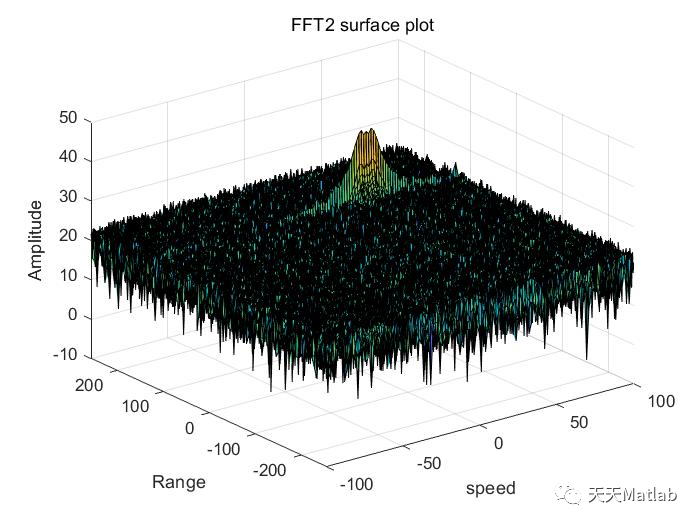
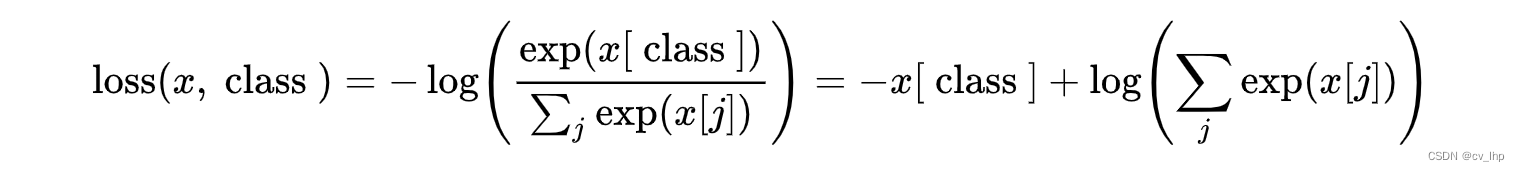之前我们已经知道了Scala中的数据结果有哪些,并且能够使用for循环取到该数据中的元素,现在我们再进一步的去了解更加方便及常用的函数操作,使得我们能够对集合更好的利用。
目录
一,foreach函数
1,遍历一维数组
1)foreach函数里面没有调用打印函数
2)foreach函数里面调用打印函数
3)使用for函数遍历一维数组
2,遍历二维数组
1)使用foreach函数
2)使用for函数
3,对集合中的元素进行运算后打印输出
二,sorted函数
三,sortBy函数
1,使用sorted函数对列表中的对偶元组进行排序
2,使用sortBy函数对列表中的对偶元组进行排序
3,使用sortBy函数对嵌套集合中的整型数组进行排序【以最大值】
4,使用sortBy函数对嵌套集合中的整型数组进行排序【以平均值】
四,sortWith函数
五,flatten函数
1,数组Array或者是列表List中嵌套字符串的起摞问题
2,数组或者是列表包含有map集合的起摞问题
3,数组或者是列表中包含有对偶元组的起摞问题
六,map函数
1,list集合中的元素进行加减乘除运算
2,对list嵌套array集合序列中的元素进行加减乘除运算
七,flatMap函数
一,foreach函数
foreach函数作用就是用来遍历集合中元素的,但是需要注意的是,使用该函数遍之后如果不去调用print/println函数来打印遍历到的元素的话,那么就只会返回为unit,即()。
现在我们有一个数组:
val num1_ar=Array(1,2,3)现在我们去对其遍历并获取到集合中的元素:
1,遍历一维数组
1)foreach函数里面没有调用打印函数
scala> num1_ar.foreach(num => num)
如上,我们可以发现当我们没有调用print函数的时候什么都没有输出,接下来我们使用一个变量接收一下该返回值:
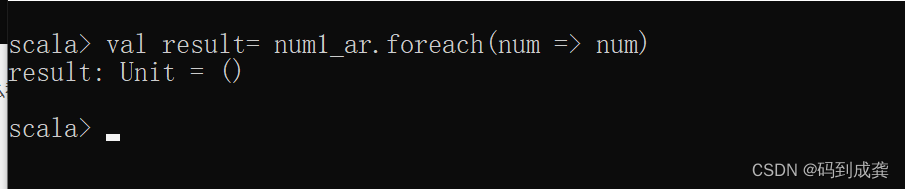
可以看到,foreach的返回值为unit,并且unit的默认值为()。
2)foreach函数里面调用打印函数
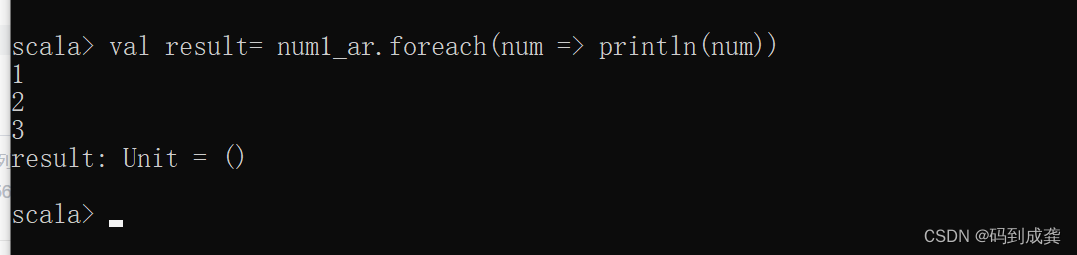
当我们调用了打印函数之后,就可以看到我们集合中的元素了,如下:
scala> num1_ar.foreach(num =>println(num))
并且,foreach的返回值依旧是unit
3)使用for函数遍历一维数组
如果不想要使用foreach函数来遍历集合的话,那么可以使用之前我们学习过的for函数来遍历,如下:
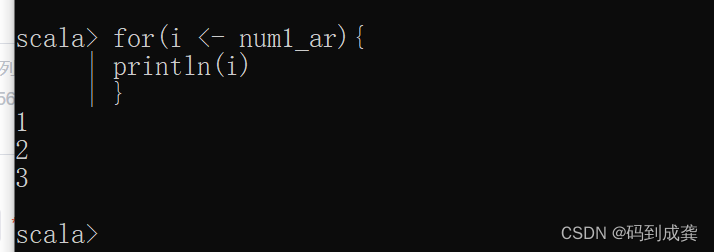
scala> for(i <- num1_ar){
| println(i)
| }
2,遍历二维数组
之前我们遍历的是一维数组,只使用一次foreach函数,那么遍历二维数组,该使用多少次foreach函数?没错,是两次。现在我们有下面这么一个二维数组,接下来我们将去遍历它:
