数据同步到PG时遇到的分区不存在问题
- 前言
- 正文
- 问题分析
- 解决方法
- 结语
前言
大概说下这个问题牵扯出来的背景,一个外场项目,选型用PG存业务数据,然后客户要求保存保留一年的数据,运行到现在服务器5个T的磁盘已经有点扛不住了,使用率接近90%:
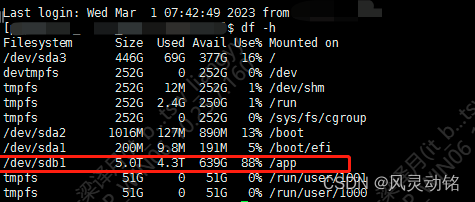
项目经理无能,跟客户沟通调整存储周期无果,就把压力转给运维运营团队,经过一堆坎坷,最后决定用datax把原pg的数据同步到另一个同配置的pg节点去,然后再把原始数据清理掉,这样等于是变相的进行了存储的冷热分割了。
至于同步走的数据客户要的时候怎么办,那自然就是再同步回去了(甲方确实会想出这种刁难你的活路)
正文
问题分析
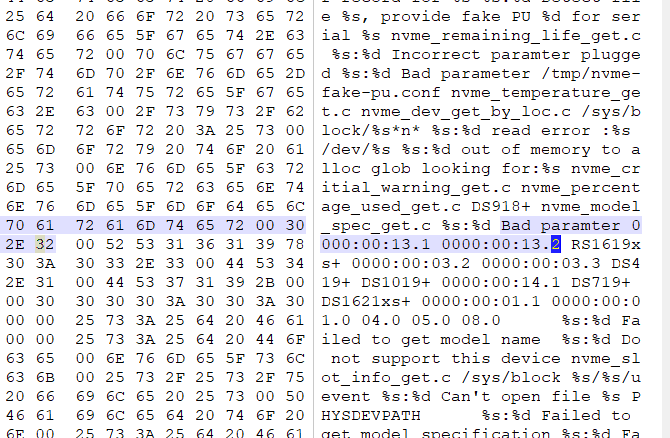
按照计划,开始进行数据同步,在部门的运维同事进行datax同步的时候一直说有问题,数据同步不了,截图如下:
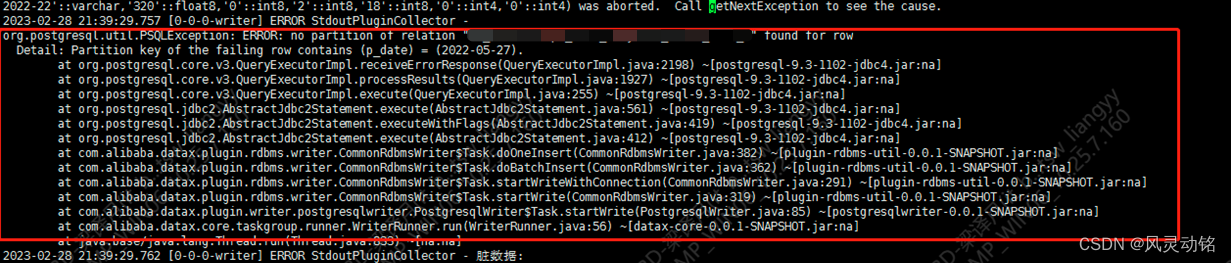
报错信息:
no partition of relation "table_name" found for row
问题就是进行数据写入的时候,找不到对应的分区,这个触发的原因也比较简单,建表语句是:
CREATE TABLE table_name (
......
p_date varchar(255) NULL DEFAULT NULL::character varying,
......
