阅读完本文你可以学到什么是索引生命周期管理,各个阶段可以做的操作以及如何使用索引模版使用索引生命周期策略,下面就跟我一起来吧
基础理论篇
索引生命周期管理(ILM)是一种可以让我们随着时间推移自动化的管理索引的一种方式。我们可以根据性能,索引文档数量、大小等弹性要求,文档的保留需求等方面来自定义索引生命周期管理策略,我们可以使用ILM实现如下需求
-
当索引达到一定的大小或者一定的文档数量时生成一个新的索引
-
每天、每周或者每个月创建一个新索引、并把之前的索引归档
-
删除历史索引、按照数据保留标准执行是否保留索引
在ILM策略期间可以触发的操作有:Set Priority,Unfollow,Rollover,Read-only,Shrink,Force merge,Searchable snapshot,Allocate,Migrate,Wait for snapshot,Delete
下面是每个操作具体的含义
-
Set Priority可应用阶段:
Hot,Warm,Cold设置步骤的优先级
必须参数,设置索引优先级,大于等于
0的整数;设置为null删除优先级;Hot阶段应具有最高值,Cold应具有最低值;例如Hot 100,Warm 50,Cold 0;未设置此值的索引优先级默认为1 -
Unfollow可应用阶段:
Hot,Warm,Cold,Frozen跨集群索引设置为标准索引,可以使
shrink、rollover、searchable snapshot操作安全的在follower索引上执行;在整个生命周期中移动
follower索引时,也可以直接使用unfollow,对于不是follower索引的没有影响、阶段执行中只是跳转到下一个操作当
shrink、rollover、searchable snapshot应用于follower索引时,该操作会自动触发follower索引安全转换为标准索引需要满足以下条件leader索引index.lifecycle.indexing_complete设置为true。如果是rollover操作,则会自动设置此设置,或者使用index settings api手动设置- 对
leader索引执行的操作都已经复制到follower索引,这样可以确保在转换索引时不会丢失任何操作
当上述条件都满足后,
unfollow将执行以下操作- 暂停
follower索引的索引 - 关闭
follower索引 - 取消
leader索引 - 打开
follower索引(此时是标准索引)
-
Rollover滚动策略,也就是按照策略递增的实现方式;
当前索引达到一定的大小、或者一定文档的数量或者年龄时自动创建一个新的写索引
可应用阶段:
Hot如果该操作是在
follower索引上执行,那么该操作将等待leader索引执行该操作完成rollover的目标可以是数据流或者索引别名当滚动目标是
数据流时,这个生成的新索引将成为数据流的写入索引,并且索引名是递增的当滚动目前是
索引别名时,别名以及其写索引需要满足以下条件(重要!!!重要!!!重要!!!)- 索引名称必须满足如下匹配规则*
^.\*-\d+$* - 索引的滚动目标别名
index.lifecycle.rollover_alias必须要设置 - 该索引必须是索引的
写入索引
例如:索引
my-index-001别名为my_data,如下配置是必须的PUT my-index-001 { "settings": { "index.lifecycle.name": "my_policy", "index.lifecycle.rollover_alias": "my_data" }, "aliases": { "my_data": { "is_write_index": true } } }上面我们看到
rollover的操作需要满足一种条件,那么我们必须至少设置一种滚动条件-
max_age:从索引创建之日起开始计算时间,满足之后触发滚动操作。例如1d,7d,30d;即使我们通过index.lifecycle.parse_origination_date或者index.lifecycle.origination_date来设置索引的起始日期,计算时也是按照索引创建时的日期 -
max_docs:达到指定的最大文档数量之后触发滚动操作。上一次refresh之后的文档不计数,副本分片中的文档也不计数 -
max_size:当索引中所有的主分片之和达到一定的大小时触发滚动操作,副本分片不计算入最大索引大小在使用
_cat API时,pri.store.size的值就是主分片的大小 -
max_primary_shard_size:当索引中最大的主分片达到一定的大小时触发滚动操作,这是索引中最大主分片的最大大小。与max_size一样,副本分片大小也不计入其中
- 索引名称必须满足如下匹配规则*
-
Read-only可应用阶段:
Hot,Warm,Cold使索引变为只读索引,如果要在
Hot阶段执行Read-only操作,前提是必须执行rollover操作,如果没有配置rollover操作,ILM将拒绝Read-only策略 -
Shrink可应用阶段:
Hot,Warm前提:将源索引设置为只读;所有分片必须在同一个节点上;集群健康状态为
Green;减少索引分片的数量或者减少主分片的数量,生成的索引名为
shrink-<random-uuid>-<original-index-name>,分片数量使用如下参数控制number_of_shards:可选整数类型,必须为现有索引分片数整除的数字,与max_primary_shard_size不兼容,只能设置一个max_primary_shard_size:可选字节单位(b,kb,mb,gb,tb,pb),目标索引的最大主分片的大小,用于查找目标索引的最大分片数,设置此参数后,每个分片在目标索引的存储占用不会大于该参数
-
Force merge可应用阶段:
Hot,Warm合并索引中的
segments到指定的最大段数,此操作会将索引设置为Read-only;强制合并会尽最大的努力去合并,如果此时有的分片在重新分配,那么该分片是无法被合并的如果我们要在
Hot阶段执行Force merge操作,rollover操作是必须的,如果没有配置rollover,ILM会拒绝该策略max_num_segments:必须的整数类型,表示要合并到的segments数量,如果要完全合并索引,需要设置值为1index_codec:可选字符串参数,压缩文档的编解码器,只能设置best_compression,它可以获得更高的压缩比,但是存储性能较差。该参数默认值LZ4,如果要使用LZ4,此参数可不用设置
