一、养成内存管理好习惯
1.1 养成动态对象创建、调用及释放好习惯
开发者手动接管内存分配时,必须处理这两个任务。分配原始内存时,必须在该内存中构造对象;在释放该内存之前,必须保证适当地撤销这些对象。如果你的项目是c++项目,就采用new和delelte操作符来管理动态对象,就尽量不要掺杂malloc和free函数行为;如果是c项目,就不要习惯性地又掺杂new和delelte操作符。
C++ 中,使用 new表达式的时候,分配内存,并在该内存中构造一个对象:使用 delete 表达式的时候,调用析构函数撤销对象,并将对象所用内存返还给系统。
在动态创建对象时,尽可能明确指定其数据类型,并及时初始化,采用new 表达式返回指向新创建对象的指针,明确指针指向内容大小,通过该指针即可来访问此对象。
int iv[2] = {1,2};
//int *p1i = NULL; p1i = iv; //不建议分开
int *p1i = iv; //建议一步到位
//int *p2i = NULL; p2i = new int(2); //不建议分开
int *p2i = new int(2); //建议一步到位
//char* pc = NULL; pc =(char*)malloc(2);//不建议分开
char* pc = (char*)malloc(2); //建议一步到位对未构造的内存中的对象进行赋值而不是初始化,其行为是未定义的。对许多类而言,这样做引起运行时崩溃。赋值涉及删除现存对象,如果没有现存对象,赋值操作符中的动作就会有灾难性效果。
在使用动态对象前,养成习惯性判断对象是否合法的习惯,毕竟内存分配失败、对象已经本删除、对象没初始化都是会发生的事,判断语句表达式最好是null在前:
void func(int *pi)
{
assert(NULL!=pi); //函数的入口校,使用前先判断
//do something
std::cout << "*pi = " << *pi <<"\n";
int *pi_new = new int(100);
if(NULL==pi_new) return; //非参数的地方使用
//do something
}
int main(int argc, char* argv[])
{
int iv[2] = {1,2};
//int *p1i = NULL; p1i = iv; //不建议分开
int *p1i = iv; //建议一步到位
if(NULL!=p1i) //使用前先判断
std::cout << "*p1i = " << *p1i <<"\n";
if(NULL!=(p1i+1))//使用前先判断
std::cout << "*(p1i+1) = " << *(p1i+1) <<"\n";
//int *p2i = NULL; p2i = new int(2); //不建议分开
int *p2i = new int(2); //建议一步到位
if(NULL!=p2i) //使用前先判断
std::cout << "*p2i = " << *p2i <<"\n";
//char* pc = NULL; pc =(char*)malloc(2);//不建议分开
char* pc = (char*)malloc(2); //建议一步到位
if(NULL!=pc) //使用前先判断
*pc= 'a';
if(NULL!=(pc+1)) //使用前先判断
*(pc+1) = 'b';
if(NULL!=pc) //使用前先判断
std::cout << "*pc = " << *pc <<"\n";
func(p1i);
//other code
return 0;
}在释放动态对象时,习惯把指针重新指向NULL,防止野指针(悬垂指针)出现,野指针往往导致程序错误,而且很难检测出来:
int iv[2] = {1,2};
int *p1i = iv; //建议一步到位
//delete p1i; //error: p1i refers to a local val
//free(p1i); //error: p1i refers to a local val
p1i = NULL; //不再使用时,重新指向对象指针为NULL
int *p2i = new int(2);
delete p2i; p2i = NULL;//删除动态对象时,立刻重指向对象指针为NULL
char *pc = (char*)malloc(2);
free(pc); pc = NULL; //释放动态对象时,立刻重指向对象指针为NULL对于容器类指针也是如此,指向引用对象的指针不允许进行对象删除,只能管理好自己的赋值操作。
//
std::cout << "vector test\n";
std::vector<std::string> svec(10);
std::vector<std::string> *pvec1 = new std::vector<std::string>(10);
std::vector<std::string> *pv1 = &svec;
std::vector<std::string> *pv2 = pvec1;
delete pvec1;
pvec1 = NULL;
//delete pv1; //error
pv1 = NULL;
//delete pv2; //error
pv2 = NULL;另外删除null指针也是可以的,虽然这样做没什么意义:
int *ip = NULL;
delete ip; //OK
//ip = NULL;1.2 控制好内存在各分支逻辑上的回收
警惕动态对象应用时,逻辑分支绕开动态对象释放,造成内存泄漏。例如下面示例:
void func1(void)
{
try{
int *pi_new = new int(100);
if(NULL==pi_new) return; //非参数的地方使用
//1 do something,这里出现异常,将跳转到2,后面的对象释放将被绕开,造成内存泄漏
delete pi_new;
pi_new = NULL;
}catch(...)
