深度学习无监督磁共振重建方法调研(二)
- Self-supervised learning of physics-guided reconstruction neural networks without fully sampled reference data(Magnetic Resonance in Medicine 2020)
- 模型设计
- 实验结果
- PARCEL: Physics-based Unsupervised Contrastive Representation Learning for Multi-coil MR Imaging(IEEE/ACM TRANSACTIONS ON COMPUTATIONAL BIOLOGY AND BIOINFORMATICS)
- 问题定义与模型设计
- 损失函数
- Undersample Calibration Loss
- Reconstructed Calibration Loss
- Contrastive Representaion Loss
- 实验结果
Self-supervised learning of physics-guided reconstruction neural networks without fully sampled reference data(Magnetic Resonance in Medicine 2020)
本文提出了一种基于自监督方式训练神经网络用于磁共振重建的方式,并通过在公开数据集(fastMRI multi-coil knee)以及前瞻性加速脑成像图(没有GT数据的?)上的数值和人工衡量,证明了方法的有效性。
模型设计
对于完整采样的mask
Ω
\Omega
Ω,作者将其划分成为了两个mask,
Θ
\Theta
Θ和
Λ
\Lambda
Λ,其中
Θ
\Theta
Θ用于训练(生成输入的降采样数据和应用数据一致层),
Λ
\Lambda
Λ用于定义损失函数,即衡量输出结果在
Λ
\Lambda
Λ采样的部分是否和真实数据一致。注意测试时会将所有采样点全部输入生成结果。
