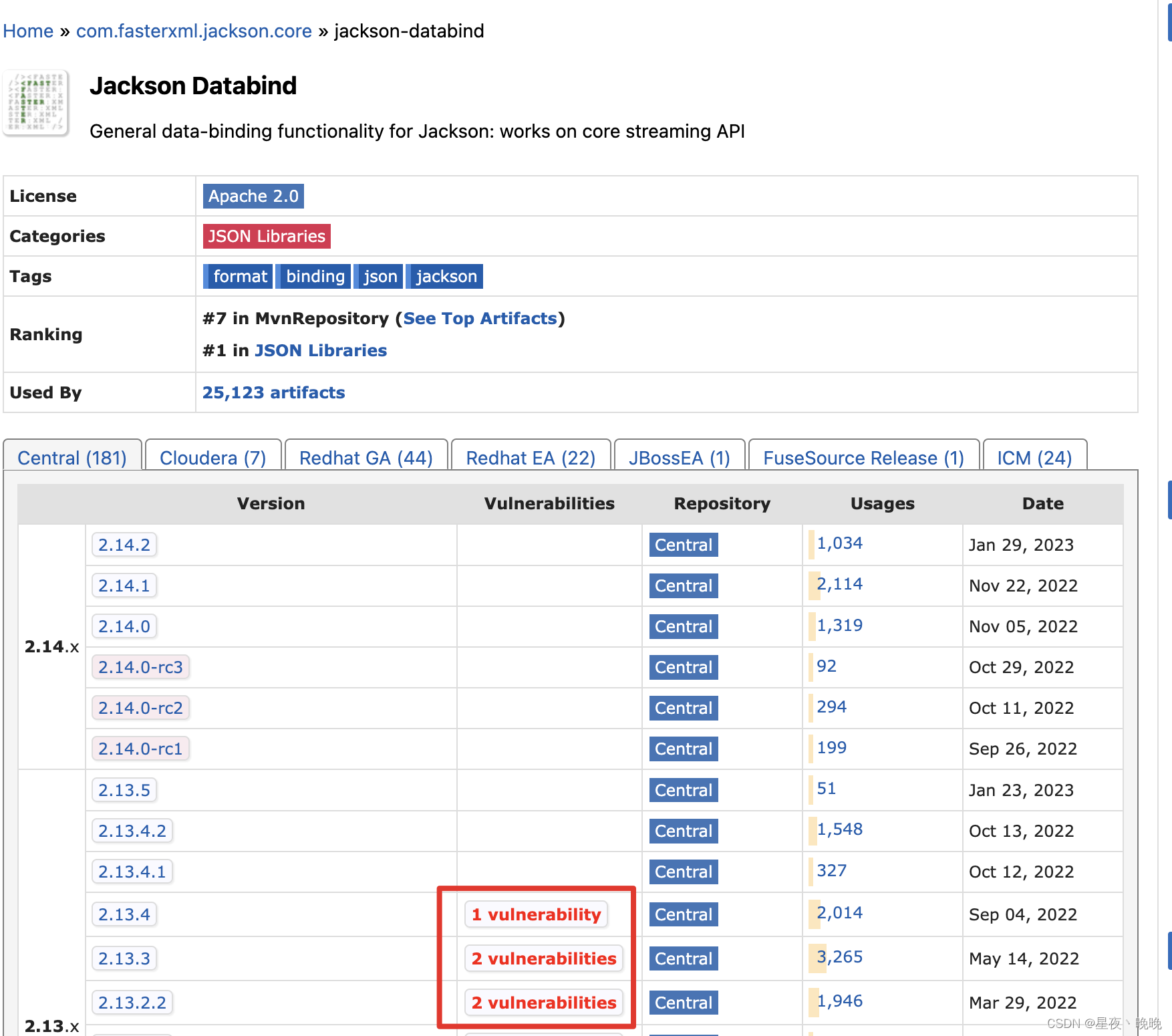
项目git地址:https://github.com/Boris-2021/Oil-price-control-forecast
使用已知的历史数据:日期、汇率、布伦特、WTI、阿曼原油价格,预测下一个调价周期中的汽油、柴油零售限价的调价价格。
一. 需求
1.1 需求说明
使用已知的历史数据:日期、汇率、布伦特、WTI、阿曼原油价格,预测下一个调价周期中的汽油、柴油零售限价的调价价格。
1.2 数据说明
原始数据中包含字段为。日期、汇率、布伦特、WTI、阿曼原油价格、汽油、柴油零售限价的调价价格、税率。其中汇率、布伦特、WTI、阿曼原油价格、为输入已知条件数据。汽油、柴油零售限价的调价价格为输出未知变量。
除日期字段其他都是数字类型可统一(float),税率列在算法开发过程没有被使用。
1.3 特别注意
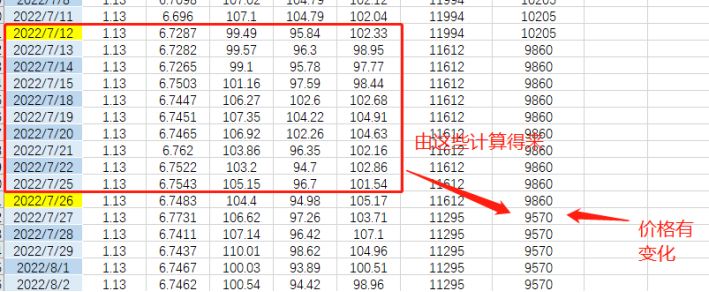
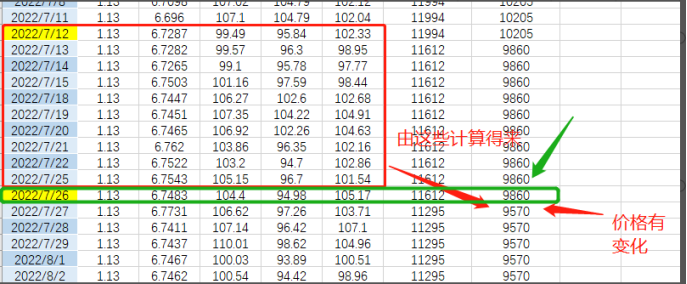
如图绿框中的数据,表示上一个十天的周期,所带来的调价一般在下一个周期的第二天出现。中间隔了一天这一天的限价还沿用上个周期的数据。
二.数据分析
数据分析适当的统计分析方法对收集来的数据初步的认识,提取有用信息和形成结论而对数据加以详细研究和概括总结。使用初步的数据认识和结论进一步规划数学建模的方法,达到为建模提供思路和提高建模效率。
2.1 可视化
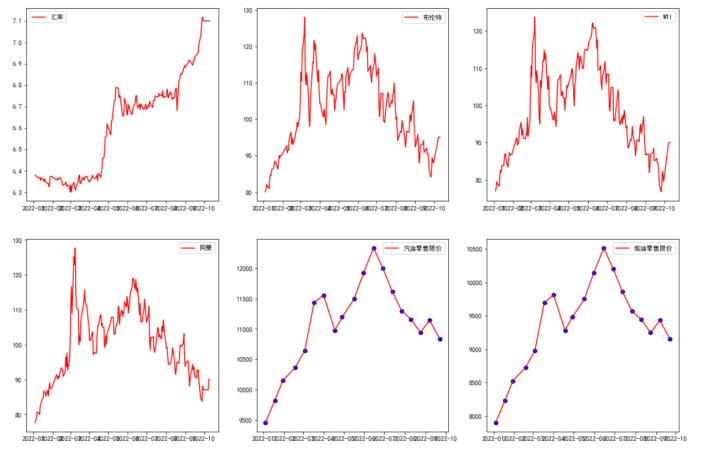
我们选取2022年1月到十月的输入数据绘制折线图。
从图中我们可以看出:
1、三种原油价格变化相似性比较高。基本保持比较一致的波动。
2、汽油柴油的价格变化相似性也比较高。基本保持比较一致的波动。
3、四个输入字段对比汽油柴油数据来看,三种原油的价格波动于目标输出有想似的趋势走向关系,有直接的因果关系。而汇率字段的数据在趋势上看没有直接的趋势因果关系。
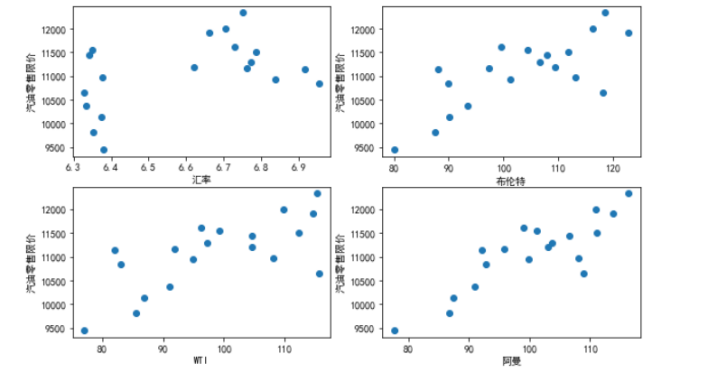
上图我们以汽油调价做Y周,四种输入字段分别做X轴绘制散点图,查看分布情况。可以看出。
1,汽油调价和三种原油呈现一定的线性分布关系,基本山随着原油价格的提高,调价也会提高。3者分布中WT离散程度最高。阿曼最低。
2,汽油调价和汇率散点图中的线性关系不明确,有一些分散,但是汇率高的时候一般汽油调价不会底。
2.2 相关性
