[acwing周赛复盘] 第 60 场周赛20220716
- 一、本周周赛总结
- 二、 4722. 数列元素
- 1. 题目描述
- 2. 思路分析
- 3. 代码实现
- 三、4723. 队列
- 1. 题目描述
- 2. 思路分析
- 3. 代码实现
- 四、4724. 靓号
- 1. 题目描述
- 2. 思路分析
- 3. 代码实现
- 六、参考链接
一、本周周赛总结
- 第一次打acwing,一共三题,难度跳跃挺大。
- acwing python竟然不支持from math import comb,震惊!还得自己实现。


二、 4722. 数列元素
链接: 4722. 数列元素
1. 题目描述

2. 思路分析
- 直接从1到n枚举,计算等比数列和即可。
3. 代码实现
import sys
from collections import *
from contextlib import redirect_stdout
from itertools import *
from math import sqrt
from array import *
from functools import lru_cache
import heapq
import bisect
import random
import io, os
from bisect import *
RI = lambda: map(int, sys.stdin.buffer.readline().split())
RS = lambda: map(bytes.decode, sys.stdin.buffer.readline().strip().split())
RILST = lambda: list(RI())
DEBUG = lambda x: sys.stderr.write(f'{str(x)}\n')
MOD = 10 ** 9 + 7
def main():
n, = RI()
for i in range(1,n+1):
if i*(i+1)//2 == n:
return print('YES')
print('NO')
if __name__ == '__main__':
# testcase 2个字段分别是input和output
test_cases = (
(
"""
1
""",
"""
YES
"""
),
(
"""
2
""",
"""
NO
"""
),
(
"""
3
""",
"""
YES
"""
),
)
if os.path.exists('test.test'):
total_result = 'ok!'
for i, (in_data, result) in enumerate(test_cases):
result = result.strip()
with io.StringIO(in_data.strip()) as buf_in:
RI = lambda: map(int, buf_in.readline().split())
RS = lambda: buf_in.readline().strip().split()
with io.StringIO() as buf_out, redirect_stdout(buf_out):
main()
output = buf_out.getvalue().strip()
if output == result:
print(f'case{i}, result={result}, output={output}, ---ok!')
else:
print(f'case{i}, result={result}, output={output}, ---WA!---WA!---WA!')
total_result = '---WA!---WA!---WA!'