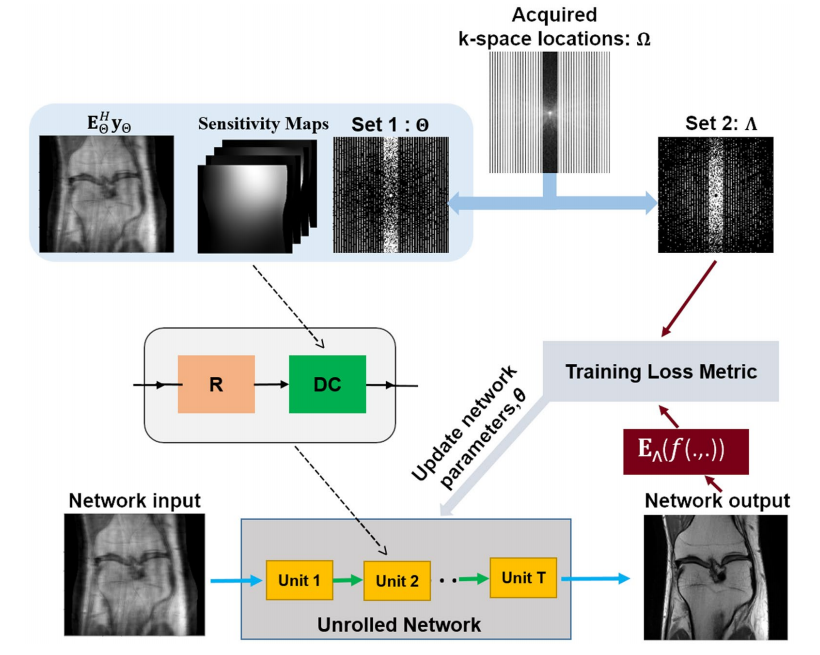
作者采用了normalized l2-l1损失进行训练,模型方法和对标的有监督方法都在K空间定义损失:
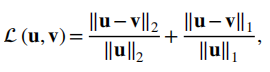
在Mask选择上,作者定义
ρ
=
∣
Λ
∣
/
∣
Ω
∣
\rho=|\Lambda|/|\Omega|
ρ=∣Λ∣/∣Ω∣,选择了表现最好的值(膝盖数据集是0.4),并且做了三个变体,主要区别是
Λ
\Lambda
Λ和
Θ
\Theta
Θ的重叠:
- 无重叠(原始设定)
- 重叠50%
- 重叠100%
最后发现原始设定最好。作者还在不同的 ρ \rho ρ下验证了不同的随机降采样方式,发现高斯比均匀降采样好,因此选择高斯降采样。
实验结果
作者在fastMRI的多线圈Knee上做了实验(4倍降采样),对比了有监督方法,无监督方法和传统CS重建方法,看起来提出的方法好于传统方法,和有监督方法相当。
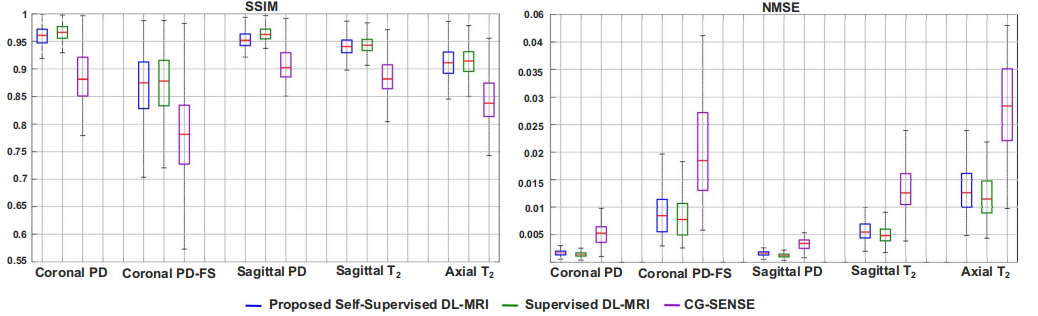
其它实验结果就不赘述了。
PARCEL: Physics-based Unsupervised Contrastive Representation Learning for Multi-coil MR Imaging(IEEE/ACM TRANSACTIONS ON COMPUTATIONAL BIOLOGY AND BIOINFORMATICS)
同样是王珊珊团队的工作,可以看作是SelfCoLearn的进阶版,对多线圈成像做了更多的讨论。
问题定义与模型设计
和单线圈磁共振成像不同的是,除了降采样矩阵
Ω
\mathbf{\Omega}
Ω和傅里叶变换
F
F
F外,还包括了线圈敏感度信息
S
S
S,下式中
ϵ
\epsilon
ϵ表示噪声,下标
i
i
i表示线圈,
C
C
C为线圈数:
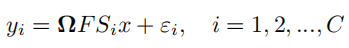