-
Searchable snapshot可应用阶段:
Hot,Cold,Forzen将快照挂载为可搜索的索引。如果索引是数据流的一部分,则挂载的索引将替换数据流中的原始索引
Searchable snapshot操作绑定对应的数据层,也就是(Hot-Warm-Cold-Forzen-Delete),恢复数据时直接恢复到对应的数据层,该操作使用
index.routing.allocation.include._tier_preference设置,在冻结层(frozen)该操作会将前缀为partial-的部分数据恢复到冻结层,在其他层,会将前缀为restored-的全部数据恢复到对应层 -
Allocate可应用阶段:
Warm,Cold设定副本数量,修改分片分配规则。将分片移动到不同性能特征的节点上并减少副本的数量,该操作不可在
Hot阶段执行,初始的分配必须通过手动设置或者索引模版设置。如果配置该设置必须指定副本的数量,或者至少指定如下操作的一个(include,exclude,require),如果不设置分配策略即空的分配策略是无效的number_of_replicas:整数类型,分配给索引的副本数total_shards_per_node:单个ES节点上索引最大分片数,-1代表没有限制include:为至少具有一个自定义属性的节点分配索引exclude:为没有指定自定义属性的节点分配索引require:为具有所有指定自定义属性的节点分配索引
elasticsearch.yml中自定义属性# 节点增加属性,在elasticsearch.yml里面 node.attr.{attribute}: {value} # 例如:增加一个node_type属性 node.attr.node_type: hot # 索引分配过滤器设置 index.routing.allocation.include.{attribute} index.routing.allocation.exclude.{attribute} index.routing.allocation.require.{attribute} -
Migrate可应用阶段:
Warm,Cold通过更新
index.routing.allocation.include._tier_preference设置,将索引移动到当前阶段对应的数据层ILM自动的在
Warm和Cold阶段开启该操作,如果我们不想自动开启可以通过设置enabled为false来关闭- 如果在
Cold阶段定义了一个可搜索的快照(Searchable snapshot)动作,那么将不会自动注入Migrate操作,因为Migrate与Searchable snapshot使用相同的index.routing.allocation.include._tier_preference设置 - 在
Warm阶段,Migrate操作会设置index.routing.allocation.include._tier_preference为data_warm,data_hot。意思就是这会将索引移动到Warm层的节点上,如果Warm层没有,那就返回到Hot层节点 - 在
Cold阶段,Migrate操作会设置index.routing.allocation.include._tier_preference为data_cold,data_warm,data_hot。这会将索引移动到Cold层,如果Cold层没有返回到Warm层,如果还没有可用的节点,返回到Hot层 - 在
Frozen阶段不允许迁移操作,Migrate操作会设置index.routing.allocation.include._tier_preference为data_frozen,data_cold,data_warm,data_hot。冻结阶段直接使用此配置挂载可搜索的镜像,这会将索引移动到(frozen)冻结层,如果冻结层没有节点,它会返回Cold层,依次是Warm层,Hot层 - 在
Hot阶段是不被允许迁移操作的,初始的索引分配是自动执行的,我们也可以通过索引模版配置
该阶段可选的配置参数如下
enabled:可选布尔值,控制ILM是否在此阶段迁移索引,默认true
- 如果在
-
Wait for snapshot可应用阶段:
Delete在删除索引之前等待指定的
SLM策略执行,这样可以确保已删除索引的快照是可用的policy:必须的字符串参数,删除操作应等待的SLM策略的名称
-
Delete可应用阶段:
Delete永久的删除索引
delete_searchable_snapshot:删除在上一个阶段创建的可搜索快照,默认true
ILM可以很轻松的管理索引的各个阶段,常见的就是处理日志类型或者度量值等时间序列的数据
需要注意的是,ILM要生效的前提是集群中所有的节点都必须是使用相同的版本。虽说可以在混合版本汇中创建或者应用ILM,但是不能保证ILM按照预期的策略执行
下面我们就详细说一下索引生命周期的几个阶段
Hot:频繁的查询、更新Warm:索引不在被更新、但是还有查询Cold:索引不在被更新、但是还有少量查询,索引的内容仍然需要被检索、检索的速度快慢没关系Frozen:索引不在被更新、但是还有少量查询,索引的内容仍然需要被检索、检索的速度非常慢也没关系Delete:索引不在需要,可以安全的删除
在上面的这几个阶段中,每个阶段的执行操作是不同的以及从一个阶段转到另一个阶段的时间也是不固定的
| 操作 | Hot | Warm | Cold | Frozen | Delete |
|---|---|---|---|---|---|
Set Priority | ✓ | ✓ | ✓ | ||
Unfollow | ✓ | ✓ | ✓ | ✓ | |
Rollover | ✓ | ||||
Read-only | ✓ | ✓ | ✓ | ||
Shrink | ✓ | ✓ | |||
Force merge | ✓ | ✓ | |||
Searchable snapshot | ✓ | ✓ | ✓ | ||
Allocate | ✓ | ✓ | |||
Migrate | ✓ | ✓ | |||
Wait for snapshot | ✓ | ||||
Delete | ✓ |
