在2013年Google开源了一款用于词向量计算的工具:word2vec,它本身不是一种深度学习之类的模型,是一种用于计算词嵌入的体系结构。实际上大家平时说的这个指代的就是前面介绍过的跳字(元)模型与连续词袋模型CBow:自然语言处理(NLP)之跳字(元)模型<skip-gram>与连续词袋模型<continuous bag of words>
自然语言处理(NLP)之近似训练法:负采样与层序Softmax
前面两篇文章属于理论层面,现在我们具体来实践一个数据集,来熟悉下这个自然语言处理的一些相关流程,对word2vec有一个具体的了解。一般来说本人建议需看原始论文:Efficient Estimation of Word Representations in Vector Space
另外两篇论文也比较重要,算是NLP奠基石的论文了,我叫它们为“托哥三部曲”下面两篇都来自Tomas Mikolov
Linguistic Regularities in Continuous Space Word Representations
Distributed Representations of Words and Phrases and their Compositionality
首先选择一个数据集,这里我们选择使用PTB(Penn Tree Bank)的一个常用的小型语料库,里面的内容是采样自《华尔街日报》的文章,下载地址:
https://download.csdn.net/download/weixin_41896770/87454758
在这节我们只使用了ptb.train.txt这个文本即可
整理数据集
下载好了之后,解压到data目录即可(这个目录看自己设定)。
每一行作为一个句子,句子中每个词用空格隔开,里面的生僻词使用<unk>替换,数字使用N替换了。
import collections
import d2lzh as d2l
import math
from mxnet import autograd, gluon, nd
from mxnet.gluon import data as gdata, loss as gloss, nn
import random
import sys
import time
with open("data/ptb.train.txt", "r") as f:
lines = f.readlines()
raw_dataset = [st.split() for st in lines]
# print(len(raw_dataset))#42068,表示有这么多条"句子"
# print(len(raw_dataset[0]),raw_dataset[0][:5])#24 ['aer', 'banknote', 'berlitz', 'calloway', 'centrust']
# raw_dataset = [[11, 2, 11, 3, 44], [22, 3, 44, 6, 44], [22, 44, 77, 66, 11]]
# 统计每个词出现的次数
counter = collections.Counter([tk for st in raw_dataset for tk in st])
# 这里为了计算简单,只保留出现5次以上的词
counter = dict(filter(lambda x: x[1] >= 5, counter.items()))
# 索引与词的映射
idx_to_token = [tk for tk, _ in counter.items()]
token_to_idx = {tk: idx for idx, tk in enumerate(idx_to_token)}
# print(idx_to_token[9850],token_to_idx['bikers'])
# 原始语料库每条语句中的每个词映射成所属的索引
dataset = [[token_to_idx[tk] for tk in st if tk in token_to_idx] for st in raw_dataset]
num_tokens = sum([len(st) for st in dataset])
#print(num_tokens)#887100,词汇量二次采样(subsampling)
在文本数据中一般会有一些高频词,比如"a","the","in"等,通常在一个背景窗口中,一个词跟低频词同时出现要比跟这些高频词同时出现对训练词嵌入模型更有益。所以我们对这些词进行二次采样。那对于如何丢弃这些高频词,使用下面这个概率:
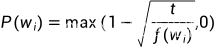
其中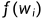 是数据集里词
是数据集里词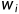 的个数跟总词汇量之比,常数t是一个超参数(实验中设为0.0001),由此可见,只有当
的个数跟总词汇量之比,常数t是一个超参数(实验中设为0.0001),由此可见,只有当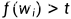 时,我们才有可能在二次采样当中丢弃,并且越高频的词被丢弃的概率越大。
时,我们才有可能在二次采样当中丢弃,并且越高频的词被丢弃的概率越大。
# 是否丢弃,高频词被随机丢弃的概率大
def discard(idx):
return random.uniform(0, 1) < 1 - math.sqrt(
1e-4 / (counter[idx_to_token[idx]] / num_tokens)
)
subsampled_dataset = [[tk for tk in st if not discard(tk)] for st in dataset]
print(sum([len(st) for st in subsampled_dataset]))# 375568,二次采样后的词汇量看得出二次采样之后有总词汇量的887100个词降到了375568(这个数是有变化的),去掉了多半的词
然后我们来对比下高低频词在二次采样前后的出现次数
def compare_counts(token):
return "%s:采样前=%d,采样后=%d" % (
token,
sum([st.count(token_to_idx[token]) for st in dataset]),
sum([st.count(token_to_idx[token]) for st in subsampled_dataset]),
)
print(compare_counts('a'))
print(compare_counts('join'))
