文章目录
- 什么是广播表
- 广播表实战
- 数据库配置表
- Java配置实体类
- 配置文件
- 测试广播表
- 水平分库+分表
- 配置文件
- 运行测试
- 什么是绑定表?
- 绑定表实战
- 配置数据库
- 配置Java实体类
- 配置文件
- 运行测试
- 水平分库+分表后的查询和删除操作
- 查询操作
什么是广播表
指所有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中均完全⼀致
适用于数据量不⼤且需要与海量数据的表进行关联查询的场景,例如:字典表、配置表
需求:在任意一个库中插入一条数据,另一个库中的相同表也插入这条数据
广播表实战
数据库配置表
脚本
CREATE TABLE `ad_config` (
`id` BIGINT UNSIGNED NOT NULL COMMENT '主键id',
`config_key` VARCHAR ( 1024 ) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '配置key',
`config_value` VARCHAR ( 1024 ) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '配置value',
`type` VARCHAR ( 128 ) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '类型',
PRIMARY KEY ( `id` )
) ENGINE = INNODB DEFAULT CHARSET = utf8mb4 COLLATE = utf8mb4_bin;
Java配置实体类
model层
@Data
@EqualsAndHashCode(callSuper = false)
@TableName("ad_config")
public class AdConfigDO {
private Long id;
private String configKey;
private String configValue;
private String type;
}
mapper层
public interface AdConfigMapper extends BaseMapper<AdConfigDO> {
}
配置文件
增加配置规则
#配置⼴播表
spring.shardingsphere.sharding.broadcasttables=ad_config
spring.shardingsphere.sharding.tables.ad_config.key-generator.column=id
spring.shardingsphere.sharding.tables.ad_config.key-generator.type=SNOWFLAKE
配置文件完整
spring.application.name=xdclass-sharding-jdbc
server.port=8080
# 打印执行的数据库以及语句
spring.shardingsphere.props.sql.show=true
# 数据源 db0
spring.shardingsphere.datasource.names=ds0,ds1
# 第一个数据库
spring.shardingsphere.datasource.ds0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds0.jdbc-url=jdbc:mysql://10.24.201.232:3306/xdclass_shop_order_0?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.ds0.username=root
spring.shardingsphere.datasource.ds0.password=root
# 第二个数据库
spring.shardingsphere.datasource.ds1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds1.jdbc-url=jdbc:mysql://10.24.201.232:3306/xdclass_shop_order_1?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=root
#配置workId
spring.shardingsphere.sharding.tables.product_order.key-generator.props.worker.id=1
#配置广播表
spring.shardingsphere.sharding.broadcast-tables=ad_config
spring.shardingsphere.sharding.tables.ad_config.key-generator.column=id
spring.shardingsphere.sharding.tables.ad_config.key-generator.type=SNOWFLAKE
#id生成策略
spring.shardingsphere.sharding.tables.product_order.key-generator.column=id
spring.shardingsphere.sharding.tables.product_order.key-generator.type=SNOWFLAKE
# 指定product_order表的数据分布情况,配置数据节点,行表达式标识符使用 ${...} 或 $->{...},
# 但前者与 Spring 本身的文件占位符冲突,所以在 Spring 环境中建议使用 $->{...}
spring.shardingsphere.sharding.tables.product_order.actual-data-nodes=ds0.product_order_$->{0..1}
# 指定product_order表的分片策略,分片策略包括【分片键和分片算法】
spring.shardingsphere.sharding.tables.product_order.table-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.product_order.table-strategy.inline.algorithm-expression=product_order_$->{user_id % 2}
测试广播表
测试类
@Test
public void testSaveAdConfig(){
AdConfigDO adConfigDO = new AdConfigDO();
adConfigDO.setConfigKey("banner");
adConfigDO.setConfigValue("xdclass.net");
adConfigDO.setType("ad");
adConfigMapper.insert(adConfigDO);
}
运行结果:


水平分库+分表
需求:插入订单数据,分布在2个数据库和每个库的2张表中
分库规则:根据 user_id 进行分库
分表规则:根据 product_order_id 订单号(id字段)进行分表
配置文件
增加分库配置规则
# 配置分库规则
spring.shardingsphere.sharding.tables.product_order.database-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.product_order.database-strategy.inline.algorithm-expression=ds$->{user_id % 2 }
修改数据节点配置规则
# 指定product_order表的数据分布情况,配置数据节点,行表达式标识符使用 ${...} 或 $->{...},
# 但前者与 Spring 本身的文件占位符冲突,所以在 Spring 环境中建议使用 $->{...}
spring.shardingsphere.sharding.tables.product_order.actual-data-nodes=ds$->{0..1}.product_order_$->{0..1}
# 指定product_order表的分片策略,分片策略包括【分片键和分片算法】
spring.shardingsphere.sharding.tables.product_order.table-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.product_order.table-strategy.inline.algorithm-expression=product_order_$->{id % 2}
运行测试
测试类
@Test
public void testSaveProductOrder(){
Random random = new Random();
for(int i=0; i<20;i++){
ProductOrderDO productOrderDO = new ProductOrderDO();
productOrderDO.setCreateTime(new Date());
productOrderDO.setNickname("我是i"+i+"号");
productOrderDO.setOutTradeNo(UUID.randomUUID().toString().substring(0,32));
productOrderDO.setPayAmount(100.00);
productOrderDO.setState("PAY");
productOrderDO.setUserId(Long.valueOf(random.nextInt(50)));
productOrderMapper.insert(productOrderDO);
}




