实现有关
访问元素为什么慢 由于一个节点地址结束 需要到另一个节点重新找
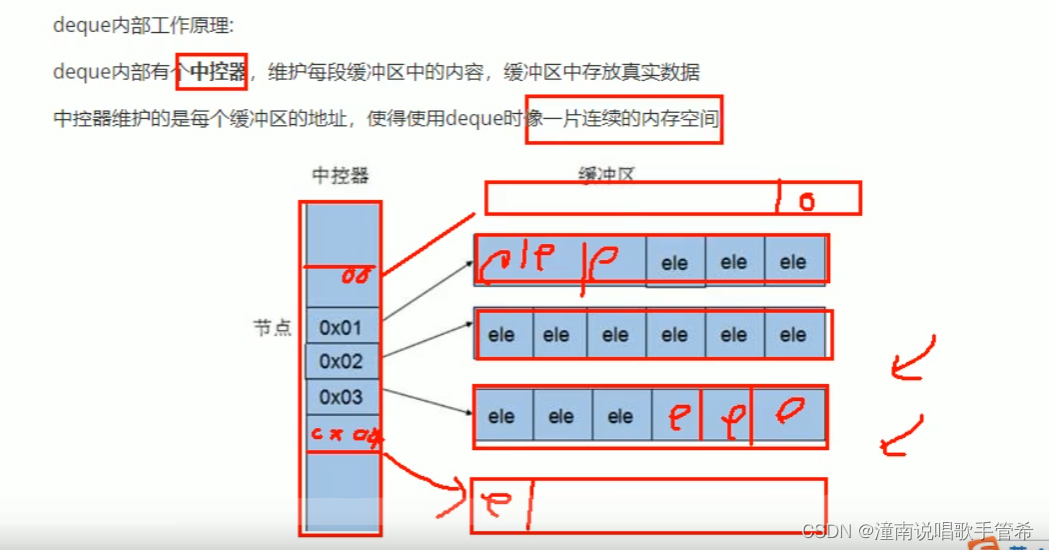
访问元素为什么慢 由于一个节点地址结束 需要到另一个节点重新找
void printDeque(const deque& d)
for (deque::const_iterator it = d.begin();
如果要限制只读状态 迭代器也要限制
dequed4(d3);
deque赋值操作
大小操作
他视频中补是补在后面的
d.erase(d.begin()); 迭代器
deque<int>::iterator it = d1.begin();
it++;
d1.erase(it)
3.3.6 deque 数据存取
总结:sort算法非常实用,使用时包含头文件 algorithm即可
默认排序规则为升序
对于支持随机访问的迭代器容器,都可以用sort算法直接对其排序
案例 评委打分
class person类
有两个属性
stack
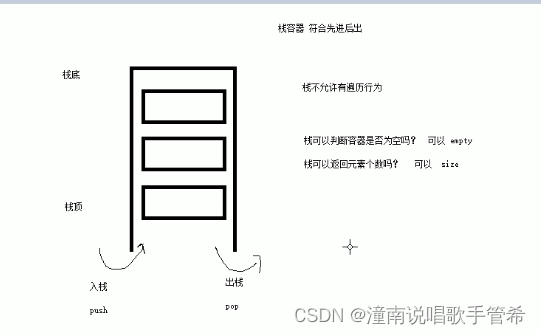
常用接口
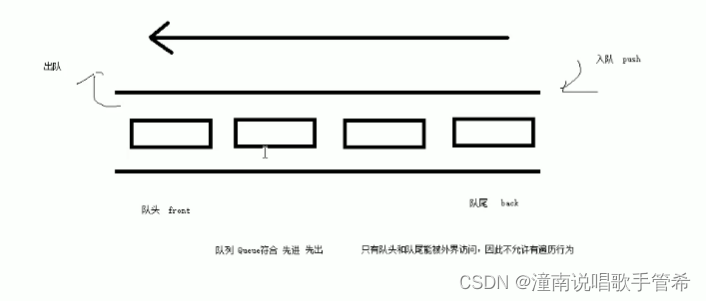
queue
list 容器
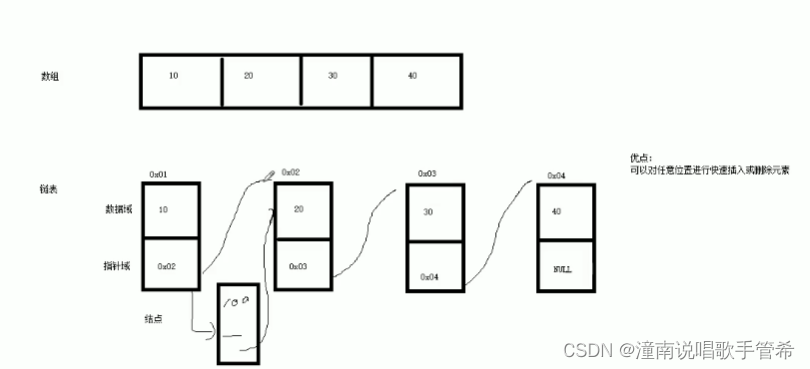
采用动态存储分配,不会造成内存浪费和溢出 有十万个数就有十万个节点
而有的会给你分配超过十万的内存空间
List有一个重要的性质,插入操作和删除操作都不会造成原有list迭代器的失效,这在vector是不成立的。 vector会重新分配内存
list函数构造
list 大小操作
list 插入和删除
不能用位置指定访问跳跃访问,例如【】 at
原因list 本质是链表 不是用连续空间存储 迭代器也不支持随机访问
可以使用 创建迭代器 自身++ 方式 多加几次访问
//it = it + 1;//错误,不可以跳跃访问,即使是+1
排序
所有不支持随机访问迭代器的的容器 不可以用标准算法
不支持随机访问迭代器的,内部会提供对应的一些算法
//排序
L.sort(); //默认的排序规则 从小到大
printList(L);
L.sort(myCompare); //指定规则,从大到小
printList(L);
bool myCompare(int val1 , int val2)
{
return val1 > val2; 前面一个大于后面一个 就是从大到小 返回值布偶型
}
排序案例
list<Person> L;
bool ComparePerson(Person& p1, Person& p2) {
if (p1.m_Age == p2.m_Age) {
return p1.m_Height > p2.m_Height;
}
else
{
return p1.m_Age < p2.m_Age;
}
}
L.sort(ComparePerson);
自定义数据类型排序需要自己写 仿函数
set / multiset
set/multiset属于关联式容器,底层结构是用二叉树实现。
set不允许容器中有重复的元素
multiset允许容器中有重复的元素
set容器插入数据时用insert
set容器插入数据的数据会自动排序
统计大小 — size
判断是否为空 — empty
交换容器 — swap
插入 — insert
删除 — erase
清空 — clear
s1.size()
s1.insert(10);