'''
a:采样前=21196,采样后=1386
join:采样前=45,采样后=45
'''可以看到高频词"a"丢弃程度很高,低频词"join"保留了。
获取中心词与背景词
我们将与中心词距离不超过背景窗口大小的词作为它的背景词,每次在整数1和max_window_size(最大背景窗口)之间随机均匀采样一个整数作为背景窗口大小,当然也可以固定,这样的话,生成的结果就是固定的,这个看自己定义:
def get_centers_and_contexts(dataset, max_window_size):
"""获取中心词与其提取的背景词"""
centers, contexts = [], []
for st in dataset:
if len(st) < 2: # 每个句子至少要有2个词才可能组成一对"中心词-背景词"
continue
centers += st
for center_i in range(len(st)):
#window_size = random.randint(1, max_window_size)
window_size=max_window_size
indices = list(
range(
max(0, center_i - window_size),
min(len(st), center_i + 1 + window_size),
)
)
indices.remove(center_i) # 删除中心词
contexts.append([st[idx] for idx in indices])
return centers, contexts我们来简单测试下:
ds = [list(range(7)), list(range(7, 10))]
for center, context in zip(*get_centers_and_contexts(ds, 2)):
print("中心词:", center, "对应的背景词:", context)
'''
中心词: 0 对应的背景词: [1, 2]
中心词: 1 对应的背景词: [0, 2, 3]
中心词: 2 对应的背景词: [0, 1, 3, 4]
中心词: 3 对应的背景词: [1, 2, 4, 5]
中心词: 4 对应的背景词: [2, 3, 5, 6]
中心词: 5 对应的背景词: [3, 4, 6]
中心词: 6 对应的背景词: [4, 5]
中心词: 7 对应的背景词: [8, 9]
中心词: 8 对应的背景词: [7, 9]
中心词: 9 对应的背景词: [7, 8]
'''读取数据集
在读取数据集之前,我们使用负采样来进行近似训练,对于一对中心词和背景词,我们随机采样K个噪声词(实验中设为K=5),根据论文中的建议,噪声词采样概率P(w)设为w词频与总词频之比的0.75次方
def get_negatives(all_contexts, sampling_weights, K):
'''负采样'''
all_negatives, neg_candidates, i = [], [], 0
population = list(range(len(sampling_weights)))
for contexts in all_contexts:
negatives = []
while len(negatives) < len(contexts) * K:
if i == len(neg_candidates):
# 根据每个词的权重sampling_weights随机生成k个词的索引作为噪声词
# 为了高效计算,这里将k设置大点
i, neg_candidates = 0, random.choices(
population, sampling_weights, k=int(1e5)
)
neg, i = neg_candidates[i], i + 1
# 噪声词不能是背景词
if neg not in set(contexts):
negatives.append(neg)
all_negatives.append(negatives)
return all_negatives
sampling_weights = [counter[w] ** 0.75 for w in idx_to_token]
all_negatives = get_negatives(all_contexts, sampling_weights, 5)有了上面的噪声词之后,我们开始从数据集中提取所有中心词、对应的背景词和噪声词,通过随机小批量来读取它们
每个样本包括一个中心词和它对应的N个背景词与M个噪声词,由于每个样本的背景窗口大小可能不一样,这造成了背景词与噪声词之和N+M也会不一样,所以在构造小批量时,我们将每个样本的背景词与噪声词连结在一起,并添加填充项0直至连接后的长度一样。为了避免填充项对损失函数计算的影响,我们构造了掩码变量masks,就是说当背景词噪声词contexts_negatives变量中的某个元素是填充项,相同位置的masks取值为1,否则为0。为了区分正类和负类,我们还需要将contexts_negatives变量中的背景词(正类)与噪声词(负类)区分开来,依据掩码变量的构造思路,我们需要构建与contexts_negatives变量形状相同的标签变量labels,并将与背景词对应的元素设为1,其余为0
下面我们实现这个小批量读取函数batchify
def batchify(data):
"""
小批量读取函数
data:长度为批量大小的列表
return:中心词、背景词噪声词、掩码、正负类标签
"""
max_len = max(len(c) + len(n) for _, c, n in data)
centers, contexts_negatives, masks, labels = [], [], [], []
for center, context, negative in data:
cur_len = len(context) + len(negative)
centers += [center]
contexts_negatives += [context + negative + [0] * (max_len - cur_len)]
masks += [[1] * cur_len + [0] * (max_len - cur_len)]
labels += [[1] * len(context) + [0] * (max_len - len(context))]
return (
nd.array(centers).reshape(-1, 1),
nd.array(contexts_negatives),
nd.array(masks),
nd.array(labels),
