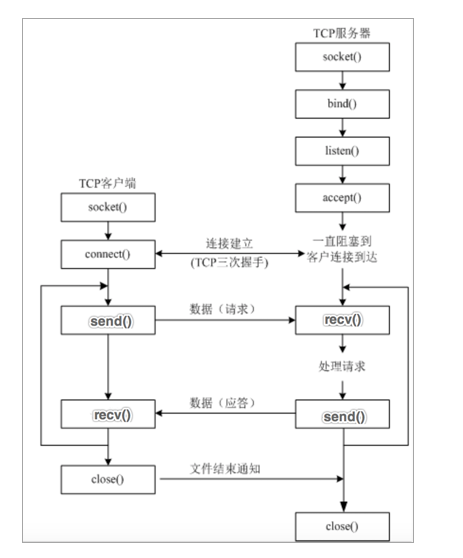
本文将以通俗易懂的方式,深入浅出地为您揭开深度学习模型构建与训练的面纱:
深度学习 = 数据 d a t a + 模型 m o d e l + 损失函数 l o s s + 优化 o p t i m i z e r + 可视化 v i s u a l i z e r 深度学习 = 数据data + 模型model + 损失函数loss + 优化optimizer + 可视化visualizer 深度学习=数据data+模型model+损失函数loss+优化optimizer+可视化visualizer
深入浅出深度学习Pytroch
- 1 数据——智慧的源泉
- 1.1 数据划分
- 1.2 数据索引txt
- 1.3 Dataset
- 1.3 Datalorder
- 1.4 数据增强
- 2 模型——拼积木的游戏
- 2.1 模型搭建
- 2.2 模型微调Finetune
- 2.3 参数组
- 3.损失函数——惩罚的艺术
- 3.1 L1 loss
- 3.2 MSE Loss
- 3.3 CrossEntropy Loss
- 3.4 NLLLoss
- 3.5 KLDivLoss
- 3.6 SmoothL1Loss
- 3.7 TripletMarginLoss
- 4. 优化器——下山的路
- 4.1 参数组(param_groups)
- 4.2 Optimizer基本方法
- 4.3 优化器分类
- 4.3.1 torch.optim.SGD
- 4.3.2 torch.optim.Adam(AMSGrad)
- 4.3.3 torch.optim.Adamax
- 4.3.4 torch.optim.ASGD
- 4.4 学习率调整策略
- 4.4.1 lr_scheduler.StepLR
- 4.2.2 lr_scheduler.MultiStepLR
- 4.2.3 lr_scheduler.ExponentialLR
- 4.2.4 lr_scheduler.CosineAnnealingLR
- 4.2.5 lr_scheduler.ReduceLROnPlateau
- 4.2.6 lr_scheduler.LambdaLR
- 5 可视化——深度学习可解释性
- 5.1 Grad-CAM(热图)
- 5.2 混淆矩阵及其可视化
- 5.3 特征图可视化
- 5.4 TensorBoardX
- 5.5 卷积核可视化
- 5.6 梯度及权值分布可视化
1 数据——智慧的源泉
数据,也叫知识库,深度学习模型从知识知识库中学习任务的一般规律(权重参数),常见数据格式有图像(cv)、文本(nlp)、音频(ar)、传统特征数据(ml)…
纠其共性,在深度学习中都会被张量化(tensor),如图像的pixel本身就是数值矩阵,文本数据会经过分词、词嵌入等操作变成词向量矩阵,音频和传统数据更是如此。
在深度学习中无非就是准备好数据集,进行数据预处理,方便输入模型,然后划分成训练集、验证集、测试集,接着在训练过程中,使用Datalorder和Dataset兄弟俩,读入数据并transforme张量化,最后输入模型,迭代优化训练。
因为笔者更了解CV领域,所以接下来将针对图像进行讲解。
1.1 数据划分
原始数据集将被划分为:训练集(train set)、验证集(valid set)、测试集(test set)
初学者千万不要搞混验证集和测试集!
训练集:顾名思义用来训练模型参数(关键是迭代优化params)
验证集:验证集用于模型选择和调整超参数(如早停法选择epoch)
测试集:测试集用来在实际应用中估计模型的泛化能力(作为论文中的指标值)
工程应用中:先将原始数据集划分为早期训练集(包含训练集和验证集)和测试集,验证集应该是从早期训练集里再划分出来的一部分作为验证集(2:8),用来选择模型和调参的。当调好之后,再用测试集对该模型进行泛化性能的评估,如果性能OK,再把测试集输入到模型中训练,最终得到的模型就是提交给用户的模型。
原始数据集划分方法: 原始数据集->早期训练集、测试集
留出法(hold-out)。直接按比例进行互斥划分,其实这种方法在国内教材和论文中最常见,就是把数据集D划分为两个互斥的集合,其中一个是训练集,一个是测试集。书中给出的参考划分比例是,训练集占比2/3~4/5。
交叉验证法(cross validation)。交叉验证法是竞赛中或者比较正式的实验中用得比较多。什么是交叉验证呢? 其实就是将数据集D划分为k个大小相同的互斥的子集,然后用k-1个子集作为训练,剩下那一个子集作为测试。这样就需要训练k个模型,得到k个结果,再取平均即可。这样的方法通常成为“k折交叉验证”。书中还给出了k的参考值,:5,10,20。
自助法(bootstrapping) 。第一次听说自助法,也从没在文献中看到过,自助法主要是用于小样本!缺点是容易引入估计偏差。具体操作是这样的,对于m个样本的数据集D,每次随机挑选D中的一个样本放到D’中(有放回),挑m次,经过计算D中有大约36.8%(≈1/e)的样本未出现在D’中,这样用D’作为训练集,D\D’(“\”表示集合减法)作为测试集。自助法又称为可重复采样,有放回采样。
留一交叉验证法(Leave-One-Out简称LOO)(cross validation 的特例):假设数据集D包含m个样本,令k=m,显然留一发不再受随机样本划分方式的影响,因为留一法的训练数据集只比D少一个样本,训练出的模型与用D训练出的模型很相似,且评估结果也是测试了数据集D中所有的样本取得平均值,因此留一法的评估结果往往比较准确。但是留一法也有一个很大的缺陷就是计算量太大了, 若D有一百万个样本那么就需要训练一百万个模型。
1.2 数据索引txt
生成图像数据索引txt文件:整个操作就是读取data路径下train和test文件夹的图片绝对路径abs_path + 标签label,保存到 txt 文件中,每行为一个图片样本的信息。分别生成train.txt和test.txt,方便Dataset中转换为list,按照索引index读取数据样本。
(txt 中的路径:是以训练时的那个 py 文件所在的目录为工作目录,所以这里需要提前算好相对路径!)
1.3 Dataset
pytorch所有的自定义Datasets 都需要继承它,需要重写__init__()、__getitem__()和__len__() 这3个函数:
init():打开保存txt文件中每个样本的路径和标签(一般为“路径, label”,从数据集.txt的每行读取),完成 txt -> img_list 和 label_list 的转换。
getitem():输入数据集的index,根据index查找img_list 路径,利用 Image.open 打开图片对象,并转换为RGB,并对其进行transform(数据增强),按index查找label,返回list中index对应的图片数据+label
len():返回数据集长度,即图像样本个数len(img_list)
Dataset读样本(图片+标签)的流程:init()中.txt -> list -> getitem()中取index, 返回对应的图片+label->返回给datalorder
class MyDataset(Dataset):
# 自己的Dataset除了有init(),还要重载len()和getitem()函数
# init()打开保存txt文件中每个样本的路径和标签
def __init__(self, txt_path, transform=None, target_transform=None):
fh = open(txt_path, 'r')
imgs = [] # 存储.txt每行样本路径和标签的list
for line in fh:
line = line.rstrip()
words = line.split()
imgs.append((words[0], int(words[1])))
self.imgs = imgs # 最主要就是要生成这个list, 然后DataLoader中给index,通过getitem读取图片数据
self.transform = transform
self.target_transform = target_transform
# getitem()输入数据集的index(一般为“路径, label”,从数据集.txt的每行读取),返回返回图片数据+label
def __getitem__(self, index):
# 然后DataLoader中给index=[路径,label],返回[经过transform的tensor图像,label]
fn, label = self.imgs[index]
img = Image.open(fn).convert('RGB') # 像素值 0~255,在transfrom.totensor会除以255,使像素值变成 0~1
if self.transform is not None:
img = self.transform(img) # 在这里做transform,转为tensor等等
return img, label
# len()返回数据集长度
def __len__(self):
return len(self.imgs)
[注意]:从 MyDataset()类中 __getitem__()函数中, PyTorch 做数据增强的方法是在原始图片上进行的,并覆盖原始图片。且图片通过 Image.open()函数读取进来时,图片的Channel维度的通道顺序(RGB ? BGR ?)、图片维度顺序是( w* h* c ? c* w* h ?)、像素值范围([0-1] or [0-255] ?)