print('\n', total_result)
else:
main()
三、4723. 队列
链接: 4723. 队列
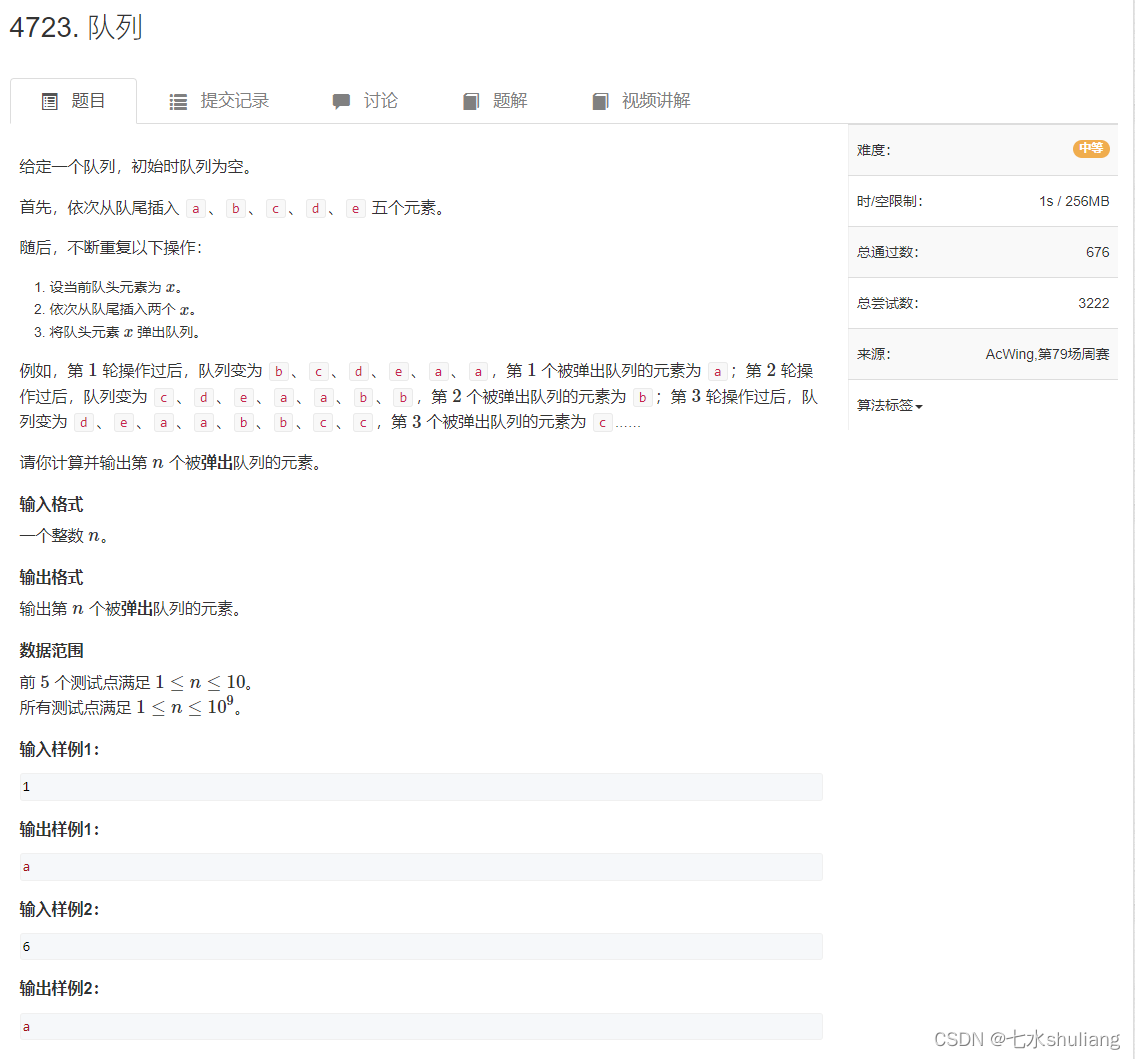
1. 题目描述
2. 思路分析
- 模拟一下可知,出队数据会被分成k个部分,第一部分有5个元素,第二部分是第一部分double:10个,第三部分20。。。
- 我们让n依次减去这些部分,直到n无法构成下一个完整的部分。
- 计算剩余的n在这个部分的哪个区域,区域的大小是x//5
- 复杂度显然是开方的,因为是减去等差数列求和,这个和将以x方的速度增长到n。
3. 代码实现
import sys
from collections import *
from contextlib import redirect_stdout
from itertools import *
from math import sqrt
from array import *
from functools import lru_cache
import heapq
import bisect
import random
import io, os
from bisect import *
RI = lambda: map(int, sys.stdin.buffer.readline().split())
RS = lambda: map(bytes.decode, sys.stdin.buffer.readline().strip().split())
RILST = lambda: list(RI())
DEBUG = lambda x: sys.stderr.write(f'{str(x)}\n')
MOD = 10 ** 9 + 7
# ms
def solve(n):
a = 'abcde'
if n <= 5:
return print(a[n-1])
x = 5
while n > x:
n -= x
x *= 2
if n == 0:
return print('e')
y = (n-1) // (x // 5)
print(a[y])
def main():
n, = RI()
solve(n)
if __name__ == '__main__':
# testcase 2个字段分别是input和output
test_cases = (
(
"""
1
""",
"""
a
"""
),
(
"""
8
""",
"""
a
"""
),
)
if os.path.exists('test.test'):
total_result = 'ok!'
for i, (in_data, result) in enumerate(test_cases):
result = result.strip()
with io.StringIO(in_data.strip()) as buf_in:
RI = lambda: map(int, buf_in.readline().split())
RS = lambda: buf_in.readline().strip().split()
with io.StringIO() as buf_out, redirect_stdout(buf_out):
main()
output = buf_out.getvalue().strip()
if output == result:
print(f'case{i}, result={result}, output={output}, ---ok!')
else:
print(f'case{i}, result={result}, output={output}, ---WA!---WA!---WA!')
total_result = '---WA!---WA!---WA!'