通过上面的学习我们知道了ILM相关的基本概念,下面我们进入实操环节,首先ILM策略的使用可以直接绑定索引,也可以在索引模版创建时绑定使用,下面跟我一起来操作起来吧
环境信息
Docker 部署,yml文件中具体映射文件地址自行修改,可以替换D:\zuiyuftp\docker\es8.1\为自己本地文件路径
需要注意的是,ES三个节点指定不同的自定义属性
// eshot节点
node.attr.node_type=hot
// eswarm节点
node.attr.node_type=warm
// escold节点
node.attr.node_type=cold
windows docker启动中如遇到vm最大限制错误可使用如下命令修改
1、打开终端
wsl -d desktop
sysctl -w vm.max_map_count=262144
exit
-
docker-compose.ymlversion: '3.8' services: cerebro: image: lmenezes/cerebro:0.8.3 container_name: cerebro ports: - "9000:9000" command: - -Dhosts.0.host=http://eshot:9200 networks: - elastic kibana: image: docker.elastic.co/kibana/kibana:8.1.3 container_name: kibana environment: - I18N_LOCALE=zh-CN - XPACK_GRAPH_ENABLED=true - TIMELION_ENABLED=true - XPACK_MONITORING_COLLECTION_ENABLED="true" - ELASTICSEARCH_HOSTS=http://eshot:9200 ports: - "5601:5601" networks: - elastic eshot: image: elasticsearch:8.1.3 container_name: eshot environment: - node.name=eshot - cluster.name=es-docker-cluster - discovery.seed_hosts=eshot,eswarm,escold - cluster.initial_master_nodes=eshot,eswarm,escold - bootstrap.memory_lock=true - "ES_JAVA_OPTS=-Xms512m -Xmx512m" - xpack.security.enabled=false - node.attr.node_type=hot ulimits: memlock: soft: -1 hard: -1 volumes: - D:\zuiyuftp\docker\es8.1\eshot\data:/usr/share/elasticsearch/data - D:\zuiyuftp\docker\es8.1\eshot\logs:/usr/share/elasticsearch/logs ports: - 9200:9200 networks: - elastic eswarm: image: elasticsearch:8.1.3 container_name: eswarm environment: - node.name=eswarm - cluster.name=es-docker-cluster - discovery.seed_hosts=eshot,eswarm,escold - cluster.initial_master_nodes=eshot,eswarm,escold - bootstrap.memory_lock=true - "ES_JAVA_OPTS=-Xms512m -Xmx512m" - xpack.security.enabled=false - node.attr.node_type=warm ulimits: memlock: soft: -1 hard: -1 volumes: - D:\zuiyuftp\docker\es8.1\eswarm\data:/usr/share/elasticsearch/data - D:\zuiyuftp\docker\es8.1\eswarm\logs:/usr/share/elasticsearch/logs networks: - elastic escold: image: elasticsearch:8.1.3 container_name: escold environment: - node.name=escold - cluster.name=es-docker-cluster - discovery.seed_hosts=eshot,eswarm,escold - cluster.initial_master_nodes=eshot,eswarm,escold - bootstrap.memory_lock=true - "ES_JAVA_OPTS=-Xms512m -Xmx512m" - xpack.security.enabled=false - node.attr.node_type=cold ulimits: memlock: soft: -1 hard: -1 volumes: - D:\zuiyuftp\docker\es8.1\escold\data:/usr/share/elasticsearch/data - D:\zuiyuftp\docker\es8.1\escold\logs:/usr/share/elasticsearch/logs networks: - elastic networks: elastic: driver: bridge -
启动成功之后浏览器进入 http://host:5601 管理页面,输入
GET _cat/nodeattrs查看ES集群启动信息,返回如下所示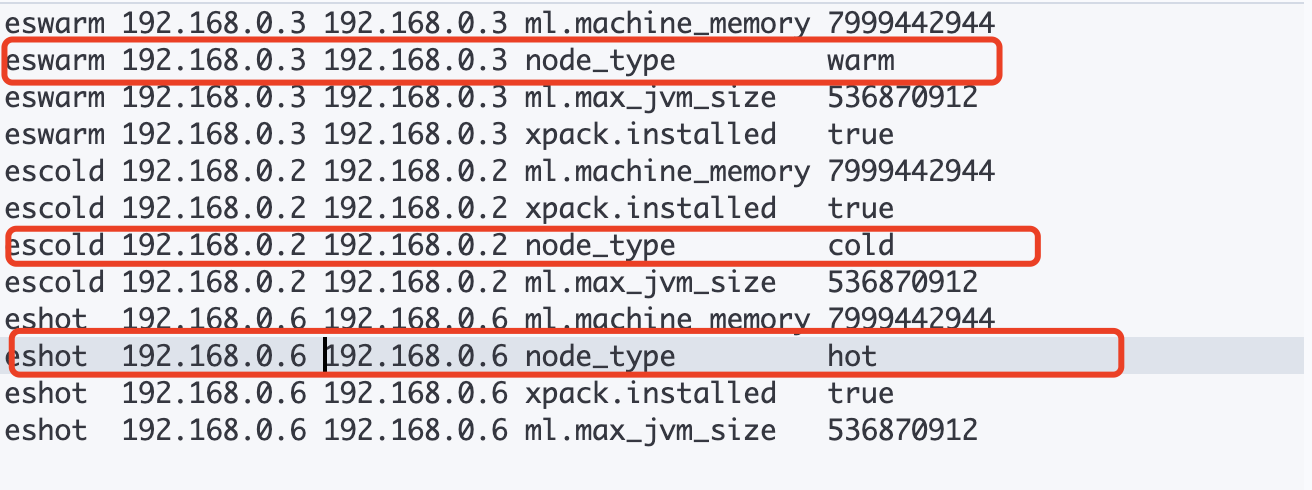
ILM验证
如果索引具有未分配的碎片,并且集群运行状况为黄色,则该索引仍然可以根据其索引生命周期管理策略过渡到下一阶段。然而,由于Elasticsearch只能在绿色集群上执行某些清理任务,因此可能会产生意想不到的副作用。
创建索引生命周期策略
-
打开Kibana,找到Stack Management页面打开