1.3 Datalorder
前面的Dataset仅为静态类,即使实例化Dataset,图像数据依然保存在硬盘,__init__()函数只会在内存创建两个list(保存图片路径和标签)。
想要在训练过程中(main.py),触发 Dataset 去读取图片及其标签,则需要使用 DataLoder:
- main.py:
train_data = MyDataset(txt_path=train_txt_path, ...)—>
(实例化Dataset,实例中包含路径list和标签list)- main.py:
train_loader = DataLoader(dataset=train_data, ...)—>
(实例化DataLoader,传入Dataset,使其拥有路径和标签)- main.py:
for i, data in enumerate(train_loader, 0)—>
(遍历可迭代对象DataLoader)- dataloder.py:
class DataLoader(): def __iter__(self): return _DataLoaderIter(self)—>
(调用DataLoader的__iter__()方法,再调用 _DataLoderIter()类)- dataloder.py:
class _DataLoderIter(): def __next__(self): batch = self.collate_fn([self.dataset[i] for i in indices])—>
(在 _ DataLoderiter()类中会跳到__next__()函数,获取一个 batch 的 indices list,如batch_size=3,则indices可能=[0,1,2],再调用self.collate_fn()获取indices list中对应的一个 batch大小的图片和标签,self.collate_fn 用来将img和label拼接成一个 batch。一个 batch 是一个 list,有两个元素,第一个元素是图片数据,是一个4D 的 Tensor,shape 为(B=64,C=3,W=32,H=32),第二个元素是标签 shape 为(64))- tool.py:
class MyDataset(): def __getitem__(): img = Image.open(fn).convert('RGB')—>
(在self.collate_fn()内部会调用MyDataset的__getitem__()返回图像和标签)- tool.py:
class MyDataset(): img = self.transform(img)—>
(getitem()内部会调用transform进行数据增强)- main.py:
inputs, labels = data inputs, labels = Variable(inputs), Variable(labels) outputs = net(inputs)
(tensor不能反向传播,variable可以反向传播,所以将图片数据Tensor转换成 Variable 类型,即为模型真正的输入)
- 将图像img数据从 path_txt -> path_list -> Image -> Tensor -> Variable
- 将标签label数据从 path_txt -> path_list -> Tensor -> Variable
1.4 数据增强
MyDataset()类中 __getitem__()函数中的transform()操作:对读入的图像数据做变换(预处理),并覆盖原图。
包括:数据标准化Normalize(减均值,再除以标准差),随机裁剪RandomCrop,随机旋转RandomRotation,大小变换resize,填充Pad,转为张量ToTensor等。
normMean和normStd的计算方法:随机挑选CNum张图片,先将像素从0~255归一化至 0-1 ,再进行按通道计算均值mean和标准差std
train_txt_path = os.path.join("..", "..", "Data/train.txt")
CNum = 2000 # 挑选多少图片进行计算
img_h, img_w = 32, 32
imgs = np.zeros([img_w, img_h, 3, 1])
means, stdevs = [], []
with open(train_txt_path, 'r') as f:
lines = f.readlines()
random.shuffle(lines) # shuffle , 随机挑选图片
for i in range(CNum):
img_path = lines[i].rstrip().split()[0]
img = cv2.imread(img_path)
img = cv2.resize(img, (img_h, img_w))
img = img[:, :, :, np.newaxis]
imgs = np.concatenate((imgs, img), axis=3)
print(i)
imgs = imgs.astype(np.float32)/255.
for i in range(3):
pixels = imgs[:,:,i,:].ravel() # 拉成一行
means.append(np.mean(pixels))
stdevs.append(np.std(pixels))
means.reverse() # BGR --> RGB
stdevs.reverse()
print("normMean = {}".format(means))
print("normStd = {}".format(stdevs))
print('transforms.Normalize(normMean = {}, normStd = {})'.format(means, stdevs))
得到normMean 和 normStd 之后,便可将其做完transform.py的参数,构造transform()
注意操作顺序:1. 随机裁剪/旋转/镜像..., 2. Totensor, 3. 数据标准化(减均值,除以标准差)
# 设置均值,标准差,以通道为单位,进行数据标准化
normMean = [0.4948052, 0.48568845, 0.44682974]
normStd = [0.24580306, 0.24236229, 0.2603115]
normTransform = transforms.Normalize(normMean, normStd)
# transforms.Compose将所需要进行的处理给集成Compose起来
# 训练集数据增强,(其他变换 + ToTensor + normTransform)
trainTransform = transforms.Compose([
transforms.Resize(32),
transforms.RandomCrop(32, padding=4),
transforms.ToTensor(),
normTransform
])
# 验证集数据增强,(ToTensor + normTransform)
validTransform = transforms.Compose([
transforms.ToTensor(),
normTransform
])
[注意]:在进行 Normalize 时,需要设置均值和方差,在这里直接给出了,但在实际应用中是要去训练集中计算的,使用第一个代码块。
2 模型——拼积木的游戏
Pytorch将常用的神经网络层封装为标准模块,通过简单的连接,就可以轻松构建复杂的深度神经网络模型,本质和搭积木没有区别,关键是将模块与模块衔接处的tensor维度对应好。
2.1 模型搭建
必须继承 nn.Module 这个类,需要重写__init__(),forward(),initialize_weights()这3个函数:
__init__(self):定义需要的“积木组件"(如 conv、pooling、Linear、BatchNorm 等,从torch.nn或 torch.nn.functional 中获取)。forward(self, x):用定义好的“组件”进行组装,就像搭积木,把网络结构搭建出来,这样一个模型就定义好了,实例化一个模型 net = Net(),然后把输入 inputs 扔进去,outputs = net(inputs),就可以使用forward()得到输出 outputs。initialize_weights(self):进行权重参数初始化,初始化方法会直接影响到模型的收敛与否,设定什么层用什么初始化方法,常用初始化方法在 torch.nn.init 中给出,如Xavier,kaiming,normal_,uniform_等。
[注意]:对于复杂模型,可以使用torch.nn.Sequential()来按先后顺序包裹多个组件构建复杂模块,也可以在class Net中构建一个_make_layer()函数来构建复杂模块,也可以单独创建一个class Block构建复杂模块。
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool1(F.relu(self.conv1(x)))
x = self.pool2(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# 定义权值初始化
def initialize_weights(self):
for m in self.modules():
# 卷积层xavier_normal_初始化
if isinstance(m, nn.Conv2d):
torch.nn.init.xavier_normal_(m.weight.data)
if m.bias is not None:
m.bias.data.zero_()
# BN层填充1初始化
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
# FC层normal_初始化
elif isinstance(m, nn.Linear):
torch.nn.init.normal_(m.weight.data, 0, 0.01)
m.bias.data.zero_()
2.2 模型微调Finetune
