目录
排序算法:
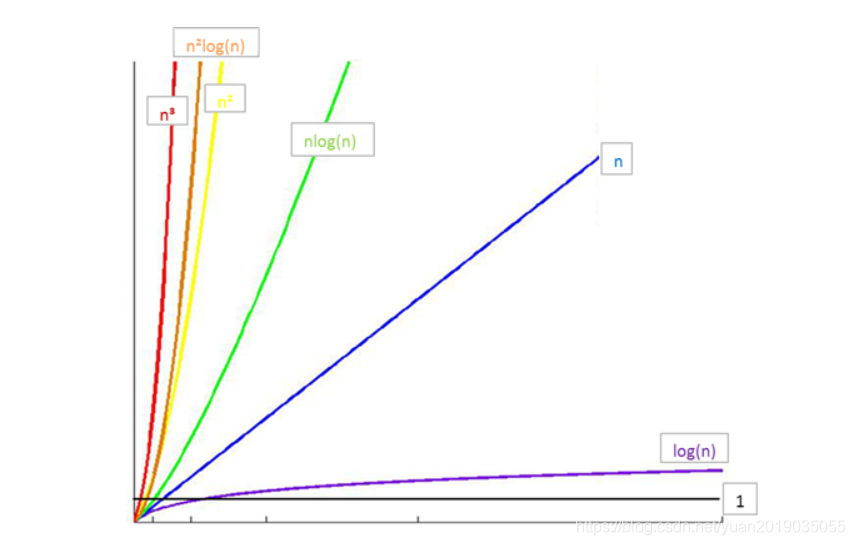
时间复杂度:
排序算法和冒泡排序之间的过渡:
冒泡排序
冒泡排序和快速排序之间的过渡:
快速排序
排序算法:

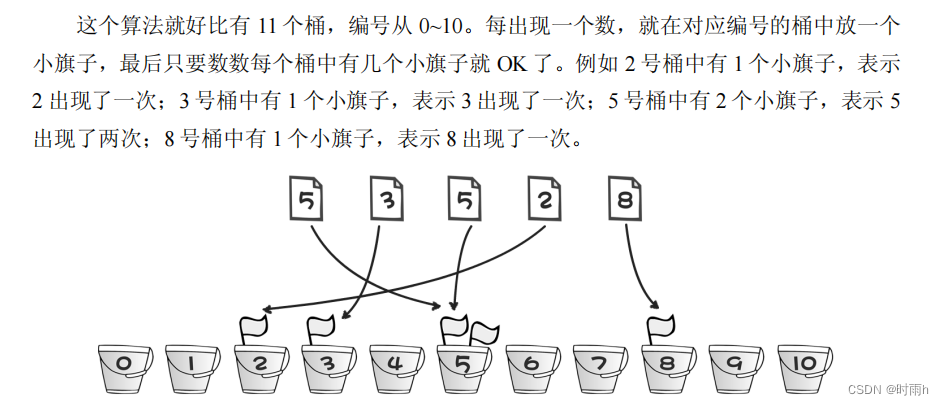
首先出场的是我们的主人公小哼,上面这个可爱的娃就是啦。期末考试完了老师要将同
学们的分数按照从高到低排序。小哼的班上只有 5
个同学,这
5
个同学分别考了
5
分、
3 分、
5 分、
2
分和
8
分,哎考得真是惨不忍睹(满分是
10 分)。接下来将分数进行从大到小排序,
排序后是 8 5 5 3 2
。你有没有什么好方法编写一段程序,让计算机随机读入
5 个数然后将这
5 个数从大到小输出?
