1. 背景
从 innodb 的整体架构中可以知道 innodb 的内存架构中分为 buffer pool 缓存区, change pool 修改缓冲区, adaptive hash index 自适应哈希索引, 和 log buffer 日志缓冲区.
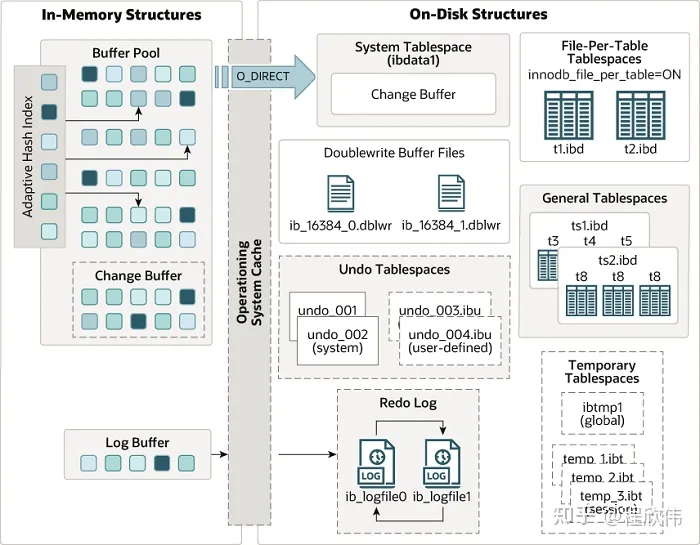
2. buffer pool
buffer pool 是用于缓冲磁盘页的数据,mysql 的80%的内存会分配给 buffer pool 来使用。
当进行数据查询的时候,如果数据页在buffer pool 中存在的话,buffer pool 则直接返回,如果不存在则会去从磁盘读取,读取后再加载到磁盘中。
当有更新操作时,更新 buffer pool 中的数据,并且记录 redo log,到了 checkpoint 点之后把内存中的脏页(内存和磁盘数据不一致的页)刷到磁盘上。
2.1. buffer pool 的数据结构
buffer pool 的内存结构中,分为3种缓存页 和 3种链表,缓存页分为 空闲页 free page,干净页 clean page,脏页 dirty page。链表分为 free list 当前没有被分配的内存页(即 free page 组成的链表),LRU list 读取到数据的内存页(即干净页和脏页组成的链表),flush list 脏页链表(即脏页组成的链表),这里需要注意在 flush list 中的页也存在与 LRU list 中。
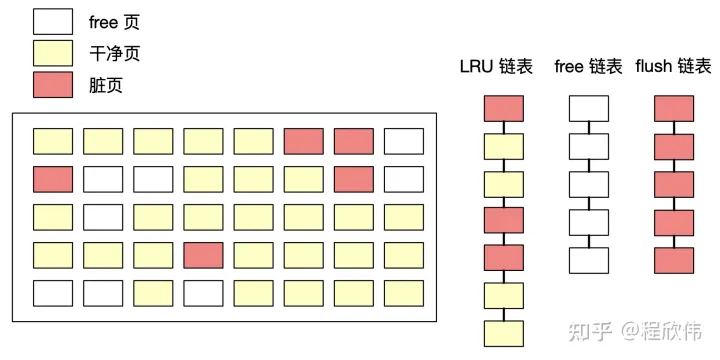
2.2. free list
free list 定义是当前没有被使用的内存页,也就是空闲的内存页,当执行查询操作时,如果页已经在 buffer pool 中了,则查询到直接返回,如果没有在 buffer pool,并且 free list 不为空,则会从磁盘中查询对应的数据,放入 free list 的某一页中,并且把这页从 free list 中移除,放入 LRU 队列中。
2.3. LRU list
LRU list 顾名思义是使用了 LRU 算法,当内存满的时候淘汰最久没有被使用的数据以释放内存空间,来缓存最近使用的数据,innoDB 在原有的 LRU 算法上做了优化,把内存区域又分为了 new 和 old 2个部分,默认配置是 37,意味着 37% 的区域是 old,63% 的区域是 new。

ref:https://dev.mysql.com/doc/refman/8.0/en/innodb-buffer-pool.html
当有新的数据从磁盘查询到内存时,会写入到 old sub list 的头部,当此数据再次被查询的时候,即在 old sublist 中命中之后,会放入 new sublist 的头部。
这样做的目的是为了避免缓存中的热点数据被污染,以提高缓存的命中率,比如有一个sql select * from table,没有设置过滤条件,那大量的数据都会被加载到缓存中,但是这种sql可能很长时间只跑一次,在未来的一段时间内都不会再次查询,如果不拆分 old 和 new,会导致缓存的污染。
2.4. flush list
flush list 中保存的数据表示当前内存中的脏页的数量,即 check point 刷盘的时候需要刷的脏页。
需要注意的是 flush list 中的数据在 LRU 中也会保存,所以当 LRU 中的缓存被淘汰,也会触发 flush list 中的脏页刷盘。
3. change buffer(double write都是mysql 专用的 O:IMU)LRU list(复制脏页进buffer pool)?
