先总结:
- 数据量小的时候,用join更划算
- 数据量大的时候,join的成本更高,但相对来说join的速度会更快
- 数据量过大的时候,in的数据量过多,会有无法执行SQL的问题,待解决
事情是这样的,去年入职的新公司,之后在代码review的时候被提出说,不要写join,join耗性能还是慢来着,当时也是真的没有多想,那就写in好了,最近发现in的数据量过大的时候会导致sql慢,甚至sql太长,直接报错了。这次来浅究一下,到底是in好还是join好,仅目前认知探寻,有不对之处欢迎指正
以下实验仅在本机电脑试验
一、表结构
1、用户表

CREATE TABLE `user` (
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(64) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '姓名',
`gender` smallint DEFAULT NULL COMMENT '性别',
`mobile` varchar(11) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '手机号',
`create_time` datetime NOT NULL COMMENT '创建时间',
PRIMARY KEY (`id`),
UNIQUE KEY `mobile` (`mobile`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1005 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci
2、订单表

CREATE TABLE `order` (
`id` int unsigned NOT NULL AUTO_INCREMENT,
`price` decimal(18,2) NOT NULL,
`user_id` int NOT NULL,
`product_id` int NOT NULL,
`status` smallint NOT NULL DEFAULT '0' COMMENT '订单状态',
PRIMARY KEY (`id`),
KEY `user_id` (`user_id`),
KEY `product_id` (`product_id`)
) ENGINE=InnoDB AUTO_INCREMENT=202 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci
二、先来试少量数据的情况
用户表插一千条随机生成的数据,订单表插一百条随机数据
查下所有的订单以及订单对应的用户
下面从三个维度来看
多表连接查询成本 = 一次驱动表成本 + 从驱动表查出的记录数 * 一次被驱动表的成本
1、join
JOIN: explain format=json select order.id, price, user.
namefromorderjoin user on order.user_id = user.id;子查询: select order.id,price,user.
namefromorder,user where user_id=user.id;
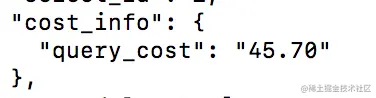
2、分开查
select
id,price,user_id fromorder;

select name from user where id in (8, 11, 20, 32, 49, 58, 64, 67, 97, 105, 113, 118, 129, 173, 179, 181, 210, 213, 215, 216, 224, 243, 244, 251, 280, 309, 319, 321, 336, 342, 344, 349, 353, 358, 363, 367, 374, 377, 380, 417, 418, 420, 435, 447, 449, 452, 454, 459, 461, 472, 480, 487, 498, 499, 515, 525, 525, 531, 564, 566, 580, 584, 586, 592, 595, 610, 633, 635, 640, 652, 658, 668, 674, 685, 687, 701, 718, 720, 733, 739, 745, 751, 758, 770, 771, 780, 806, 834, 841, 856, 856, 857, 858, 882, 934, 942, 983, 989, 994, 995); [in的是order查出来的所有用户id]

如此看来,分开查和join查的成本并没有相差许多
3、代码层面
主要用php原生写了脚本,用ab进行10个同时的请求,看下时间,进行比较
ab -n 100 -c 10
in
$mysqli = new mysqli('127.0.0.1', 'root', 'root', 'test');
if ($mysqli->connect_error) {
die('Connect Error (' . $mysqli->connect_errno . ') ' . $mysqli->connect_error);
}
$result = $mysqli->query('select `id`,price,user_id from `order`');
$orders = $result->fetch_all(MYSQLI_ASSOC);
$userIds = implode(',', array_column($orders, 'user_id')); // 获取订单中的用户id
$result = $mysqli->query("select `id`,`name` from `user` where id in ({$userIds})");
$users = $result->fetch_all(MYSQLI_ASSOC);// 获取这些用户的姓名
// 将id做数组键
$userRes = [];
foreach ($users as $user) {
$userRes[$user['id']] = $user['name'];
}
$res = [];
// 整合数据
foreach ($orders as $order) {
$current = [];
$current['id'] = $order['id'];
$current['price'] = $order['price'];
$current['name'] = $userRes[$order['user_id']] ?: '';
$res[] = $current;
}
var_dump($res);
// 关闭mysql连接
$mysqli->close();

join
$mysqli = new mysqli('127.0.0.1', 'root', 'root', 'test');
if ($mysqli->connect_error) {
die('Connect Error (' . $mysqli->connect_errno . ') ' . $mysqli->connect_error);
}
$result = $mysqli->query('select order.id, price, user.`name` from `order` join user on order.user_id = user.id;');
$orders = $result->fetch_all(MYSQLI_ASSOC);
var_dump($orders);
$mysqli->close();
复制代码
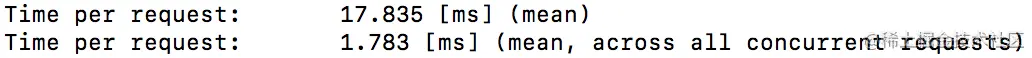
看时间的话,明显join更快一些
三、试下多一些数据的情况
user表现在10000条数据,order表10000条试下
1、join

2、分开

user
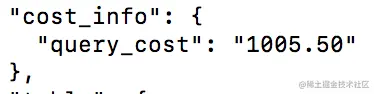
3、代码层面
in
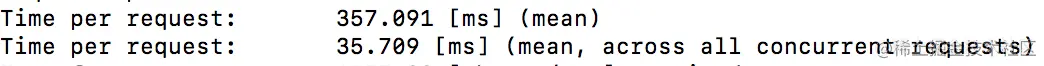
join
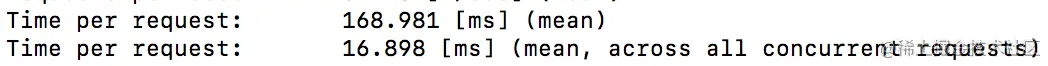
三、试下多一些数据的情况
随机插入后user表十万条数据,order表一百万条试下
1、join
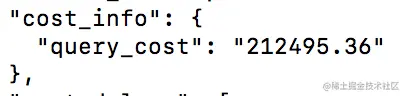
2、分开
order

user
order查出来的结果过长了,
3、代码层面
in
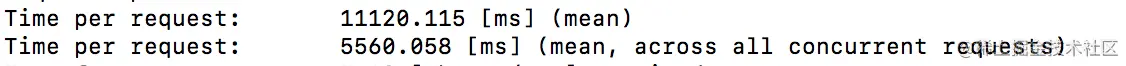
join

四、到底怎么才能更好
注:对于本机来说100000条数据不少了,更大的数据量害怕电脑卡死
总的来说,当数据量小时,可能一页数据就够放的时候,join的成本和速度都更好。数据量大的时候确实分开查的成本更低,但是由于数据量大,造成循环的成本更多,代码执行的时间也就越长。实验过程中发现,当in的数据量过大的时候,sql过长会无法执行,可能还要拆开多条sql进行查询,这样的查询成本和时间一定也会更长,而且如果有分页的需求的话,也无法满足。。。
感觉这两个方法都不是太好,各位小伙伴,有没有更好的方法呢?

![[acwing周赛复盘] 第 60 场周赛20220716](https://img-blog.csdnimg.cn/91063086883741c3b1f9b389fbcdd3da.png)