val num_array=Array(Array(1,2,3),Array(9,10,11))
1)使用foreach函数
scala> num_array.foreach(f => f.foreach(println))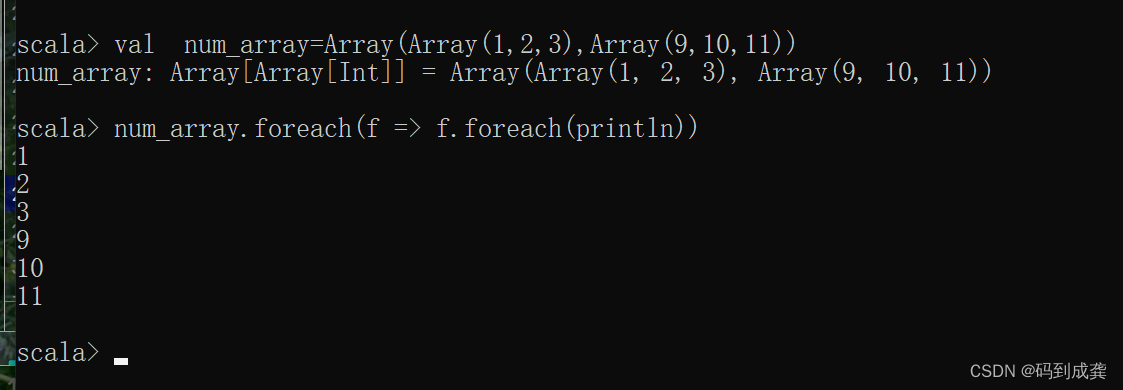
如上,我们可以发现,已经成功的打印出来了集合中的元素。接下来我们使用双层for循环来遍历试试。
2)使用for函数
我们使用for函数遍历和使用foreach函数的得到的结果是一样的:
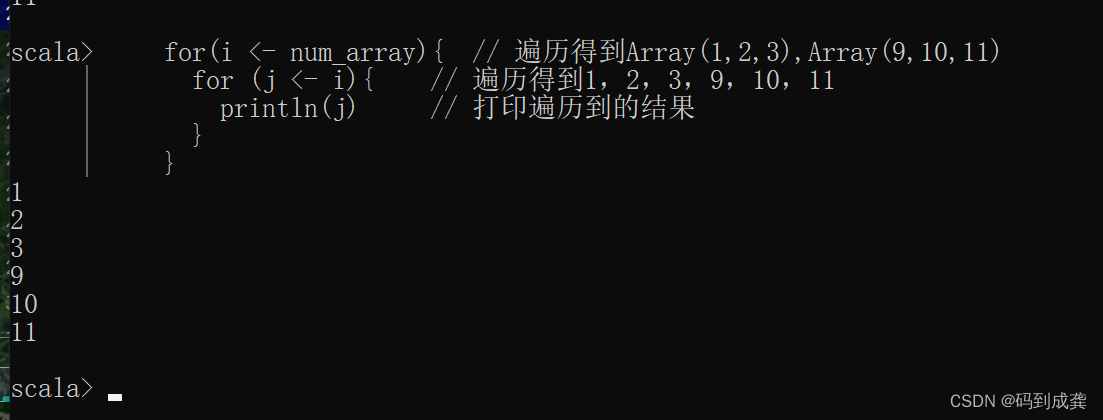
for(i <- num_array){ // 遍历得到Array(1,2,3),Array(9,10,11)
for (j <- i){ // 遍历得到1,2,3,9,10,11
println(j) // 打印遍历到的结果
}
}
具体是使用for函数和foreach函数看个人喜欢就行。
3,对集合中的元素进行运算后打印输出
如果我们不仅想要遍历出结果,也想要对其进行运算后再打印输出,那么我们可以在foreach中调用打印函数的时候将要打印的结果进行相应的运算即可,例如,现在我们想要将二维数组num_array中的每一个数组中的元素都乘3输出:
scala> num_array.foreach(element => element.foreach(element => {println(element*3)}))二,sorted函数
sorted函数一般用于一维数组的排序,并且是以从小打大的顺序进行即升序。如下我们有一个数列:
scala> val ar_im=Array(1,9,2,10,2)现在对其进行排序:
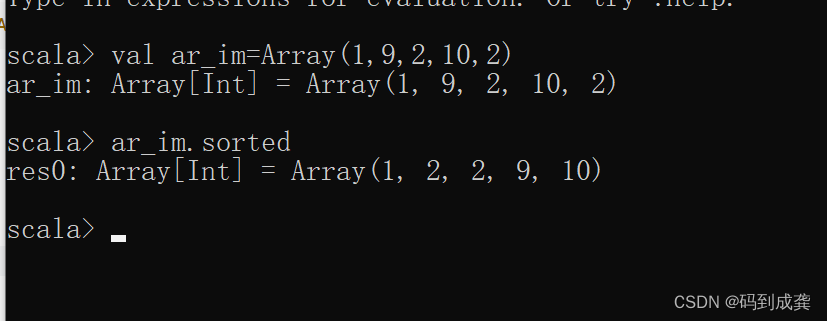
如上,我们可以看到,使用sorte函数的集合序列中的元素是从小到大进行排序显示的。
但是如果我们想要使用降序的方式输出结果,那么我们可以使用之前学习过的reverse函数来使数组集合进行反转即可:
scala> ar_im.sorted // 使用升序排序
res0: Array[Int] = Array(1, 2, 2, 9, 10)
scala> res0.reverse // 使用了降序排序
res1: Array[Int] = Array(10, 9, 2, 2, 1)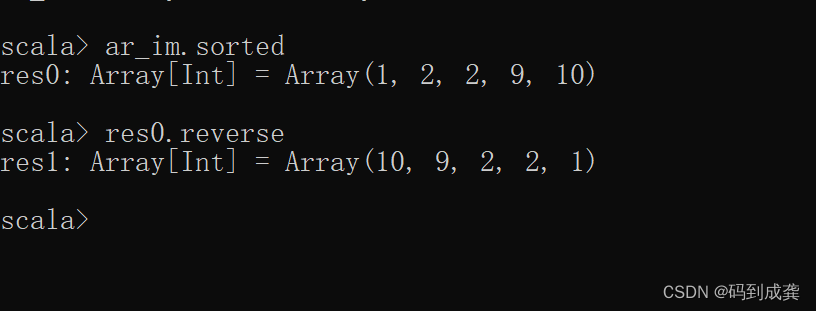
三,sortBy函数
sortBy函数与sorted函数相比的不同之处在于,sortBy函数可以传入参数,并指定嵌套集合序列中让哪一个元素作我们排序的标准。
现在我们有一个嵌套的集合序列【列表中嵌套对偶元组】:
val list_tup2=List(("张三",55),("张三",88),("李四",100))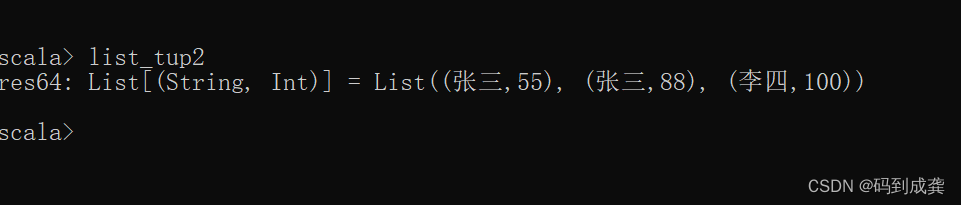