相关性分析是指对两个或多个具备相关性的变量元素进行分析,从而衡量两个变量因素的相关密切程度。
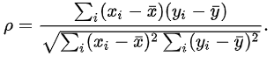
pearson相关系数衡量的是线性相关关系。若r=0,只能说x与y之间无线性相关关系,不能说无相关关系。相关系数的绝对值越大,相关性越强:相关系数越接近于1或-1,相关度越强,相关系数越接近于0,相关度越弱。
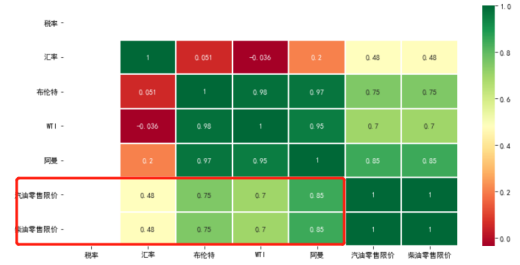
计算相关性系数,绘制热力图记录相关性数据,三原油价格和汽油调价价格相关性都大于0.7,属于强相关因素。汇率小于0.5直接相关性比较弱。
由于汇率并不直接作用于调价数据。我们尝试将汇率乘进原油价格,比较乘积数据的相关性。
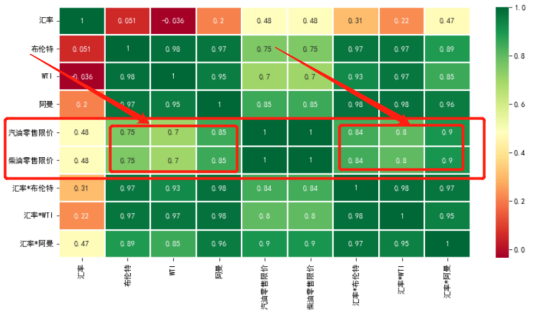
计算相关性,绘制热力图,发现汇率乘进原油价格后与零售价格调整之间的相关性系数变大。可见汇率*原油价格的数据更直接影响价格的调整。
基于以上数据认知我们进行建模的初试。
三. 算法模型初探
3.1 线性模型
3.1.1 Lr线性回归模型
(这节主要描述线性回归模型原理内容,只关注使用可忽略此章节)
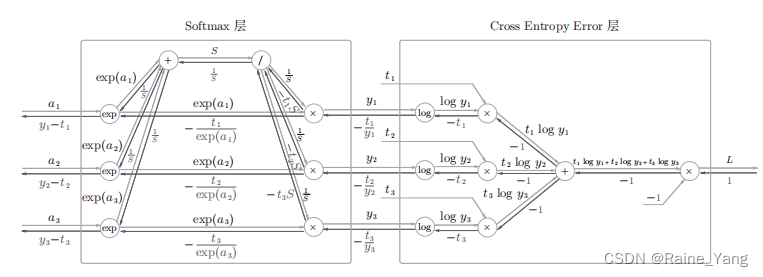
回归分析是指一种预测性的建模技术,主要是研究自变量和因变量的关系。通常使用线/曲线来拟合数据点,计算出参数使曲线到数据点的距离差异最小。
假设目标值(因变量)与特征值(自变量)之间线性相关(即满足一个多元一次方程,如:f(x)=w1x1+…+wnxn+b.)。
然后构建损失函数。
最后通过令损失函数最小来确定参数。(最关键的一步)
那么因变量中的参数是如何通过算法确定的呢:这里使用正规方程解的方式说明。
正规方程一般用在多元线性回归中,原因等你看完也就能理解为什么。所以这里不再用一元线性回归举栗子了。
同样,假设有n组数据,其中目标值(因变量)与特征值(自变量)之间的关系为:
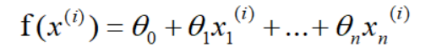
其中i表示第i组数据,这里先直接给出正规方程的公式:
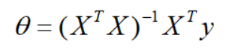
损失函数为:
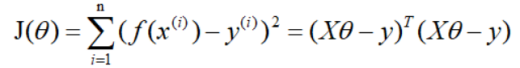
对损失函数求导并令其为0,有
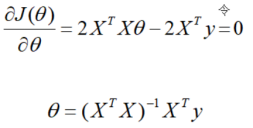
到此,就求出了所有系数θ。
3.1.2 Lr模型初试