)
batch_size = 512
num_workers = 0 if sys.platform.startswith("win32") else 4
dataset = gdata.ArrayDataset(all_centers, all_contexts, all_negatives)
data_iter = gdata.DataLoader(
dataset, batch_size, shuffle=True, batchify_fn=batchify, num_workers=num_workers
)
for batch in data_iter:
for name, data in zip(["中心词", "背景词噪声词", "掩码", "正负类标签"], batch):
print(name, "形状:", data.shape)
break
'''
中心词 形状: (512, 1)
背景词噪声词 形状: (512, 60)
掩码 形状: (512, 60)
正负类标签 形状: (512, 60)
'''应用跳字(元)模型
1、嵌入层
获取词嵌入的层成为嵌入层,在Gluon中可以通过创建nn.Embedding实例得到,嵌入层的权重是一个矩阵,行数是词典大小(input_dim),列数是每个词向量的维度(output_dim)。
嵌入层的输入是词的索引,输入一个词的索引i,嵌入层返回权重矩阵的第i行作为它的词向量,下面我们将形状为(2,3)的索引输入到嵌入层,由于词向量的维度是4,所以我们最终得到了形状为(2,3,4)的词向量。
embed = nn.Embedding(input_dim=20, output_dim=4)
embed.initialize()
x = nd.array([[1, 2, 3], [4, 5, 6]])
'''
[[[ 0.01438687 0.05011239 0.00628365 0.04861524]
[-0.01068833 0.01729892 0.02042518 -0.01618656]
[-0.00873779 -0.02834515 0.05484822 -0.06206018]]
[[ 0.06491279 -0.03182812 -0.01631819 -0.00312688]
[ 0.0408415 0.04370362 0.00404529 -0.0028032 ]
[ 0.00952624 -0.01501013 0.05958354 0.04705103]]]
<NDArray 2x3x4 @cpu(0)>
'''2、小批量乘法
我们可以使用小批量乘法运算batch_dot(MXNet自带的)对两个小批量中的矩阵一一做乘法,输出的形状是给定形状(n,a,b)和(n,b,c)的NDArray,乘法之后形状为(n,a,c)
X=nd.arange(8).reshape(2,1,4)
Y=nd.arange(64).reshape(2,4,8)
print(nd.batch_dot(X,Y))
'''
[[[ 112. 118. 124. 130. 136. 142. 148. 154.]]
[[1008. 1030. 1052. 1074. 1096. 1118. 1140. 1162.]]]
<NDArray 2x1x8 @cpu(0)>
'''可以看出就是分别做点积,属于批量点积。
3、跳字模型前向计算
在前向计算中,跳字模型的输入包含中心词索引center以及连结的背景词与噪声词索引contexts_and_negatives,其中center变量的形状为(N,1),N为批量大小,而contexts_and_negatives变量的形状为(N,max_len),这两个变量先通过词嵌入层分别由词索引变换为词向量,再通过小批量乘法得到形状为(N,1,max_len)的输出,输出中的每个元素是中心词向量与背景词向量或噪声词向量的内积
def skip_gram(center, contexts_and_negatives, embed_v, embed_u):
v = embed_v(center)
u = embed_u(contexts_and_negatives)
pred = nd.batch_dot(v, u.swapaxes(1, 2)) # swapaxes换轴,将第二轴与第三轴交换
return pred训练模型
前面准备工作做好了之后,我们就开始来训练模型,在此之前先定义一个损失函数:
# 二元交叉熵损失函数
loss = gloss.SigmoidBinaryCrossEntropyLoss()
# test
pred = nd.array([[1.5, 0.3, -1, 2], [1.1, -0.6, 2.2, 0.4]])
# 正负类标签
label = nd.array([[1, 0, 0, 0], [1, 1, 0, 0]]) # 1表是背景词,0表示噪声词
mask = nd.array([[1, 1, 1, 1], [1, 1, 1, 0]]) # 避免填充项参数损失函数的计算,0
print(loss(pred, label, mask) * mask.shape[1] / mask.sum(axis=1))
'''
[0.8739896 1.2099689]
<NDArray 2 @cpu(0)>
'''我们对上面结果做个验证,从零开始实现二元交叉熵损失函数计算,并根据掩码变量mask计算掩码为1的预测值和标签的损失
def sbcel(x):
return -math.log(1 / (1 + math.exp(-x)))
print("%.7f" % ((sbcel(1.5) + sbcel(-0.3) + sbcel(1) + sbcel(-2)) / 4))
print("%.7f" % ((sbcel(1.1) + sbcel(-0.6) + sbcel(-2.2)) / 3))
'''
0.8739896
1.2099689
'''接下来就是训练函数train,这个由于有填充项的存在,和以前的训练函数有点区别:
def train(net, lr, num_epochs):
ctx = d2l.try_gpu()
net.initialize(ctx=ctx, force_reinit=True)
trainer = gluon.Trainer(net.collect_params(), "adam", {"learning_rate": lr})
for epoch in range(num_epochs):
start, l_sum, n = time.time(), 0, 0
for batch in data_iter:
center, context_negative, mask, label = [