之前在创建的时候没有注意顺序,创建的对偶元组中第二个元素,现在后期去添加一个对偶元组进行并将新生成的列表用一个变量list_tup3来接收:
scala> list_tup2 // 原列表
res70: List[(String, Int)] = List((张三,55), (张三,88), (李四,100))
scala> val list_tup3=list_tup2.+:("王五",150) // 在列表的前面添加一个对偶元组
list_tup3: List[(String, Int)] = List((王五,150), (张三,55), (张三,88), (李四,100))
scala> list_tup3 // 新生成的列表
res71: List[(String, Int)] = List((王五,150), (张三,55), (张三,88), (李四,100))
1,使用sorted函数对列表中的对偶元组进行排序
如上,我们有了一个列表list_tup3数据。接下来我们使用sorted函数对其进行排序,结果如下:

虽然上面的数据看起来是按照对偶元组中的第二个元素进行排序的,其实不然,sorted函数在处理嵌套集合时,默认使用的是元组中的第一个元素进行排序,不信?我们继续去看===========
因为之前的列表创建的也很巧,所以现在我再在列表中添加一个key值比其他元素都长的对偶元组,如下,添加("德玛西亚",250)
scala> val list_tup4=list_tup3.:+("德玛西亚",250) // 在不可变列表的末尾添加数据
list_tup4: List[(String, Int)] = List((王五,150), (张三,55), (张三,88), (李四,100), (德玛西亚,250))
scala> list_tup4 // 查看新的列表
res75: List[(String, Int)] = List((王五,150), (张三,55), (张三,88), (李四,100), (德玛西亚,250))
 接下来我们再去使用之前的sorted函数,就会发现没有按照对偶元组中的第二个元素即数值进行排序:
接下来我们再去使用之前的sorted函数,就会发现没有按照对偶元组中的第二个元素即数值进行排序:

如上,value最大的250并没有在排序后的列表的最后面,所以sorted函数并不是按照元组中的第一个元素来进行排序。那么,如果我们想要根据元素的第二个元素进行排序该怎么办?这个时候就是sortBy展示的用武之时。
2,使用sortBy函数对列表中的对偶元组进行排序
【需要回顾的知识:元组的访问需要使用点下划线下标的方式,例如访问第一个元素tuple._1,第二个:tupel._2.... 以此类推】【在对偶元组中只有两个元素,所以接下来我们也只会使用到tuple._1(元组中的第一个元素 )与tuple._2(元组中的第二个元素)】
我们接下来需要做的就是向sortBy函数中传入元组中指定的元素来进行排序即可:
scala> list_tup4.sortBy(f=>f._1) // 以元组中的第一个元素进行排序即”张三“,德玛西亚"....