模型微调其实是上一节模型初始化方式的一种,我们知道一个良好的权值初始化,可以使收敛速度加快,甚至可以获得更好的精度。
模型初始化包括两种: ①PyTorch 自带的权值初始化方法(上节),②迁移学习(微调):采用一个已经训练模型的模型的权值参数作为我们模型的初始化参数。
Finetune操作分为6步:
第一步:保存/下载训练好的模型参数,拥有一个预训练模型文件.pkl;
torch.save(net.state_dict(), 'net_params.pkl')
第二步:加载模型,把预训练模型中的权值取出来;
pretrained_dict = torch.load('net_params.pkl')
第三步:创建自己的模型,并且获取新模型的参数字典 net_state_dict:
net = Net() # 创建 net
net_state_dict = net.state_dict() # 获取已创建 net 的 state_dict
第四步:接着将 pretrained_dict 里不属于 net_state_dict 的键剔除掉:
pretrained_dict_1 = {k: v for k, v in pretrained_dict.items() if k in net_state_dict}
第五步:用预训练模型的参数字典 对 新模型的参数字典 net_state_dict 进行更新:
net_state_dict.update(pretrained_dict_1)
第六步:将更新了参数的字典 “放”回到网络中:
net.load_state_dict(net_state_dict)
[注意]:采用 finetune 的训练过程中,有时候使用冻结训练,即前50个epoch(冻结),将前面层的梯度设0(param.requires_grad = False),后面层的梯度正常(param.requires_grad = True)。后150个epoch(解冻),将前面层的梯度恢复正常(param.requires_grad = True)。这时就需要对不同的层设置不同的学习率。
# 冻结阶段训练参数,learning_rate和batch_size可以设置大一点
Init_Epoch = 0
Freeze_Epoch = 50
Freeze_batch_size = 8
Freeze_lr = 1e-3
# 解冻阶段训练参数,learning_rate和batch_size设置小一点
UnFreeze_Epoch = 100
Unfreeze_batch_size = 4
Unfreeze_lr = 1e-4
# 可以加一个变量控制是否进行冻结训练
Freeze_Train = True
# 冻结
batch_size = Freeze_batch_size
lr = Freeze_lr
start_epoch = Init_Epoch
end_epoch = Freeze_Epoch
if Freeze_Train:
for param in model.backbone.parameters():
param.requires_grad = False
# 解冻
batch_size = Unfreeze_batch_size
lr = Unfreeze_lr
start_epoch = Freeze_Epoch
end_epoch = UnFreeze_Epoch
if Freeze_Train:
for param in model.backbone.parameters():
param.requires_grad = True
2.3 参数组
为不同层设置不同超参数:通过优化器对多个参数组进行设置不同的超参数(lr等),只需要将原始的参数组,划分成两个,甚至更多的参数组,然后分别进行设置学习率等超参数。
这里将原始参数“切分”成 fc3 层参数(net.fc3.parameters()) 和 其余参数(net.parameters() - net.fc3.parameters())。挑选出特定的层的机制是利用内存地址作为过滤条件,将需要单独设定的那部分参数,从总的参数中剔除。
# fc3参数的内存地址!
ignored_params = list(map(id, net.fc3.parameters())) # 返回的是fc3的parameters的 内存地址
# 剩余部分的参数!(总的-fc3的)
base_params = filter(lambda p: id(p) not in ignored_params, net.parameters())
# 分别在优化器optimizer中设置超参数
optimizer = optim.SGD([
{'params': base_params, 'lr': 0.000001},
{'params': net.fc3.parameters(), 'lr': 0.001*10}], 0.001, momentum=0.9, weight_decay=1e-4)
3.损失函数——惩罚的艺术
一般来说损失函数值越大,说明模型学习的越不好,所以我们要根据loss值,对模型进行惩罚,调整让它们朝着正确的方向调整。这就像小时侯我们做了错事,父母不断地惩罚鞭策我们,让我们朝着正确的方向成长一样。loss函数就是对我们做事情好坏的衡量标准。
Loss种类繁多,根据不同任务,还可以自行组合设计,这里我们只讲解几种常见的loss函数,更多类型可以在pytorch官网查阅学习。
3.1 L1 loss
torch.nn.L1Loss(size_average=None, reduce=None)
L1损失也叫L1正则项惩罚,计算 output 和 target 之差的绝对值,可选返回同维度的 tensor 或者是一个标量。
3.2 MSE Loss
torch.nn.MSELoss(size_average=None, reduce=None, reduction='elementwise_mean')
均方差损失,计算 output 和 target 之差的平方,可选返回同维度的 tensor 或者是一个标量。
3.3 CrossEntropy Loss
torch.nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='elementwise_mean')
# weight(Tensor)- 为每个类别的 loss 设置权值,常用于类别不均衡问题
Pytorch版本的交叉熵损失,将输入经过 softmax 激活函数之后,再计算其与 target 的交叉熵损失。
-
CrossEntropyLoss将nn.LogSoftmax()和 nn.NLLLoss()进行了结合。
-
严格意义上的交叉熵损失函数应该是nn.NLLLoss()。
-
交叉熵损失(cross-entropy Loss) 又称为对数似然损失(Log-likelihood Loss)、对数损失;二分类时还可称之为逻辑斯谛回归损失(Logistic Loss)。交叉熵损失函数表达式为 L = - sigama(y_i * log(x_i))。
-
Pytroch 这里不是严格意义上的交叉熵损失函数,而是先将 input 经 过 softmax 激活函数,将向量“归一化”成概率形式,然后再与 target 计算严格意义上交叉熵损失。
-
在多分类任务中,经常采用 softmax 激活函数+交叉熵损失函数,因为交叉熵描述了两个概率分布的差异,然而神经网络输出的是向量,并不是概率分布的形式。所以需要 softmax激活函数将一个向量进行“归一化”成概率分布的形式,再采用交叉熵损失函数计算 loss。
-
output 不仅可以是向量,还可以是图片,即对图像进行像素点的分类,这个例子可以
从 NLLLoss()中看到,这在图像分割当中很有用。
3.4 NLLLoss
torch.nn.NLLLoss(weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='elementwise_mean')
真正的交叉熵损失,计算公式:loss(input, class) = -input[class]。举个例,三分类任务,input=[-1.233, 2.657, 0.534], 真实标签为 2(class=2),则 loss 为-0.534。就是对应类别上的输出,取一个负号!感觉被 NLLLoss 的名字欺骗了。
常用于多分类任务,但是 input 在输入 NLLLoss()之前,需要对 input 进行 log_softmax 函数
激活,即将 input 转换成概率分布的形式,并且取对数。其实这些步骤在 CrossEntropyLoss
中就有,如果不想让网络的最后一层是 log_softmax 层的话,就可以采用 CrossEntropyLoss
完全代替此函数。
3.5 KLDivLoss
torch.nn.KLDivLoss(size_average=None, reduce=None, reduction='elementwise_mean')
计算 input 和 target 之间的 KL 散度( Kullback–Leibler divergence),KL 散度( Kullback–Leibler divergence) 又称为相对熵(Relative Entropy),用于描述两个概率分布之间的差异。
- 从信息论角度观察三者,其关系为信息熵 = 交叉熵 - 相对熵。在机器学习中,当训练数
据固定,最小化相对熵 D(p||q) 等价于最小化交叉熵 H(p,q) 。
3.6 SmoothL1Loss
torch.nn.SmoothL1Loss(size_average=None, reduce=None, reduction='elementwise_mean')
平滑 L1 损失,属于 Huber Loss 中的一种(因为参数 δ 固定为 1 了),Huber Loss 常用于回归问题,其最大的特点是对离群点(outliers)、噪声不敏感,具有较强的鲁棒性。当误差绝对值小于 δ,采用 L2 损失;若大于 δ,采用 L1 损失。
3.7 TripletMarginLoss
torch.nn.TripletMarginLoss(margin=1.0, p=2, eps=1e-06, swap=False, size_average=None, reduce=None, reduction='elementwise_mean')