data.as_in_context(ctx) for data in batch
]
with autograd.record():
pred = skip_gram(center, context_negative, net[0], net[1])
l = (
loss(pred.reshape(label.shape), label, mask)
* mask.shape[1]
/ mask.sum(axis=1)
)
l.backward()
trainer.step(batch_size)
l_sum += l.sum().asscalar()
n += l.size
print(
"epoch:%d,loss:%.2f,time:%.2f" % (epoch + 1, l_sum / n, time.time() - start)
)
train(net, 0.005, 5)
'''
epoch:1,loss:0.46,time:23.71s
epoch:2,loss:0.40,time:24.24s
epoch:3,loss:0.37,time:23.78s
epoch:4,loss:0.35,time:23.68s
epoch:5,loss:0.34,time:23.75s
'''寻找语义相近的词
训练好嵌入模型之后,我们可以根据两个词向量的余弦相似度表示词与词之间在语义上的相似度,我们来看下:
def get_similar_tokens(query_token, k, embed):
W = embed.weight.data()
x = W[token_to_idx[query_token]]
# 添加1e-9是为了数值稳定性
cos = nd.dot(W, x) / (nd.sum(W * W, axis=1) * nd.sum(x * x) + 1e-9).sqrt()
topk = nd.topk(cos, k=k + 1, ret_typ="indices").asnumpy().astype("int32")
for i in topk[1:]:
print("余弦相似度:%.3f:%s" % (cos[i].asscalar(), (idx_to_token[i])))
get_similar_tokens("chip", 3, net[0])
'''
余弦相似度:0.670:intel
余弦相似度:0.665:microprocessor
余弦相似度:0.595:microprocessors
'''可以看到结果都跟“芯片有关”
另外在嵌入层我们可以将nn.Embedding()函数,指定一个稀疏梯度的参数:sparse_grad=True,我们发现训练速度要快了很多:
'''
epoch:1,loss:0.48,time:16.10s
epoch:2,loss:0.41,time:15.77s
epoch:3,loss:0.39,time:15.94s
epoch:4,loss:0.37,time:15.93s
epoch:5,loss:0.35,time:16.43s
'''全部代码
import collections
import d2lzh as d2l
import math
from mxnet import autograd, gluon, nd
from mxnet.gluon import data as gdata, loss as gloss, nn
import random
import sys
import time
with open("data/ptb.train.txt", "r") as f:
lines = f.readlines()
raw_dataset = [st.split() for st in lines]
# print(len(raw_dataset))#42068,表示有这么多条"句子"
# print(len(raw_dataset[0]),raw_dataset[0][:5])#24 ['aer', 'banknote', 'berlitz', 'calloway', 'centrust']
# 统计每个词出现的次数
counter = collections.Counter([tk for st in raw_dataset for tk in st])
# 这里为了计算简单,只保留出现5次以上的词
counter = dict(filter(lambda x: x[1] >= 5, counter.items()))
# 索引与词的映射
idx_to_token = [tk for tk, _ in counter.items()]
token_to_idx = {tk: idx for idx, tk in enumerate(idx_to_token)}
# print(idx_to_token[9850],token_to_idx['bikers'])
# 原始语料库每条语句中的每个词映射成所属的索引
dataset = [[token_to_idx[tk] for tk in st if tk in token_to_idx] for st in raw_dataset]
num_tokens = sum([len(st) for st in dataset])
# print(num_tokens)#887100,词汇量
# 是否丢弃,高频词被随机丢弃的概率大
def discard(idx):
return random.uniform(0, 1) < 1 - math.sqrt(
1e-4 / (counter[idx_to_token[idx]] / num_tokens)
)
subsampled_dataset = [[tk for tk in st if not discard(tk)] for st in dataset]
# print(sum([len(st) for st in subsampled_dataset])) # 375568,二次采样后的词汇量
def compare_counts(token):
return "%s:采样前=%d,采样后=%d" % (
token,
sum([st.count(token_to_idx[token]) for st in dataset]),
sum([st.count(token_to_idx[token]) for st in subsampled_dataset]),
)
# print(compare_counts('a'))
# print(compare_counts('join'))
def get_centers_and_contexts(dataset, max_window_size):