print('\n', total_result)
else:
main()
四、4724. 靓号
链接: 4724. 靓号
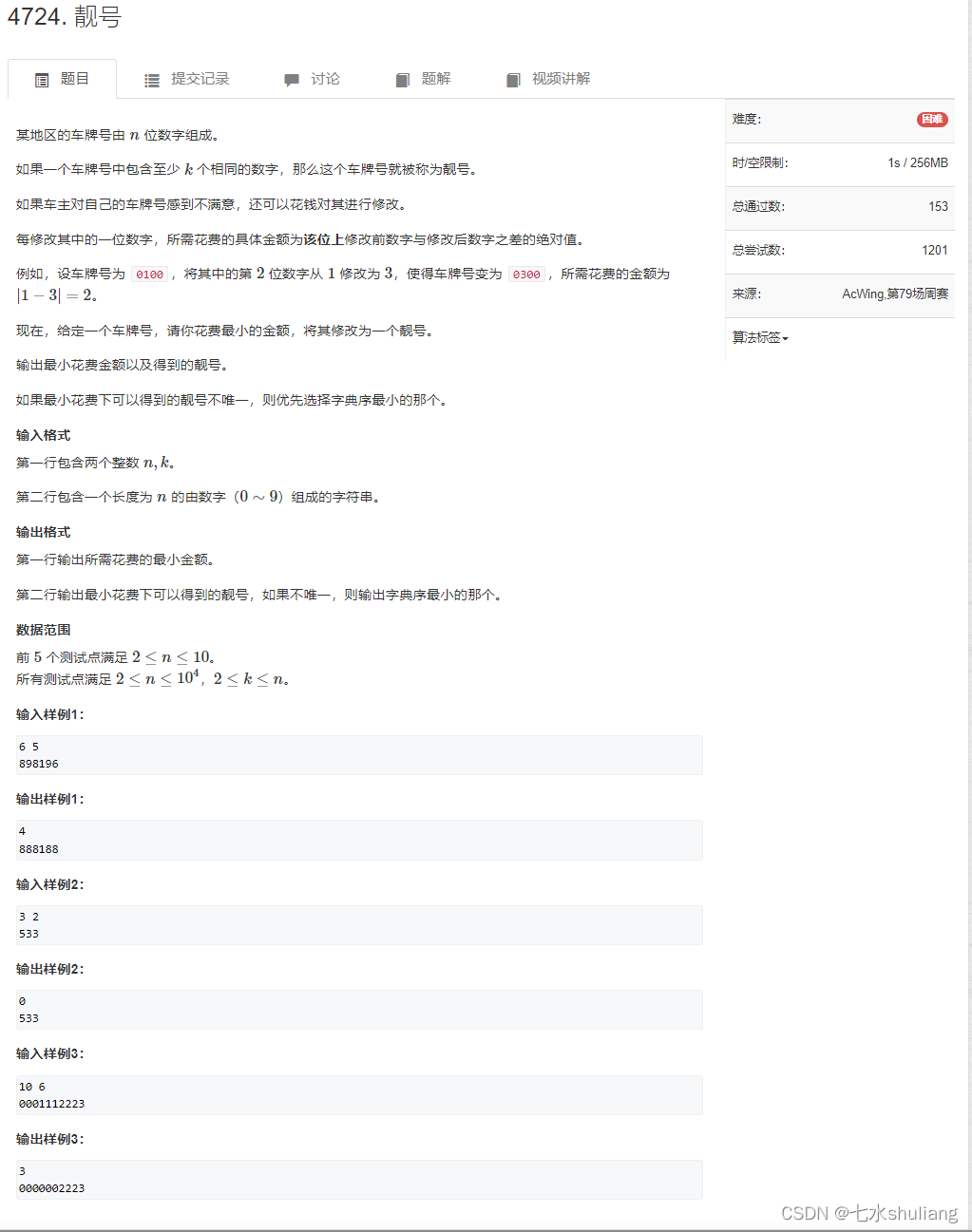
1. 题目描述
2. 思路分析
二分然后构造答案
- 先计数找出最多的那个数的次数,记为mx,如果mx>=k,则直接返回不用花费任何。
- 我们定义calc(x)为花费x及以上是否能改成靓号,显然这个是具有单调性的,可以二分一下,求出最小x。
- calc的实现可以枚举i∈{0-9},尝试把其它数字改成i,这里贪心一下,由于花费是两数之差,因此顺序一定是从i向左右两端扩展来优先获得最小花费。
- 构造答案是最费劲的,当我们知道最小花费是mn后,可能存在多种构造方式满足最小花费,但如何取最小呢。
- 依然枚举i∈{0-9},尝试把其它数字改成i,然后比较10个答案中的字典序最小的那个。
- 对特定的i,修改其它数字j时,要遵循一个原则,先修改比它大的j,从左到右;后修改比它小的j,从右向左。
- 因为:
- 如果j<i,修改j显然会使字典序变大。
- 如果j>i,修改j显然会使字典序变小。
3. 代码实现
import sys
from collections import *
from contextlib import redirect_stdout
from itertools import *
from math import sqrt
from array import *
from functools import lru_cache
import heapq
import bisect
import random
import io, os
from bisect import *
RI = lambda: map(int, sys.stdin.buffer.readline().split())
RS = lambda: map(bytes.decode, sys.stdin.buffer.readline().strip().split())
RILST = lambda: list(RI())
DEBUG = lambda x: sys.stderr.write(f'{str(x)}\n')
MOD = 10 ** 9 + 7
def my_bisect_left(a, x, lo=None, hi=None, key=None):
"""
由于3.10才能用key参数,因此自己实现一个。
:param a: 需要二分的数据
:param x: 查找的值
:param lo: 左边界
:param hi: 右边界(闭区间)
:param key: 数组a中的值会依次执行key方法,
:return: 第一个大于等于x的下标位置
"""
if not lo:
lo = 0
if not hi:
hi = len(a) - 1
else:
hi = min(hi, len(a) - 1)
size = hi - lo + 1
if not key:
key = lambda _x: _x
while size:
half = size >> 1
mid = lo + half
if key(a[mid]) < x:
lo = mid + 1
size = size - half - 1
else:
size = half
return lo
def solve(n, k, s):
s = list(map(int, s))
cnt = Counter(s)
mx = max(cnt.values())
if mx >= k:
return print(f"0\n{''.join(map(str, s))}")
poses = [[] for _ in range(10)]
for i, v in enumerate(s):
poses[v].append(i)
# 花x是否能搞出k个相同
def calc(x):
def f(i):
cost = 0
remain = k - cnt[i]
for j in range(1, 10):
if remain <= 0: break
