目录
- 一、网址
- 二、重要时间点
- 三、论文篇幅要求
- 四、征稿主题
- 五、论文格式相关要求
- 六、论文模板修改成投稿模式
- 上述参考
- 七、模板使用相关
- 八、关于图片方面的问题
- 九、Review and Rebuttal
- 十、ACM MM2022相关论文参考
- arxiv上 ACM MM2022 论文汇总
一、网址
-
ACM MM2023 主页:
- https://www.acmmm2023.org/
-
Call for Papers:
- https://www.acmmm2023.org/cfp/
-
论文模板:
- https://www.acm.org/publications/proceedings-template
二、重要时间点
- 论文摘要截止日期
- Paper abstract deadline (firm deadline, no extension): 23 April 2023
- 论文提交截止日期
- Paper submission deadline (firm deadline, no extension): 30 April 2023
- Regular Paper Reviews To Author: 2 July 2023
- Regular Paper Rebuttal Deadline: 6 July 2023
- Notification: 25 July 2023
- Camera-ready Submission: 10 August 2023
- Conference dates: October 28, 2023 – November 3, 2023
三、论文篇幅要求
-
会议 6至8页不等长度的研究论文
- 以及参考页的额外页面;即参考页不计入6至8页的页数限制。
-
The conference invites research papers of varying length from 6 to 8 pages, plus additional pages for the reference pages; i.e., the reference page(s) are not counted towards the page limit of 6 to 8 pages.
- Please note that there is no longer a distinction between long and short papers, but the authors may themselves decide on the appropriate length of the paper.
- All papers will undergo the same review process and review period.
Length:
- As stated in the CfP, submitted papers may be 6 to 8 pages.
- Up to two additional pages may be added for references.
- The reference pages must only contain references.
- Overlength papers will be rejected without review. Optionally, you may upload supplementary material that complements your submission (100Mb limit).
四、征稿主题
- Theme: Engaging users with multimedia
- Emotional and Social Signals
- Multimedia Search and Recommendation
- Summarization, Analytics, and Storytelling
- 主题: 用多媒体吸引用户
- 情感和社会信号
- 多媒体搜索和推荐
- 总结、分析和讲故事
- Theme: Experience
- Interactions and Quality of Experience
- Social-good, fairness and transparency
- Metaverse, Art and Culture
- Multimedia Applications
- 主题: 经验
- 互动和体验质量
- 社会公益、公平透明
- 元宇宙、艺术与文化
- 多媒体应用
- Theme: Multimedia systems
- Systems and Middleware
- Transport and Delivery
- Data Systems Management and Indexing
- 主题: 多媒体系统
- 系统和中间件
- 运输及交付
- 数据系统管理和索引
- Theme: Understanding multimedia content、
- Multimodal Fusion and Embedding
- Vision and Language
- Media Interpretation
- 主题: 理解多媒体内容,
- 多模态融合和嵌入
- 视觉和语言
- 媒体解说
-
多模态融合和嵌入
- 在现实世界中,有些问题只能通过多种媒介和/或模式的组合来解决。
- 本主题寻求如何嵌入和融合多视角媒体信息的新见解和解决方案,以解决新问题和创新应用。
-
视觉和语言
- 最近的研究以不同的方式推动了视觉和语言的融合,例如字幕、问答和多模式聊天机器人。
- 该领域寻求新的解决方案和结果,这些解决方案和结果特定于结合或弥合视觉和语言的问题。
-
媒体解读
- 该领域寻求以任何形式对媒体相关信息进行新颖处理,从而产生解释多媒体内容的新方法。
- 示例包括处理图像、视频、音频、音乐、语言、语音或其他感官模式,以进行解释、知识发现和理解。
五、论文格式相关要求
提交的论文(.pdf格式)必须使用 ACM 文章模板。
Please remember to add Concepts and Keywords
- 模板下载:
- https://www.acm.org/publications/proceedings-template
Please use the template in traditional double-column format to prepare your submissions.
- For example, word users may use Word Interim Template, and latex users may use sample-sigconf template.
- 请使用传统双栏格式的模板来准备您的提交。比如word用户可以使用Word Interim Template,latex用户可以使用sample-sigconf模板。
“双盲”:
- 提交的论文必须符合“双盲”评审政策。这意味着作者不应该知道他们论文的审稿人的名字,审稿人也不应该知道作者的名字。请以保护作者匿名的方式准备您的论文。
- 不要把作者的名字放在标题下面
- 在提及作者的早期出版物时,避免使用诸如“我们以前的工作”之类的短语。
- 删除致谢中可能识别作者身份的信息(例如,同事和资助 ID)。
- 检查补充材料(例如,视频剪辑中的标题或补充文件)以获取可能识别作者身份的信息。
- 避免提供指向可识别作者身份的网站的链接。
没有适当盲法的论文将被直接拒绝而不经审查。
六、论文模板修改成投稿模式
-
论文模板下载:
- https://www.acm.org/publications/proceedings-template

- https://www.acm.org/publications/proceedings-template
-
压缩包解压
acmart-primary.zip -
选择模板
- 压缩包里的
samples文件夹里包含ACM 的一系列模板 sample-authordraft.tex或者sample-sigconf.tex均可
- 压缩包里的
-
修改模板
- 首先将
\documentclass[sigconf,authordraft]{acmart}- 改成
\documentclass[sigconf,review,anonymous]{acmart}
- 改成
- 然后将
%%\acmSubmissionID{123-A56-BU3}这个注释打开- 并修改为自己注册的号码
\acmSubmissionID{123} - 基础匿名版本就得到啦
- 并修改为自己注册的号码
- 首先将
-
微调
-
图片中红色框出的是模板里自带的,投稿情况下可以保留也可以删除
-
官网没有对此的明确说明,但大家是默认删除是可以的
-
删除1,在tex添加以下语句
\renewcommand\footnotetextcopyrightpermission[1]{}
-
如果不删除1,想要保留
- 请修改tex里为当年的MM信息
- 比如2022年的如下:
-

\setcopyright{acmcopyright}
\copyrightyear{2022}
\acmYear{2022}
\acmDOI{XXXXXXX.XXXXXXX}
%% These commands are for a PROCEEDINGS abstract or paper.
\acmConference[MM '22]{Proceedings of the 30th ACM International Conference on Multimedia}{October 10--14, 2022}{Portugal, Lisbon}
\acmBooktitle{Proceedings of the 30th ACM International Conference on Multimedia (MM '22), October 10--14, 2022, Portugal, Lisbon}
\acmPrice{15.00}
\acmISBN{978-1-4503-XXXX-X/18/06}
-
DOI信息
- 记得摘要截止提交后,会邮件发给作者,加上就行
-
删除2
- 很easy
- 添加如下语句就可以
\settopmatter{printacmref=false} %remove ACM reference format
上述参考
https://zhuanlan.zhihu.com/p/491172953
七、模板使用相关
模板的使用
- 投稿是ACM 下的 multi mudie 会议 , 使用sample-sigconf模板。
- 新建一个文件夹将
acmart-master中acmart.cls、acmart.bib、ACM-Reference-Format.bst及samples文件夹下sigconf拷入,编译即可。 - 报错是因为没有考入sample下的图片
sample-franklin.png。 - 另外。Texstudio的编译改为
Xelatex。 - 之后,复制粘贴就行。
- 新建一个文件夹将
公式的编辑
-
公式分为两种:行内和行间。
- https://blog.csdn.net/beta_2187/article/details/79980281
- 这篇博客对公式插入做了整理。
-
下面是对sample-sigconf模板的总结。
- 首先说需要注意的问题.
- 1 数学公式中有时候会出现文字(中文或英文),
- 需要将文字用命令 \text{…} 包起来.
- 如果将文字不加处理, 直接写到公式里面会出现如下问题:https://blog.csdn.net/beta_2187/article/details/79980281
- 2 上下标
\max_{k=1,2,…,K}上下结构max_{k=1,2,…,K}左右结构
- 3 数学希腊字符
- https://jingyan.baidu.com/article/4b52d702df537efc5c774bc9.html
-
公式
- 行内公式
- 方法:
$…$来表达. $前后一般要有空格, 除非公式后面有标点符号.
- 方法:
- 行间公式
- 行间公式有编号与不变号
- 编号公式
- 单行
- 单行编号
- 单行不编号
- 多行
- 多行不编号
- 多行编号
- 参考博客:https://blog.csdn.net/beta_2187/article/details/79980281
- 单行
- 行内公式
-
图片插入
- 这里只说明组合图
- 在原模板中加入
\usepackage{subfigure} - 上下组合图
- 左右组合图
- 在原模板中加入
- 这里只说明组合图
-
插入表格
- 合并列
\multicolumn{2}{c}{CityPersons} - 注一下, 这里的 分列都是通过合并操作完成的
- 合并列
八、关于图片方面的问题
经常在word中画图的同学,得先先在电脑里面安装好一个Adobe acrobat professional
-
将word画布里面的图复制出来,放到一个新建的word文件里
- 这一步很关键,不然虽然能够导出正确的pdf,但是用pdf生成eps时会出错。
-
将新建的word文件里的图选择另存为pdf格式
-
然后用
Adobe acrobat professional打开生成好的pdf图,选择工具里面的高级编辑工具,将图片周围空白的地方裁减掉 -
然后另存为eps格式。
-
注意,保存图片的时候一直报错,异常和内存不够。
- 换了
smart pdf就解决了。https://smallpdf.com/cn/pdf-converter
- 换了
九、Review and Rebuttal
每份提交将由至少三名审稿人审阅。
收到评论后,作者可以选择提交反驳,以在提交系统的界面中以纯文本形式处理评论者的评论。
- 对此有 5000 个字符的限制。
- 请注意,作者反驳是可选的,它旨在为您提供反驳事实错误或提供审稿人要求的额外信息的机会。
- 它无意添加原始提交中未包含且审阅者未要求的新贡献(定理、算法、实验)。
- 作者可以选择联系作者的代言人,其职责是倾听作者的意见,并在评论质量明显低于平均水平时为他们提供帮助。作者代言人独立于技术计划委员会运作。
十、ACM MM2022相关论文参考
-
师广琛同学论文被ACM MM(CCF-A)录用
- https://zhuanlan.zhihu.com/p/549247763
- ACM Multimedia 2022 (CCF-A,多媒体领域顶会)
- 《Incremental Few-Shot Semantic Segmentation via Embedding Adaptive-Update and Hyper-class Representation》
- 师广琛:河海大学硕士
-
ACM MM 2022 中科院信工所第三研究室部分录取论文详解
- https://zhuanlan.zhihu.com/p/537521485
- 《Camera-specific Informative Data Augmentation Module for Unbalanced Person Re-identification》
- 行人重识别任务致力于在无重叠的摄像头网络中检索出目标人物,并返回相应排序结果。
- 《Efficient Hash Code Expansion by Recycling Old Bits》
- 哈希技术因其优越的存储和计算效率被广泛应用于多媒体大数据检索中,近年来,得益于深度学习技术的不断发展,深度哈希方法受到广泛关注。
- 《Attack is the Best Defense: Towards Preemptive-Protection Person Re-Identification》
- 行人重识别旨在跨多个摄像机视图检索同一个人的图像。尽管它在监控和公共安全方面很受欢迎,但身份信息的泄露仍然存在风险。
- 《Multimodal Hate Speech Detection via Cross-Domain Knowledge Transfer》
- 提出一种基于跨领域知识迁移(CDKT)的多模态仇恨言论检测框架,该框架遵循“主-辅任务” 的设计思路,包括三个核心组成:语义自适应模块、定义自适应模块、领域自适应模块,同时拟合主任务和辅助任务之间的语义、定义和领域差异。
- 《Detach and Attach: Stylized Image Captioning without Paired Stylized Dataset》
- 风格化图像标题生成旨在生成同时具有准确图像内容和风格特征(例如积极、消极等)的标题。然而,大规模的平行图像-风格化标题数据集需要花费大量资源。因此,如何在没有成对的风格化图像标题数据集的情况下生成风格化标题是一个挑战。
- 《TPSNet: Reverse Thinking of Thin Plate Splines for Arbitrary Shape Scene Text Representation》
- 任意形状的场景文本的检测和识别是当前OCR研究的重点之一。虽然目前已有一些方法可以取得不错的效果,但是这些方法所采用的文本形状表示方法并不够理想。
- 《TextBlock: Towards Scene Text Spotting without Fine-grained Detection》
- 年来,场景文本定位与识别的系统取得了很大的成功。现有的工作大多数遵循着单词/字符级别细粒度和单个实例识别的框架,这种框架过分强调了检测器的作用,同时忽略了丰富的上下文信息在识别中的作用。
- 《MaMiCo: Macro-to-Micro Semantic Correspondence for Self-supervised Video Representation Learning》
- 早期的视频自监督学习通过手工设计的代理任务,利用数据本身的变换产生的伪标签进行预训练;近期得益于图像对比学习框架的巨大进展,对比学习在视频自监督学习领域同样取得了成功。然而,现有的工作一方面需要更多的视频帧来提取视频级别的信息,造成巨量的计算开销,另一方面忽略了细粒度的像素级别特征建模。
-
ACM MM 2022 | 腾讯优图11篇论文入选,含盲超分辨率算法、视频场景分割分类等研究方向
- https://zhuanlan.zhihu.com/p/543066761
-
网易伏羲4篇论文入选ACM MM2022,再创游戏AI领域佳绩
- https://zhuanlan.zhihu.com/p/556988297
-
【ACMMM 2022】PMN论文解读与复现
- https://zhuanlan.zhihu.com/p/544592330
- 本文是入选ACM MM 2022 Best Paper Runner-up Award的工作。
- 本工作基于噪声建模和配对真实数据提出了一种用于Raw单帧去噪的新训练方法。本工作核心在于改造数据而与神经网络的结构无关,因此适用于各类去噪算法
-
ACM MM 2022 | 内容和梯度引导的模型驱动单图像反射移除网络
- https://zhuanlan.zhihu.com/p/561593611
- 深圳大学计算机与软件学院
- 该工作针对单图像反射移除任务提出了一个内容和梯度引导的深度展开网络。该方法结合了模型驱动和数据驱动的优点,不仅能够保持较好的反射移除性能,而且具备良好的可解释性。
-
ACM MM’2022 | 首个针对跨语言跨模态检索的噪声鲁棒研究工作
- https://zhuanlan.zhihu.com/p/561151473‘
- 虽然目前传统的跨模态检索工作已取得了巨大的进展,但由于缺少低资源语言的标注数据,这些工作通常关注于高资源语言(比如英语),因此极大地限制了低资源语言在该领域的发展。
-
[论文阅读] ACM 2022 best paper: Search-oriented Micro-video Captioning
- https://zhuanlan.zhihu.com/p/573669606
- 聂礼强团队与快手合作,斩获ACM MM 2022最佳论文奖
- https://mp.weixin.qq.com/s/dkKOmwta1olBAlrsSwUhOg
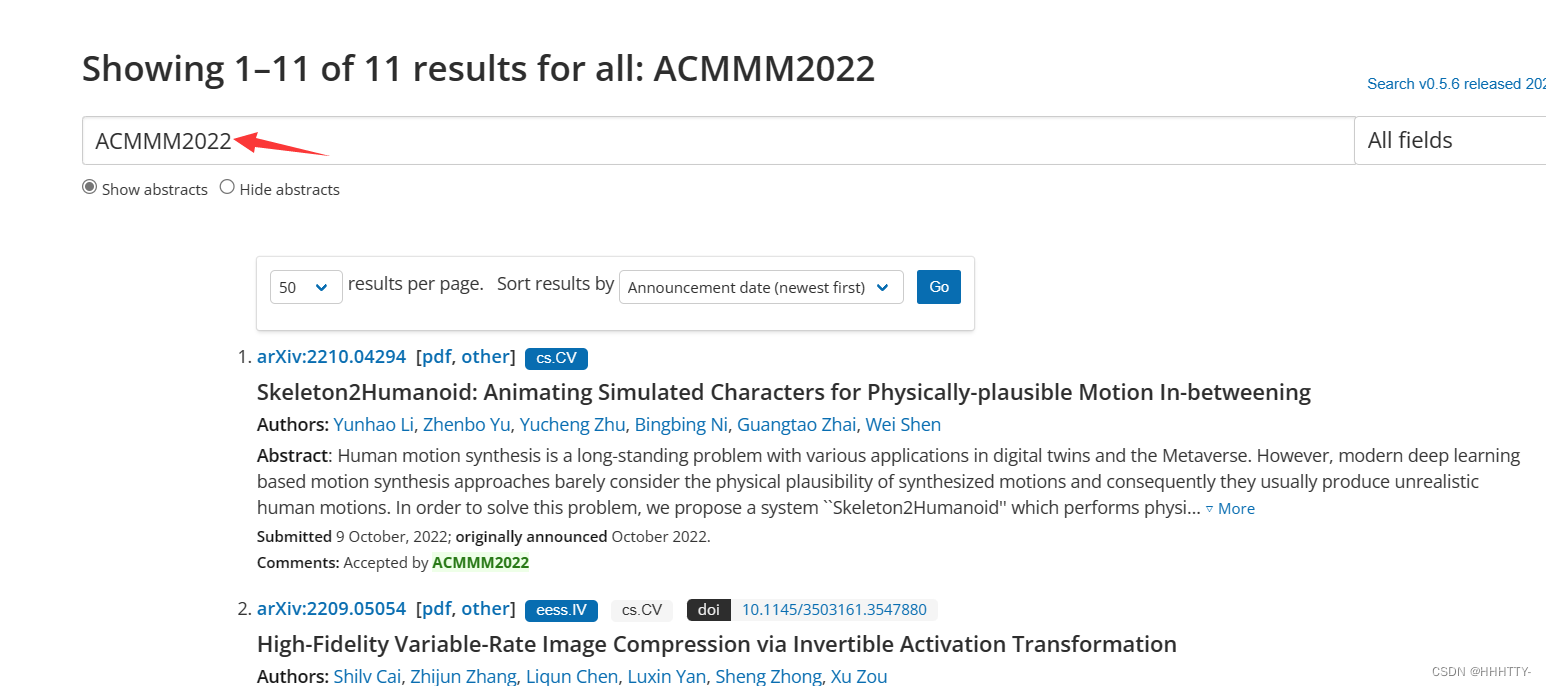
arxiv上 ACM MM2022 论文汇总
-
网址
- https://arxiv.org/search/?query=ACMMM2022&searchtype=all&abstracts=show&order=-announced_date_first&size=50
-
ACMMM2022