"""获取中心词与其提取的背景词"""
centers, contexts = [], []
for st in dataset:
if len(st) < 2: # 每个句子至少要有2个词才可能组成一对"中心词-背景词"
continue
centers += st
for center_i in range(len(st)):
# window_size = random.randint(1, max_window_size)
window_size = max_window_size
indices = list(
range(
max(0, center_i - window_size),
min(len(st), center_i + 1 + window_size),
)
)
indices.remove(center_i) # 删除中心词
contexts.append([st[idx] for idx in indices])
return centers, contexts
"""
ds = [list(range(7)), list(range(7, 10))]
for center, context in zip(*get_centers_and_contexts(ds, 2)):
print("中心词:", center, "对应的背景词:", context)
"""
# 试验中我们设置最大窗口大小为5
all_centers, all_contexts = get_centers_and_contexts(subsampled_dataset, 5)
def get_negatives(all_contexts, sampling_weights, K):
"""负采样"""
all_negatives, neg_candidates, i = [], [], 0
population = list(range(len(sampling_weights)))
for contexts in all_contexts:
negatives = []
while len(negatives) < len(contexts) * K:
if i == len(neg_candidates):
# 根据每个词的权重sampling_weights随机生成k个词的索引作为噪声词
# 为了高效计算,这里将k设置大点
i, neg_candidates = 0, random.choices(
population, sampling_weights, k=int(1e5)
)
neg, i = neg_candidates[i], i + 1
# 噪声词不能是背景词
if neg not in set(contexts):
negatives.append(neg)
all_negatives.append(negatives)
return all_negatives
sampling_weights = [counter[w] ** 0.75 for w in idx_to_token]
all_negatives = get_negatives(all_contexts, sampling_weights, 5)
def batchify(data):
"""
小批量读取函数
data:长度为批量大小的列表
return:中心词、背景词噪声词、掩码、正负类标签
"""
max_len = max(len(c) + len(n) for _, c, n in data)
centers, contexts_negatives, masks, labels = [], [], [], []
for center, context, negative in data:
cur_len = len(context) + len(negative)
centers += [center]
contexts_negatives += [context + negative + [0] * (max_len - cur_len)]
masks += [[1] * cur_len + [0] * (max_len - cur_len)]
labels += [[1] * len(context) + [0] * (max_len - len(context))]
return (
nd.array(centers).reshape(-1, 1),
nd.array(contexts_negatives),
nd.array(masks),
nd.array(labels),
)
batch_size = 512
num_workers = 0 if sys.platform.startswith("win32") else 4
dataset = gdata.ArrayDataset(all_centers, all_contexts, all_negatives)
data_iter = gdata.DataLoader(
dataset, batch_size, shuffle=True, batchify_fn=batchify, num_workers=num_workers
)
for batch in data_iter:
for name, data in zip(["中心词", "背景词噪声词", "掩码", "正负类标签"], batch):
print(name, "形状:", data.shape)
break
embed = nn.Embedding(input_dim=20, output_dim=4)
embed.initialize()
# x = nd.array([[1, 2, 3], [4, 5, 6]])
# print(embed(x))
X = nd.arange(8).reshape(2, 1, 4)
Y = nd.arange(64).reshape(2, 4, 8)
# print(nd.batch_dot(X,Y))
def skip_gram(center, contexts_and_negatives, embed_v, embed_u):
v = embed_v(center)
u = embed_u(contexts_and_negatives)
pred = nd.batch_dot(v, u.swapaxes(1, 2)) # swapaxes换轴,将第二轴与第三轴交换
return pred
# 二元交叉熵损失函数
loss = gloss.SigmoidBinaryCrossEntropyLoss()
# test
pred = nd.array([[1.5, 0.3, -1, 2], [1.1, -0.6, 2.2, 0.4]])
