一、顺序表概念
二、顺序表各类接口实现
*顺序表初始化
**顺序表销毁
***顺序表插入操作
****顺序表删除操作
*****顺序表查找操作
******顺序表实现打印操作
三、顺序表整体实现源码
*SeqList.h
**SeqList.c
***test.c
一、顺序表概念
讲顺序表之前先引入线性表概念,线性表是n个有相同特性的数据元素的有限序列,而常见的线性表又有:顺序表、链表、栈、队列、串,而例如图、树就是非线性表;
顺序表概念:顺序表向内存中要了一块连续的空间,然后依次存储数据,就是一个一个的挨着存储,而且里面存放的数据类型是同一种类型,就是c语言中的一维数组。
而顺序表又可分为静态的和动态的,静态顺序表就是给定一个空间,这个空间大小就定死了,不可再修改,那样的话就会造成空间浪费或者空间不足,比如:电梯超重不能运行,就是给定人数为13人,多了就不能升降(当然这只是理论上的);静态顺序表的空间不可改变,因此用动态顺序表比较合适,按照自己的需求向堆中申请空间一次不够再第二次第三次直到申请空间足够,这样不会造成空间过多的浪费。
在顺序表中要实现对数据的各种操作包括增、删、查、改。而其中增和删又可以在尾部,中间,头部进行
二、顺序表的各类接口实现
以下是顺序表存储的结构化以及常用头文件包含
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
typedef int SDataType;//类型想换就换,不然在后面换时需要每一个都换类型
#define INIT_CAPACITY 4//对最开始空间容量为4
typedef struct SeqList
{
SDataType *a;//动态分配数组
int size;//有效数据个数
int capacity;//数组容量
}SL;
*顺序表初始化代码
void SeqInit(SL* ps)
{
ps->a = (SDataType*)malloc(sizeof(SDataType)*INIT_CAPACITY);//向堆动态申请内存空间
if (ps->a == NULL)//但凡申请都有可能失败
{
perror("malloc fail");
return;
}
ps->size = 0;//初始条件下数组中没有数据
ps->capacity = INIT_CAPACITY;//一上来就先给数组4个空间大小
}
**顺序表销毁代码
void SeqDestory(SL* ps)
{
free(ps->a);//堆中开辟的需要释放
ps->a = NULL;//释放之后置空
ps->size = ps->capacity = 0;//空间大小置为0
}
***顺序表插入代码(包含头插,尾插,任意位置插入)
顺序表插入过程就如插队一样,当中午下课后,去食堂排队吃饭,一个挨着一个排好,这时忽然走来一个人,他可以选择就在队伍末尾跟上,也可以在队头和其他位置插入俗称插队,当然在其后面的肯定不安逸,因为他们都要向后挪动一位,这时顺序表插入就比如排队
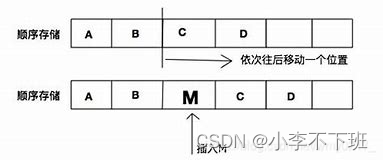
顺序表插入算法思路:从最末尾开始向后挪动,直到空出一个位置,然后将数据插入进去,顺序表长度加一
其中空间容量不够需要给它扩容
尾插时间复杂度为O(1)
最坏的情况下,每一个元素都要向后移到,所以时间复杂度为O(n)
当然在顺序表插入数据时需要考虑空间是否足够,以下是对顺序表增容代码
void Checkcpacity(SL* ps)
{
//扩容
if (ps->size == ps->capacity)
{
SDataType* tmp = (SDataType*)realloc(ps->a, sizeof(SDataType) * ps->capacity * 2);//扩容看自己喜欢,但是二倍较为合适
if (tmp == NULL)
{
printf(“realloc fail”);
exit(-1);
}
ps->capacity *= 2;
ps->a = tmp;//将新开辟的空间给数组a
}
}
*尾插代码
void SeqPushBack(SL* ps, SDataType x)
{
扩容
//if (ps->size == ps->capacity)
//{