-
打开索引生命周期策略,点击创建策略

-
输入策略名称
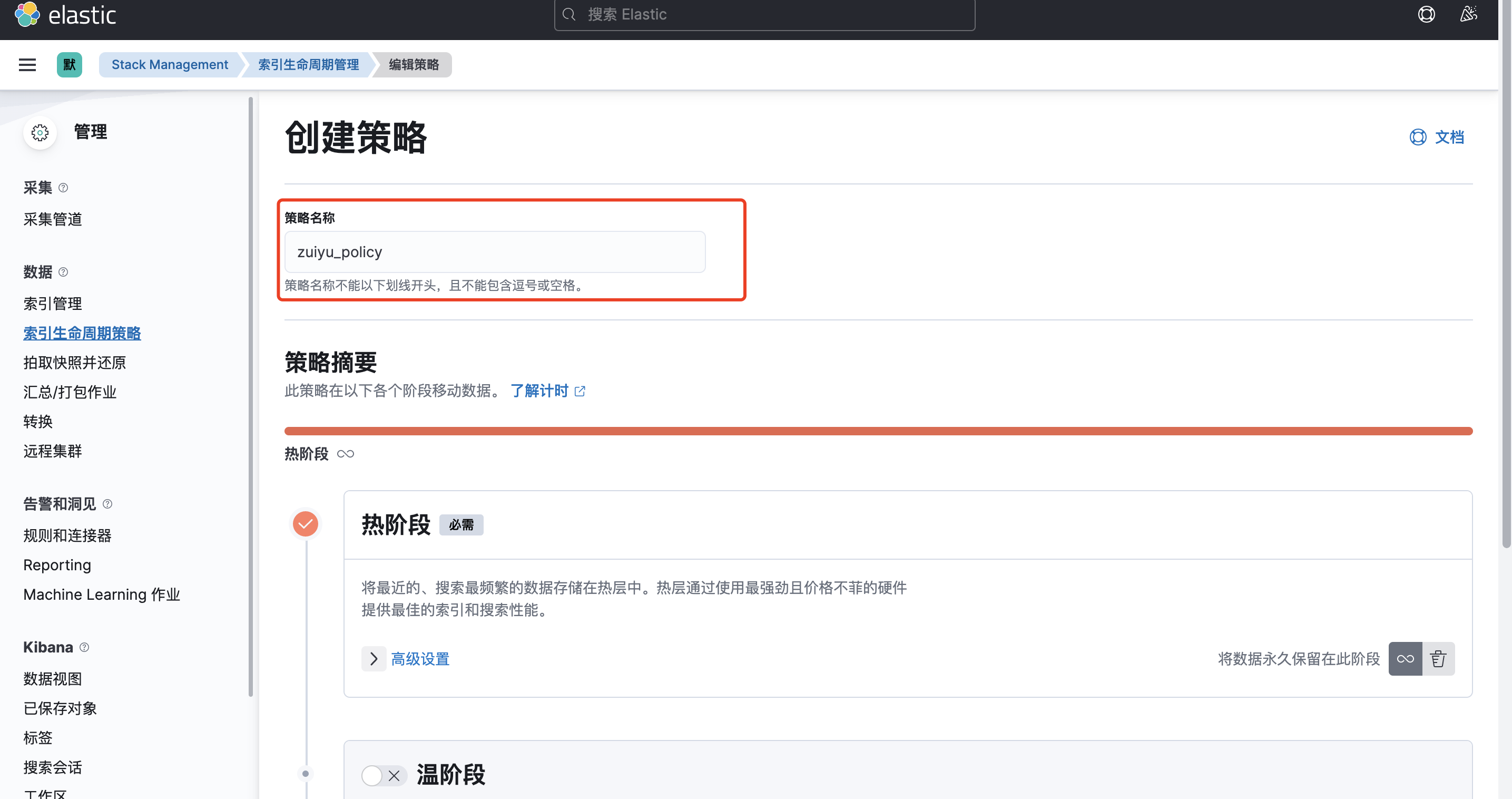
-
配置热阶段属性
关闭【使用建议的默认值】,配置文档数量最大为10个的时候发生滚动索引,其他暂不配置,如有需要可自行测试