# 正负类标签
label = nd.array([[1, 0, 0, 0], [1, 1, 0, 0]]) # 1表是背景词,0表示噪声词
mask = nd.array([[1, 1, 1, 1], [1, 1, 1, 0]]) # 避免填充项参数损失函数的计算,0
# print(loss(pred, label, mask) * mask.shape[1] / mask.sum(axis=1))
def sbcel(x):
return -math.log(1 / (1 + math.exp(-x)))
# print("%.7f" % ((sbcel(1.5) + sbcel(-0.3) + sbcel(1) + sbcel(-2)) / 4))
# print("%.7f" % ((sbcel(1.1) + sbcel(-0.6) + sbcel(-2.2)) / 3))
# -----------训练模型-------------
embed_size = 100
net = nn.Sequential()
net.add(
nn.Embedding(input_dim=len(idx_to_token), output_dim=embed_size,sparse_grad=True),
nn.Embedding(input_dim=len(idx_to_token), output_dim=embed_size,sparse_grad=True),
)
def train(net, lr, num_epochs):
ctx = d2l.try_gpu()
net.initialize(ctx=ctx, force_reinit=True)
trainer = gluon.Trainer(net.collect_params(), "adam", {"learning_rate": lr})
for epoch in range(num_epochs):
start, l_sum, n = time.time(), 0, 0
for batch in data_iter:
center, context_negative, mask, label = [
data.as_in_context(ctx) for data in batch
]
with autograd.record():
pred = skip_gram(center, context_negative, net[0], net[1])
l = (
loss(pred.reshape(label.shape), label, mask)
* mask.shape[1]
/ mask.sum(axis=1)
)
l.backward()
trainer.step(batch_size)
l_sum += l.sum().asscalar()
n += l.size
print(
"epoch:%d,loss:%.2f,time:%.2fs" % (epoch + 1, l_sum / n, time.time() - start)
)
train(net, 0.005, 5)
def get_similar_tokens(query_token, k, embed):
W = embed.weight.data()
x = W[token_to_idx[query_token]]
# 添加1e-9是为了数值稳定性
cos = nd.dot(W, x) / (nd.sum(W * W, axis=1) * nd.sum(x * x) + 1e-9).sqrt()
topk = nd.topk(cos, k=k + 1, ret_typ="indices").asnumpy().astype("int32")
for i in topk[1:]:
print("余弦相似度:%.3f:%s" % (cos[i].asscalar(), (idx_to_token[i])))
get_similar_tokens("chip", 3, net[0])错误疑问
第二天来测试的时候却报错了,就是指定sparse_grad参数,前一天还是正常运行,这让人感到很意外:
Traceback (most recent call last):
File "2.py", line 179, in <module>
nn.Embedding(input_dim=len(idx_to_token), output_dim=embed_size,sparse_grad=True),
File "D:\Anaconda3\envs\myd2l\lib\site-packages\mxnet\gluon\nn\basic_layers.py", line 380, in __init__
super(Embedding, self).__init__(**kwargs)
TypeError: __init__() got an unexpected keyword argument 'sparse_grad'
然后换个虚拟环境出现下面这样的结果:
get_similar_tokens("products", 3, net[0])
'''
[22:06:25] c:\jenkins\workspace\mxnet-tag\mxnet\src\operator\../common/utils.h:450: Optimizer with lazy_update = True detected. Be aware that lazy update with row_sparse gradient is different from standard update, and may lead to different empirical results. See https://mxnet.incubator.apache.org/api/python/optimization/optimization.html for more details.
epoch:1,loss:0.48,time:18.36s
epoch:2,loss:0.41,time:18.45s
epoch:3,loss:0.39,time:18.42s
epoch:4,loss:0.37,time:18.28s
epoch:5,loss:0.35,time:18.66s
余弦相似度:0.570:manufactures
余弦相似度:0.569:chemicals
余弦相似度:0.563:tissue
'''可以正常运行,出现的那些英文的意思是优化器使用lazy_update = True会延迟更新,注意,使用row_sparse梯度的延迟更新不同于标准更新,可能会导致不同的经验结果,这个环境是用到了GPU,而报错的那个是在CPU环境测试。