// SDataType* tmp = (SDataType*)realloc(ps->a, sizeof(SDataType) *ps->capacity*2);//扩容看自己喜欢,但是二倍较为合适
// if (tmp == NULL)
// {
// printf("realloc fail");
// exit(-1);
// }
// ps->capacity *= 2;
// ps->a = tmp;//将新开辟的空间给数组a
//}
Checkcpacity(ps);
ps->a[ps->size++] = x;
}
头插代码
void SeqPushFront(SL* ps, SDataType x)
{
assert(ps);
Checkcpacity(ps);
int begin = 0;
int end = ps->size;
while (end >= 0)
{
ps->a[end] = ps->a[end - 1];
end--;
}
ps->a[0] = x;
ps->size++;
}
任意位置插入
void SeqInsert(SL* ps, int pos, SDataType x)
{
assert(ps);
Checkcpacity(ps);
assert(pos >= 0 && pos <= ps->size);
int end = ps->size;
while (end > pos)
{
ps->a[end] = ps->a[end - 1];
end--;
}
ps->a[pos] = x;
ps->size++;
}
****顺序表删除操作
也包括头删尾删和任意位置删除,删除可以理解为是后一个把前一个覆盖,然后顺序表长度减一
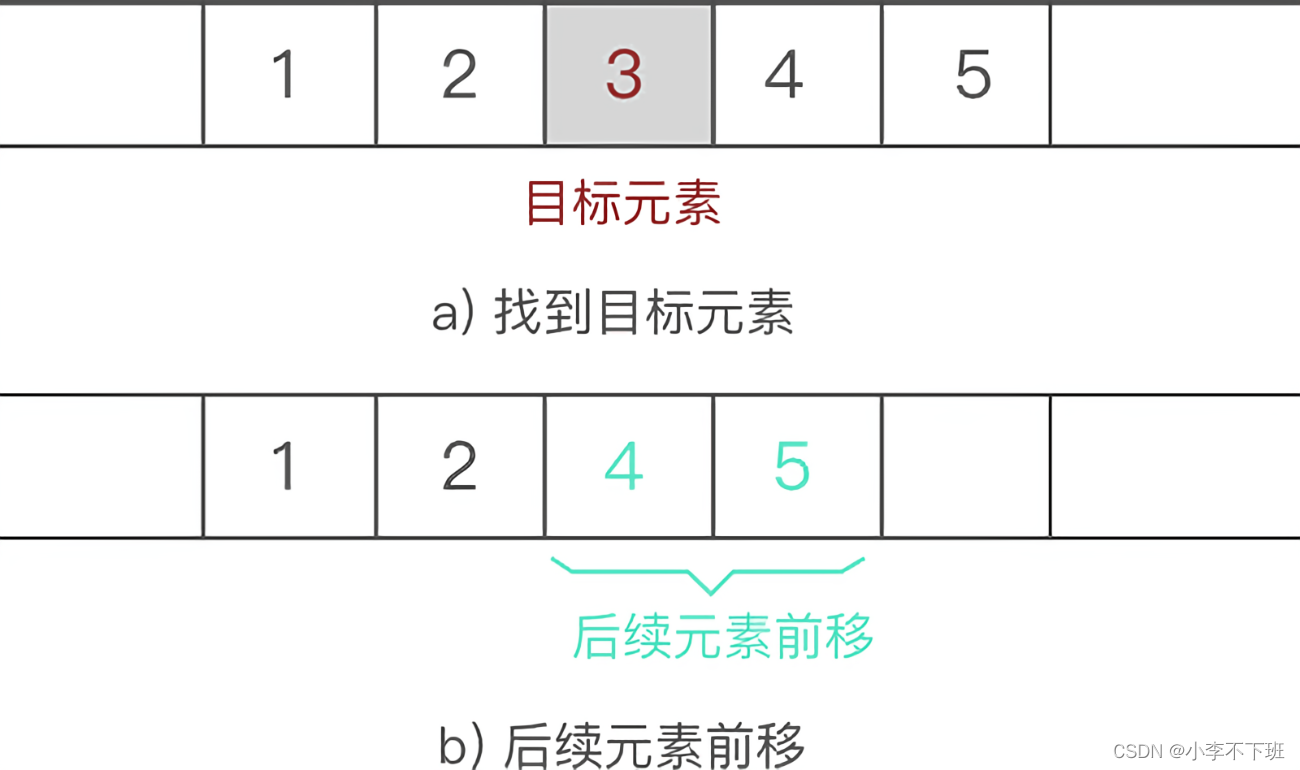
删除算法在末尾删时间复杂度就是最好的情况为O(1),它不必循环
最坏的情况是在头部删除,删除一个就要挪动n-1个数据,其时间复杂度为O(N),删除操作的时间复杂度就为O(n)
头删
void SeqPopFront(SL* ps)
{
assert(ps);
int begin = 0;
assert(ps->size > 0);
while (begin < ps->size - 1)
{
ps->a[begin] = ps->a[begin + 1];
begin++;
}
ps->size--;
}
**``尾删**
```c
void SeqPopBack(SL* ps)
{/*
if (ps->size == 0)
{
return;
}*/
assert(ps->size > 0);//断言可以让你知道是哪里出了问题
ps->size--;
}
任意位置删除
void SeqErase(SL* ps, int pos)
{
assert(ps);
assert(pos >= 0 && pos < ps->size - 1);
assert(ps->size > 0);
while (pos < ps->size-1)
{
ps->a[pos] = ps->a[pos + 1];
pos++;
}
ps->size--;
}
*****顺序表查找与修改操作
查找
int SeqFind(SL* ps, SDataType x)
{
assert(ps);
int i = 0;
for (i = 0; i < ps->size; i++)
{
if (ps->a[i] == x)
{
return i;
}
}
return -1;
}
修改
void SeqModify(SL* ps, int pos, SDataType x)
{
int i = 0;
for (i = 0; i < ps->size; i++)
{
if (i == pos)
{
ps->a[i] = x;
}
}
}
******顺序表打印
void Seqprint(SL* ps)
{
int i = 0;
for (i = 0; i < ps->size; i++)
{
printf("%d ", ps->a[i]);
}
printf("\n");
}
****三、顺序表整体实现源码
SeqList.h
#include<stdlib.h>
#include<stdio.h>
#include<assert.h>
#define INIT_CAPACITY 4//初始容量