for p in i - j, i + j:
if 0 <= p <= 9:
c = min(cnt[p], remain)
cost += c * j
if cost > x: break
remain -= c
return cost
return any(f(i) <= x for i in range(10))
mn = my_bisect_left(range(n * 10), True, key=calc)
# DEBUG(mn)
print(mn)
def find(i):
t = s[:]
cost = 0
remain = k - cnt[i]
for j in range(1, 10):
if remain <= 0:
return ''.join(map(str, t))
p = i + j
if 0 <= p <= 9:
ps = poses[p]
c = min(cnt[p], remain)
cost += c * j
for x in range(c):
t[ps[x]] = i
if cost > mn: break
remain -= c
p = i - j
if 0 <= p <= 9:
ps = poses[p][::-1]
c = min(cnt[p], remain)
cost += c * j
for x in range(c):
t[ps[x]] = i
if cost > mn: break
remain -= c
if remain <= 0:
return ''.join(map(str, t))
return 's'
# for i in range(10):
# DEBUG((i,find(i)))
print(min(find(i) for i in range(10)))
def main():
n, k = RI()
s, = RS()
solve(n, k, s)
if __name__ == '__main__':
# testcase 2个字段分别是input和output
test_cases = (
(
"""
6 5
898196
""",
"""
4
888188
"""
),
(
"""
3 2
533
""",
"""
0
533
"""
),
(
"""
10 6
0001112223
""",
"""
3
0000002223
"""
),
(
"""
3 2
531
""",
"""
2
331
"""
),
)
if os.path.exists('test.test'):
total_result = 'ok!'
for i, (in_data, result) in enumerate(test_cases):
result = result.strip()
with io.StringIO(in_data.strip()) as buf_in:
RI = lambda: map(int, buf_in.readline().split())
RS = lambda: buf_in.readline().strip().split()
with io.StringIO() as buf_out, redirect_stdout(buf_out):
main()
output = buf_out.getvalue().strip()
if output == result:
print(f'case{i}, result={result}, output={output}, ---ok!')
else:
print(f'case{i}, result={result}, output={output}, ---WA!---WA!---WA!')
total_result = '---WA!---WA!---WA!'
print('\n', total_result)
else:
main()
六、参考链接
- 无



![[附源码]Python计算机毕业设计儿童闲置物品交易网站](https://img-blog.csdnimg.cn/8085f7fcbf1c49688ca327ba9ce8c968.png)