输入:汇率+3种原油价格、
只选取调价日当天的数据(2022.1-2022.10)19条、 训练集前14条数据,验证在后5条数据。
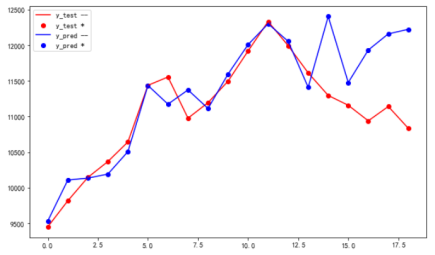
结论:1,R2指标0.41, 2,后5条数据拟合情况很差, 3,在训练数据集种的数据拟合很好平均差值100左右,验证数据平均差值大于500。
输入: 选用特征:3种原油价格+原油价格*汇率、
只选取调价日的数据19条数据、 训练集前15条数据,验证在后4条数据。
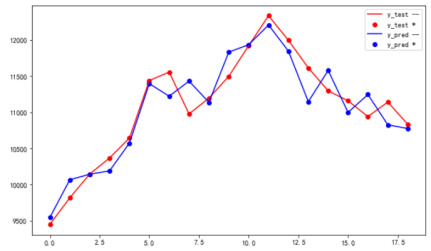
结论:1,R2指标0.88、2,后4条数据拟合情况一般、3,后四条数据预测和真实情况差距在300以内
发现模型预测的数据和真实数据还是有一定的距离,而后四条测试的数据,在验证涨跌这一块有一些问题(后四次数据展示出一次涨,三次跌)预测的数据预只测对了两次跌的情况。
3.2 决策树模型
3.2.1 决策树回归模型
(这节主要描述决策树回归模型原理内容,只关注使用可忽略此章节)
决策树是一种非常基础又常见的机器学习模型。
一棵决策树(Decision Tree)是一个树结构(可以是二叉树或非二叉树),每个非叶节点对应一个特征,该节点的每个分支代表这个特征的一个取值,而每个叶节点存放一个类别或一个回归函数。
使用决策树进行决策的过程就是从根节点开始,提取出待分类项中相应的特征,按照其值选择输出分支,依次向下,直到到达叶子节点,将叶子节点存放的类别或者回归函数的运算结果作为输出(决策)结果。
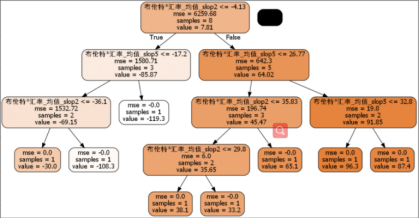
上图是后边拟合残差形成的决策树图,后边会对图进行解释说明。
简单讲,有以下几步可训练得到一个决策树:
准备若干的训练数据(假设有 m 个样本);
标明每个样本预期的类别;(本数据中为调价结果)
人为选取一些特征(即决策条件:本数据中为输入指标);
为每个训练样本对应所有需要的特征生成相应值——数值化特征;
将通过上面的1-4步获得的训练数据输入给训练算法,训练算法通过一定的原则,决定各个特征的重要性程度,然后按照决策重要性从高到底,生成决策树。
这里边要理解一个决定特征重要程度是如何计算的:决策树的构造过程是一个迭代的过程。每次迭代中,采用不同特征作为分裂点,来将样本数据划分成不同的类别。被用作分裂点的特征叫做分裂特征。选择分裂特征的目标,是让各个分裂子集尽可能地“纯”,即尽量让一个分裂子集中的样本都属于同一类别。如何使得各个分裂子集“纯”,算法也有多种,这里以ID3为例。