typedef int SDataType;//类型想换就换,不然在后面换时需要每一个都换类型
typedef struct SeqList
{
SDataType *a;
int size;//有效数据个数
int capacity;//空间容量不够考虑扩容
}SL;
void SeqInit(SL* ps);//顺序表初始化
void SeqDestory(SL* ps);//顺序表销毁
void Seqprint(SL* ps);//顺序表输出
void SeqPushBack(SL* ps, SDataType x);//尾插
void SeqPopBack(SL* ps);//尾删
void SeqPushFront(SL* ps, SDataType x);//头插
void SeqPopFront(SL* ps);//头删
void SeqErase(SL* ps, int pos);//删除pos位置的元素
void SeqInsert(SL* ps, int pos, SDataType x);//在pos位置插入x
int SeqFind(SL* ps, SDataType x);//查找值为x的位置
void SeqModify(SL* ps, int pos, SDataType x);//修改
SeqList.c
#include"SeqList.h"
void SeqInit(SL* ps)
{
ps->a = (SDataType*)malloc(sizeof(SDataType)*INIT_CAPACITY);
if (ps->a == NULL)
{
perror("malloc fail");
return;
}
ps->size = 0;
ps->capacity = INIT_CAPACITY;
}
void SeqDestory(SL* ps)
{
free(ps->a);//堆中开辟的需要释放
ps->a = NULL;//释放之后置空
ps->size = ps->capacity = 0;//空间大小置为0
}
void Seqprint(SL* ps)
{
int i = 0;
for (i = 0; i < ps->size; i++)
{
printf("%d ", ps->a[i]);
}
printf("\n");
}
void Checkcpacity(SL* ps)
{
//扩容
if (ps->size == ps->capacity)
{
SDataType* tmp = (SDataType*)realloc(ps->a, sizeof(SDataType) * ps->capacity * 2);//扩容看自己喜欢,但是二倍较为合适
if (tmp == NULL)
{
printf("realloc fail");
exit(-1);
}
ps->capacity *= 2;
ps->a = tmp;//将新开辟的空间给数组a
}
}
void SeqPushBack(SL* ps, SDataType x)
{
扩容
//if (ps->size == ps->capacity)
//{
// SDataType* tmp = (SDataType*)realloc(ps->a, sizeof(SDataType) *ps->capacity*2);//扩容看自己喜欢,但是二倍较为合适
// if (tmp == NULL)
// {
// printf("realloc fail");
// exit(-1);
// }
// ps->capacity *= 2;
// ps->a = tmp;//将新开辟的空间给数组a
//}
Checkcpacity(ps);
ps->a[ps->size++] = x;
}
void SeqPopBack(SL* ps)
{/*
if (ps->size == 0)
{
return;
}*/
assert(ps->size > 0);//断言可以让你知道是哪里出了问题
ps->size--;
}
void SeqPushFront(SL* ps, SDataType x)
{
assert(ps);
Checkcpacity(ps);
int begin = 0;
int end = ps->size;
while (end >= 0)
{
ps->a[end] = ps->a[end - 1];