和SelfCoLearn一样,模型也分为了两个子网络,输入的数据经过了re-降采样(
A
j
A_j
Aj),求解的问题的表示如下所示:
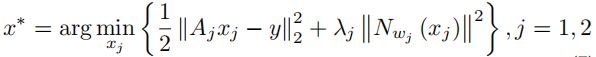
其中
A
j
=
Ω
i
F
S
A_j=\mathbf{\Omega_i}FS
Aj=ΩiFS,
j
j
j用于表示两个子网络。网络用
D
w
D_w
Dw表示,采用MoDL结构(因为是在每次迭代中共享权重,所以
D
w
D_w
Dw也可以用来表示整个网络),输出为
x
1
x_1
x1和
x
2
x_2
x2。
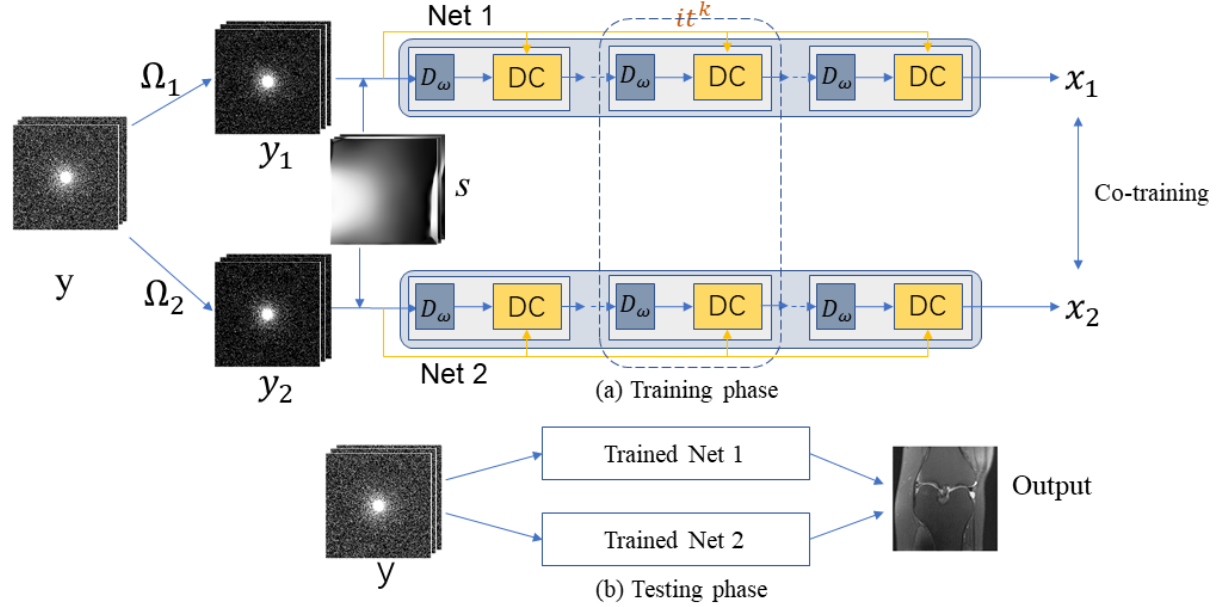
损失函数
模型设计了精巧的co-training loss,包含三个部分,总公式如下,
L
L
L为样本总数,不过根据代码,三种损失并不是1:1:1,而是1:0.1:0.1。
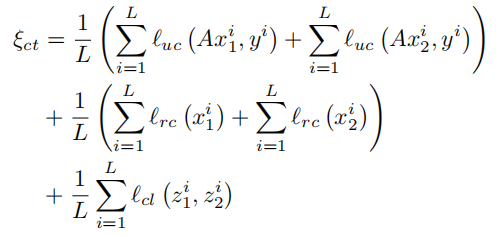
Undersample Calibration Loss
表示为
l
u
c
l_{uc}
luc,主要是确保重建后的结果在所有采样位置(未经过re-降采样)和已知的结果一致:
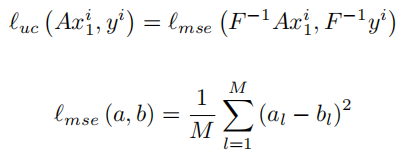
Reconstructed Calibration Loss
表示为
l
r
c
l_{rc}
lrc,其将
x
x
x(这里只是表示损失函数的输入,实际使用中的输入就是两个子网络的输出
x
1
x_1
x1或者
x
2
x_2
x2),
E
E
E表示
F
S
FS
FS,
E
H
E^H
EH表示
S
F
−
1
SF^{-1}
SF−1。
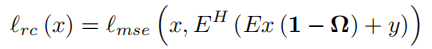
从式子上看,是希望将输出的重建结果的真实采样部分替换为真实值
y
y
y后得到的图像,和不替换也尽可能相似。不过这样的话似乎和
l
u
c
l_{uc}
luc没什么区别?只不过一个比的是零填充其余部分,一个比的是用重建值填充其余部分的图像的MSE损失,这有影响吗?