-
配置热阶段索引优先级
100
-
点击温阶段开关,开启温阶段

-
配置为5分钟后移动到此阶段(实际使用根据自身场景设置,此处仅为测试)
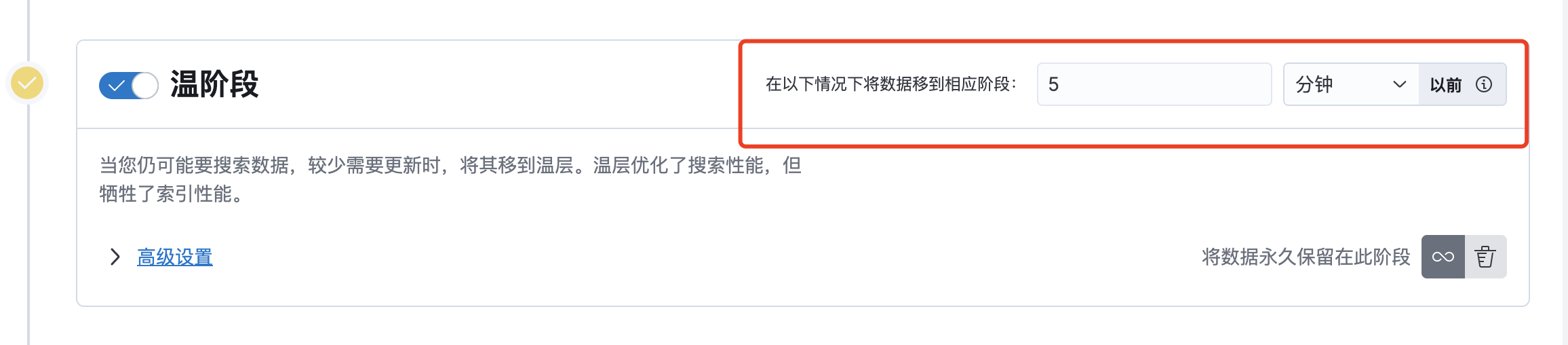
-
点击高级设置配置温阶段高级属性
-
配置缩小分片数量为
1

-
选中数据分配,配置为定制属性

-
选择节点属性为
warm节点
-
配置温阶段索引优先级
50
-
开启冷阶段

-
配置5分钟后移动到该阶段(实际使用根据自身场景设置,此处仅为测试)

- 与上一步
warm节点类似,冷阶段数据分配选择cold节点

-
配置冷阶段索引优先级
0
-
开启删除阶段
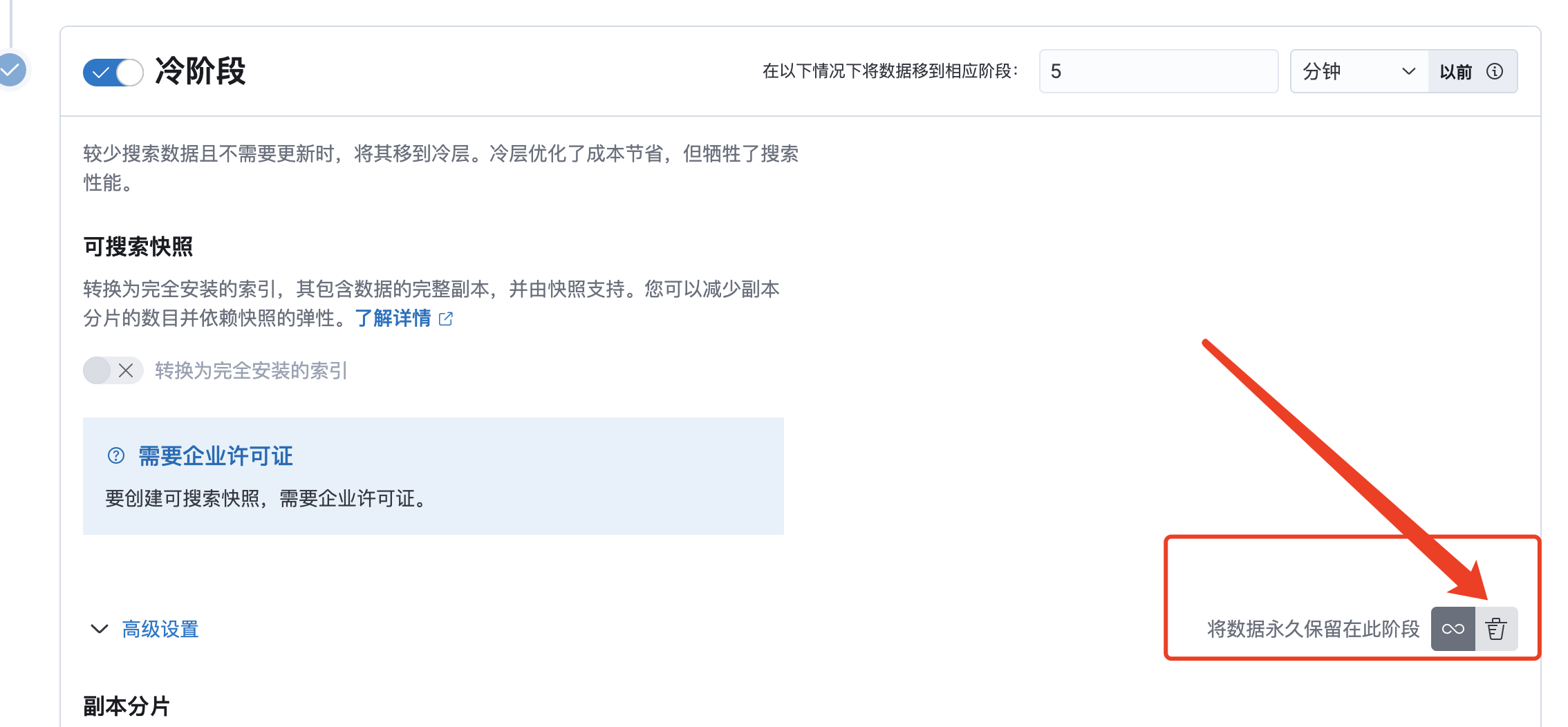
-
设置
一天之后索引删除
-
保存策略