{
//2 do something
}
};
//建议
void func2(void)
{
int *pi_new = new int(100);
if(NULL==pi_new) return; //非参数的地方使用
try{
//1 do something
}catch(...)
{
//2 do something
}
if(NULL!=pi_new)
{
delete pi_new;
pi_new = NULL;
}
};如果编译器版本支持智能指针的话,为了避免逻辑分支引起动态对象内存释放失败,建议采用智能指针替代:
void func3(void)
{
std::auto_ptr<int> pai(new int(100));//只要函数调用结束,就自动释放
try{
std::cout << "*pai = " << *pai << "\n";
//1 do something
}catch(...)
{
//2 do something
}
};但要注意智能指针的使用,把握好智能指针为处理动态分配的内存提供了安全性和便利性的尺度。
- 不要使用 auto_ptr 对象保存指向静态分配对象的指针,否则,当 auto_ptr 对象本身被撤销的时候,它将试图删除指向非动态分配对象的指针,导致未定义的行为。
- 永远不要使用两个 auto_ptrs 对象指向同一对象,导致这个错误的一种明显方式是,使用同一指针来初始化或者 reset 两个不同的 auto_ptr 对象。另一种导致这个错误的微妙方式可能是,使用一个 auto_ptr 对象的 get 函数的结果来初始化或者 reset另一个 auto_ptr 对象。
- 不要使用 auto_ptr 对象保存指向动态分配数组的指针。当auto_ptr 对象被删除的时候,它只释放一个对象—它使用普通delete 操作符,而不用数组的 delete [] 操作符。
- 不要将 auto_ptr 对象存储在容器中。容器要求所保存的类型定义复制和赋值操作符,使它们表现得类似于内置类型的操作符:在复制(或者赋值)之后,两个对象必须具有相同值,auto_ptr 类不满足这个要求。
1.3 确保为动态对象分配了合适的内存
很多时候,我们定义了指针变量,但是常忘了为指针分配内存,即使得指针没有指向一块合法的内存,尤其是在自定义结构体或类的成员变量包含指针类型时。
class AClass
{
public:
//AClass() {}; //pc既没初始化了指针,也没有分配空间,pv没初始化
//AClass() : pc(NULL){} //初始化指针,没有分配空间,pv已经分配了空间,但没有初始化
AClass() : pc(NULL) { //初始化指针
pc = new char[10]; //分配空间
memset(pv,0,sizeof(pv));//初始化
};
~AClass() {
if(NULL!=pc) //记得析构函数要手动释放动态对象
{
delete pc;
pc = NULL;
}
//pv自动释放内存
}
char *pc;
char pv[10];
};
//main函数内
AClass atest;
if(NULL!=atest.pc){
strcpy(atest.pc,"hello");
std::cout << "*(atest.pc) = " << std::string(atest.pc) <<"\n";