#include <stdio.h>
int main()
{
int a[11],i,j,t;
for(i=0;i<=10;i++)
a[i]=0; //初始化为0
for(i=1;i<=5;i++) //循环读入5个数
{
scanf("%d",&t); //把每一个数读到变量t中
a[t]++; //进行计数
}
for(i=0;i<=10;i++) //依次判断a[0]~a[10]
for(j=1;j<=a[i];j++) //出现了几次就打印几次
printf("%d ",i);
getchar();getchar();
//这里的getchar();用来暂停程序,以便查看程序输出的内容
//也可以用system("pause");等来代替
return 0;
}
#include <stdio.h>
int main()
{
int book[1001],i,j,t,n;
for(i=0;i<=1000;i++)
book[i]=0;
scanf("%d",&n);//输入一个数n,表示接下来有n个数
for(i=1;i<=n;i++)//循环读入n个数,并进行桶排序
{
scanf("%d",&t); //把每一个数读到变量t中
book[t]++; //进行计数,对编号为t的桶放一个小旗子
}
for(i=1000;i>=0;i--) //依次判断编号1000~0的桶
for(j=1;j<=book[i];j++) //出现了几次就将桶的编号打印几次
printf("%d ",i);
getchar();getchar();
return 0;
}时间复杂度:
代码中第
6
行的循环一共循环了
m
次(
m
为桶的个数),
第
9
行的代码循环了
n
次(
n
为待排序数的个数),第
14
行和第
15
行一共循环了
m
+
n
次。
所以整个排序算法一共执行了
m
+
n
+
m
+
n
次。我们用大写字母
O
来表示时间复杂度,因此该
算法的时间复杂度是
O
(
m
+
n
+
m
+
n
)
即
O
(2*(
m
+
n
))
。我们在说时间复杂度的时候可以忽略较小
的常数,最终桶排序的时间复杂度为
O
(
m
+
n
)
。还有一点,在表示时间复杂度的时候,
n
和
m
通常用大写字母即
O
(
M
+
N
)
排序算法和冒泡排序之间的过渡:
现在分别有
5
个人的名字和分数:
huhu 5
分、
haha 3
分、
xixi 5
分、
hengheng 2
分和
gaoshou
8
分。请按照分数从高到低,输出他们的名字。即应该输出
gaoshou
、
huhu
、
xixi
、
haha
、
hengheng
。 发现问题了没有?如果使用我们刚才简化版的桶排序算法仅仅是把分数进行了排序。最终输 出的也仅仅是分数,但没有对人本身进行排序。也就是说,我们现在并不知道排序后的分数 原本对应着哪一个人!这该怎么办呢?不要着急,请看下节——冒泡排序。
简化版的桶排序不仅仅有所遗留的问题,更要命的是:它非常浪费空间!例如需 要排序数的范围是 0~2100000000
之间,那你则需要申请
2100000001
个变量,也就是说要写 成 int a[2100000001]
。因为我们需要用
2100000001
个“桶”来存储
0~2100000000
之间每一个数出现的次数。即便只给你 5
个数进行排序(例如这
5
个数是
1
、
1912345678
、
2100000000,
18000000 和
912345678
),你也仍然需要
2100000001
个“桶”,这真是太浪费空间了!还有,如果现在需要排序的不再是整数而是一些小数,比如将 5.56789
、
2.12
、
1.1
、
3.123
、
4.1234 这五个数进行从小到大排序又该怎么办呢?
冒泡排序
冒泡排序的基本思想是:每次比较两个相邻的元素,如果它们的顺序错误就把它们交换
过来

#include <stdio.h>
int main()
{
int a[100],i,j,t,n;
scanf("%d",&n); //输入一个数n,表示接下来有n个数
for(i=1;i<=n;i++) //循环读入n个数到数组a中
scanf("%d",&a[i]);
//混混藏书阁:http://book-life.blog.163.com
//啊哈!算法
//冒泡排序的核心部分
for(i=1;i<=n-1;i++) //n个数排序,只用进行n-1趟
{
for(j=1;j<=n-i;j++) //从第1位开始比较直到最后一个尚未归位的数,想一想为什
么到n-i就可以了。
{
if(a[j]<a[j+1]) //比较大小并交换
{ t=a[j]; a[j]=a[j+1]; a[j+1]=t; }
}
}
for(i=1;i<=n;i++) //输出结果
printf("%d ",a[i]);
getchar();getchar();
return 0;
}将上面代码稍加修改,就可以解决第 1 节遗留的问题,如下。
#include <stdio.h>
struct student
{
char name[21];
char score;
};//这里创建了一个结构体用来存储姓名和分数
int main()
{
struct student a[100],t;
int i,j,n;
scanf("%d",&n); //输入一个数n
for(i=1;i<=n;i++) //循环读入n个人名和分数
scanf("%s %d",a[i].name,&a[i].score);
//按分数从高到低进行排序
for(i=1;i<=n-1;i++)
{
for(j=1;j<=n-i;j++)
{
if(a[j].score<a[j+1].score)//对分数进行比较
{ t=a[j]; a[j]=a[j+1]; a[j+1]=t; }
}
}
for(i=1;i<=n;i++)//输出人名
printf("%s\n",a[i].name);
getchar();getchar();
return 0;
}
冒泡排序的核心部分是双重嵌套循环。不难看出冒泡排序的时间复杂度是 O(N 2 )。
冒泡排序和快速排序之间的过渡:
上一节的冒泡排序可以说是我们学习的第一个真正的排序算法,并且解决了桶排序浪费
空间的问题,但在算法的执行效率上却牺牲了很多,它的时间复杂度达到了
O
(
N
2
)
。假如我
们的计算机每秒钟可以运行
10
亿次,那么对
1
亿个数进行排序,桶排序只需要
0.1
秒,而冒
泡排序则需要
1
千万秒,达到
115
天之久,是不是很吓人?那有没有既不浪费空间又可以快
一点的排序算法呢?