该算法的核心是:以信息增益为度量,选择分裂后信息增益最大的特征进行分裂。
首先我们要了解一个概念——信息熵。
假设一个随机变量 x 有 n 种取值,分别为 {x1,x1,…,xn},每一种取值取到的概率分别是 {p1,p2,…,pn},那么 x 的信息熵定义为:
Entropy(x)=−∑ni=1pilog2(pi)
熵表示的是信息的混乱程度,信息越混乱,熵值越大。
设 S 为全部样本的集合,全部的样本一共分为 n 个类,则:
Entropy(S)=−∑ni=1pilog2(pi)
其中,pi 为属于第 i 个类别的样本,在总样本中出现的概率。
接下来要了解的概念是信息增益,信息增益的公式为(下式表达的是样本集合 S 基于特征 T 进行分裂后所获取的信息增益):
InformationGain(T)=Entropy(S)−∑value(T)|Sv||S|Entropy(Sv)
其中:
S 为全部样本集合,|S|为S 的样本数;T为样本的一个特征;value(T) 是特征 T 所有取值的集合;v 是 T 的一个特征值;Sv 是 S 中特征 T 的值为 v 的样本的集合,|Sv|为Sv 的样本数。
(这节主要描述决策树回归模型原理内容,只关注使用可忽略此章节)
3.2.2 决策树模型初试
输入: 选用特征:3种原油价格+原油价格*汇率+前一次价格、
只选取调价日的数据19条数据、 训练集前15条数据,验证在后4条数据。
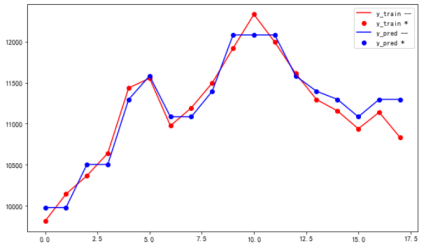
结论:1,R2指标0.96、2,后4条数据拟合情况一般、3,后四条数据预测和真实情况差距在300以内、4、在验证涨跌趋势这一块有提升
决策树模型的稳定性比较差,经过多次测试,有很多次结果都不是一致的。所以还是以线性回归模型做基准模型。
3.2.3 XGB集成学习模型
这个模型的尝试效果不佳暂不展开说明了。
四. 特征分析
在上边的算法模型初探中,我们的输入都是调价日当天的,也就是每个十天的周期只选择了一天的数据,2022.1-2022.10有19个十天周期挑选出了19条数据。这样没有使用上10天的综合数据。
特征分析目的在于对输入做处理,通过分析不同的输入特征方式,来改善模型的效果。
4.1 不同特征组合对比
4.1.1 每组中十天的数据做输入
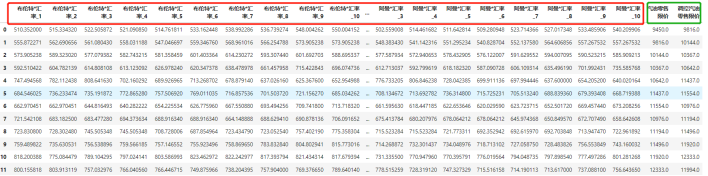
如图所示:将每个十天周期中的第1天到10天的原油汇率乘积与本周期的调价结果放同一行。