上面提到的 buffer pool 主要是用于提升 mysql 查询性能的,mysql 写的性能提升提升主要依赖 change buffer,以前 change buffer 称为 insert buffer,因为以前只做了 insert 操作的性能优化,之后版本更新之后,也能对于修改和删除做缓存处理,所以改名为 change buffer。
3.1. change buffer 解决的问题
我们假设,现在有一张表,其二级索引数据没有 load 到内存的 buffer pool 中,我们对表进行更新操作,那这个时候 innodb 会从磁盘中 load 数据出来到内存中,这是第一次随机 IO 读取,然后在内存进行 update 操作,更新的字段如果涉及二级索引的更新,需要再次读取二级索引的数据到内存中,进行更新,这是第二次随机读取的操作。那 change buffer 就是为了减少第二次随机 IO 读取,以提高更新的效率。
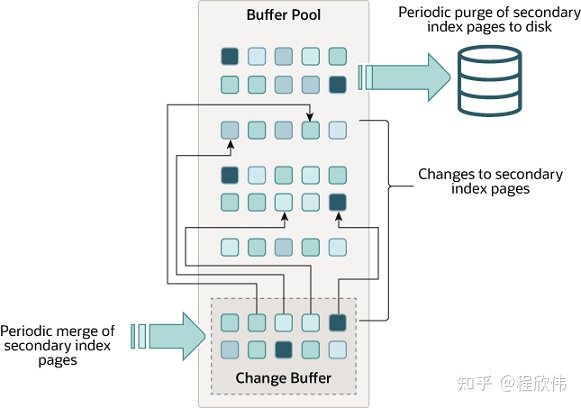
change buffer 的思路是,假设有很多次的更新,但是没有查询,二级索引的更新是可以批处理的,一直等到下一次使用二级索引查询的时候,把磁盘上的二级索引查询出来,和 change buffer 中的索引修改的增量记录做 merge 之后,在使用,那磁盘的查询操作就会从多次变成一次了。
3.2. merge 是不是等于刷盘?
merge 是指把 change buffer 中的增量变更在下一次查询的时候,合并到 buffer pool 中,从而这个 buffer pool 也变成了脏页。刷盘是指的是 buffer pool 中的脏页写到磁盘的过程,这是两个事情。
3.3. 宕机会不会丢失?
不会丢失,因为事务提交的时候,会写 redo log,redo log 中会包含 change buffer 的内容,如果出现宕机,机器重启之后会基于 redo log 做重放,可以恢复 change buffer。
3.4. 查看当前的change buffer
Ibuf: size 1, free list len 12, seg size 14, 1118 merges
merged operations:
insert 1, delete mark 1117, delete 04. log buffer
log buffer 的作用是缓存 redo log 的写入操作,考虑到一个大事务,在事务期间可能会有很多次数据库操作,不需要在事务中的每一次操作都写入 redo log,可以缓存一定量的 redo log,在合适的时间进行写盘。
合适的时间取决于 mysql 的配置,0 1 2,默认是 1,1是可以保证 ACID 的,0 和 2 都有可能在极端情况下产生数据丢失。具体 0 1 2 的配置可见:https://dev.mysql.com/doc/refman/8.0/en/innodb-parameters.html#sysvar_innodb_flush_log_at_trx_commit
5. adaptive index
adaptive index 自适应哈希索引,目的是为了提升索引的检索效率,B+ 树的检索时间复杂度是 O(logn),生产上 B+ 树的深度一般是 3-4,而 hash 索引的时间复杂度是 O(1)。
mysql 会默认开启自适应哈希索引,基于mysql 的规则,如果是符合自适应 hash 索引要求的,会在 B+ 树的基础上,建立自适应哈希索引。mysql 建立哈希索引必须是对于这个页的访问模式是一样的并且此处超过一定次数,查询条件必须是等值条件查询,比如 select * from table where a = ? 或者是联合索引 where a=? and b=?。
5.1. adaptive index 锁的问题
因为自适应索引是针对于 B+ 树的索引进行优化,涉及到索引的并发问题,所以 mysql 更新自适应索引时需要获得锁,在 5.7 之前只有一把锁,有性能问题,在之后的更新中加入了分片的概念,默认分片是8个分片,也就是8个锁,提高了并行处理的能力。
5.2. 查看当前 mysql adaptive index
可以通过 show engine innodb status 语句来查看是否开启了自适应哈希索引。
可以看到下面的内容,mysql 默认分片是8个分片,所以看到有8块自适应哈希索引。
以及看到通过自适应哈希索引的查询效率是 0.09,而不通过自适应哈希索引的,即通过 B+ 树查询的效率是 0.15.
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 1, free list len 0, seg size 2, 0 merges
merged operations:
insert 0, delete mark 0, delete 0
discarded operations:
insert 0, delete mark 0, delete 0
Hash table size 34679, node heap has 0 buffer(s)
Hash table size 34679, node heap has 0 buffer(s)
Hash table size 34679, node heap has 0 buffer(s)
Hash table size 34679, node heap has 0 buffer(s)
Hash table size 34679, node heap has 0 buffer(s)
Hash table size 34679, node heap has 0 buffer(s)
Hash table size 34679, node heap has 1 buffer(s)
Hash table size 34679, node heap has 3 buffer(s)
0.09 hash searches/s, 0.15 non-hash searches/s