res82: List[(String, Int)] = List((张三,55), (张三,88), (德玛西亚,250), (李四,100), (王五,150))
scala> list_tup4.sortBy(f=>f._2) // 以元组中的第二个元组进行排序即55,88,100....
res83: List[(String, Int)] = List((张三,55), (张三,88), (李四,100), (王五,150), (德玛西亚,250))
scala> list_tup4.sorted // 以元组中的第一个元素进行排序即”张三“,德玛西亚"....
res84: List[(String, Int)] = List((张三,55), (张三,88), (德玛西亚,250), (李四,100), (王五,150))
如上,我们可以再一次证实sorted函数在对嵌套集合进行排序的时候是按照元组(或被嵌套序列)中的第一个元素来进行排序的。
3,使用sortBy函数对嵌套集合中的整型数组进行排序【以最大值】
嵌套的整型数组的列表:
scala> val list_arr=List(Array(1,2,4),Array(22,11,33)) // 列表嵌套数组之后我们可以使用sortBy函数: sortBy(f => f.max)将列表中的每一个数组的最大值进行比较,并将max值相对小的的排序到前面【主要是因为排序默认的都是升序】。
例如:获取数组中的最大值,将其使用sortBy函数排序进行比较并输出:
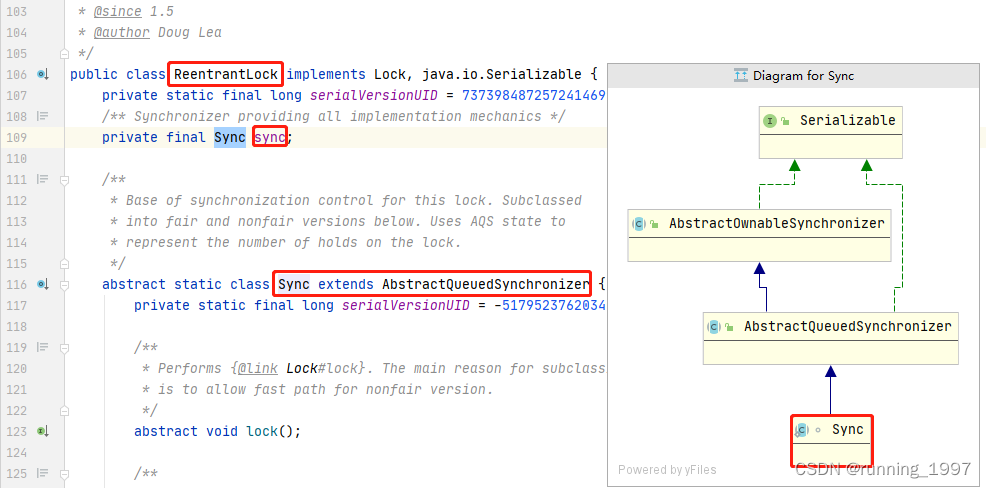
scala> list_arr // 原列表
res100: List[Array[Int]] = List(Array(1, 2, 4), Array(22, 11, 33))
scala> list_arr.sortBy(f=>f.max) // 对比数组中的最大值,并将最小的放前面
res101: List[Array[Int]] = List(Array(1, 2, 4), Array(22, 11, 33))
scala> // 如果想要将最大值大的放到排序结果的前面,可以使用reverse函数,反转列表
scala> res101.reverse // 反转列表
res102: List[Array[Int]] = List(Array(22, 11, 33), Array(1, 2, 4))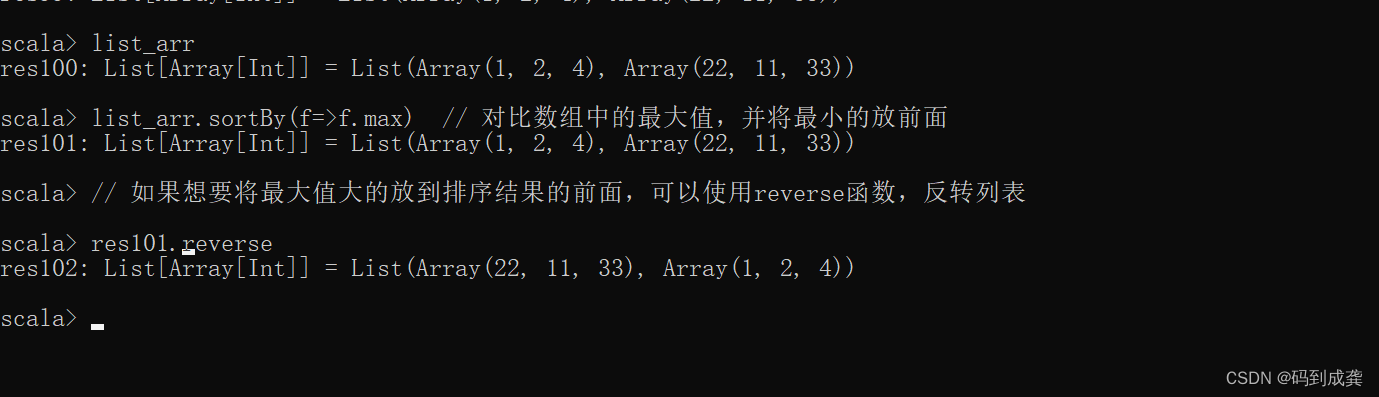
如上,当我们向sortBy函数中传入一个参数f,该参数表示的就是列表中嵌套的每一个数组,对于数组来说,有一个可以获取集合序列中最大值的函数max,当两个数组[1,2,4]及[22,11,33]都使用该函数之后,我们会得到它们中的最大值:4和33.。因为对于排序函数来说,都是默认使用升序来进行排序,所以如果想要使用降序的话,可以使用reverse函数来反转结果。