到此、一个完整的索引生命周期策略就创建完成了,以上我们只是做测试,具体数值使用中还是要根据实际场景设置,上面演示了一个完整的索引生命周期,下面是使用语句创建,也就是上面我们图形化创建的东西使用API创建
-
使用API创建ILM
PUT _ilm/policy/zuiyu_policy { "policy": { "phases": { "hot": { "actions": { "rollover": { "max_docs": 10 }, "set_priority": { "priority": 100 } }, "min_age": "0ms" }, "warm": { "min_age": "5m", "actions": { "shrink": { "number_of_shards": 1 }, "set_priority": { "priority": 50 }, "allocate": { "require": { "node_type": "warm" } } } }, "cold": { "min_age": "5m", "actions": { "set_priority": { "priority": 0 }, "allocate": { "require": { "node_type": "cold" } } } }, "delete": { "min_age": "1d", "actions": { "delete": {} } } } } }
创建索引模版
指定分片数量为3,副本分片为0,生命周期策略为zuiyu_policy,rollover操作时别名为zuiyu-index,索引分配策略为 "node_type":"hot",匹配索引模式为zuiyu-开头的索引名
PUT _index_template/zuiyu_template
{
"index_patterns": ["zuiyu-*"],
"template":{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 0,
"index.lifecycle.name": "zuiyu_policy",
"index.lifecycle.rollover_alias": "zuiyu-index" ,
"index.routing.allocation.require.node_type":"hot"
}
}
}
创建测试索引
分片数量3,索引别名zuiyu-index
PUT zuiyu-000001
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 0
},
"aliases": {
"zuiyu-index": {}
}
}
查看分片分布可以看到,所有的分片都按照分配策略分不到了hot节点上,访问cerebro可看到如下(http://host:9000)

插入测试文档
连续执行多次,大于10次即可
POST zuiyu-index/_doc
{
"id":"zuiyu index",
"content":"ilm alias insert content"
}
查看文档数量
GET zuiyu-index/_count
// 返回结果如下
{
"count" : 21,
"_shards" : {
"total" : 3,
"successful" : 3,
"skipped" : 0,
"failed" : 0
}
}
我在上面插入了21条数据,按照刚才我们定义的ILM,在文档数量大于10个的时候会发生rollover操作,滚动生成一个新的索引(具体索引名规则、不生效约束查看前文rollover小节)
验证ILM策略
- 打开Kibana,找到定义的
zuiyu_policy策略

- 找到索引管理,点击生成的索引
zuiyu-000001

- 弹出的页面中我们可以清晰的看到当前索引的相关信息,此时处于
hot阶段

ILM策略刷新的时间默认是10分钟(并不是固定10分钟,哪怕我们设置为10分钟也可能20分钟才能执行,甚至可能赶巧的话马上就执行也说不准),我们可以通过如下API进行修改为10s测试,也可以等待ILM自动执行
官网的说明如下
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/ilm-index-lifecycle.html
PUT _cluster/settings
{
"transient": {
"indices.lifecycle.poll_interval": "10s"
}
}
- 等待10多分钟之后,索引
zuiyu-000002生成,此时索引zuiyu-000001与zuiyu-000002都在hot节点
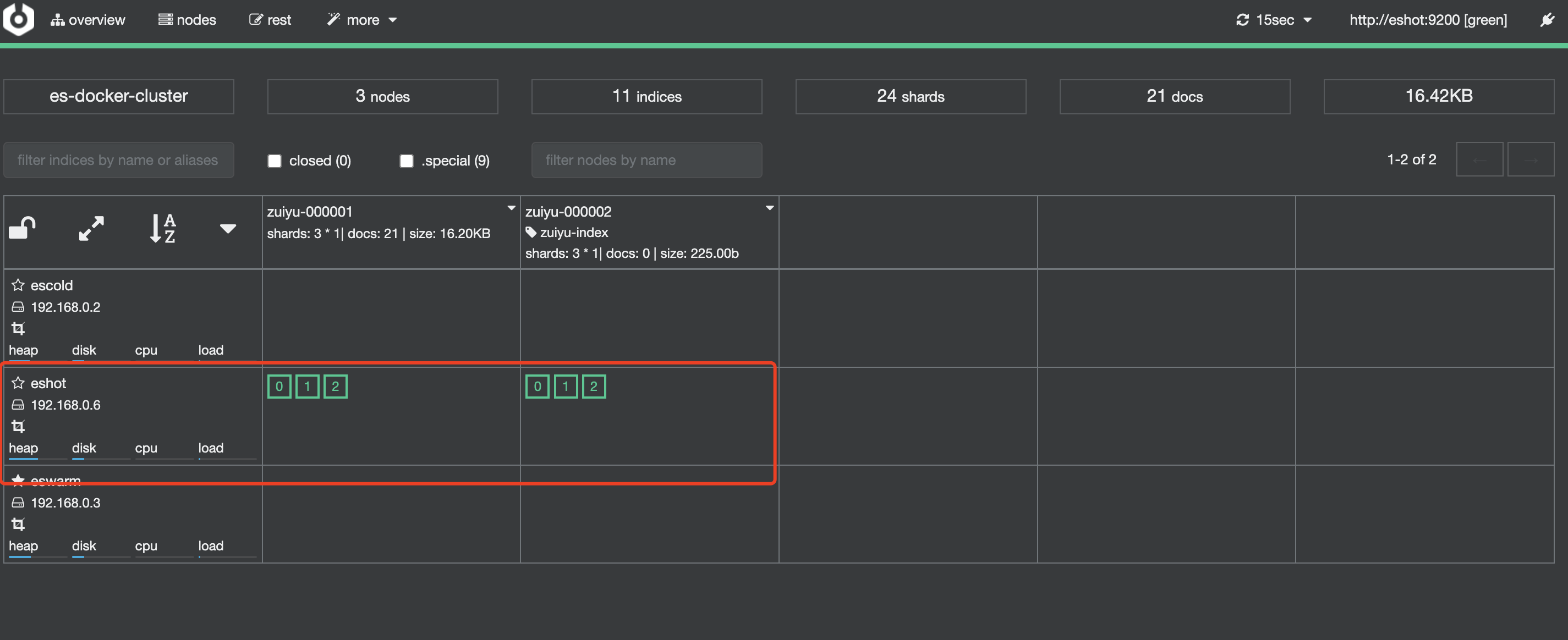
- 继续等待约
10分钟,此时发现zuiyu-000001节点已经移动到了warm节点上