)
PARTITION BY LIST (p_date);
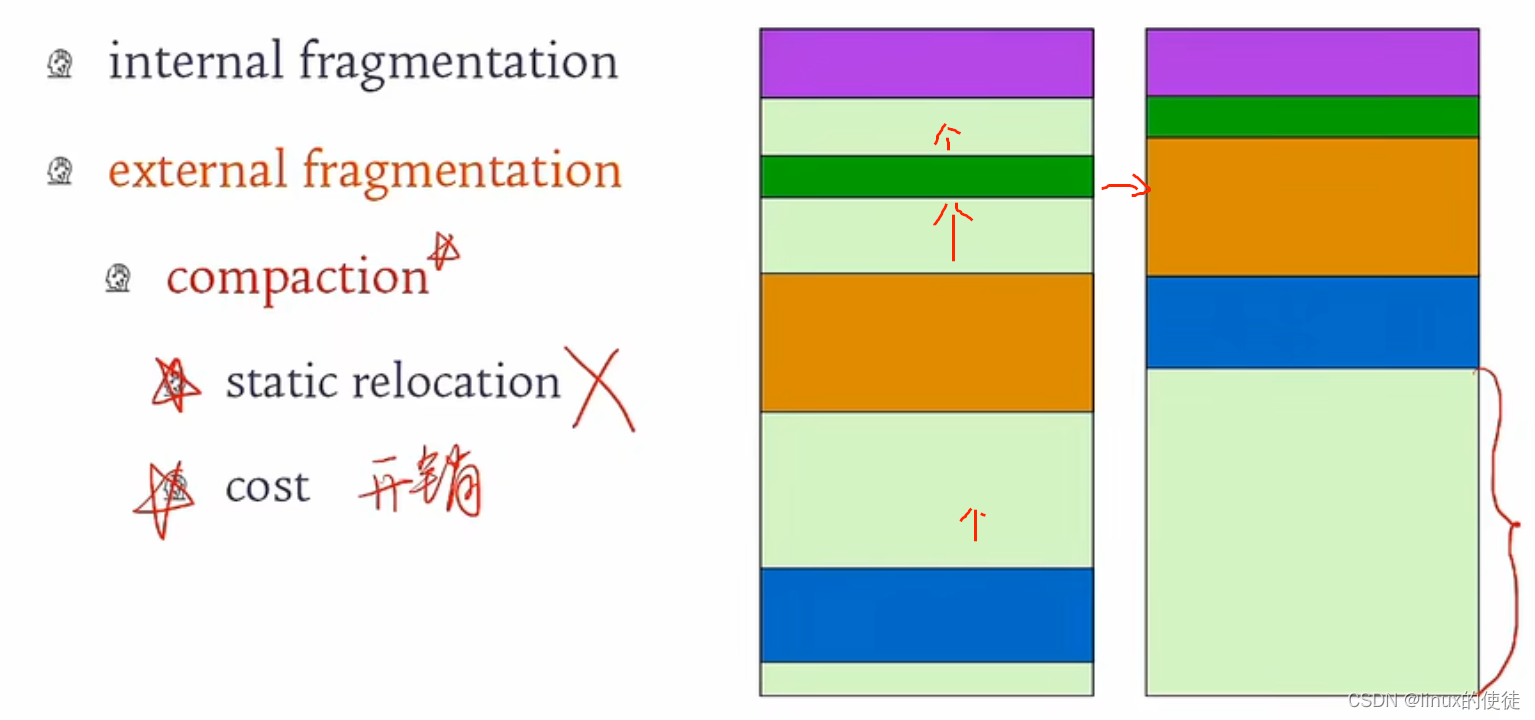
表建的是分区表,使用的是List Partitioning,而目标端的库只是建了表,并没有建分区,所以进行数据同步的时候,插入数据有问题,会报分区不存在。
解决方法
有了结论后,先尝试在库里先建分区:
create table tablename_20220601 partition of tablename for values in ('2022-06-01');
然后再进行同步,就能成功了。
不过总不能每次做同步前都先建分区,这样操作起来也烦得很,于是就去看了下datax的文档,找到了postgresqlwriter插件中的一个参数preSql:

那么只需要把建分区的语句写入preSql就行了:
"writer":{
"name":"postgresqlwriter",
"parameter":{
"username":"xx",
"password":"xx",
"column":[
"id",
"name"
],
"preSql":[
"create table tablename_20220601 partition of tablename for values in ('2022-06-01');"
],
"connection":[
{
"jdbcUrl":"jdbc:postgresql://127.0.0.1:3002/datax",
"table":[
"test"
]
}
]
}
}
结语
Datax在做多数据源同步的时候,看起来依旧是目前最好用的方法,部署简单,也不对什么引擎强依赖,在做这些历史数据的同步时,属于是点击即用了。