快速排序
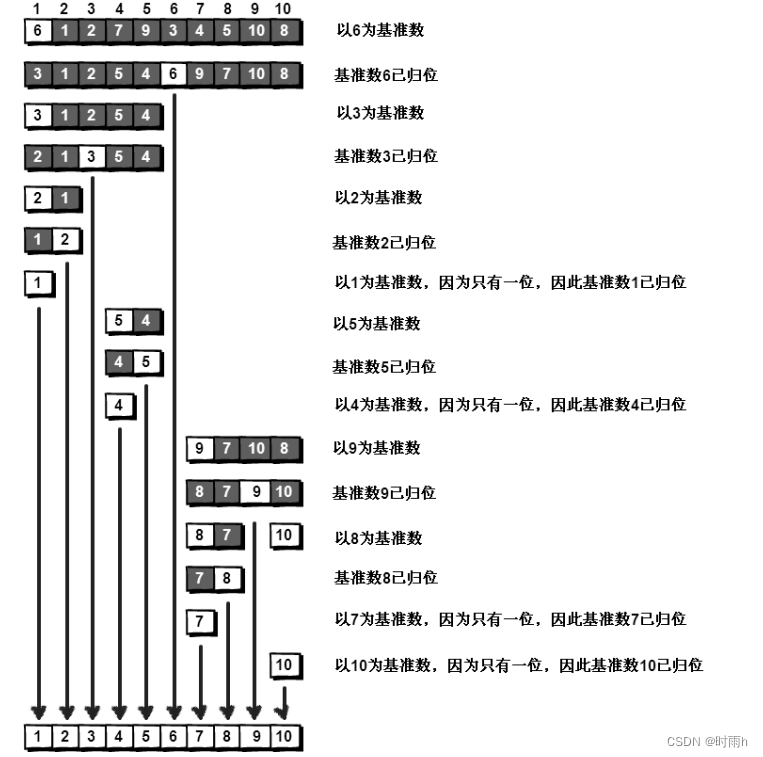
快速排序之所以比较快,是因为相比冒泡排序,每次交换是跳跃式的。每次排序的时候
设置一个基准点,将小于等于基准点的数全部放到基准点的左边,将大于等于基准点的数全
部放到基准点的右边。这样在每次交换的时候就不会像冒泡排序一样只能在相邻的数之间进
行交换,交换的距离就大得多了。因此总的比较和交换次数就少了,速度自然就提高了。当
然在最坏的情况下,仍可能是相邻的两个数进行了交换。因此快速排序的最差时间复杂度和
冒泡排序是一样的,都是
O
(
N
2
)
,它的平均时间复杂度为
O
(
N
log
N
)
。其实快速排序是基于一
种叫做“二分”的思想。
#include <stdio.h>
int a[101],n;//定义全局变量,这两个变量需要在子函数中使用
void quicksort(int left,int right)
{
int i,j,t,temp;
if(left>right)
return;
temp=a[left]; //temp中存的就是基准数
i=left;
j=right;
while(i!=j)
{
//顺序很重要,要先从右往左找
while(a[j]>=temp && i<j)
j--;
//再从左往右找
while(a[i]<=temp && i<j)
i++;
//交换两个数在数组中的位置
if(i<j)//当哨兵i和哨兵j没有相遇时
{
t=a[i];
a[i]=a[j];
a[j]=t;
}
}
//最终将基准数归位
a[left]=a[i];
a[i]=temp;
quicksort(left,i-1);//继续处理左边的,这里是一个递归的过程
quicksort(i+1,right);//继续处理右边的,这里是一个递归的过程
}
int main()
{
int i,j,t;
//读入数据
scanf("%d",&n);
for(i=1;i<=n;i++)
scanf("%d",&a[i]);
quicksort(1,n); //快速排序调用
//输出排序后的结果
for(i=1;i<=n;i++)
printf("%d ",a[i]);
getchar();getchar();
return 0;
}书上对冒泡排序法的拓展介绍:快速排序由 C. A. R. Hoare (东尼·霍尔, Charles Antony Richard Hoare )在 1960 年提出,之后又有许多人做了进一步的优化。如果你对快速排序感兴趣,可以去看看东尼·霍尔1962 年在 Computer Journal 发表的论文“ Quicksort ”以及《算法导论》的第七章。快速排序算法仅仅是东尼·霍尔在计算机领域才能的第一次显露,后来他受到了老板的赏识和重用,公司希望他为新机器设计一种新的高级语言。你要知道当时还没有 PASCAL 或者 C 语言这些高级的东东。后来东尼·霍尔参加了由 Edsger Wybe Dijkstra ( 1972 年图灵奖得主,这个大神我们后面还会遇到的,到时候再细聊)举办的 ALGOL 60 培训班,他觉得自己与其没有把握地去设计一种新的语言,还不如对现有的 ALGOL 60 进行改进,使之能在公司的新机器上使用。于是他便设计了 ALGOL 60 的一个子集版本。这个版本在执行效率和可靠性上都在当时 ALGOL 60 的各种版本中首屈一指,因此东尼·霍尔受到了国际学术界的重视。后来他在 ALGOL X 的设计中还发明了大家熟知的 case 语句,也被各种高级语言广泛采用,比如PASCAL 、 C 、 Java 语言等等。当然,东尼·霍尔在计算机领域的贡献还有很多很多,他在1980 年获得了图灵奖。
啊哈算法---小哼买书(练习快速排序)_慢慢走比较快k的博客-CSDN博客
解决这个问题的方法大致有两种。第一种方法:先将这
n
个图书的
ISBN
号去重,再进
行从小到大排序并输出;第二种方法:先从小到大排序,输出的时候再去重。这两种方法都
可以。
方法一:
#include <stdio.h>
int main()