三元组损失,图像检索匹配(人脸验证,行人重识别)中常用。Anchor、Negative、Positive,目标是让 Positive 元和 Anchor 元之间的距离尽可能的小,Positive 元和 Negative 元之间的距离尽可能的大。
从公式上看,Anchor 元和 Positive 元之间的距离加上一个 threshold 之后,要小于Anchor 元与 Negative 元之间的距离。
4. 优化器——下山的路
优化器Optimizer 完成对不同的参数组设置不同的超参数,进行迭代调整权重参数。对于凸或非凸函数都可以沿梯度,进行调整,就像下山一样。
PyTorch 中所有的优化器(如:optim.Adadelta、optim.SGD、optim.RMSprop 等)均是Optimizer的子类。Optimizer 中定义了一些常用的方法,有 zero_grad()、step(closure)、state_dict()、load_state_dict(state_dict)和add_param_group(param_group)
4.1 参数组(param_groups)
之前在finetune中我们了解过param_groups这个概念,我们用它来不同层定制学习率。
optimizer 对参数的管理是基于组的概念,可以为每一组参数配置特定的超参数
lr,momentum,weight_decay 等等。
参数组在 optimizer 中表现为一个 list(self.param_groups),其中每个元素是
一个dict(表示一个参数及其相应配置),在 dict 中包含’params’、‘weight_decay’、‘lr’ 、
'momentum’等字段。
4.2 Optimizer基本方法
step(closure) 执行一步权值参数更新,
w
=
w
−
l
r
∗
g
r
a
d
w=w-lr*grad
w=w−lr∗grad, 其中可传入参数 closure(一个闭包)。如当采用二阶优化器 LBFGS时,需要多次计算,因此需要传入一个闭包去允许它们重新计算 loss
zero_grad() 将梯度清零。
state_dict() 获取模型当前的参数,以一个有序字典形式返回。这个有序字典中,key 是各层参数名,value 就是参数,常用于 finetune。
load_state_dict(state_dict) 将 state_dict 中的参数加载到当前网络,常用于 finetune。
add_param_group() 给 optimizer 管理的参数组中增加一组参数,可为该组参数定制 lr, momentum, weight_decay 等,如optimizer_1.add_param_group({‘params’: w3, ‘lr’: 0.001, ‘momentum’: 0.8}),在 finetune 中常用。
for input, target in dataset:
def closure():
optimizer.zero_grad()
output = model(input)
loss = loss_fn(output, target)
loss.backward()
return loss
optimizer.step(closure)
4.3 优化器分类
有常见的 SGD、ASGD、Rprop、RMSprop、Adam…
4.3.1 torch.optim.SGD
torch.optim.SGD(params, lr=<object>, momentum=0, dampening=0, weight_decay=0, esterov=False)
可实现 SGD 优化算法,带动量 SGD 优化算法,带 NAG(Nesterov accelerated
gradient)动量 SGD 优化算法,并且均可拥有 weight_decay 项。
params(iterable)- 参数组(参数组的概念请查看 3.2 优化器基类:Optimizer),优化器要管理的那部分参数。
lr(float)- 初始学习率,可按需随着训练过程不断调整学习率。
momentum(float)- 动量,通常设置为> 0.9,0.8
dampening(float)- dampening for momentum ,暂时不了其功能,在源码中是这样用的:buf.mul_(momentum).add_(1 - dampening, d_p),值得注意的是,若采用nesterov,dampening 必须为 0.
weight_decay(float)- 权值衰减系数,也就是 L2 正则项的系数
nesterov(bool)- bool 选项,是否使用 NAG(Nesterov accelerated gradient)
4.3.2 torch.optim.Adam(AMSGrad)
torch.optim.Adam(params, lr=0.001, betas=(0.9, 0.999), eps=1e- 08, weight_decay=0, amsgrad=False)
实现 Adam(Adaptive Moment Estimation))优化方法。Adam 是一种自适应学习率的优化方法,Adam 利用梯度的一阶矩估计和二阶矩估计动态的调整学习率。吴老师课上说过,Adam 是结合了Momentum 和 RMSprop,并进行了偏差修正。
amsgrad- 是否采用 AMSGrad 优化方法,asmgrad 优化方法是针对 Adam 的改进,通过添加额外的约束,使学习率始终为正值。(AMSGrad,ICLR-2018 Best-Pper 之一,《On the convergence of Adam and Beyond 》)。详细了解 Adam 可阅读,Adam: A Method for Stochastic Optimization(https://arxiv.org/abs/1412.6980)。
4.3.3 torch.optim.Adamax
torch.optim.Adamax(params, lr=0.002, betas=(0.9, 0.999), eps=1e-08, weight_decay=0)
实现 Adamax 优化方法。Adamax 是对 Adam 增加了一个学习率上限的概念,所以也称之
为 Adamax。详细了解可阅读,Adam: A Method for Stochastic Optimization(https://arxiv.org/abs/1412.6980)(没错,就是 Adam 论文中提出了Adamax)
4.3.4 torch.optim.ASGD
torch.optim.ASGD(params, lr=0.01, lambd=0.0001, alpha=0.75, t0=1000000.0, weight_decay=0)
ASGD 也成为 SAG,均表示随机平均梯度下降(Averaged Stochastic Gradient Descent),简单地说 ASGD 就是用空间换时间的一种 SGD,详细可参看论文:http://riejohnson.com/rie/stograd_nips.pdf
params(iterable)- 参数组(参数组的概念请查看 3.1 优化器基类:Optimizer),优化器
要优化的那些参数。
lr(float)- 初始学习率,可按需随着训练过程不断调整学习率。
lambd(float)- 衰减项,默认值 1e-4。
alpha(float)- power for eta update ,默认值 0.75。
t0(float)- point at which to start averaging,默认值 1e6。
weight_decay(float)- 权值衰减系数,也就是 L2 正则项的系数。
除了上述常用的Optimizer,还有以下几类,可以自行学习:
torch.optim.Rprop
torch.optim.Adagrad
torch.optim.Adadelta
torch.optim.RMSprop
torch.optim.SparseAdam
torch.optim.LBFGS
4.4 学习率调整策略
学习率调整策略:就是学习率减小的策略。优化器中最重要的一个参数就是学习率,合理的学习率可以使优化器快速收敛。一般在训练初期给予较大的学习率,随着训练的进行,学习率逐渐减小。
在 PyTorch 中,学习率的更新是通过 scheduler.step(), 由于 PyTorch 是基于参数组的管理方式,这里需要采用 for 循环对每一个参数组的学习率进行获取及更新。这里需要注意的是 get_lr(),get_lr()的功能就是获取当前epoch,该参数组的学习率。
三大类策略:
- 有序调整
依一定规律有序进行调整,这一类是最常用的,分别是等间隔下降(Step),按需设定下降间隔(MultiStep),指数下降(Exponential)和余弦退火(CosineAnnealing)。这四种方法的调整时机都是人为可控的,也是训练时常用到的。 - 自适应调整
依训练状况伺机调整 (ReduceLROnPlateau)方法。该法通过监测某一指标的变化情况,当该指标不再怎么变化的时候,就是调整学习率的时机,因而属于自适应的调整。 - 自定义调整
自定义调整(Lambda)方法提供的调整策略十分灵活,我们可以为不同的层设定不同的学习率调整方法,这在 fine-tune 中十分有用,我们不仅可为不同的层设定不同的学习率,还可以为其设定不同的学习率调整策略,简直不能更棒!
4.4.1 lr_scheduler.StepLR
torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1)
等间隔调整学习率,调整倍数为 gamma 倍,调整间隔为 step_size。间隔单位是step。需要注意的是,step 通常是指 epoch,不要弄成 iteration 了。
step_size(int)-学习率下降间隔数,若为 30,则会在 30、60、90…个 step 时,将 学习率调整为 lr*gamma。
gamma(float)-学习率调整倍数,默认为 0.1 倍,即下降 10 倍。
last_epoch(int)-上一个 epoch 数,这个变量用来指示学习率是否需要调整。当 last_epoch符合设定的间隔时,就会对学习率进行调整。当为-1 时,学习率设置为初始值.