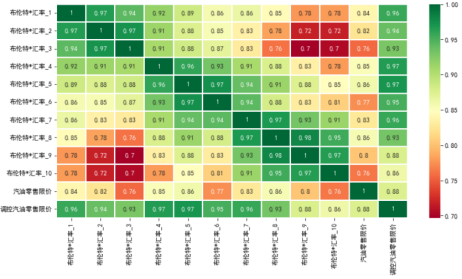
通过相关性热力图(布伦特十天数据为例)可以看出,调价和前8天数据的相关性都比调价日的高,所以使用更多强相关的输入,会提升线型模型的效果。
使用10天的数据做输入,调价做输出训练模型。
输入: 所有特征前十天数据
只选取调价日的数据19条数据、 训练集前14条数据,验证在后4条数据。
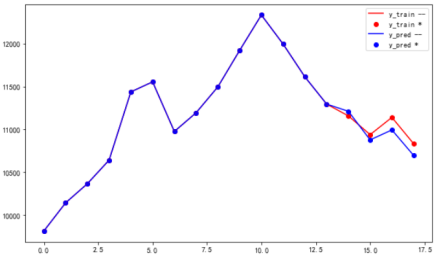
y_test-y_pred: [0.0, -0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, -54.0, 61.2, 145.9, 136.7]
y_test-y_pred表示图中真实值和预测值的差值。
结论:0、做输入表现次好,1,后4条数据拟合情况还可以、3,后四条数据预测和真实情况差距在150以内。
除了所有特征前十天数据做输入,还进行了只使用布伦特x汇率前十天数据、只使用WTIx汇率前十天数据、只使用阿曼x汇率前十天数据、所有特征1\4\5\6\7天数据做输入的多种组合的尝试。总体效果比上一阶段有所提升,他们之间区别不大,不展开说明了。
4.1.2 每组中十天综合指标做输入
尝试输入新的指标特征提升模型效果:加入每组中的输入的均值、斜率、中位数、等特征。
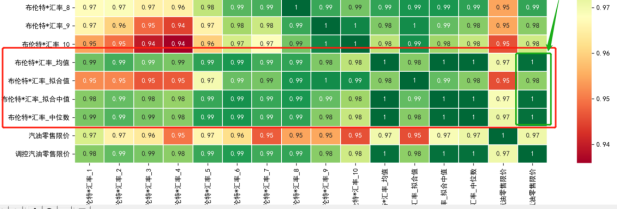
绘制相关性热力图,我们发现,汽油调价与均值,中位值,拟合中值,相关性系数很高,基本接近于1。加入这个特征做输入训练模型,尝试效果。
使用10天的数据做均值,调价做输出训练模型。
输入: 所有特征前十天数据的均值
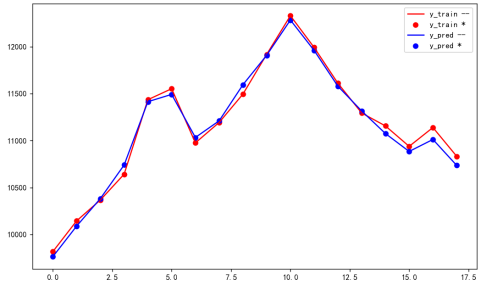
y_test-y_pred: [54.1, 56.2, -15.3, -98.3, 21.6, 60.4, -58.0, -17.5, -100.2, 9.5, 45.9, 31.9, 31.5, -21.9, 81.1, 54.3, 127.4, 97.0]
y_test-y_pred表示图中真实值和预测值的差值。
结论:0、做输入表现次好,1,后4条数据拟合情况还可以、3,后四条数据预测和真实情况差距在130以内。
除了所有特征前十天数据的均值做输入,还进行了只使用十天数据的中位数、拟合中值、斜率、十天数据加以上指标的多种组合的尝试。总体上还是单使用均值做输入,真实与预测的差值最小。
五.算法模型的优化
5.1 滑动窗口回测分析