Contrastive Representaion Loss
表示为
l
c
l
l_{cl}
lcl,用来尽可能增加两个自网络输出结果的相似性:

特别注意的是这里的
z
z
z是输出经过额外一个1024大小的全连接层+ReLU的expander来实现的,
z
1
=
h
1
(
x
1
)
z_1=h_1(x_1)
z1=h1(x1),
z
2
=
h
2
(
x
2
)
z_2=h_2(x_2)
z2=h2(x2)。
s
i
m
(
)
sim()
sim()采用余弦相似度,作者通过该损失函数最大化两个网络输出的相似。不过从代码上来看
h
1
=
h
2
h_1=h_2
h1=h2。
实验结果
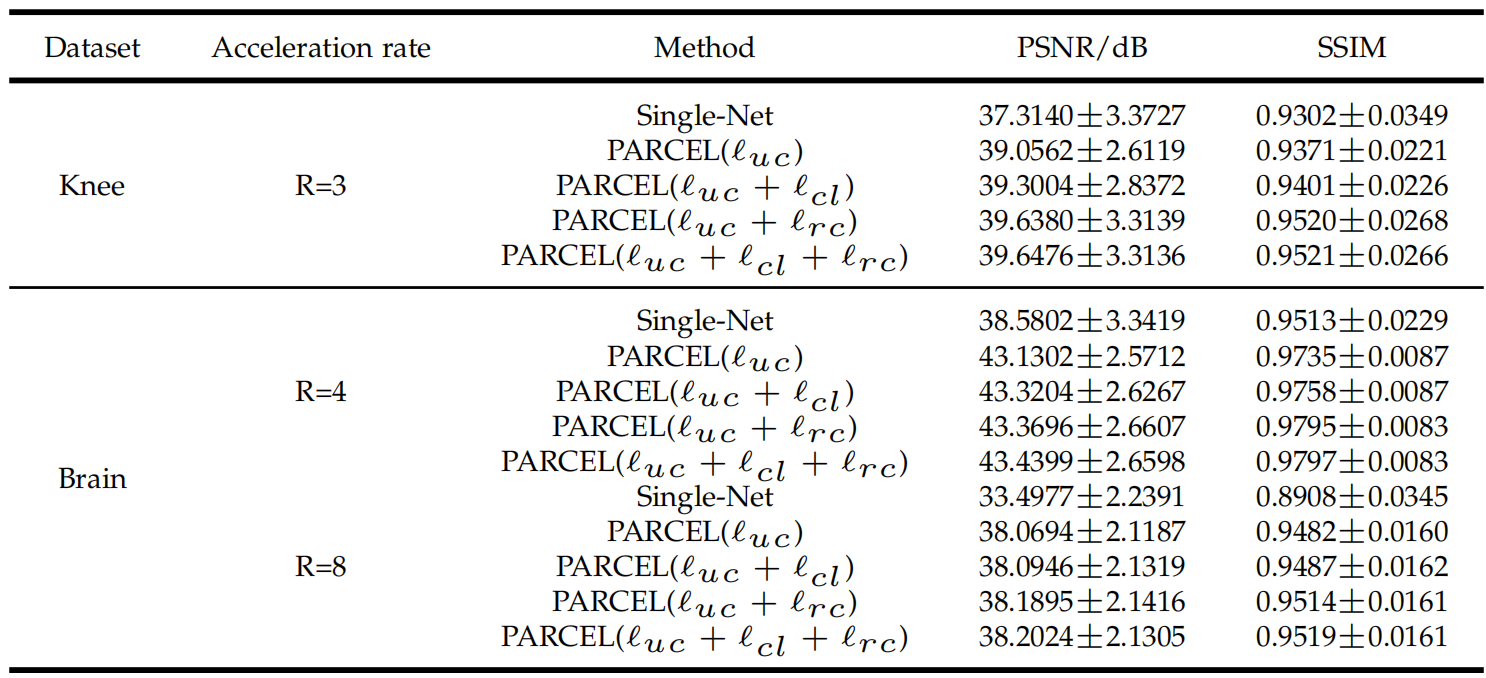
作者在fastMRI的多线圈膝盖数据集和一个自己的大脑数据集上做了实验,尝试了三种不容的降采样mask。对比了SENSE,Variational-Net,U-Net-256,SSDU(上一篇文章),Supervised-MoDL。反正结果基本是仅次于Supervised MoDL。
作者验证了Contrastive Loss的作用,使用只使用单个网络自监督Single-Net(没说什么方法,应该是UC损失),只使用UC的PARCEL模型Parallel-Net,加入了CL损失的PARCEL模型CL,对比如下:
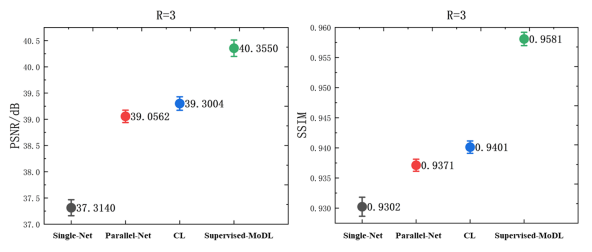
下一节中进行了更详细的比较,如下: