第九章 - 多表查询(join,left join 等),合并查询(union & union all),子查询
- 交叉链接(笛卡尔积)
- 内连接查询
- 外连接查询
- 左链接: left join
- 右链接:right join
- 组合查询 union & union all
- 使用数据下载:
在日常工作中,需要查询的数据一般是存在多个不同的数据表中,比如用户的基本数据信息,商品的信息,用户的行为,订单信息等,都是不同的表,通过用户ID,订单ID等信息可以链接多个表进行多表查询。
多表链接的几种常见的方法:
交叉链接(笛卡尔积)
交叉链接会产生笛卡尔积,所以基本不会用此种链接查询。
select 字段名称 from 表a,表b
实例:
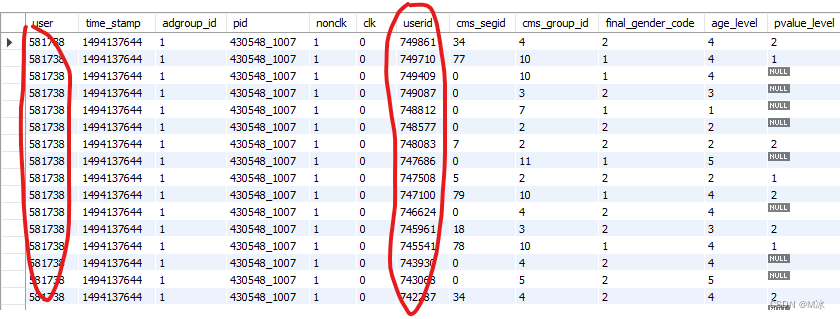
select
*
from
raw_sample,user_profile
可以看到显示的结果是没有对应关系的,这样的结果也是不能使用的。
内连接查询
内连接查询可以通过指定的条件来匹配两张或多张表中的数据,能按照条件匹配上就显示,匹配不上就不显示。
有两种写法:
1.完整写法
select 字段名称 from 表a inner join 表b on 对应条件
2.省略写法
select 字段名称 from 表a,表b where 对应条件
虽然两种写法查询的结果是一样的,但是还是建议使用完整的写法,更规范一些,而且在别人看的时候会更容易理解一些。尤其是在写一些比较复杂的查询代码的时候。
举个例子:查询所有男性的点击行为。
- user_profile 为用户基本信息表,其中userid为用户id,final_gender_code为用户性别字段(男=1,女=2)。
- behavior_log 为用户性别信息表,btag为用户点击行为(ipv = 浏览,cart = 加入购物车,fav = 喜欢,buy = 购买)
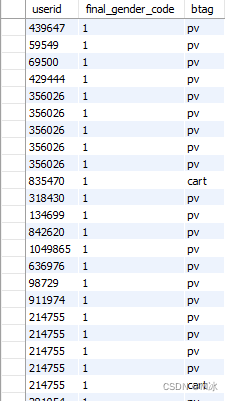
1.完整写法:
select
a.userid, # 用户id
a.final_gender_code, # 性别 1男,2女
b.btag # 行为(ipv = 浏览,cart = 加入购物车,fav = 喜欢,buy = 购买)
from
# as 别名也可以对表用,此处就用a,b来替代原来的表名
# on表示表时间的关联条件,此处为关联用户id
user_profile as a inner join behavior_log as b on a.userid = b.user
where
# 性别为1男性
a.final_gender_code = 1
输出结果:
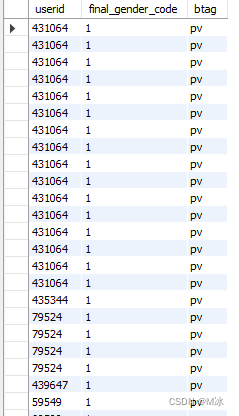
2.省略写法
select
a.userid, # 用户id
a.final_gender_code, #性别
b.btag # 行为(ipv = 浏览,cart = 加入购物车,fav = 喜欢,buy = 购买)
from
user_profile as a , behavior_log as b
where
# 链接条件为用户ID,筛选条件为1男性
a.userid = b.user and a.final_gender_code = 1
输出结果:
外连接查询
左链接: left join
左外连接,也是最常用的一种链接方式,是以左边表为基本表,用右边表去匹配左边表中对应的数据,匹配上就显示,没有匹配上就用null来填充。
select 字段名称 from 表a left outer join 表b on 对应条件
outer 可以省略,一般直接写为 left join
举个例子:
select
a.userid, # 用户ID
b.user, # 用户ID
b.btag # 行为(ipv = 浏览,cart = 加入购物车,fav = 喜欢,buy = 购买)
from