4,使用sortBy函数对嵌套集合中的整型数组进行排序【以平均值】
sortBy函数里面传入的参数可以有多种表达式,之前我们使用的是数组自带的函数来作为排序的依据,如果我们想要以数组中平均值来进行排序,并且将平均值大的放到列表中靠前的位置,该咋搞?对于Java和Scala来说,不存在获取平均值的函数,但是我们可以使用公式:avg=sum/size(length)获得。接下来我们去使用相关的代码查看具体的实现:
scala> // 以平均值作为排序的依据
scala> list_arr.sortBy(f => f.sum/f.length)
res0: List[Array[Int]] = List(Array(1, 2, 4), Array(22, 11, 33))
scala> res0.reverse // 反转列表
res1: List[Array[Int]] = List(Array(22, 11, 33), Array(1, 2, 4))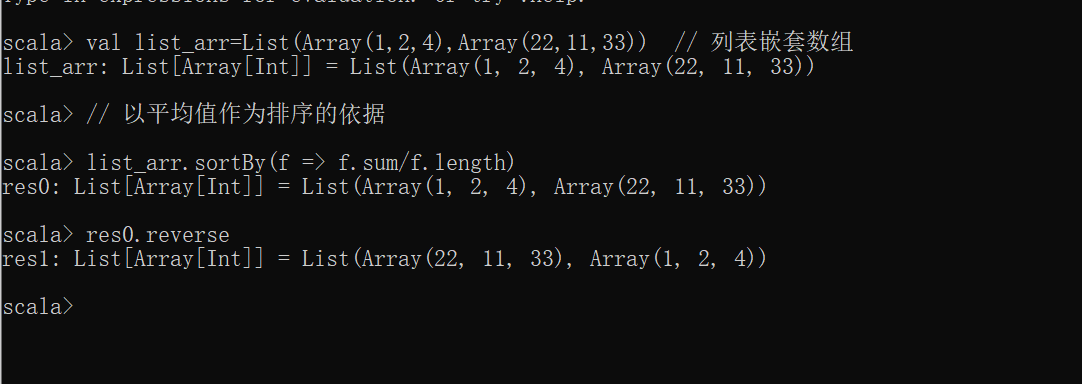
【白看不如一做,建议先运行代码之后再去理解】
接下来我们继续学习排序相关的函数,sortWith函数。
四,sortWith函数
sortWith函数与sorted函数相比,有一个很大的有点,就是我们可以指定我们排序的方式;
与sortBy相比,sortWith更加灵活,里面可以指定相关的比较表达式,直接就可以实现集合序列的降序排序。
当我们使用sorted函数或者是sortBy函数时只能对集合序列进行一种处理:升序排序。但是如果我们使用sortWith函数的话就可以在里面写上一些表达式来完成对集合序列的降序处理,
现在我们有如下一个数组:
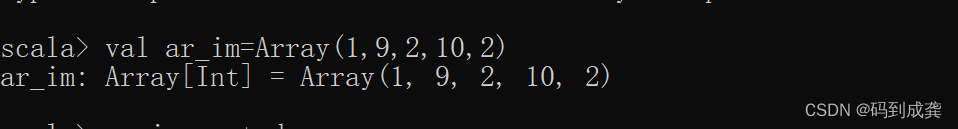
接下来我们使用去sortWith函数将里面的元素按照降序排序:
scala> ar_im // 原数组
res7: Array[Int] = Array(1, 9, 2, 10, 2)
scala> ar_im.sortWith((a:Int,b:Int) => {a>b}) // 使用降序排序
res8: Array[Int] = Array(10, 9, 2, 2, 1)
如上,我们可以看到在使用sortWith能够实现集合序列的降序排序(指定条件:需要前面的元素大于后面的元素)。如果想要实现升序的话,直接调用sorted函数就行。
五,flatten函数
flatten函数主要是解决集合序列的起摞问题:集合中的元素被其他对象包裹,获取困难。
1,例如无嵌套集合序列中的起摞:想要获取的元素被其他对象数据类型包裹
List("a,b,c","d,e,f")----> a,b,c,d,e,f等元素分别被字符串包裹
2,例如map集合序列中的起摞:map集合序列嵌套在了其他的集合序列中,如列表,数组
List(map("a" -> 1),map("b" -> 2))
3,例如嵌套集合序列中的起摞:列表list或者是数组array中嵌套了对偶元组