4.2.2 lr_scheduler.MultiStepLR
torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=-1)
按设定的间隔调整学习率。这个方法适合后期调试使用,观察 loss 曲线,为每个实验
定制学习率调整时机。
milestones(list)-一个 list,每一个元素代表何时调整学习率,list 元素必须是递增的。如milestones=[30,80,120]
gamma(float)-学习率调整倍数,默认为 0.1 倍,即下降 10 倍。
last_epoch(int)-上一个 epoch 数,这个变量用来指示学习率是否需要调整。当last_epoch
符合设定的间隔时,就会对学习率进行调整。当为-1 时,学习率设置为初始值。
4.2.3 lr_scheduler.ExponentialLR
torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch=-1)
按指数衰减调整学习率,调整公式: lr = lr * gamma**epoch
gamma-学习率调整倍数的底,指数为 epoch,即 gamma**epoch
last_epoch(int)-上一个epoch 数,这个变量用来指示学习率是否需要调整。当last_epoch 符合设定的间隔时,就会对学习率进行调整。当为-1时,学习率设置为初始值。
4.2.4 lr_scheduler.CosineAnnealingLR
torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=-1)
以余弦函数为周期,并在每个周期最大值时重新设置学习率。
T_max(int)-一次学习率周期的迭代次数,即 T_max 个 epoch 之后重新设置学习率。
eta_min(float)-最小学习率,即在一个周期中,学习率最小会下降到 eta_min,默认值为 0。
具体如下图所示:
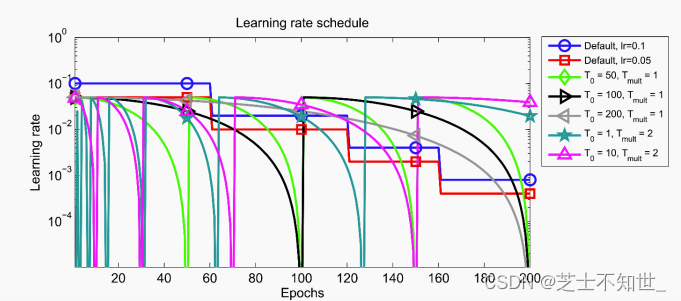
详细请阅读论文《 SGDR: Stochastic Gradient Descent with Warm Restarts》(ICLR-2017):
学习率调整公式为:
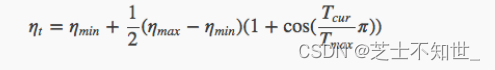
可以看出是以初始学习率为最大学习率,以 2*Tmax 为周期,在一个周期内先下降,后上升。
例如,T_max = 200, 初始学习率 = 0.001, eta_min = 0,则lr调整如下:
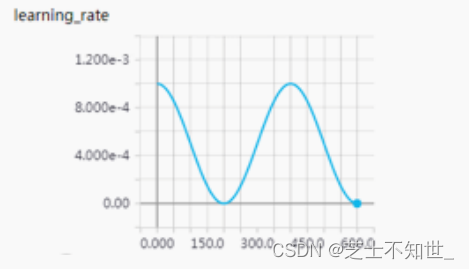
4.2.5 lr_scheduler.ReduceLROnPlateau
torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min',factor=0.1, patience=10, verbose=False, threshold=0.0001, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08)
当某指标不再变化(下降或升高),调整学习率,这是非常实用的学习率调整策略。
例如,当验证集的 loss 不再下降时,进行学习率调整;或者监测验证集的 accuracy,当
accuracy 不再上升时,则调整学习率。
mode(str)-模式选择,有 min 和 max 两种模式,min 表示当指标不再降低(如监测loss),max 表示当指标不再升高(如监测 accuracy)。
factor(float)-学习率调整倍数(等同于其它方法的 gamma),即学习率更新为 lr = lr * factor
patience(int)-直译——“耐心”,即忍受该指标多少个 step 不变化,当忍无可忍时,调整学习率。
verbose(bool)-是否打印学习率信息, print(‘Epoch {:5d}: reducing learning rate’ ’ of group {} to {:.4e}.'.format(epoch, i, new_lr))
threshold(float)-Threshold for measuring the new optimum,配合 threshold_mode 使用。
threshold_mode(str)-选择判断指标是否达最优的模式,有两种模式,rel 和 abs。 当 threshold_moderel,并且 modemax 时,dynamic_threshold = best * ( 1 + threshold ); 当 threshold_moderel,并且 modemin 时,dynamic_threshold = best * ( 1 - threshold ); 当 threshold_modeabs,并且 modemax 时,dynamic_threshold = best + threshold ; 当 threshold_moderel,并且 modemax 时,dynamic_threshold = best - threshold
cooldown(int)-“冷却时间“,当调整学习率之后,让学习率调整策略冷静一下,让模型再训练一段时间,再重启监测模式。
min_lr(float or list)-学习率下限,可为 float,或者 list,当有多个参数组时,可用 list 进行设置。
eps(float)-学习率衰减的最小值,当学习率变化小于 eps 时,则不调整学习率。
4.2.6 lr_scheduler.LambdaLR
torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=- 1)
为不同参数组设定不同学习率调整策略。调整规则为,lr = base_lr * lmbda(self.last_epoch) 。
lr_lambda(function or list)-一个计算学习率调整倍数的函数,输入通常为 step,当有多个参数组时,设为
list。
last_epoch(int)-上一个 epoch 数,这个变量用来指示学习率是否需要调整。当last_epoch 符合设定的间隔时,就会对学习率进行调整。当为-1 时,学习率设置为初始值。
5 可视化——深度学习可解释性
神经网络是一个复杂的数学模型,很多东西暂时没办法解释。但归根到底,它始终是一个数学模型,我们就可以用统计的方法去观察它,理解它。
PyTorch 中使用 TensorBoardX 对神经网络进行统计可视化,如Loss 曲线、Accuracy 曲线、卷积核可视化、权值直方图及多分位数折线图、特征图可视化、梯度直方图及多分位数折线图及混淆矩阵图等。
5.1 Grad-CAM(热图)
CAM即类别激活映射,CAM是一个很简单的算法,对于一张图像,每个类别都可以得到一个CAM热力图,并且表现出视觉任务上的早期注意力机制。每个类别都可以得到一个对应的CAM热力图(标注类别是dome,通过CAM解释后,发现网络其实可以感知出其他语义信息)。
Grad-CAM 全称 Gradient-weighted Class Activation Mapping,用于卷积神经网络的可视化。
CAM算法非常简单,只要模型结构符合CAM的默认要求,就无需重新训练网络,可以做到直接使用:CAM很简单,但是要求必须要有一个GAP层(Global average pooling层),否则不能得到最后一个feature maps的每个channel的特征图(热力图)对应的权重。如果没有GAP,需要把模型末端改成GAP+全连接层的形式,并重新训练网络。