{
int a[1001],n,i,t;
for(i=1;i<=1000;i++)
a[i]=0; //初始化
scanf("%d",&n); //读入n
for(i=1;i<=n;i++) //循环读入n个图书的ISBN号
{
scanf("%d",&t); //把每一个ISBN号读到变量t中
a[t]=1; //标记出现过的ISBN号
}
for(i=1;i<=1000;i++) //依次判断1~1000这个1000个桶
{
if(a[i]==1)//如果这个ISBN号出现过则打印出来
printf("%d ",i);
}
getchar();getchar();
return 0;
}
这种方法的时间复杂度就是桶排序的时间复杂度,为
O
(
N
+
M
)
。
方法二:
第二种方法我们需要先排序再去重。排序我们可以用冒泡排序或者快速排序。
20 40 32 67 40 20 89 300 400 15
将这
10
个数从小到大排序之后为
15 20 20 32 40 40 67 89 300 400
。
接下来,要在输出的时候去掉重复的。因为我们已经排好序,所以相同的数都会紧挨在
第
1
章 一大波数正在靠近
——
排序
一起。只要在输出的时候,预先判断一下当前这个数
a
[
i
]
与前面一个数
a
[
i
1]
是否相同。如
果相同则表示这个数之前已经输出过了,不用再次输出;不同则表示这个数是第一次出现,
需要输出这个数。
#include <stdio.h>
int main()
{
int a[101],n,i,j,t;
scanf("%d",&n); //读入n
for(i=1;i<=n;i++) //循环读入n个图书ISBN号
{
scanf("%d",&a[i]);
}
//开始冒泡排序
for(i=1;i<=n-1;i++)
{
for(j=1;j<=n-i;j++)
{
if(a[j]>a[j+1])
{ t=a[j]; a[j]=a[j+1]; a[j+1]=t; }
}
}
printf("%d ",a[1]); //输出第1个数
for(i=2;i<=n;i++) //从2循环到n
{
if( a[i] != a[i-1] ) //如果当前这个数是第一次出现则输出
printf("%d ",a[i]);
}
getchar();getchar();
return 0;
}
这种方法的时间复杂度由两部分组成,一部分是冒泡排序的时间复杂度,是
N
(
N
2
)
,另
一部分是读入和输出,都是
O
(
N
)
,因此整个算法的时间复杂度是
O
(2*
N
+
N
2
)
。相对于
N
2
来
说,
2*
N
可以忽略(我们通常忽略低阶),最终该方法的时间复杂度是
O
(
N
2
)
。
原书中的总结:接下来我们还需要看下数据范围。每个图书 ISBN 号都是 1~1000 之间的整数,并且参加调查的同学人数不超过 100 ,即 n ≤ 100 。之前已经说过,在粗略计算时间复杂度的时候,我们通常认为计算机每秒钟大约运行 10 亿次(当然实际情况要更快)。因此以上两种方法都可以在 1 秒钟内计算出解。如果题目中图书的 ISBN 号范围不是在 1~1000 之间,而是-2147483648~2147483647 之间的话,那么第一种方法就不可行了,因为你无法申请出这么大的数组来标记每一个 ISBN 号是否出现过。另外如果 n 的范围不是小于等于 100 ,而是小于等于 10 万,那么第二种方法的排序部分也不能使用冒泡排序。因为题目要求的时间限制是 1 秒,使用冒泡排序对 10 万个数进行排序,计算机要运行 100 亿次,需要 10 秒钟,因此要替换为快速排序,快速排序只需要 100000×log 2 100000≈100000×17≈170 万次,这还不到0.0017 秒。是不是很神奇?同样的问题使用不同的算法竟然有如此之大的时间差距,这就是算法的魅力!我们来回顾一下本章三种排序算法的时间复杂度。桶排序是最快的,它的时间复杂度是O ( N + M ) ;冒泡排序是 O ( N 2 ) ;快速排序是 O ( N log N )