# 以左边表user_profile为准,用behavior_log中的数据去匹配
# on 链接条件为 用户ID
user_profile as a left join behavior_log as b on a.userid = b.user
order by
# 以userid列正序排序
a.userid
输出结果:
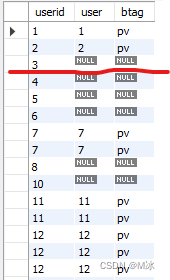
以左表user_profile的userid为准,用右表去匹配左表,当右表没有对应数据的时候就用null来填充显示
右链接:right join
右外连接,和左外连接相反,是以右边表为基本表,用左边表去匹配右边表中对应的数据,匹配上就显示,没有匹配上就用null来填充。
不过一般情况下基本都是用左连接。
select 字段名称 from 表a right outer join 表b on 对应条件
outer 可以省略,一般直接写为 right join
举个例子:
select
a.userid, # 用户ID
b.user, # 用户ID
b.btag #行为(ipv = 浏览,cart = 加入购物车,fav = 喜欢,buy = 购买)
from
# 以右边表behavior_log为准,用左边表user_profile中的数据去匹配。
# 筛选条件 on 为用户ID
user_profile as a right outer join behavior_log as b on a.userid = b.user
order by
# 按user列正序排序
b.user
输出结果:
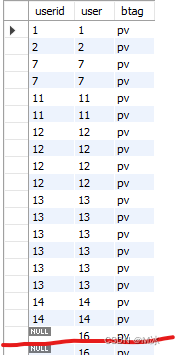
从结果可以看到,左边userid没有匹配到user上面数据的,也是用null来填充。
组合查询 union & union all
组合查询是可以执行多个select查询,并且可以将结果作为单个查询结果返回。
使用要点:
- 选择的字段数量需要一致
- 相对应字段的数据类型需要一致
- 列名在显示的时候会使用第一条
select的列名 union的结果会进行去重操作union all不会进行去重,所以计算速度会快一些。- 可以用于合并链接数据,或者合并多个查询结果。
语法格式:
select 字段名称 from 表 (where 条件)
union (或者union all)
select 字段名称 from 表 (where 条件)
举个例子1:基本拼接数据
例子使用用union,如果不需要去重可以替换为union all 。
select
userid,
final_gender_code
from
user_profile
# union会进行去重操作
# 如果允许有重复值出现,可以使用 union all
union
select
adgroup_id,
price
from
ad_feature
输出结果:
列名是以第一条select的列名来显示的
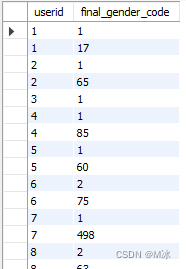
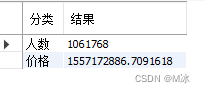
举个例子2:用来链接聚合后的数据
- 一般使用
select进行多个数据汇总的时候,数据结果是在一行数据上显示的,如果想要把数据结果用竖列显示,可以尝试适合用此方法。
select
# 添加新的行内容和列名
"人数" as "分类",
# 设置新的列名
count(distinct userid) as "结果"
from
user_profile
union
select
# 添加新行的内容
"价格",
sum(price)
from
ad_feature
输出结果:
使用数据下载:
SQL演示数据集 - ad-feature(广告基本信息表)
SQL演示数据集 - user-profile(用户基本信息)
SQL演示数据集 - behavior-log(行为数据表)
SQL演示数据集 - raw-sample(样本骨架数据)