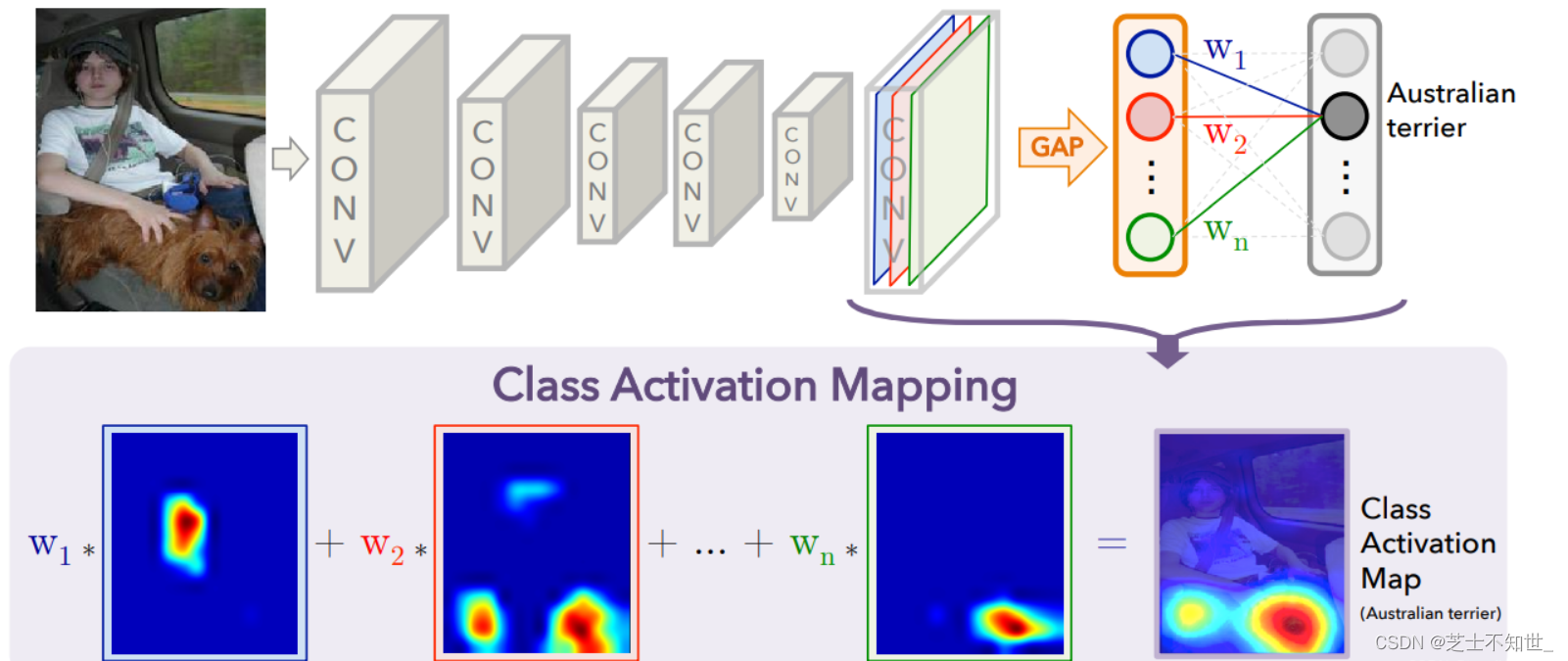
GradCAM概述:给定一张图像和一个感兴趣的类别(例如,"cat"或任何其他类别的输出)作为输入,我们通过模型的CNN部分前向计算图像,然后通过特定任务(task-specific)的计算获得该类别的原始分数。所有类别的梯度都设置为零,但所需类别"cat"除外,该类别设置为1。然后,该信号被反向传播到Rectified Conv Feature Maps,我们将其结合起来计算粗糙GradCAM(蓝色热图),该热力图表示模型决策的局部激活(类似CAM)。最后,我们将热图与引导反向传播(Guided Backprop,输入图像级的梯度)逐点相乘,以获得高分辨率和语义特定的Guided GradCAM可视化。
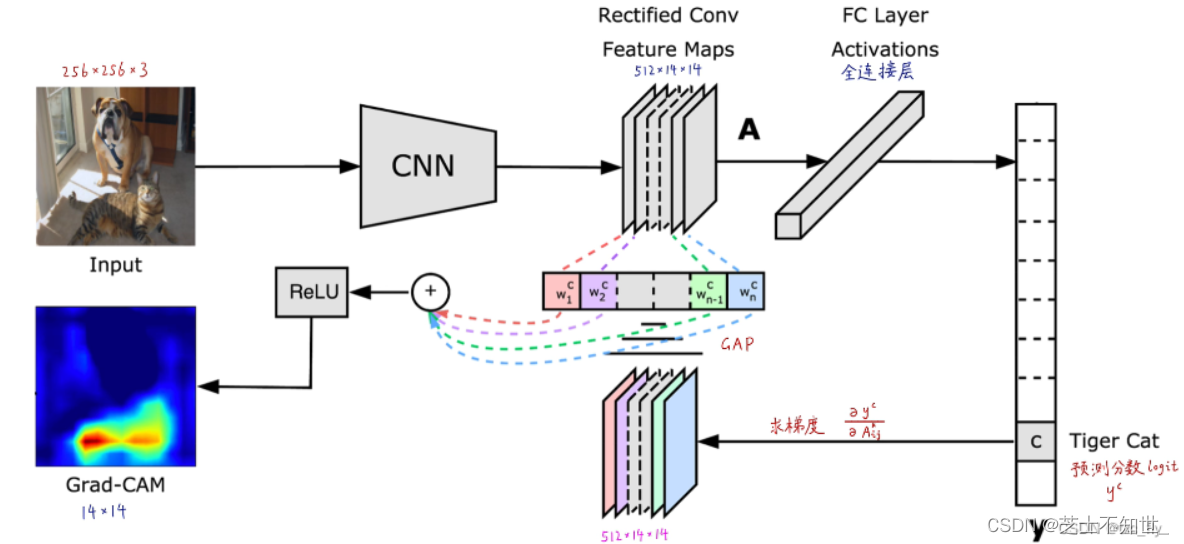
Grad-CAM 的前身是 CAM,CAM 的基本的思想是求分类网络某一类别得分对高维特征图 (卷积层的输出) 的偏导数,从而可以该高维特征图每个通道对该类别得分的权值;而高维特征图的激活信息 (正值) 又代表了卷积神经网络的所感兴趣的信息,加权后使用热力图呈现得到 CAM。

# coding: utf-8
"""
通过实现Grad-CAM学习module中的forward_hook和backward_hook函数
"""
import cv2
import os
import numpy as np
from PIL import Image
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision.transforms as transforms
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool1(F.relu(self.conv1(x)))
x = self.pool1(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def img_transform(img_in, transform):
"""
将img进行预处理,并转换成模型输入所需的形式—— B*C*H*W
:param img_roi: np.array
:return:
"""
img = img_in.copy()
img = Image.fromarray(np.uint8(img))
img = transform(img)
img = img.unsqueeze(0) # C*H*W --> B*C*H*W
return img
def img_preprocess(img_in):
"""
读取图片,转为模型可读的形式
:param img_in: ndarray, [H, W, C]
:return: PIL.image
"""
img = img_in.copy()
img = cv2.resize(img,(32, 32))
img = img[:, :, ::-1] # BGR --> RGB
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.4948052, 0.48568845, 0.44682974], [0.24580306, 0.24236229, 0.2603115])
])
img_input = img_transform(img, transform)
return img_input
def backward_hook(module, grad_in, grad_out):
grad_block.append(grad_out[0].detach())
def farward_hook(module, input, output):
fmap_block.append(output)
def show_cam_on_image(img, mask, out_dir):
heatmap = cv2.applyColorMap(np.uint8(255*mask), cv2.COLORMAP_JET)
heatmap = np.float32(heatmap) / 255
cam = heatmap + np.float32(img)
cam = cam / np.max(cam)
path_cam_img = os.path.join(out_dir, "cam.jpg")
path_raw_img = os.path.join(out_dir, "raw.jpg")
if not os.path.exists(out_dir):
os.makedirs(out_dir)
cv2.imwrite(path_cam_img, np.uint8(255 * cam))
cv2.imwrite(path_raw_img, np.uint8(255 * img))
def comp_class_vec(ouput_vec, index=None):
"""
计算类向量
:param ouput_vec: tensor
:param index: int,指定类别
:return: tensor
"""
if not index:
index = np.argmax(ouput_vec.cpu().data.numpy())
else:
index = np.array(index)
index = index[np.newaxis, np.newaxis]
index = torch.from_numpy(index)
one_hot = torch.zeros(1, 10).scatter_(1, index, 1)
one_hot.requires_grad = True
class_vec = torch.sum(one_hot * output) # one_hot = 11.8605
return class_vec
def gen_cam(feature_map, grads):
"""
依据梯度和特征图,生成cam
:param feature_map: np.array, in [C, H, W]
:param grads: np.array, in [C, H, W]
:return: np.array, [H, W]
"""
cam = np.zeros(feature_map.shape[1:], dtype=np.float32) # cam shape (H, W)
weights = np.mean(grads, axis=(1, 2)) #
for i, w in enumerate(weights):
cam += w * feature_map[i, :, :]
cam = np.maximum(cam, 0)
cam = cv2.resize(cam, (32, 32))
cam -= np.min(cam)
cam /= np.max(cam)
return cam
if __name__ == '__main__':
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
path_img = os.path.join(BASE_DIR, "..", "..", "Data", "cam_img", "test_img_8.png")
path_net = os.path.join(BASE_DIR, "..", "..", "Data", "net_params_72p.pkl")