}另外即使给动态内存分配了内存,也要注意在应用时,内存空间是否足够。例如下面代码,为指针分配了内存10,但是应用需要13的内存,内存大小不够,导致出现越界错误,虽然由于指针指向特性及数组连续存储特性,这段代码没有报警,也能运行,但埋下了隐患。
char str_vec[] = "hello world!";
std::cout << "sizeof(str_vec) = " << sizeof(str_vec) << "\n";
if(NULL!=atest.pc){
strncpy(atest.pc,str_vec,sizeof(str_vec));//越界了,也能完成拷贝
//strcpy(atest.pc,str_vec); //strcpy
std::cout << "*(atest.pc) = " << std::string(atest.pc) <<"\n";//输出也正常,但安全隐患埋下了
}
//
if(NULL!=atest.pv){ //转换为指针操作
strncpy(atest.pv,str_vec,sizeof(str_vec));//越界了,也能完成拷贝
//strcpy(atest.pv,str_vec); //strcpy
std::cout << "*(atest.pv) = " << std::string(atest.pv) <<"\n";//输出也正常,但安全隐患埋下了
}上述代码越界了,但是由于指针指向特性,并没有告警出现,下面这段代码,是否刷新您的想象。
//
int vec[10] = {0};//内存分配成功,且已经初始化
try{
for(int i=0; i<=10; i++) //赋值了11次
{
vec[i] = i;
}
for(int i=0; i<=10; i++) //遍历了11次
{
std::cout << vec[i] << " ";
}
std::cout << "\n";
}catch(...){
std::cout << "throw!\n";
}
//out
0 1 2 3 4 5 6 7 8 9 10调整打印输出宽度,依然没有报错,那是因为编译器忽略为任何数组形参指定的长度,因此编译没有问题,但是这两个调用都是错误的,可能导致运行可能成功,可能失败,取决于系统的包容都,但数据没有了保证。再调整看看:
//
int vec[10] = {0};
try{
for(int i=0; i<=10; i++)
{
vec[i] = i;
}
for(int i=0; i<=20; i++) //调整了这里
{
std::cout << vec[i] << " ";
}
std::cout << "\n";
}catch(...){
std::cout << "throw!\n";
}
//out log
0 1 2 3 4 5 6 7 8 9 10 1869376613 1919907616 2188396 8367176 1819043176 1870078063 560229490 0 2 6422176再调整设值时的宽度
//
int vec[10] = {0};
try{
for(int i=0; i<=30; i++)//调整30
{
vec[i] = i;
}
for(int i=0; i<=20; i++)//调整20
{
std::cout << vec[i] << " ";
}
std::cout << "\n";
}catch(...){
std::cout << "throw!\n";
}哦,linux下终于给我报错了:
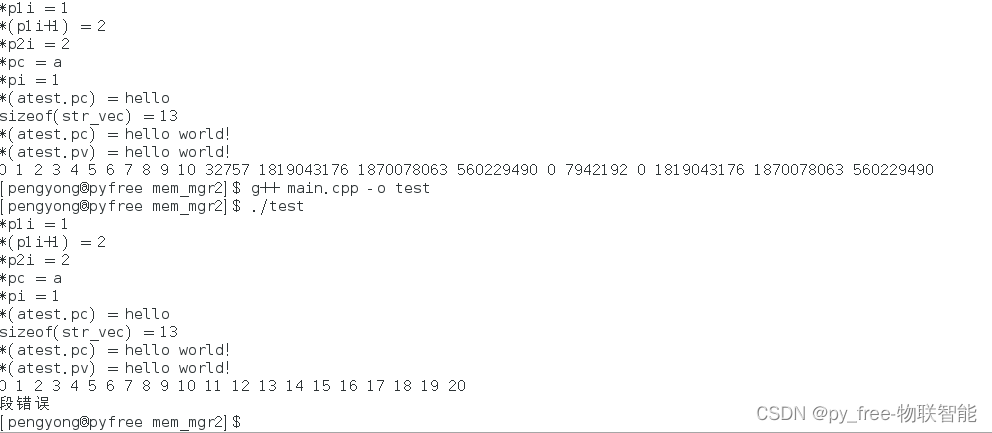