回测是指基于历史已经发生过的真实油价数据,在历史上某一个时间点开始,按照上文的预测方式,得出历史中的预测结果,与真实结果比较。进一步分析模型在历史数据中表现的好坏。
以上步骤我们都只使用了2022.1-2022.10的19个调价周期的数据,现在我们准备将数据增加2021.1到2022.11的43个调价周期的数据。在这些数据上使用以上的方式,进行滑动窗口的模型回测。
1, 通过回测,确定最好作为训练集数据的时间段。(通过之前的工作发现将所有的数据作为训练集并不好。40组并不比20组数据好。一组10天)
2,通过回测,确定最好的输入特征(通过之前的工作,确定好几个强相关性指标,有很多种排列组合,通过不同特征模型的回测数据确定那种效果是最好的)
3,通过回测,确定最好的模型。(之前实验过线性模型,决策树模型,XGB模型)
y_pre_list-y_ture: [38.1, 21.7, -16.8, -18.0, -14.6, -39.4, -13.6, -53.6, 33.2, -10.3, -27.3, 1.9, -4.4, 1.1, 18.4, 65.1, 96.3, 87.4, -87.1, -53.3, 8.7, 50.9, 86.2, -23.9, -63.5, -48.9, 17.2, -30.0, 1.4, -108.3, -30.8, -119.3, -57.6]
y_pre_list-y_ture表示预测值和真实值的差。
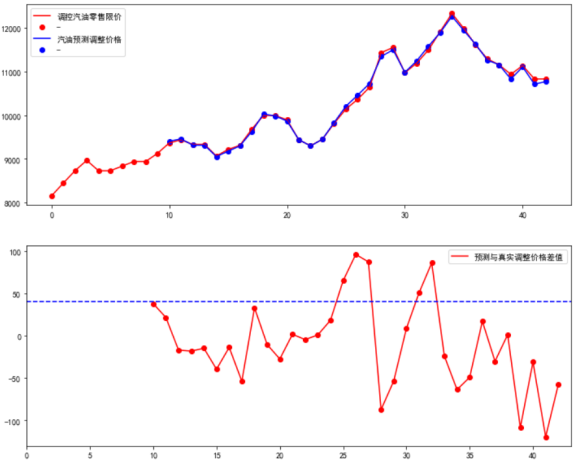
1,实验了分别使用5-20组时间段数据训练模型预测,结论使用10组训练模型去预测结果较好。
2,我使用了【原油X汇率均值,原油X汇率拟合中值,原油X汇率中位数,本次限价价格】排列组合,回测效果,结果是使用【原油X汇率均值】拟合的模型,效果好
3,再确定输入特征的基础上,模型试用了,决策树,XGB,线性回归,再模型的稳定性上看,结果是线性模型效果好
5.2 线性模型的不足
经过各种输入特征,各种模型,及训练集长度的回测测试后,我们已经找到了一种做好的情况的组合。但是任然在一些情况下,预测与真实差值会比较大。
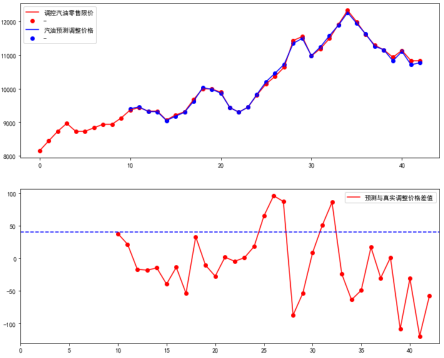
在回测数据中,真实值与预测的平均误差在48左右,而真实值和预测值误差较大的地方,一般出现在调整价格长期增长的时候,或者长期下降的时候。
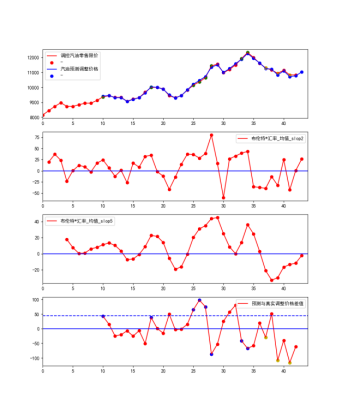