output_dir = os.path.join(BASE_DIR, "..", "..", "Result", "backward_hook_cam")
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
fmap_block = list()
grad_block = list()
# 图片读取;网络加载
img = cv2.imread(path_img, 1) # H*W*C
img_input = img_preprocess(img)
net = Net()
net.load_state_dict(torch.load(path_net))
# 注册hook
net.conv2.register_forward_hook(farward_hook)
net.conv2.register_backward_hook(backward_hook)
# forward
output = net(img_input)
idx = np.argmax(output.cpu().data.numpy())
print("predict: {}".format(classes[idx]))
# backward
net.zero_grad()
class_loss = comp_class_vec(output)
class_loss.backward()
# 生成cam
grads_val = grad_block[0].cpu().data.numpy().squeeze()
fmap = fmap_block[0].cpu().data.numpy().squeeze()
cam = gen_cam(fmap, grads_val)
# 保存cam图片
img_show = np.float32(cv2.resize(img, (32, 32))) / 255
show_cam_on_image(img_show, cam, output_dir)
5.2 混淆矩阵及其可视化
在分类任务中,通过混淆矩阵可以看出模型的偏好,而且对每一个类别的分类情况都了如指掌,为模型的优化提供很大帮助。
混淆矩阵概念
混淆矩阵(Confusion Matrix)常用来观察分类结果,其是一个 N*N 的方阵,N 表示类别数。混淆矩阵的行表示真实类别,列表示预测类别。例如,猫狗的二分类问题,有猫的图像 10 张,狗的图像 30 张,模型对这 40 张图片进行预测,得到的混淆矩阵为
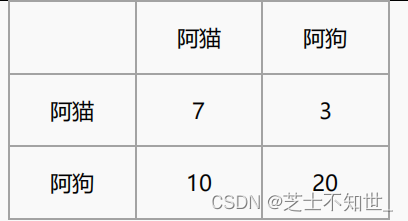
模型的准确率(Accuracy)为 7+20 / 40 = 67.5%
可以发现通过混淆矩阵可以清晰的看出网络模型的分类情况,若再结合上颜色可视化,可方便的看出模型的分类偏好。
混淆矩阵的统计
第一步:创建混淆矩阵
获取类别数,创建 N*N 的零矩阵
conf_mat = np.zeros([cls_num, cls_num])
第二步:获取真实标签和预测标签
labels 为真实标签,通常为一个 batch 的标签
predicted 为预测类别,与 labels 同长度
第三步:依据标签为混淆矩阵计数
for i in range(len(labels)):
true_i = np.array(labels[i])
pre_i = np.array(predicted[i])
conf_mat[true_i, pre_i] += 1.0
混淆矩阵可视化
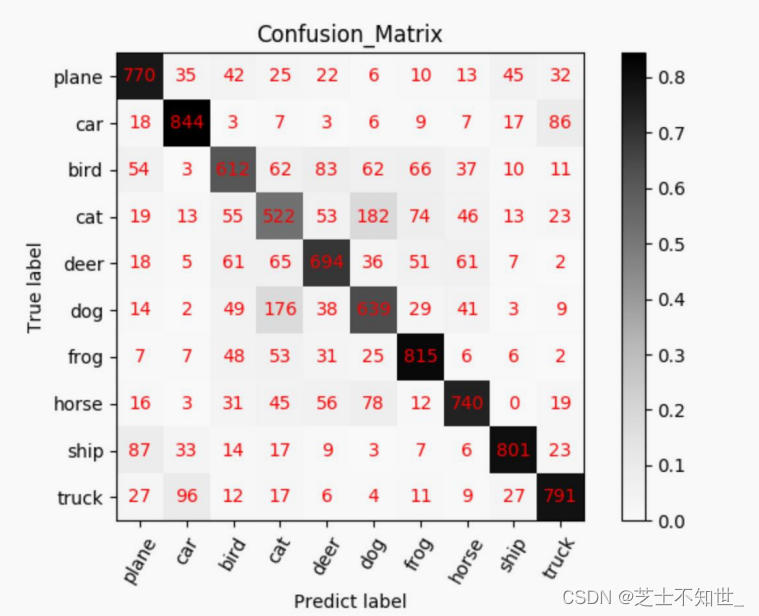
def show_confMat(confusion_mat, classes_name, set_name, out_dir):
"""
可视化混淆矩阵,保存png格式
:param confusion_mat: nd-array
:param classes_name: list,各类别名称
:param set_name: str, eg: 'valid', 'train'
:param out_dir: str, png输出的文件夹
:return:
"""
# 归一化
confusion_mat_N = confusion_mat.copy()
for i in range(len(classes_name)):
confusion_mat_N[i, :] = confusion_mat[i, :] / confusion_mat[i, :].sum()
# 获取颜色
cmap = plt.cm.get_cmap('Greys') # 更多颜色: http://matplotlib.org/examples/color/colormaps_reference.html
plt.imshow(confusion_mat_N, cmap=cmap)
plt.colorbar()
# 设置文字
xlocations = np.array(range(len(classes_name)))
plt.xticks(xlocations, classes_name, rotation=60)
plt.yticks(xlocations, classes_name)
plt.xlabel('Predict label')
plt.ylabel('True label')
plt.title('Confusion_Matrix_' + set_name)
# 打印数字
for i in range(confusion_mat_N.shape[0]):
for j in range(confusion_mat_N.shape[1]):
plt.text(x=j, y=i, s=int(confusion_mat[i, j]), va='center', ha='center', color='red', fontsize=10)
# 保存
plt.savefig(os.path.join(out_dir, 'Confusion_Matrix_' + set_name + '.png'))
plt.close()
5.3 特征图可视化
可视化经网络操作后的图像(feature maps)。
基本思路:
- 获取图片,将其转换成模型输入前的数据格式,即一系列 transform,
- 获取模型各层操作,手动的执行每一层操作,拿到所需的 feature maps,
- 借助 tensorboardX 进行绘制。
Tips: 此处获取模型各层操作是__init__()中定义的操作,然而模型真实运行采用的是
forward(), 所以需要人工比对两者差异。本例的差异是,init()中缺少激活函数
relu。
先看看图,下图为 conv1 层输出的 feature maps, 左图为未经过 relu 激活函数,右
图为经过 relu 之后的 feature maps。
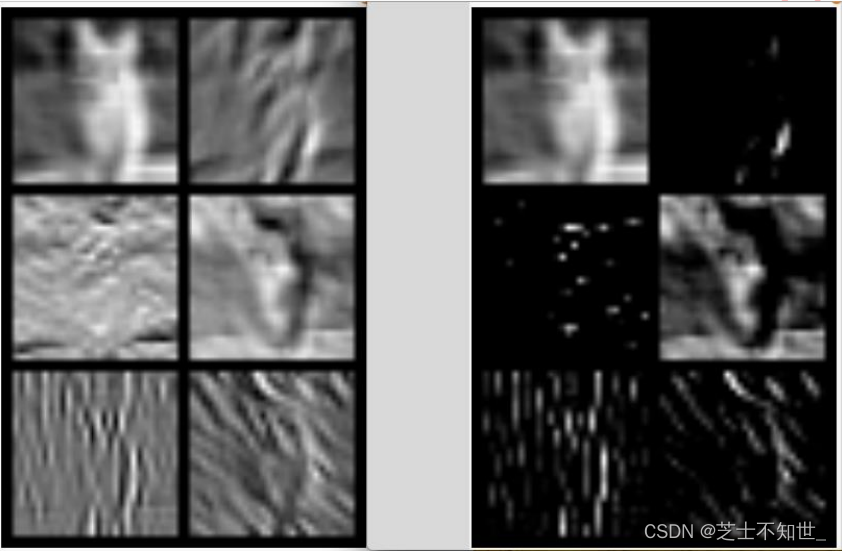
基本流程:输入图像预处理->经过模型每一层->选择各层feature map进行绘图
# coding: utf-8
import os
import torch
import torchvision.utils as vutils
import numpy as np
from tensorboardX import SummaryWriter
import torch.nn.functional as F
import torchvision.transforms as transforms
import sys
sys.path.append("..")