什么是绑定表?
指分片规则⼀致的主表和子表
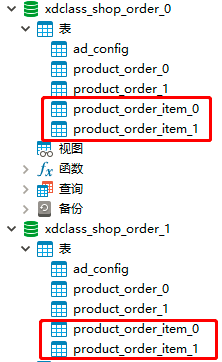
需求:product_order表和product_order_item表,均按照order_id分片,则此两张表互为绑定表关系
绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升
绑定表实战
配置数据库
脚本
CREATE TABLE `product_order_item_0` (
`id` BIGINT UNSIGNED NOT NULL AUTO_INCREMENT,
`product_order_id` BIGINT DEFAULT NULL COMMENT '订单号',
`product_id` BIGINT DEFAULT NULL COMMENT '产品id',
`product_name` VARCHAR ( 128 ) DEFAULT NULL COMMENT '商品名称',
`buy_num` INT DEFAULT NULL COMMENT '购买数量',
`user_id` BIGINT DEFAULT NULL,
PRIMARY KEY ( `id` )
) ENGINE = INNODB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8mb4 COLLATE = utf8mb4_bin;
配置Java实体类
model层
@Data
@TableName("product_order_item")
@EqualsAndHashCode(callSuper = false)
public class ProductOrderItemDO {
private Long id;
private Long productOrderId;
private Long productId;
private String productName;
private Integer buyNum;
private Long userId;
}
mapper层
public interface ProductOrderMapper extends BaseMapper<ProductOrderDO> {
@Select("select * from product_order o left join product_order_item i on o.id=i.product_order_id")
List<Object> listProductOrderDetail();
}
public interface ProductOrderItemMapper extends BaseMapper<ProductOrderItemDO> {
}
配置文件
添加配置:默认分库策略
#配置【默认分库策略】
spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=ds$->{user_id % 2 }
添加配置:配置绑定表
#配置绑定表
spring.shardingsphere.sharding.binding‐tables[0] = product_order,product_order_item
添加配置:分片键、分片策略
# 指定product_order_item表的分片策略,分片策略包括【分片键和分片算法】
spring.shardingsphere.sharding.tables.product_order_item.actual-data-nodes=ds$->{0..1}.product_order_item_$->{0..1}
spring.shardingsphere.sharding.tables.product_order_item.table-strategy.inline.sharding-column=product_order_id
spring.shardingsphere.sharding.tables.product_order_item.table-strategy.inline.algorithm-expression=product_order_item_$->{product_order_id % 2}
运行测试
测试类
@Test
public void testBingding(){
List<Object> list = productOrderMapper.listProductOrderDetail();
System.out.println(list);
}
配置绑定表时SQL数量(性能):4条SQL
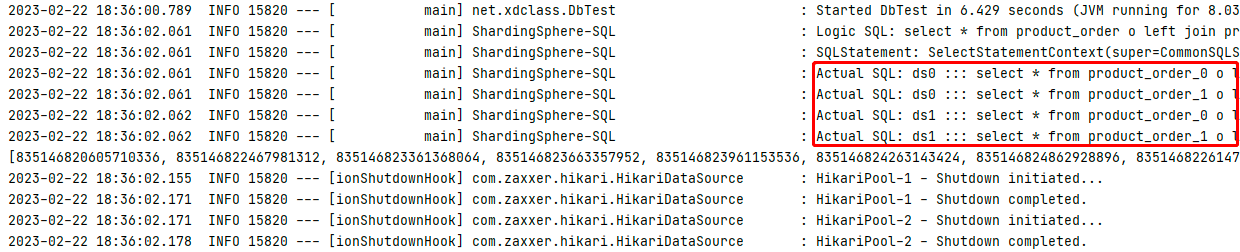
不配置绑定表时SQL数量(性能):8条SQL(注释掉绑定表的配置文件配置)
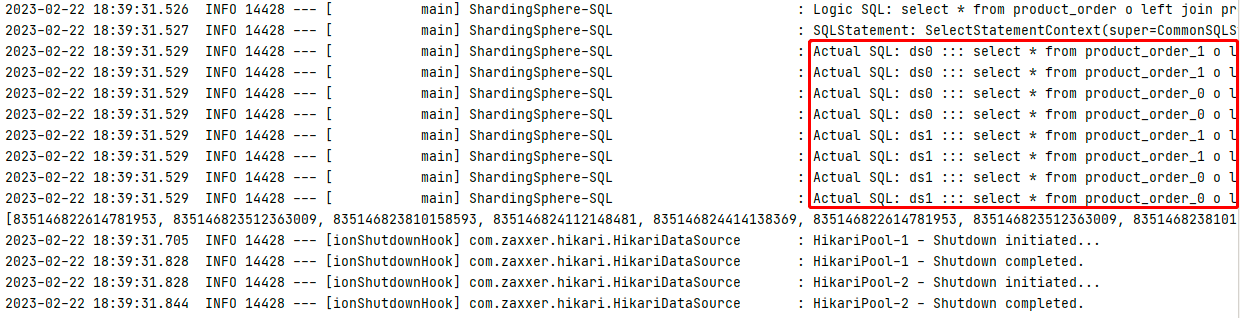
水平分库+分表后的查询和删除操作
查询操作
有分片键(标准路由)=、in
测试类
/**
* 有分片键
*/
@Test
public void testPartitionKeySelect(){
productOrderMapper.selectList(new QueryWrapper<ProductOrderDO>().eq("id",835146820605710336L));
//productOrderMapper.selectList(new QueryWrapper<ProductOrderDO>().in("id",Arrays.asList(1464129579089227778L,1464129582369173506L,1464129583140925441L)));
}



![论文解读 | [AAAI2020] 你所需要的是边界:走向任意形状的文本定位](https://img-blog.csdnimg.cn/6ef7902e4dea4188835df6e715ba62ef.png)