end--;
}
ps->a[0] = x;
ps->size++;
}
void SeqPopFront(SL* ps)
{
assert(ps);
int begin = 0;
assert(ps->size > 0);
while (begin < ps->size - 1)
{
ps->a[begin] = ps->a[begin + 1];
begin++;
}
ps->size--;
}
void SeqInsert(SL* ps, int pos, SDataType x)
{
assert(ps);
Checkcpacity(ps);
assert(pos >= 0 && pos <= ps->size);
int end = ps->size;
while (end > pos)
{
ps->a[end] = ps->a[end - 1];
end--;
}
ps->a[pos] = x;
ps->size++;
}
void SeqErase(SL* ps, int pos)
{
assert(ps);
assert(pos >= 0 && pos < ps->size - 1);
assert(ps->size > 0);
while (pos < ps->size-1)
{
ps->a[pos] = ps->a[pos + 1];
pos++;
}
ps->size--;
}
int SeqFind(SL* ps, SDataType x)
{
assert(ps);
int i = 0;
for (i = 0; i < ps->size; i++)
{
if (ps->a[i] == x)
{
return i;
}
}
return -1;
}
void SeqModify(SL* ps, int pos, SDataType x)
{
int i = 0;
for (i = 0; i < ps->size; i++)
{
if (i == pos)
{
ps->a[i] = x;
}
}
}
test.c
#include"SeqList.h"
void test()
{
SL s;
SeqInit(&s);//传结构体地址过去,形参改变实参
SeqPushBack(&s, 1);
SeqPushBack(&s, 2);
SeqPushBack(&s, 3);
SeqPushBack(&s, 4);
SeqPushBack(&s, 5);
Seqprint(&s);
/*SeqPopBack(&s);
SeqPopBack(&s);
SeqPopBack(&s);
SeqPopBack(&s);
Seqprint(&s);
SeqPopBack(&s);
SeqPopBack(&s);
SeqPopBack(&s);
Seqprint(&s)*/;
SeqPushFront(&s, 9);
Seqprint(&s);
/*SeqPopFront(&s);
SeqPopFront(&s);
SeqPopFront(&s);
SeqPopFront(&s);*/
//SeqPopFront(&s);
//SeqPopFront(&s);
//SeqPopFront(&s);
//SeqPopFront(&s);
//SeqPopFront(&s);
//SeqPopFront(&s);
//SeqPopFront(&s);
SeqPopFront(&s);
//SeqPopFront(&s);
//Seqprint(&s);
SeqInsert(&s, 3, 10);
Seqprint(&s);
SeqErase(&s, 3);
Seqprint(&s);
int pos = SeqFind(&s, 3);
printf("%d\n", pos);
if (pos != -1)
{
SeqModify(&s, pos, 10);
}
Seqprint(&s);
SeqDestory(&s);
}
int main()
{
test();
return 0;
}
总结
顺序表有优点也有缺点
优点:尾插、尾删效率贼高,也可以按下表来访问顺序表中的元素
缺点:在顺序表中出了尾部上的插入删除外,在其他位置删除或者插入效率都极低,而且在空间不够扩容的时候容易造成空间浪费
好了数据结构顺序表篇就结束了,球球各位佬们一键四练叭!你们的支持对于我来说尤为重要