- 我们呢此时也可以通过Kibana查看ILM执行情况,也可以看到执行该操作的时间,如下

- 继续等待约
10分钟,索引zuiyu-000001已经减少分片数量为1,并且移动到节点cold上了

按照上面ILM策略执行的话,我们当时定义的是一天之后删除,也就是24小时之后,移动到cold节点上的索引就会被删除,这个大家可以自行验证一下,这边就不演示了,不过我本地是测试成功过的
我们还可以通过创建索引时直接绑定索引生命周期策略,API如下,测试就不测试了,感兴趣的自己下面测试下吧
注意测试时别与上面的索引模版冲突覆盖了哦
PUT zy-index-000001
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 0,
"index.lifecycle.name": "zuiyu_policy",
"index.lifecycle.rollover_alias": "zy-index" ,
"index.routing.allocation.require.node_type":"hot"
},
"aliases": {
"zy-index": {}
}
}
上面我们测试了通过索引模版创建索引,并且应用索引生命周期策略,下面来测试一下数据流索引,与索引模版的类似,首先还是创建一个数据流模版
创建数据流模版
该模版会匹配zyds-开头的,匹配为数据流索引,创建的分片数量为3,应用刚才我们创建的ILM策略,路由分片到hot节点
PUT _index_template/zyds_template
{
"index_patterns": ["zyds-*"],
"data_stream": {},
"priority": 200,
"template": {
"settings": {
"number_of_shards": 3,
"number_of_replicas":0,
"index.lifecycle.name": "zuiyu_policy",
"index.routing.allocation.require.node_type": "hot"
}
}
}
创建数据流索引
PUT _data_stream/zyds-stream
查看生成的数据流索引
此时我们在cerebro页面输入zyds进行过滤,并且勾选special,可以看到生成的数据流也是在hot节点上

验证数据流ILM策略
-
定义一个pipeline,方便插入数据到数据流使用,作用是生成字段
@timestampPUT _ingest/pipeline/add-timestamp { "processors": [ { "set": { "field": "@timestamp", "value": "{{_ingest.timestamp}}" } } ] } -
添加测试数据
点击多次,大于
10即可,此处我点了19次,生成了19个文档,也是可以触发ILM策略的POST zyds-stream/_doc?pipeline=add-timestamp { "user": { "id": "zuiyu", "name":"鱼" }, "message": "zuiyu is successful!" }