from util import *
from torch.utils.data import DataLoader
vis_layer = 'conv1'
log_dir = os.path.join("..", "..", "Result", "visual_featuremaps")
txt_path = os.path.join("..", "..", "Data", "visual.txt")
pretrained_path = os.path.join("..", "..", "Data", "net_params_72p.pkl")
net = Net()
pretrained_dict = torch.load(pretrained_path)
net.load_state_dict(pretrained_dict)
# 数据预处理
normMean = [0.49139968, 0.48215827, 0.44653124]
normStd = [0.24703233, 0.24348505, 0.26158768]
normTransform = transforms.Normalize(normMean, normStd)
testTransform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
normTransform
])
# 载入数据
test_data = MyDataset(txt_path=txt_path, transform=testTransform)
test_loader = DataLoader(dataset=test_data, batch_size=1)
img, label = iter(test_loader).next()
x = img
writer = SummaryWriter(log_dir=log_dir)
for name, layer in net._modules.items():
# 为fc层预处理x
x = x.view(x.size(0), -1) if "fc" in name else x
# 对x执行单层运算
x = layer(x)
print(x.size())
# 由于__init__()相较于forward()缺少relu操作,需要手动增加
x = F.relu(x) if 'conv' in name else x
# 依据选择的层,进行记录feature maps
if name == vis_layer:
# 绘制feature maps
x1 = x.transpose(0, 1) # C,B, H, W ---> B,C, H, W
img_grid = vutils.make_grid(x1, normalize=True, scale_each=True, nrow=2) # B,C, H, W
writer.add_image(vis_layer + '_feature_maps', img_grid, global_step=666)
# 绘制原始图像
img_raw = normalize_invert(img, normMean, normStd) # 图像去标准化
img_raw = np.array(img_raw * 255).clip(0, 255).squeeze().astype('uint8')
writer.add_image('raw img', img_raw, global_step=666) # j 表示feature map数
writer.close()
原始图片(已经 resize 至 32*32):绘制如下

5.4 TensorBoardX
PyTorch 自身的可视化功能没有 TensorFlow 的 tensorboard 那么优秀,所以 PyTorch通常是借助 tensorboard(是借助,非直接使用)进行可视化,目前流行的有如下两种方法,常用的就是TensorBoardX。
这里不做介绍,具体可自行查阅学习。
5.5 卷积核可视化
神经网络中最重要的就是权值,而人们对神经网络理解有限,所以我们需要通过尽可能了解权值来帮助诊断网络的训练情况。除了查看权值分布图和多折线分位图,还可以对卷积核权值进行可视化,来辅助我们分析网络。
如下一副卷积核权值可视化的图片:可以发现有趣的现象,第一个 GPU 中的卷积核(前3行)呈现初边缘的特性,第二个 GPU 中的卷积核(后3行)呈现色彩的特性。对卷积核权值进行可视化,在一定程度上帮助我们诊断网络的训练好坏,因此对卷积核权值的可视化十分有必要。

可视化原理很简单,对单个卷积核进行“归一化”至 0~255,然后将其展现出来即可,这一系列操作可以借助 TensorboardX 的 add_image 来实现。
下图以卷积层 conv1 为例,conv1.weight.shape() = [6,3,5,5],输入通道数为 3,卷积核个数为 6,则 feature map 数为 6,卷积核大小为 5*5。 图 1,绘制全部卷积核。

# coding: utf-8
import os
import torch
import torchvision.utils as vutils
from tensorboardX import SummaryWriter
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool1(F.relu(self.conv1(x)))
x = self.pool2(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# 定义权值初始化
def initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
torch.nn.init.xavier_normal_(m.weight.data)
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
torch.nn.init.normal_(m.weight.data, 0, 0.01)
m.bias.data.zero_()
net = Net() # 创建一个网络
pretrained_dict = torch.load(os.path.join("..", "2_model", "net_params.pkl"))
net.load_state_dict(pretrained_dict)
writer = SummaryWriter(log_dir=os.path.join("..", "..", "Result", "visual_weights"))
params = net.state_dict()
for k, v in params.items():
if 'conv' in k and 'weight' in k:
c_int = v.size()[1] # 输入层通道数
c_out = v.size()[0] # 输出层通道数
# 以feature map为单位,绘制一组卷积核,一张feature map对应的卷积核个数为输入通道数
for j in range(c_out):
print(k, v.size(), j)
kernel_j = v[j, :, :, :].unsqueeze(1) # 压缩维度,为make_grid制作输入
kernel_grid = vutils.make_grid(kernel_j, normalize=True, scale_each=True, nrow=c_int) # 1*输入通道数, w, h
writer.add_image(k+'_split_in_channel', kernel_grid, global_step=j) # j 表示feature map数
# 将一个卷积层的卷积核绘制在一起,每一行是一个feature map的卷积核
k_w, k_h = v.size()[-1], v.size()[-2]
kernel_all = v.view(-1, 1, k_w, k_h)
kernel_grid = vutils.make_grid(kernel_all, normalize=True, scale_each=True, nrow=c_int) # 1*输入通道数, w, h
writer.add_image(k + '_all', kernel_grid, global_step=666)
writer.close()
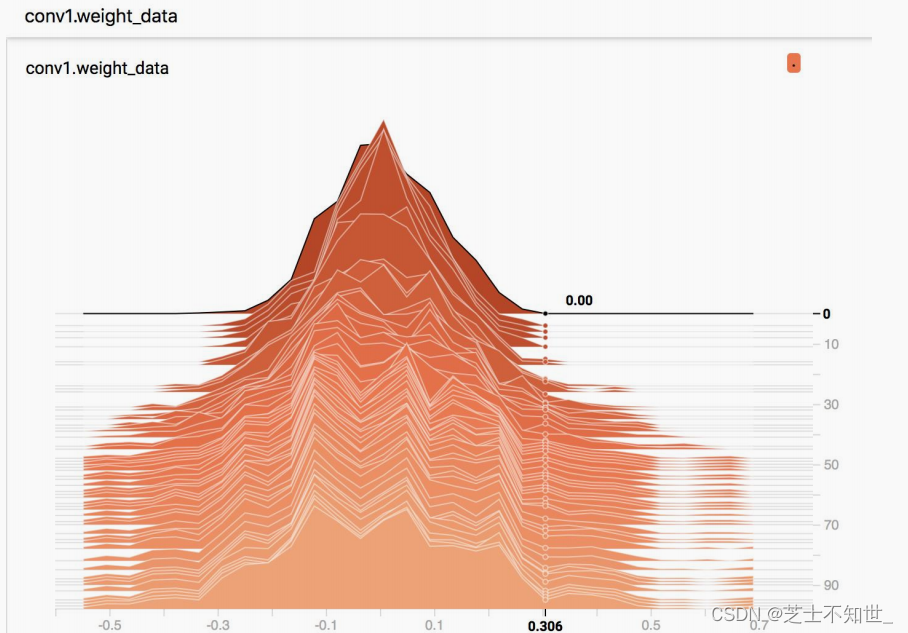
5.6 梯度及权值分布可视化
在网络训练过程中,我们常常会遇到梯度消失、梯度爆炸等问题,我们可以通过记录每个 epoch 的梯度的值来监测梯度的情况,还可以记录权值,分析权值更新的方向是否符合规律.
记录梯度和权值主要是以下三行代码:
# 每个 epoch,记录梯度,权值
for name, layer in net.named_parameters():
writer.add_histogram(name + '_grad', layer.grad.cpu().data.numpy(), epoch)
writer.add_histogram(name + '_data', layer.cpu().data.numpy(), epoch)