而win10下依然运行的稳当着:
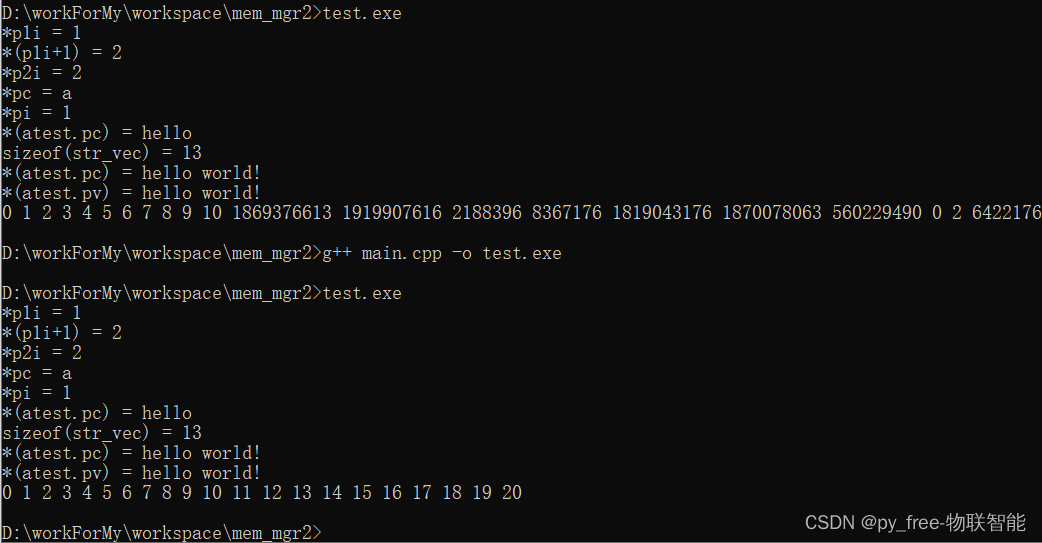
但是,不管系统或编译器如何包容,请遵循半闭半开的区间范围-[a,b)写法吧:
//
int vec[10] = {0};
try{
//for(int i=0; i<=20; i++) //越界不是事
for(int i=0; i<10; i++) //请遵循
{
vec[i] = i;
}
//for(int i=0; i<=20; i++) //越界不是事
for(int i=0; i<10; i++)
{
std::cout << vec[i] << " ";
}
std::cout << "\n";
}catch(...){
std::cout << "throw!\n";
}1.4 为动态对象做合适的初始化
通常,除了对其赋值之外,对未初始化的对象所关联的值的任何使用都是没有定义的。对于类类型的对象,用该类的默认构造函数初始化;而内置类型的对象则无初始化。如果不提供显式初始化,动态创建的对象与在函数内定义的变量初始化方式相同。但建议创建动态对象时做值初始化。
string *ps = new string; // initialized to empty string
int *pi = new int; // pi points to an uninitialized
//建议
string *ps = new string(); // initialized to empty string
int *pi = new int(); // pi points to an int value-initialized to 0
class cls{};
cls *pc = new cls(); // pc points to a value-initialized object of type cls 显式表明通过在类型名后面使用一对内容为空的圆括号,对动态创建的对象做值初始化。内容为空的圆括号表示虽然要做初始化,但实际上并未提供特定的初值。对于提供了默认构造函数的类类型(例如 string),没有必要对其对象进行值初始化:无论程序是明确地不初始化还是要求进行值初始化,都会自动调用其默认构造函数初始化该对象。而对于内置类型或没有定义默认构造
函数的类型,采用不同初始化方式则有显著的差别:
int *pi = new int; // pi 指向int型变量,该变量未初始化
int *pi = new int(); // pi 指向int型变量,该变量初始化值为01.5 const对象动态分配
C++ 允许动态创建 const 对象:
//
const int* pci = new const int(100);
//int *p5i = pci; //error
int *p5i = (int*)(pci); //类型转换
p5i = NULL;
delete pci; //OK: deletes a const object
pci = NULL;与其他常量一样,动态创建的 const 对象必须在创建时初始化,并且一经初始化,其值就不能再修改。上述 new 表达式返回指向 int 型 const 对象的指针。与其他 const 对象的地址一样,由于 new 返回的地址上存放的是 const对象,因此该地址只能赋给指向 const 的指针。
尽管不能改变 const 对象的值,但可撤销对象本身。如同其他动态对象一样, const 动态对象也是使用删除指针来释放的.