List(("a",1),("b",2))
接下来我们去一一了解与学习。
1,数组Array或者是列表List中嵌套字符串的起摞问题
该种类型的起摞最直接的表现形式就是我们要获取的元素被其他对象数据类型包裹,如下:
List("a,b,c","d,e,f")
a,b,c,d,e,f等元素分别被字符串包裹,但是它们依旧是在数组array或者是列表list集合序列中,这个时候如果我们直接让它调用flatten函数也是可以的,但是因为在字符串中含有逗号,所以在进行扁平化的时候也会将逗号显示出来(默认也将逗号识别为一个元素):
scala> val listDemo1=List("a,b,c","d,e,f") // 无嵌套集合序列的起摞问题
listDemo1: List[String] = List(a,b,c, d,e,f)
scala> listDemo1.flatten // 将起摞的集合进行扁平化操作
res2: List[Char] = List(a, ,, b, ,, c, d, ,, e, ,, f)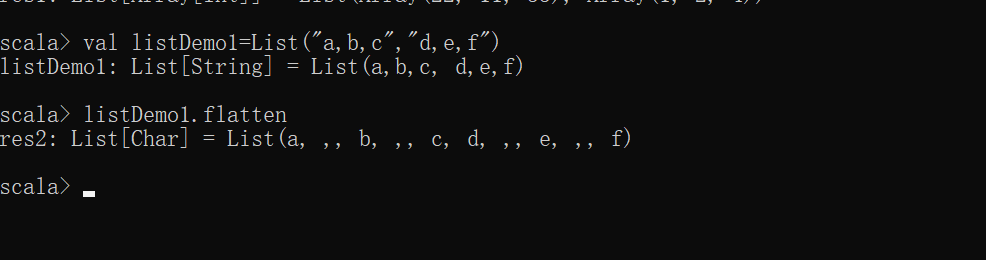
如上,显然是不大美观并且也不符合我们的需求的,所以在对它进行扁平化操作之前,我们可以先将字符串切割成数组之后再对其进行扁平化操作:
scala> val qiluo_arr=listDemo1.map(f => f.split(",")) // 字符串切割,得到数组
qiluo_arr: List[Array[String]] = List(Array(a, b, c), Array(d, e, f))
scala> qiluo_arr.flatten
res4: List[String] = List(a, b, c, d, e, f)
现在我们就得到了一个干净清爽的列表,后期对它的操作就会更加方便。
2,数组或者是列表包含有map集合的起摞问题
map集合起摞就是map集合序列嵌套在了其他的集合序列中,如列表,数组。如下:
List(Map("a" -> 1),Map("b" -> 2))
以上的集合如果直接调用flatten函数,得到的数据只是一个含有对偶元组的集合序列:
scala> qiluo_map // 列表中含有map集合,为map起摞问题
res6: List[scala.collection.immutable.Map[String,Int]] = List(Map(a -> 1), Map(b -> 2))
scala> qiluo_map.flatten
res7: List[(String, Int)] = List((a,1), (b,2)) 如上得到的结果依旧存在起摞问题,不是我们想要的数据,如果我们想要将上述的数据结构转换成:List(a,1,b,2)。不仅仅需要调用flatten函数将该数据结构转换成列表中嵌套对偶元组的数据,之后还得再使用map函数,将对偶元组转换成数组或者是列表,最后再次使用flatten函数即可:
如上得到的结果依旧存在起摞问题,不是我们想要的数据,如果我们想要将上述的数据结构转换成:List(a,1,b,2)。不仅仅需要调用flatten函数将该数据结构转换成列表中嵌套对偶元组的数据,之后还得再使用map函数,将对偶元组转换成数组或者是列表,最后再次使用flatten函数即可:
scala> qiluo_map
res11: List[scala.collection.immutable.Map[String,Int]] = List(Map(a -> 1), Map(b -> 2))
scala> qiluo_map.flatten // 将存在起摞问题的集合序列扁平化
res12: List[(String, Int)] = List((a,1), (b,2))
scala> res12.map(f=>List(f._1,f._2)) // 将含有对偶元组转换成数组或者是列表这两种集合序列中的一个
res13: List[List[Any]] = List(List(a, 1), List(b, 2))
scala> res13.flatten
res14: List[Any] = List(a, 1, b, 2)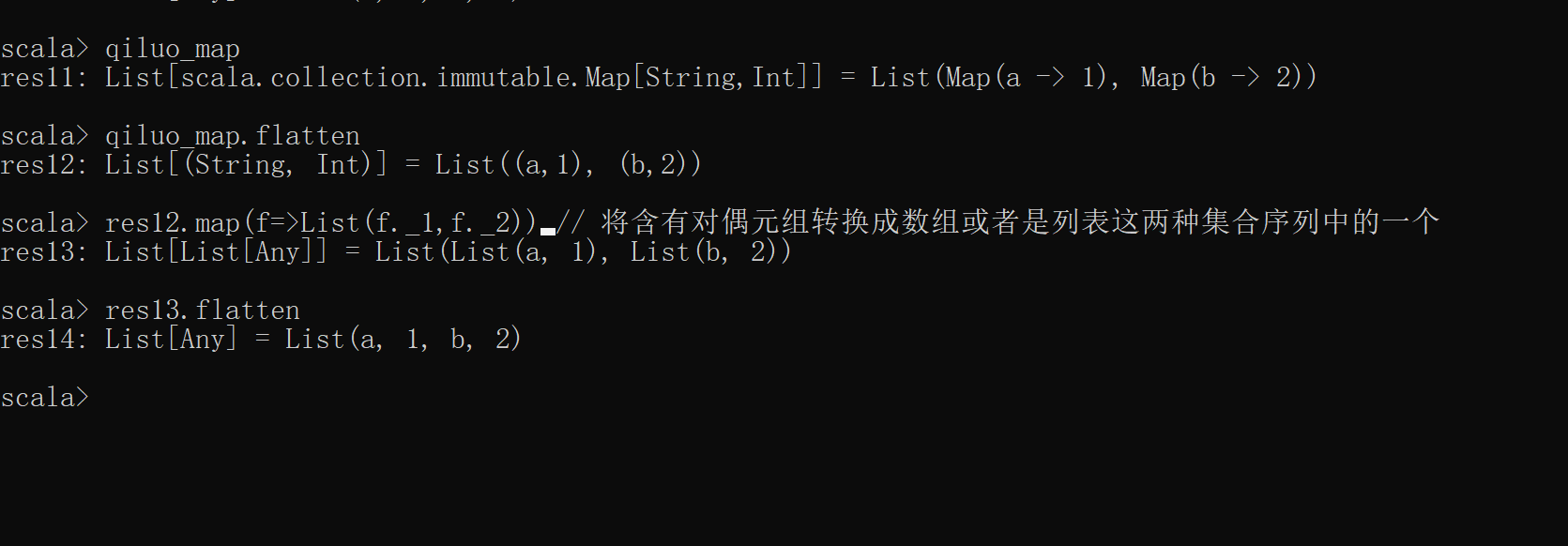
3,数组或者是列表中包含有对偶元组的起摞问题
列表list或者是数组array中嵌套了对偶元组,例如:List(("a",1),("b",2))
对于上面这样的数据结构来说,不能够直接使用flatten函数对其处理,因为严格意义上来说,元组并不是一种集合,它只是一种序列而已,flatten函数一般就是用来对集合序列进行扁平化的,如果直接对含有对偶元组的集合序列直接使用flatten会出现报错:
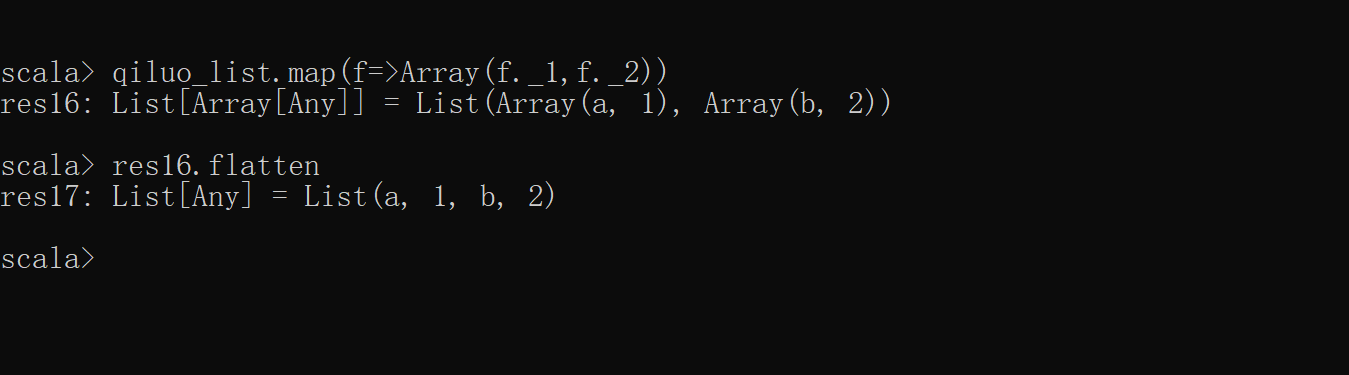
scala> val qiluo_list=List(("a",1),("b",2)) 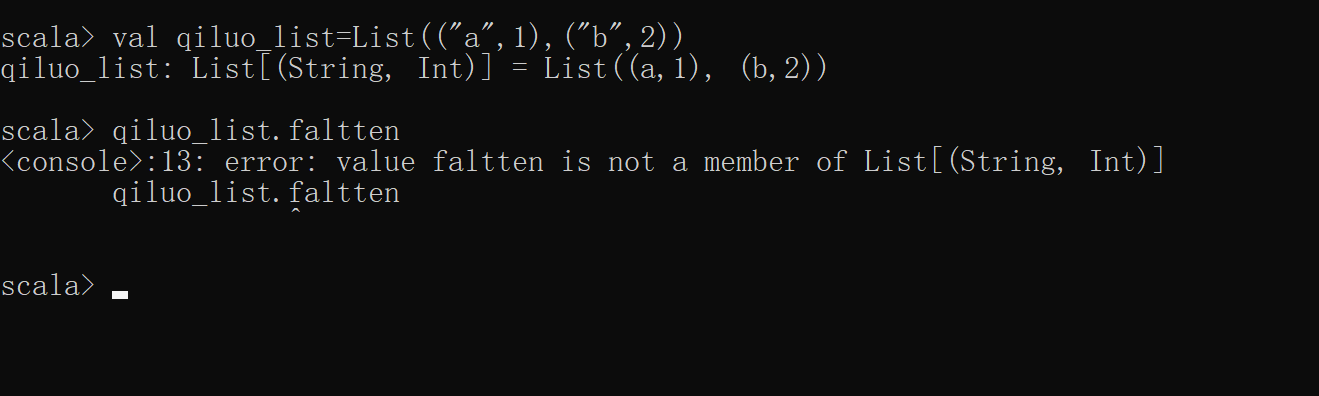
如果想要得到这种集合序列;List(a,1,b,2),可以使用map函数先将对偶元组都转换成数组或是列表类型的数据,保证了集合序列中的所有序列都是集合之后我们再去使用flatten函数,对数据结构进行扁平化操作。如下:
scala> qiluo_list.map(f=>Array(f._1,f._2)) // 将对偶元组转换成数组或是列表
res16: List[Array[Any]] = List(Array(a, 1), Array(b, 2))
scala> res16.flatten
res17: List[Any] = List(a, 1, b, 2)
六,map函数
map函数,可以用来做映射用,例如参入参数,之后再返回进过自定义处理的数据。
1,list集合中的元素进行加减乘除运算
现在我们有一个列表:List(1,2,3,4),我们可以对里面的元素进行加减乘除运算,现在我想要列表中的每一个元素都加上18,那么我该怎么去写?很简单,传入一个参数(该参数代表列表中的每一个元素),并让这个参数去加上18即可,如下:
scala> listDemo
res4: List[Int] = List(1, 2, 3, 4)
scala> listDemo.map(f=>f+18)
res5: List[Int] = List(19, 20, 21, 22)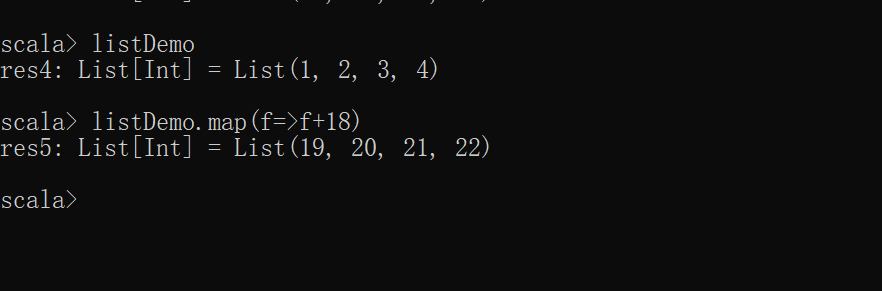
或者是乘18也可以:

2,对list嵌套array集合序列中的元素进行加减乘除运算
上面我还只是对不是嵌套的集合序列进行处理,如果我想要将下面的集合序列里面的元素都加18的话
scala> val listArray=List(Array(1,2,3),Array(5,7,8))
我就得需要先获取到被嵌套的集合序列(以上面的数据结构为例,被嵌套的集合序列为数组),就得需要使用两次map函数(第一次获取到每一个数组,第二次获取到数组中的每一个元素):
scala> listArray
res11: List[Array[Int]] = List(Array(1, 2, 3), Array(5, 7, 8))
scala> listArray.map(arr=>arr.map(f=>f+18))
res12: List[Array[Int]] = List(Array(19, 20, 21), Array(23, 25, 26))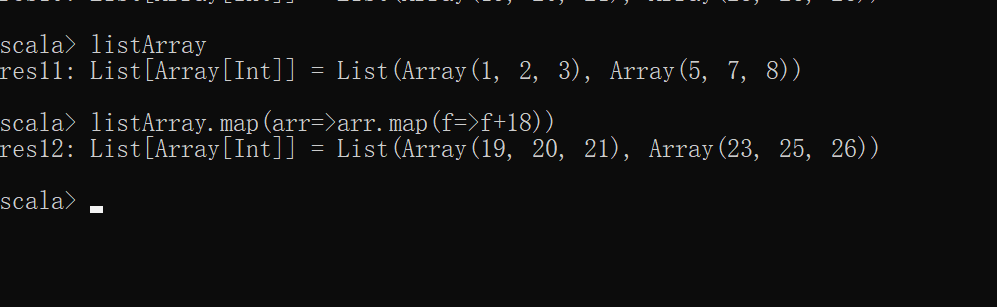
七,flatMap函数
flapMap函数与flatten函数相比,flatMap函数可以实现扁平化与数据处理同时进行。
相信之前看过了flatten函数对一些存在有起摞问题的数据进行处理的时候是先将数据转换成都是集合序列的数据结构,最后才是使用flatten函数进行扁平化处理。但是使用了flatMap之后就会发现这个函数真的不要太贴心,可以省掉一些重复的扁平化操作,如下,之前我们在处理List(("a",1),("b",2)) 集合序列的时候先使用了map函数再使用了flatten函数才得到:List(a, 1, b, 2)
现在我们来使用flatMap函数,来实现相同的效果:由List(("a",1),("b",2))得到List(a, 1, b, 2):
scala> val qiluo_list=List(("a",1),("b",2))
qiluo_list: List[(String, Int)] = List((a,1), (b,2))
scala> qiluo_list.flatMap(f=>Array(f._1,f._2)) // 一次性处理起摞集合序列
res0: List[Any] = List(a, 1, b, 2)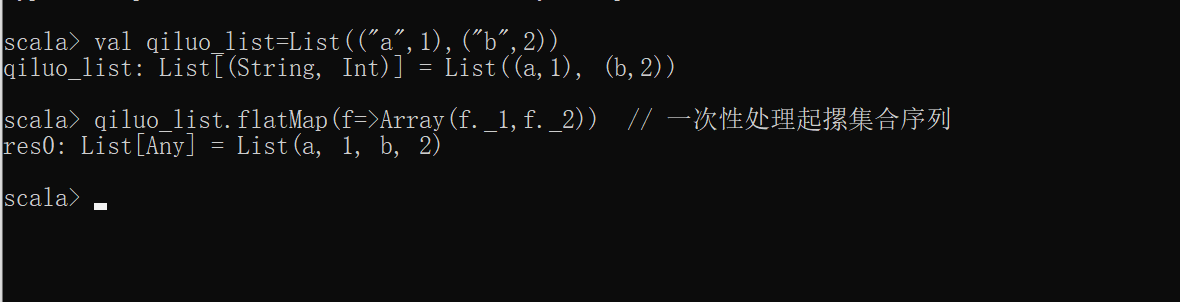
我们可以发现使用flatMap直接一步到位,不需要再在最后去使用flatten进行扁平化处理。
以上就是常用的几个有关集合函数的使用和代码及操作展示,有问题的请在评论区留言。