s1.empty()
s1.swap(s2);
set插入和删除
set容器进行插入数据和删除数据
插入 — insert
删除 — erase
清空 — clear
set<int>::iterator pos = s1.find(30);
对组 迭代器和布偶类型数据
插入成功或者失败
miltiset返回只返回一个迭代器 不会返回布偶类型数据
pair对组创建
仿函数
set<int,MyCompare> s2;
set数据在插入之后就无法改变,只能在插入之前改变规则,在模板参数列表中制定规则。
重写仿函数
一个是重写()
一个是类外写class
自定义数据类型要指定排序规则
他list里是写了一个函数 这里直接写了一个类,在类里写运算符重载函数
class comparePerson
set<int,MyCompare> s2; set模板中再加入一个参数
map
m.insert(pair<int, int>(1, 10));
里面是匿名 创建 然后 插入
总结:map中所有元素都是成对出现,插入数据时候要使用对组
1 插入
2 拷贝
2 等于号 赋值
大小和交换
插入和删除
//第四种插入方式
m[4] = 40;
不太建议用第四种,比如
cout<<m[5]<<endl; 此时没有5 但是你显示他会默认给你键值对 5,0的
可以用key访问value
箭头方式也可以
cout << "找到了元素 key = " << (*pos).first << " value = " << (*pos).second << endl;
count统计而言 要么0要么1
案例员工分组
multimap<int,Worker>::iterator pos = m.find(CEHUA); 找到cehua键的 对应值
pos->second.m_Name 前面指向worker 然后 worker的name属性
容器总结
vector 预留空间 尾部插入 删除 向指定位置插入
deque 两边都可以 push pop 中间可以insert 总结:sort算法非常实用,使用时包含头文件 algorithm即可 sort(d.begin(), d.end());
stack 先进后出 不允许遍历行为 栈顶添加移除 返回栈顶元素
queue 先进先出 往尾部添加元素 移除头部元素
list 可以头尾 都插入删除 push back/ front pop 只能前移和后移
remove(elem);//删除容器中所有与elem值匹配的元素。
函数对象
重载函数调用操作符的类,其对象常称为函数对象
函数对象使用重载的()时,行为类似函数调用,也叫仿函数
谓词
返回bool类型的仿函数称为谓词
如果operator()接受一个参数,那么叫做一元谓词
如果operator()接受两个参数,那么叫做二元谓词
如果参数里看到有pred 代表需要返回布偶类型的谓词
vector<int>::iterator it = find_if(v.begin(), v.end(), GreaterFive());
GreaterFive()匿名的函数对象, find_if(返回叠加器位置 1个 他例子里0-9 返回大于5的 找到6 就返回了
sort(v.begin(), v.end());
sort(v.begin(), v.end(), MyCompare());
class MyCompare
{
public:
bool operator()(int num1, int num2)
{
return num1 > num2;
}
};