delete pci; //OK: deletes a const object
pci = NULL;对于类类型的 const 动态对象,如果该类提供了默认的构造函数,则此对象可隐式初始化。
//
const std::string *ps_const = new const std::string;
delete ps_const;
ps_const = NULL;new 表达式没有显式初始化 ps_const所指向的对象,而是隐式地将 ps_const所指向的对象初始化为空的 string 对象。内置类型对象或未提供默认构造函数的类类型对象必须显式初始化。
1.6 dynamic_cast向下转型时内存错误
dynamic_cast 支持运行时识别指针或引用所指向的对象,但是对于从父类转向子类时,稍有不慎就引擎内存错误:
//AClass见前文定义
class BClass : public AClass
{
public:
BClass(): AClass(),pbc(NULL)
{
pbc = new char[10]; //分配10个字节空间
};
~BClass()
{
if(NULL!=pbc) //记得析构函数要手动释放动态对象
{
delete pbc;
pbc = NULL;
}
//默认调用~AClass()
}
char *pbc;
};
//main函数内
AClass *pa = new AClass();
BClass *pb = dynamic_cast<BClass*>(pa);
if(NULL!=pb->pbc){//error,本质上是pa,BClass构造函数没被调用,pbc没分配空间及初始化
strcpy(pb->pbc,"hello");
std::cout << "*(pb->pbc) = " << std::string(pb->pbc) <<"\n";
}因此强烈建议程序员避免使用强制类型转换,尤其要使用ynamic_cast和reinterpret_cast时,请三思再三思。当然还有旧式的强制类型转换也是如此。
1.7 千万不要返回局部对象的引用
前一篇博文就阐述了局部指针变量引起的内存问题,这探讨一下局部对象引用的问题:当函数执行完毕时,将释放分配给局部对象的存储空间。此时,对局部对象的引用就会指向不确定的内存。
const string& mapStr(const string& s)
{
string ret = s;
ret += ":";
return ret; // error: 返回局部对象的引用!
}这个函数会在运行时出错,因为它返回了局部对象的引用。当函数执行完毕,字符串 ret 占用的储存空间被释放,函数返回值指向了对于这个程序来说不再有效的内存空间。确保返回引用有效的方法就是,和指针指向一样,确保引用指向在此之前存在的对象,而非局部变量。
二、 内存对齐
2.1 内存对齐是编译器的效率优化要求
内存对齐通常都是编译器的职责范围,但C/C++语言的一个特点就是太灵活,太强大,它允许你干预“内存对齐”。缺省情况下,编译器默认将结构、栈中的成员数据进行内存对齐。每个特定平台上的编译器都有自己的默认“对齐系数”(也叫对齐模数)。这个对齐模数要求可以是2^n[0,N)=1,2,4,8,16,32,64...中的一个。一般的编译器默认对齐模数是8。
对齐模数是8时,一个字或双字操作数跨越了 4 字节边界,或者一个四字操作数跨越了 8 字节边界,被认为是未对齐的,从而需要两次总线周期来访问内存。一个字起始地址是奇数但却没有跨
越字边界被认为是对齐的,能够在一个总线周期中被访问。
为了提高程序的性能,数据结构(尤其是栈)应该尽可能地在自然边界上对齐。因为,为
了访问未对齐的内存,处理器需要作两次内存访问;然而,对齐的内存访问仅需要一次访问。因此,编译器会将未对齐的成员向后移,将每一个都成员对齐到自然边界上,从而也导致了整个结构的尺寸变大。尽管会牺牲一点空间(成员之间有部分内存空闲),但提高了性能。
typedef struct Struct1
{
char c1;
short s;
char c2;
int i;
}Test1;
//
Test1 t1;
std::cout << "sizeof(t1) = " << sizeof(t1) << "\n";//sizeof(t1) = 12上述结构体的内存大小并不是各成员变量内存大小之和,而是12,这是因为编译器为了内存对齐给成员变量做了后移。下面这段代码打印各个成员变量与结构体首地址的偏移量:
//
printf("c1 %p, s %p, c2 %p, i %p\n",
(unsigned long int)(void*)&t1.c1 - (unsigned long int)(void*)&t1,
(unsigned long int)(void*)&t1.s - (unsigned long int)(void*)&t1,
(unsigned long int)(void*)&t1.c2 - (unsigned long int)(void*)&t1,
(unsigned long int)(void*)&t1.i - (unsigned long int)(void*)&t1);
//out log
c1 00000000, s 00000002, c2 00000004, i 00000008前面就说到,编译器将未对齐的成员向后移,将每一个都成员对齐到自然边界上,其对齐规则为:
1)首先是数据成员变量的对齐规则,第一个数据成员放在offset为0的地方,以后每个数据成员的对齐按照#pragma pack指定的对齐模数和这个数据成员自身长度中,比较小的那个进行,每个成员相对于结构体首地址的偏移量(offset)都是成员大小的整数倍。