如图示,第二个第三个子图,分别表示历史布伦特汇率_均值最近2次周期中的价格斜率,历史布伦特汇率_均值最近5次周期中价格斜率,斜率表示价格增长或者降低的程度。第四子图表示真实值和预测值误差折线图。
可以到误差极大极小值,一般都在短期斜率长期斜率都在高位或者低位的时候。
1,预测值是基于历史前十组数据形成lr模型生成的结果,它反应了历史近十组原油价格与调价结果的函数关系。
2,了解1中的含义,再看长期短期原油都在增长的是时期中,前期阶段真实值小于预测值,也就是真实值要低于原油价格反应出的调整价格(基于历史十次周期)。
3,再此基础上将此现象示为调价的“长尾效应”,即在外围原油成本价格上涨的时候,国内价格调整并没有那么多,也就是小于预测值。外围成本下降时相反。
4,长尾效果并不会持续出力很长时间,一方面新的数据参与进lr模型的训练,使函数在预测增长偏于保守,另一方面真实调整价格的压增长的行为可能也就进行几次,之后会释放。这也就容易在长期增长的曲线中出现,误差这次极大,下次极小的震荡现象。
5.3 决策树模型
基于原油平均值拟合的lr模型已经基本拟合了,平均误差48,调整价格平均在10000的话,误差占调整价格的大概不到0.5%。所以我们可以使用lr模型来做基准模型,给我们预测值一个比较不错的数值范围。
而在上边的线性模型的不足中了解到,有些较大的误差的出现,可能时源自于价格调整中的长尾效应。想要进一步提高模型的准确性,我们可以从这些较大误差入手,我们将回测数据中的误差看作残差,我们在训练一个拟合残差的模型,来提升基准模型的准确度。
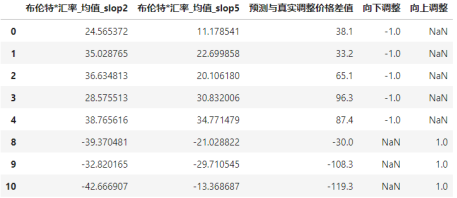
上表将长期短期同增长或下降的数据提出,对比看起残差值。
布伦特汇率_均值_slop2 为布伦特汇率_均值在两次调价中表现的斜率、布伦特汇率_均值_slop5 为布伦特汇率_均值在五次调价中表现出来的斜率。
预测与真实调整价格差值 为正,通常是在一定时间上升期中,基模型通常遵循原油价格预测调控价格的值,高于真实发改委给出的调控价格,原因在长尾效应在上升期有意拉低上升的程度。
预测与真实调整价格差值 为负,通常是在一定时间下降期中,基模型通常遵循原油价格预测调控价格的值,低于真实发改委给出的调控价格,原因在于长尾效应在下降期有意延缓下降的程度。
认为残差的大小与长期短期增长斜率有关系,所以使用这个数据,训练决策树模型。
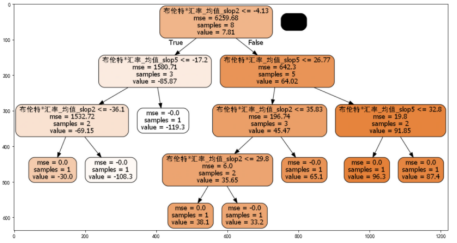
上图是决策树可视化图。决策树算法可以通过历史回测的误差数据的增多,增加决策树的条件分支。增加模型的规模。