-
等待约10分钟,文档数量大于10,发生滚动策略,生成新索引
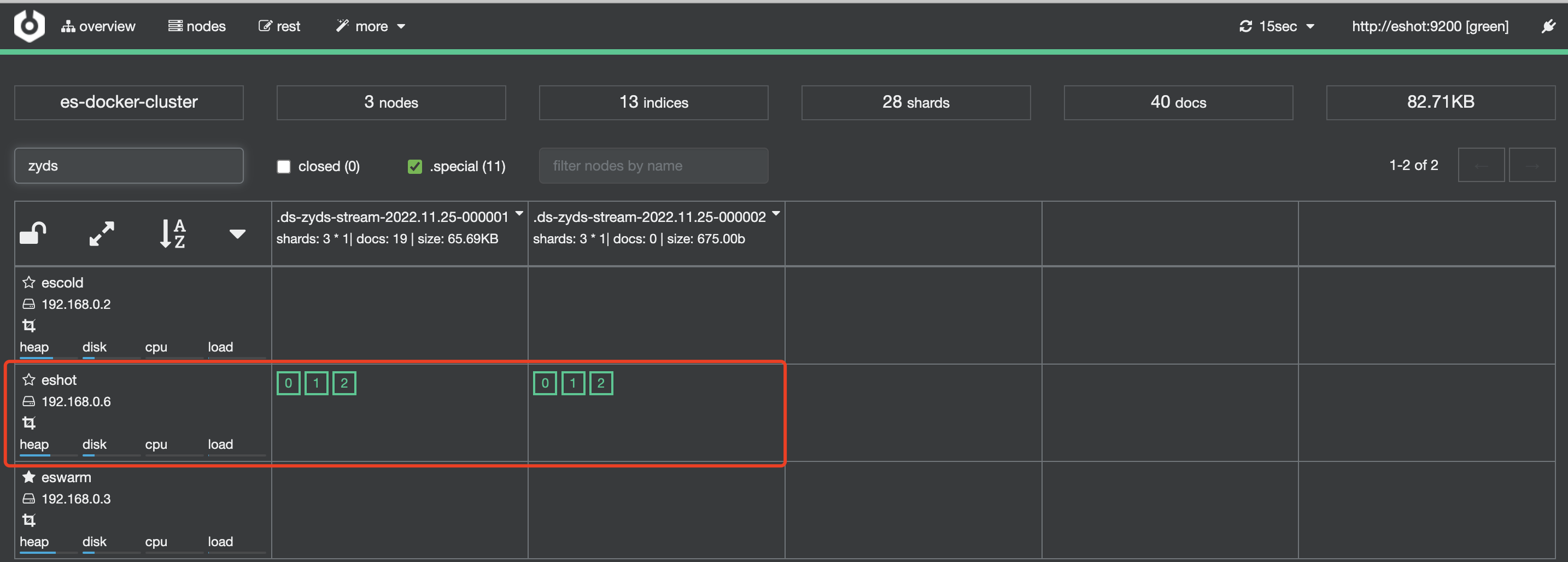
-
等待约
10分钟,第一个索引已经从hot节点数据移动到warm节点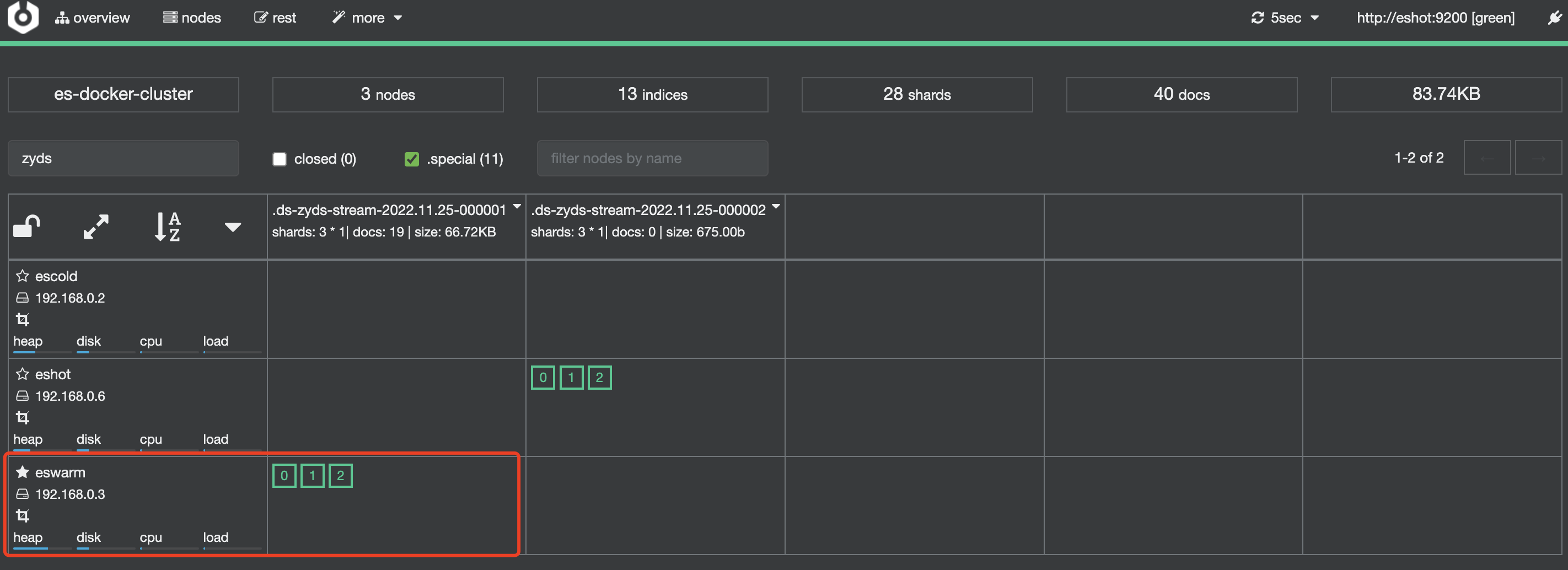
-
继续等待约
10分钟,分片减少为1个后面就不演示了,相信大家也看到了,本篇文章耗时巨长了,感觉写的还不错的可以点赞分享哦
总结
通过上面的学习我们学会了ILM期间的各种操作,并且实操了索引模版,数据流模版使用索引生命周期策略的例子,相信大家看完本篇文章也有一定的收获,毕竟我可以非常自信的说的是,看完本篇文章,你可能不会很精通ILM,但是ILM入门你绝对可以
参考链接
ILM:https://www.elastic.co/guide/en/elasticsearch/reference/8.1/index-lifecycle-management.html








![[附源码]java毕业设计在线二手车交易信息管理系统](https://img-blog.csdnimg.cn/06da7ba9f0464ec9bdc8344f25b001d9.png)