2)然后是结构(或联合)的整体对齐规则,在数据成员完成各自对齐之后,结构(或联合)本身也要进行对齐,对齐将按照#pragma pack指定的数值和结构(或联合)最大数据成员长度中,比较小的那个进行。
3)当#pragma pack的n值等于或超过所有数据成员变量长度的时候,这个n值的大小将不产生任何效果。
因此上面结构体,对齐模数是8,c1长度1,偏移为0;s长度2,偏移取1时,不能构成长度2的整数倍偏移,所以取偏移2;c2长度1,紧接着s取得偏移4;i长度4,不能紧接着c2取5,而是偏移8,为4的整数倍。整体对齐上,对齐模数是8,最大数据成员长度是4,按4整体对齐。他们的偏移布局如下(1为成员占位)。
t1:111111111111
------------------------------
c1:1*
s: 11
c2: 1***
i: 1111如果调整一下成员变量的次序,其对齐发生了变化,内存大小也跟着被改变:
typedef struct Struct2
{
char c1;
char c2;
short s;
int i;
}Test2;
//
Test2 t2;
std::cout << "sizeof(t2) = " << sizeof(t2) << "\n";//sizeof(t2) = 8
//
printf("c1 %p, c2 %p, s %p, i %p\n",
(unsigned long int)(void*)&t2.c1 - (unsigned long int)(void*)&t2,
(unsigned long int)(void*)&t2.c2 - (unsigned long int)(void*)&t2,
(unsigned long int)(void*)&t2.s - (unsigned long int)(void*)&t2,
(unsigned long int)(void*)&t2.i - (unsigned long int)(void*)&t2);
//out log
sizeof(t2) = 8
c1 00000000, c2 00000001, s 00000002, i 00000004新的结构体中,每个成员都自然地对齐在自然边界上,避免了编译器自动对齐。其对齐如下:
t1:11111111
------------------------------
c1:1
c2: 1
s: 11
i: 11112.2 自行设置对齐模数
程序员可以通过预编译命令#pragma pack(n),n=1,2,4,8,16来改变这一系数,其中的n就是你要指定的“对齐系数”。而使用指令#pragma pack (),编译器将取消自定义字节对齐方式。在#pragma pack (n)和#pragma pack ()之间的代码按我们指定的 n 个字节对齐。
#pragma pack(2)
typedef struct Struct3
{
char c1;
short s;
char c2;
int i;
}Test3;
Test3 t3;
std::cout << "sizeof(t3) = " << sizeof(t3) << "\n";//sizeof(t3) = 12
//
printf("c1 %p, s %p, c2 %p, i %p\n",
(unsigned long int)(void*)&t3.c1 - (unsigned long int)(void*)&t3,
(unsigned long int)(void*)&t3.s - (unsigned long int)(void*)&t3,
(unsigned long int)(void*)&t3.c2 - (unsigned long int)(void*)&t3,
(unsigned long int)(void*)&t3.i - (unsigned long int)(void*)&t3);
#pragma pack()
//out log
sizeof(t3) = 10
c1 00000000, s 00000002, c2 00000004, i 00000006上述代码指定对齐模数为2,各个数据成员可以按2的整数倍偏移piany对齐,那么6也能作为自然对齐边界,当i对齐6时,结构体长度为10。数据成员最大长度是4(int型),而对齐模数是2,所以取2做对齐,10是2的整数倍,因此结构体对齐满足,所以综合得到整个结构体的内存大小是10。
三、本文源代码
g++ main.cpp -o test
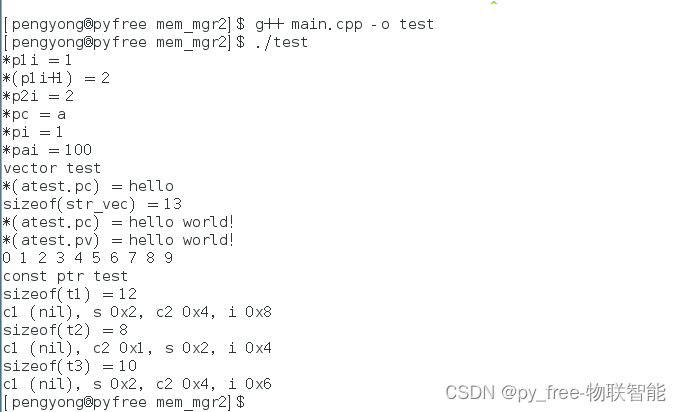
main.cpp
#include <iostream>
#include <cassert>
#include <cstring>
#include <cstdlib>
#include <vector>
#include <memory>
#include <stdio.h>
void func(int *pi)
{
assert(NULL!=pi); //函数的入口校,使用前先判断
//do something
std::cout << "*pi = " << *pi <<"\n";
int *pi_new = new int(100);
if(NULL==pi_new) return; //非参数的地方使用
//do something
}
void func1(void)
{
try{
int *pi_new = new int(100);
if(NULL==pi_new) return; //非参数的地方使用
//1 do something,这里出现异常,将跳转到2,后面的对象释放将被绕开,造成内存泄漏
delete pi_new;
pi_new = NULL;
}catch(...)
{
//2 do something
}
};
void func2(void)
{
int *pi_new = new int(100);
if(NULL==pi_new) return; //非参数的地方使用
try{
//1 do something,这里出现异常,将跳转到2,后面的对象释放将被绕开,造成内存泄漏
}catch(...)
{
//2 do something
}
if(NULL!=pi_new)
{
delete pi_new;
pi_new = NULL;
}
};
void func3(void)
{
std::auto_ptr<int> pai(new int(100));//只要函数调用结束,就自动释放
try{
std::cout << "*pai = " << *pai << "\n";
//1 do something
}catch(...)
{
//2 do something
}
};
class AClass
{
public:
//AClass() {}; //pc既没初始化了指针,也没有分配空间,pv没初始化
//AClass() : pc(NULL){}; //初始化指针,没有分配空间,pv已经分配了空间,但没有初始化
AClass() :pc(NULL) { //
pc = new char[10]; //分配10个字节空间
memset(pv,0,sizeof(pv));//初始化
};
virtual ~AClass() {
if(NULL!=pc) //记得析构函数要手动释放动态对象
{
delete pc;
pc = NULL;
}
//pv自动释放内存
}
char *pc;
char pv[10];
};
class BClass : public AClass
{
public:
BClass(): AClass(),pbc(NULL)
{
pbc = new char[10]; //分配10个字节空间
};
~BClass()
{
if(NULL!=pbc) //记得析构函数要手动释放动态对象
{
delete pbc;
pbc = NULL;
}
//默认调用~AClass()
}
char *pbc;
};
//内存对齐
typedef struct Struct1
{
char c1;
short s;
char c2;
int i;
}Test1;
typedef struct Struct2
{
char c1;
char c2;
short s;
int i;
}Test2;
int main(int argc, char* argv[])
{
int iv[2] = {1,2};
//int *p1i = NULL; p1i = iv; //不建议分开
int *p1i = iv; //建议一步到位
if(NULL!=p1i)
std::cout << "*p1i = " << *p1i <<"\n";
if(NULL!=(p1i+1))
std::cout << "*(p1i+1) = " << *(p1i+1) <<"\n";
//int *p2i = NULL; p2i = new int(2); //不建议分开
int *p2i = new int(2); //建议一步到位
if(NULL!=p2i)
std::cout << "*p2i = " << *p2i <<"\n";
//char* pc = NULL; pc =(char*)malloc(2);//不建议分开
char* pc = (char*)malloc(2); //建议一步到位
if(NULL!=pc)
*pc= 'a';
if(NULL!=(pc+1))
*(pc+1) = 'b';
if(NULL!=pc)
std::cout << "*pc = " << *pc <<"\n";
func(p1i);
func2();
func3();
//
p1i = NULL; //重新指向对象指针为NULL
delete p2i; p2i = NULL; //删除动态对象时,立刻重指向对象指针为NULL
free(pc); pc = NULL; //释放动态对象时,立刻重指向对象指针为NULL
//
std::cout << "vector test\n";
std::vector<std::string> svec(10);
std::vector<std::string> *pvec1 = new std::vector<std::string>(10);
std::vector<std::string> *pv1 = &svec;
std::vector<std::string> *pv2 = pvec1;
delete pvec1;
pvec1 = NULL;
//delete pv1; //error
pv1 = NULL;
//delete pv2; //error
pv2 = NULL;
//
AClass atest;
if(NULL!=atest.pc){
strcpy(atest.pc,"hello");
std::cout << "*(atest.pc) = " << std::string(atest.pc) <<"\n";
}
char str_vec[] = "hello world!";
std::cout << "sizeof(str_vec) = " << sizeof(str_vec) << "\n";
if(NULL!=atest.pc){
strncpy(atest.pc,str_vec,sizeof(str_vec));//越界了,也能完成拷贝
//strcpy(atest.pc,str_vec); //strcpy
std::cout << "*(atest.pc) = " << std::string(atest.pc) <<"\n";//输出也正常,但安全隐患埋下了
}
//
if(NULL!=atest.pv){
strncpy(atest.pv,str_vec,sizeof(str_vec));//越界了,也能完成拷贝
//strcpy(atest.pv,str_vec); //strcpy
std::cout << "*(atest.pv) = " << std::string(atest.pv) <<"\n";//输出也正常,但安全隐患埋下了
}
//
int vec[10] = {0};
try{
//for(int i=0; i<=20; i++) //越界不是事
for(int i=0; i<10; i++) //请遵循
{
vec[i] = i;
}
//for(int i=0; i<=20; i++) //越界不是事
for(int i=0; i<10; i++)
{
std::cout << vec[i] << " ";
}
std::cout << "\n";
}catch(...){
std::cout << "throw!\n";
}
//
std::cout << "const ptr test\n";
const int* pci = new const int(100);
//int *p5i = pci; //error
int *p5i = (int*)(pci); //类型转换
p5i = NULL;
delete pci; // ok: deletes a const object
pci = NULL;
//
const std::string *ps_const = new const std::string;
delete ps_const;
ps_const = NULL;
AClass *pa = new AClass();
BClass *pb = dynamic_cast<BClass*>(pa);
/*
if(NULL!=pb->pbc){ //error
strcpy(pb->pbc,"hello");
std::cout << "*(pb->pbc) = " << std::string(pb->pbc) <<"\n";
}
*/
Test1 t1;
std::cout << "sizeof(t1) = " << sizeof(t1) << "\n";//sizeof(t1) = 12
//
printf("c1 %p, s %p, c2 %p, i %p\n",
(unsigned long int)(void*)&t1.c1 - (unsigned long int)(void*)&t1,
(unsigned long int)(void*)&t1.s - (unsigned long int)(void*)&t1,
(unsigned long int)(void*)&t1.c2 - (unsigned long int)(void*)&t1,
(unsigned long int)(void*)&t1.i - (unsigned long int)(void*)&t1);
//
Test2 t2;
std::cout << "sizeof(t2) = " << sizeof(t2) << "\n";//sizeof(t2) = 8
//
printf("c1 %p, c2 %p, s %p, i %p\n",
(unsigned long int)(void*)&t2.c1 - (unsigned long int)(void*)&t2,
(unsigned long int)(void*)&t2.c2 - (unsigned long int)(void*)&t2,
(unsigned long int)(void*)&t2.s - (unsigned long int)(void*)&t2,
(unsigned long int)(void*)&t2.i - (unsigned long int)(void*)&t2);
#pragma pack(2)
typedef struct Struct3
{
char c1;
short s;
char c2;
int i;
}Test3;
Test3 t3;
std::cout << "sizeof(t3) = " << sizeof(t3) << "\n";//sizeof(t3) = 12
//
printf("c1 %p, s %p, c2 %p, i %p\n",
(unsigned long int)(void*)&t3.c1 - (unsigned long int)(void*)&t3,
(unsigned long int)(void*)&t3.s - (unsigned long int)(void*)&t3,
(unsigned long int)(void*)&t3.c2 - (unsigned long int)(void*)&t3,
(unsigned long int)(void*)&t3.i - (unsigned long int)(void*)&t3);
#pragma pack()
return 0;
}