5.4 最终模型的确立
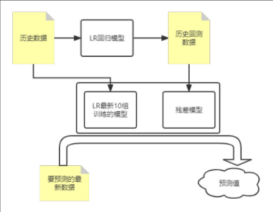
最终采用了lr模型+决策树(拟合残差)模型的组合方式,进行算法预测。
算法的计算过程:
1,使用历史数据,回测基模型(lr模型)产生历史回测数据,记录基模型的误差。
2,使历史回测数据中记录的误差数据训练残差模型(决策树模型),用来弥补基模型的误差。
3,在预测的使用阶段,预测数据由 :基模型(lr模型)预测数值 - 残差模型(决策树)预测数值 = 最终预测值
六.评估
6.1 回测评估
最终的计算预测的方式确立为lr模型+决策树(拟合残差)模型的组合方式,我们在使用这个算法模型在历史数据终回测,查看效果。
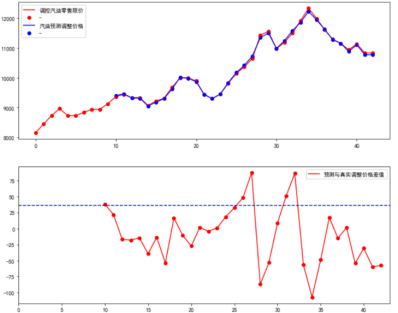
经过基模型+残差模块修正 的回测,误差的均值由48多下降到30。
经过回测,连续上升期或下降期,前中期残差模块可以起到修正误差作用。
应该注意的是,由于长尾效果并不会持续出力很长时间,超过几次逆势调整之后的修正比较容易失效。所以出现了一些负向的误差负向增大的现象。
6.2 最新两次调价结果
使用这种预测方法在近两次真实调价中的表现结果:
11月16号:
预测值:
汽油:11159 价格下降
柴油:9445 价格下降
真实值:
汽油:11194 价格下降
柴油:9475 价格下降
误差:
汽油:-35
柴油:-30
七.总结
目前已经在运用的预测调价油价的方法,是通过单一的时间维度的价格调整数据,其预测的本质基本都是围绕单一维度数:调价价格。这一时序数据本身的周期性,趋势性等特性来进行预测。
这种传统方式是有很大局限性的。首先决定调整价格结果的因素有很多,仅仅使用单一维度的时序数据,数据利用率很低,并且训练算法模型很难保证准确率。其次时序算法是将过去的趋势延伸到来来,因此这种方法无法预测时间序列的转折点。在这种情况下,预测人员往往需要依靠自己的知识和经验对预测结果进行修正。
实时上国内油价调整价格受 国际原油价格,汇率等指标强影响,因此通过收集处理布伦特,WTI、阿曼、汇率等数据。将这些数据纳入预测调价结果的模型,可以大大提升可用数据利用率,更重要的是也提高预测准确率。在误差的基础上训练自触发的修正学习模型,可以对结果进行自动的进一步修正,大大提升了算法的健壮性,减少了人工的参与更加智能。
经过回测,连续上升期或下降期,残差模块可以起到修正误差作用。相对于传统人工对预测结果进行修正的方法,本技术方案自动化修正大大提升了模型的应用性。