文章目录
- 前言
- 决策和流量方向
- 接收到帧时通知驱动程序
- 轮询
- 中断
- 在中断期间处理多帧
- 定时器驱动的中断事件
- 组合
- 范例
- 中断处理函数
- 下半部函数存在的原因
- 下半部解决方案
- 并发和上锁
- 抢占功能
- 下半部函数
- 微任务
- 软IRQ初始化
- 未决软IRQ的处理
- __do_softirq函数
- 依体系结构处理软IRQ
- ksoftirqd内核线程
- 启动线程
- 微任务处理
- 网络代码何时使用软IRQ
- softnet_data结构
- softnet_data字段
- softnet_data初始化
前言
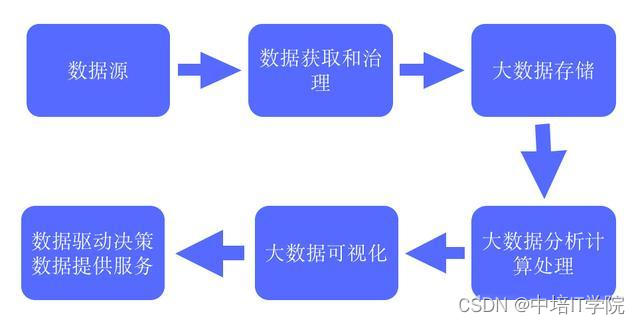
这一篇我们将按照一个个的功能或一个个的子系统分析如何实现网络,为什么要引入某些功能,以及当功能之间有意义时彼此之间是如何交互的进行分析。
决策和流量方向
封包经过网络协议栈所走的路径,会随封包是接收的,传输的还是转发的而不同,参考下图
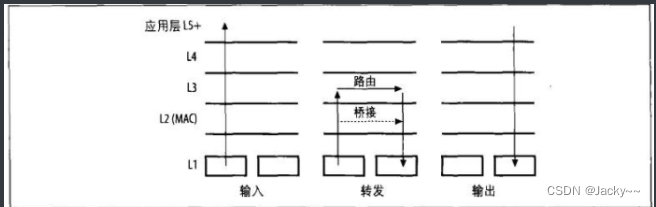
处理时的差异性也依赖于编译内核的功能,以及这些功能是如何配置的而定。最后,所包括的设备也会造成差异,因为不同的设备支持不同的功能。
虚拟设备,如我们熟悉的回环设备,倾向于使用网络协议栈中的快捷方式。这些设备只是软件而已。例如,回环接口和任何硬件无关,但是绑定接口则进和一块或多块网络卡间接相关。因此,有些虚拟设备可以免除硬件上的某些限制(如MTU),因而可以提高性能。
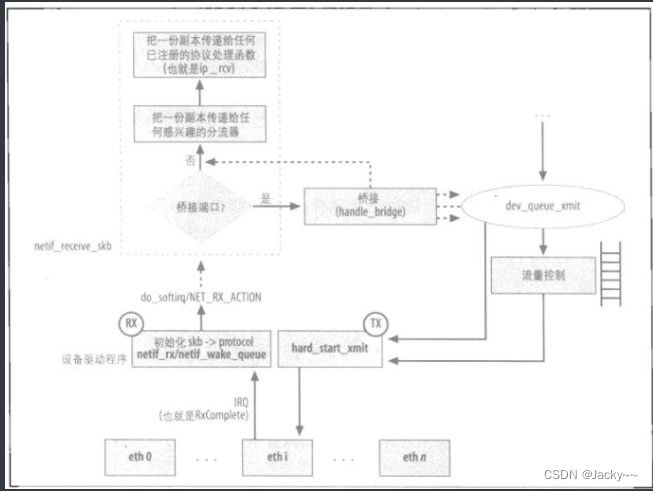
下图是一个丽新娘的打蓝图,当然,相当简略。例如,没有显示导致丢弃帧的所有条件。此图包括其他与输入路径有关的细节,后面会详细分析
接收到帧时通知驱动程序
设备与内核可以使用两种主要技术来交换数据:轮询和中断。这两种技术的组合也是有效的选项。本节概述驱动程序用于通知内核接收到帧最常见的方法,以及每种方法的优缺点。有些方法依赖于设备上的特定功能是否可用(如特殊的定时器),而有些可能必须对驱动程序、操作系统或者两者做变更。
理论上,这里的讨论使用任何设备类型,但是,这些设备看成是产生高交互量(就是帧的接收)的网络接口卡会比较好。
轮询
通过这种技术,内核可不断持续检查设备是否有话要说。例如,内核可以持续读取设备上的一个内存寄存器,或者当一个定时器到期时就回头去检查那个内存寄存器。可以想象得到,这种做法会轻易浪费掉很多系统资源,因此,如果操作系统和设备可以使用其他技术(如中断)轮询就很少会被采用。不过在有些情况下,轮询是最佳方法。
中断
此时,当特定事件发生时,设备驱动程序会代表内核指示设备产生硬件中断。内核将中断其他的活动,然后调用一个驱动程序所注册的处理函数,以满足设备的需要。当事件时接收到一个帧时,处理函数就会把帧排入队列某处,然后通知内核。这一项技术相当常见,依然是低流量负载下的最佳选择。遗憾的是,在高流量负载下就无法良好的运行:没接收一个帧就强制产生中断,很快就会让CPU为处理中断事件浪费所有的时间。
负责接受帧的代码分成两部分:首先,驱动程序把该帧拷贝到内核可访问的输入队列,然后,内核再予以处理,通常是把那个帧传给一个相关的(如IP)专用的处理函数。第一部分会在中断环境中执行,而且可以抢占第二部分的执行。也就是说,接收输入帧并将其拷贝到队列的代码比实际处理帧的代码有较高的优先级。
在高流量负载下,中断代码会持续抢占正在处理的代码。这种结果很明显:到某一时间点,输入队列会满,但是由于应该让帧退出队列并予以处理的代码的优先级过低而没有机会执行,结果系统就崩溃了。新的帧无法排入队列,因为已经没有空间了。而旧的帧又无法被处理,因为没有CPU可供其使用。这种情况文献中称为接收-活锁(receive-livelock)。
总之,这种技术的优点是帧的接收及其处理之间的延时很短,但是,在高负债下就无法运行良好。多数网络驱动 程序都使用中断。后面会大量讨论中断的工作方式。
在中断期间处理多帧
有不少Linux设备驱动程序使用这种方法。通知内核中断事件已发生而且驱动程序处理函数也执行了,接着处理函数会持续下载帧,然后将之排入内核的输入队列,知道帧最大数目(或者一段时间)到达为止。当然,有可能一直做下去,直到队列清空为止,但是我们要记住,设备驱动程序应该扮演优良组件的角色。驱动程序必须与其他子系统共享CPU,与其他设备共享IRQ线。合于礼法的行为尤其重要,因为当驱动程序运行时中断功能会关闭。
存储限制也要适用,如同前面所述。每个设备的内存数量都有限,因此,其能存储的帧数目也有限。如果驱动程序不能以实时的方式处理帧,缓冲区就会填满,而新的帧就会被秀气。如果承受负载的设备一直处理送进来的帧,直到队列为空,那么饿死的情形就会发生在其他设备身上。
这种技术不需要对操作系统做任何变更,完全是设备驱动程序内实现的。
这种方法有其他一些变种。驱动程序可以只关闭某个设备的中断事件,该设备的输入队列中有一些帧,然后把轮询驱动程序的队列的任务交给一个内核处理函数,不再把所有中断事件都关闭,之后令驱动程序为内核把帧排入队列以便于处理。而这正是为什么Linux采用新接口——NAPI的原因。然而,与这里描述方法不同的是,NAPI需要对内核做变更。
定时器驱动的中断事件
这种技术是前几种技术的增强版。驱动程序会指示设备定期产生一个中断事件,不再是让设备以异步方式通知驱动程序有关帧的接收。然后,处理函数会检查自从上次中断事件以来是否有任何帧到达,然后一次处理所有的帧。最好是在驱动程序有话要说时才定期产生中断事件。
目前,只有少数设备能够提供这种能力,所以Linux内核中的所有驱动程序不一定都能用这种解决方案。驱动程序可以把该设备的中断事件关闭,然后改用内核定时器,借此模拟这种能力。然而,驱动程序没有硬件的支持,处理定时器时CPU能花费的资源也不像设备那么多,所以,驱动程序也没办法让定时器的调度过于频繁。结果,绕到最后就变成轮询方法了。
组合
前面已经说明每种方法都有其优缺点,有些时候,有可能将它们组合起来得到更好的东西。我们说,在低负载下,纯中断模型可以保证低延时,但在在高负载下,其运行就很糟糕。另一方面,定时器驱动的中断事件在低负载下可能会引入过多的延时,而且浪费太多的CPU时间,但是在高负载下,可以大量减少CPU用量并解决接收-活锁问题。好的组合就是在低负载下使用中断技术,在高负载下切换至定时器驱动的中断事件。例如,Linux内核中的tulip驱动程序就可以这么做(参见drivers/net/tulip/interrupt.c)
范例
处理多个帧的平衡方法如下列代码片段所示(取自drivers/net/3c59x.c Ethernet驱动程序)。这段代码是vortex_interrupt中的关键几行代码,此函数是由驱动程序注册,作为处理来自3Com的Vortex系列设备的中断处理函数:
static irqretum_t vortex_interrupt(int irq, void *dev_id, struct pt_regs *regs)
{
int work_doen = max_interrupt_work;
ioaddr = dev->basc_addr;
... ... ...
status = inw(ioaddr + EL3_STATUS);
do{
... ... ...
if(status & RxComplete)
vortex_rx(dev);
if(--work_done < 0){
/*关闭所有未决的中断事件。*/
... ... ...
/*定时器会重新开启中断事件*/
mod_timer(&vp->timer, jiffies + 1*HZ);
break;
}
... .... ...
}while((status = inw(ioaddr + El3_STATUS)) & (IntLatch | RxComplete))
.... ... ...
}
其他遵循此模型的驱动程序也有类似的东西,可能把EL3_STATUS和RxComplete符号叫做其他名称,而且xxx_rx函数的实现可能也不同,但是其架构和此列所示非常接近。
在vortex_interrupt之中,驱动程序从设备读取发生中断事件的原因,然后存储至status。网络设备产生一个中断事件的原因有很多种,而且好几种原因都可归结于单一中断事件。如果RxComplete(此驱动程序特别定义的符号,意指已接收一个新的帧)是这些原因之一,程序就会启用vortex_rx。执行期间,该设备的中断事件就会被关闭。然而,驱动程序可以读取卡上的一个硬件寄存器,同时寻找是否已有新的中断事件发布。已有新的中断事件发布时,IntLatch标识就是真(当驱动程序把该中断事件处理掉时,就会将此标记清除)
vortex_interrupt会持续处理送进来的帧,直到寄存器说有个中断事件处理未决中,而且是起因于接收一个帧(RxComplete)。这也就是说,只有多次出现的RxComplete中断事件能以一次处理。其他类型的中断事件比较少见,就要等待。
最后,如果达到了可以处理的输入帧的最大数目时,循环就终止,存储在work_done中,这就优良组件该做的事。驱动程序使用默认值32,但是可以在模块加载期间调整此值。
中断处理函数
中断事件触发的函数的调度是很复杂的主题,即使与网络间并没有特备厉害的关系,也还是值得做一些研究。因此我们讨论不同网络驱动程序处理中断事件的各种方式,然后介绍下半部(BH)和软中断(softirq)的概念。
前面我们了解了设备驱动程序如何以IRQ编号注册其处理函数,但是,我们没有说明硬件中断事件如何把帧的处理委托给软中断处理函数。这里我们要说明与接受一个帧相关联的中断事件请求如何处理的,然后再说明协议处理函数在何处接收其封包。我们会说明硬IRQ和软IRQ之间的关系,以及为什么需要软IRQ。
下半部函数存在的原因
每当CPU接收一个中断通知信息时,就会调用与该中断事件相关联的处理函数,这种关联性由编号识别。在该处理函数执行期间,即内核程序处于中断环境(interrupt context)中,服务于该中断事件的CPU就会被关闭其中断功能。也就说,如果一个CPU忙于服务一个中断事件,就不能服务其他中断事件,无论是相同类型或是不同类型的中断事件。CPU也不能执行其他进程:CPU完全属于该中断处理函数,而且不能被抢占。
最简单的情况下,这些是一个中断事件引起的主要事件:
-
设备产生一个中断事件,而硬件通知内核
-
如果内核没有为另一个中断事件服务(而且如果中断功能没有因为其他原因而被关闭),就会看到通知信息。
-
内核关闭本地CPU的中断功能,然后执行与所接受的中断事件类型相关联的处理函数。
-
内核会离开该中断处理函数,然后重启本地CPU的中断功能。
简而言之,中断处理函数是非抢占的,而且是非可再进入的。当一个函数无法被另一个自身的调用而中断,该函数就定义为非可再进入;就中断处理函数而言,就是说其执行的中断功能会关闭。这种设计选择有助于降低竞争情况的可能性。然而,因为CPU能做的事如此有限,内核做非可抢占设计以及等待被CPU服务的进程,就会对性能有潜在的严重影响。
因此,中断处理函数所做的工作应该尽快完成。中断处理函数在中断环境所需的处理量依赖于事件的类型。例如,键盘可能只需要在每次有一个按键被按下时传送一个中断事件,而处理此事只需要很少的能力:处理函数只需要把按键的编码存储于某处,而且最多每秒执行几次。在其他时间,处理一个中断事件所需所需要的动作并非琐碎之事,而且其执行需要花费很多CPU时间。例如,网络设备就有相当复杂的工作:必须分配一个缓冲区(sk_buff),把接收到的数据拷贝进去,对缓冲区结构内的一些参数做初始化以告知较高层协议的处理函数来自于驱动程序的数据是什么种类等等。
以下该由“下半部”处理程序的概念登场。尽管由一个中断事件所触发的动作需要用掉很多CPU时间,通常此动作的内容多数都可以等待。中断事件可以先对CPU抢占,这是因为如果操作系统让硬件等太久,可能遗失数据。对实时数据流而言,这显然是真的,但是对任何必须把送进来的数据存储在固定大小的缓冲区的硬件而言,这也是真的。此外,如果硬件遗失数据,通常无法再找回来。
另一方面,如果内核或用户空间进程必须被延迟或被抢占,则没有数据会遗失(实时系统例外,因其必须使用完全不同的方式处理进程和中断事件)。根据这些考虑,现代中断处理函数就区分上半部和下半部。上半部就是释放CPU之前必须执行的一切事务,以此保留数据;下半部则包含所有可以从容做完的一切事情。
你可以把下半部定义成指定特定函数的异步请求。一般而言,当想执行函数时,不用请求任何东西,只要调用就行了。当一个中断事件到达时,有很多事要做,不想立刻中断。因此,你可以把多数工作打包成一个函数,当成下半部函数。
与简单模型相比,下列模型允许内核把中断功能关闭的时间大幅减少:
-
设备发出信号给CPU,通知有中断事件
-
CPU会执行相关的上半部,关闭后续的中断事件通知信息,直到处理函数完成其工作为止。
-
一般而言,上半部会执行下列工作
-
把内核稍后处理该中断事件的所有信息保存在RAM某处。
-
在某处标记一个标识(或者使用另一种内核机制触发某事),以确保内核会知道该中断事件,而且会使用处理函数锁保存的数据以完成事件的处理。
-
终止前,会重新开启本地CPU的中断事件通知信息功能。
-
稍后某个时刻,当内核不用再做一些紧迫之事时,就会检查该中断处理函数所设的标识(指出有要求处理的数据存在),然后调用相关的下半部函数。内核也会清除该标识,稍后当中断处理函数再次设置该标识时,就能再认出来。
随着时间的流逝,Linux开发人员已尝试过各种类型的下半部,不同理性遵循不同规则。网络在新的产品开发上扮演了一个重要的角色,这是因为网络需要低延时,也就是帧接收和其传递之间的时间量要最小。与其他类型的设备相比,低延时对网络设备驱动程序的重要性更高,这是因为涉及接收和传输的任务数目很高。声卡是另一种需要快速响应的设备范例。
下半部解决方案
内核提供各种不同机制以实现各种下半部以及一般的延期性工作。这些机制的主要差别在于下列几点:
-
运行环境- 内核把来自于其他内核代码和用户空间进程的中断事件区别看待。当下半部函数所执行的函数可以进入休眠时,就会受限于进程环境中的许可机制,有别于中断环境。
-
并发和上锁- 当一种机制可以利用SMP时,就涉及如何强制(必要时)串行化以及锁机制如何影响伸缩性。
这里我们只讨论把鞋不需要进程环境的机制,也就是软IRQ和微任务。下面我们会简述这些机制对于并发以及上锁的意义。
当必须延期一个可能会休眠函数的执行时,必须使用一个专用的内核线程或工作队列。工作队列只是一种队列,你可以把执行一个函数的请求排入队列,然后一个内核线程就会去负责这件事。就此而言,此函数会在该内核线程的环境内执行,因此,休眠是可以的。因为网络代码主要使用软IRQ和微任务,所以我们不会谈工作队列。
并发和上锁
并发指的是一些函数之间可以彼此干扰,也许是因为它们在不同的CPU中调度,或者是因为有一个函数被内核挂起,而去执行另一个函数。
这里要介绍三种不同类型的函数,分别用来处理中断事件、旧式下半部、软IRQ及微任务。这些都可用于为一个函数的执行进行调度,但是彼此间存在很大的差异。就并发而言,我们把差异性总结如下:
-
只有一个旧式下半部可以在任何时刻执行,无论CPU的数目有多少个。
-
任何时刻,每个微任务只有一个实例可以执行。不同的微任务可以同时在不同的CPU中执行。也就是说,就所有微任务而言,不需要强制任何串行化之事,因为内核已经强制了:同一个微任务不能有多个实例同时执行。
-
任何时刻,一个CPU中每个软IRQ只能有一个实例可以执行。然后,相同的IRQ可以在不同的CPU中同时执行。也就是说,对任何IRQ而言,必须确保不同的CPU对共享数据的访问,都采用正确的上锁机制。为了提高并行性,软IRQ应该尽可能设计成只访问每个CPU的数据,以减少大量使用上锁机制的需求。
一些与软件中断及硬件中断相关的API
| in_interrupt | 如果CPU正在服务于一个硬件中断或软件中断,或者抢占功能是关闭的,in_interrupt就返回TRUE |
|---|---|
| in_softirq | 如果CPU正在服务于一个软件中断,in_softirq就返回TRUE |
| in_irq | 如果CPU正在服务于一个硬件中断,in_irq就返回TRUE |
| softirq_pending | 如果CPU(其ID当成输入自变量传递进来)至少有一个软IRQ在未决中(也就是调度准备执行),就返回TRUE |
| local_softirq_pengding | 如果本地CPU至少有一个软IRQ在未决中,就返回TRUE |
| __rasie_softirq_irqoff | 设置与输入的软IRQ类型相关联的标识,将该软IRQ标记为未决 |
| raise_softirq_irqoff | 这是一个内含__raise_softirq_irqoff的包裹函数,当in_interrupt()返回FALSE时,也会唤醒ksoftirqd。 |
| raise_softirq | 这是一个内含raise_softirq_irqoff的包裹函数,而调用raise_softirq_irqoff之前,会先关闭硬件中断,然后再恢复其原有状态。 |
| __local_bh_enable | __local_bh_enable会开启本地CPU的下半部(等同于软IRQ/微任务一个开启),此外,如果有任何软IRQ处于味觉中,并且in_interrupt()返回FALSE,则local_bh_enable也会启动invoke_softtirq. |
| local_bh_enable | |
| local_bh_disable | |
| local_bh_disable | 关闭本地CPU下半部 |
| local_irq_disable | |
| local_irq_enable | 关闭和开启本地CPU的中断功能 |
| local_irq_save | local_irq_save会先把本地CPU的中断状态保存起来,然后再予以关闭。 |
| local_irq_restore | local_irq_restore会恢复本地CPU的中断状态(源于local_irq_save先前所保存的信息) |
| spin_lock_bh | 分别为取得和释放回转锁(spin lock)。这两个函数在操作过程中会关闭和重新开启下半部以及抢占功能 |
| spin_unlock_bh |
抢占功能
在分时系统中,内核总是能按其意愿抢占用户进程,但是内核本身通常是非可抢占的;也就是说,一旦开始运行,就不断被中断,除非已准备好放弃控制权。非可抢占内核有时会阻碍已准备好可以执行的高优先级进程,因为内核正在为一个低优先级进程执行一个系统调用。为了支持实时扩展功能以及其他原因,Linux在2.5版本内核开发周期中终于实现了完全可抢占。有了这个新的内核功能,系统调用和其他内核任务就可以被其他较高优先级的内核任务给抢占掉。
为了支持SMP上锁机制,必须从内核中把那些关键节区消除掉(非可抢占代码),在这方面已经做了很多工作,因此,加上完整的抢占功能并没有对内核造成重大变革,一旦加入抢占功能,开发人员需要明确定义在何处予以关闭(硬、软件中断代码中,调度器本身的内部,以及由回转锁和读/写锁所保护的代码中等等)。
然而,有些时候抢占功能必须予以关闭,正如中断功能一样。
下列几个函数可控制抢占功能:
| preempt_disable | 为当前任务关闭抢占功能。可以重复调用,递增一个引用计数器 |
|---|---|
| preempt_enable | |
| preempt_enable_no_resched | 与preempt_disable相反,可使抢占功能再度开启。preempt_enable_no_resched只是递减一个引用计数器,使得当期值达到零时,可以让抢占功能再度开启。此外,preempt_enable会检查计数器是否为零,然后强制调用schedule(),让任何较高优先级的任务去执行。 |
| preempt_check_resched | 此函数由preempt_enable调用,与preempt_enable_no_resched不同 |
每个进程都有一个计数器,名为preempt_count,内嵌于thread_info结构内,指出特定的进程是否容许抢占功能。此字段可以通过preempt_count()读取,而且会通过定义在include/linux/preempt.h中的inc_preempt_count和dec_preempt_count函数间接操作。有些情况下,内核不应该被抢占的,如正在服务于硬件,以及其所用的一些函数调用之一显示出抢占功能已关闭。因此,preempt_count被分成三个组件,每个字节都是一个计数器,各自针对一种需要非抢占功能的情况:硬件中断、软件中断以及一般非抢占情况。preempt_count的配置如下
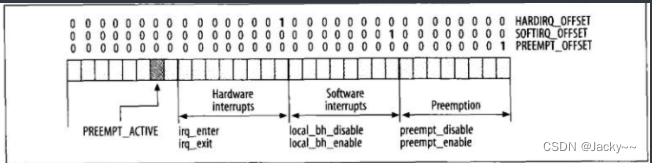
此图除了显示出每个字节的用途外,也显示出操作该字节的主要函数。此时,并没有完全用到高位字节,但是,调用schedule()函数并通知该函数它已被调用而抢占了当前任务之前,其第二最低位会被设置。在include/asm-xxx/hardirq.h中有几个宏,可以让你轻易读写preempt_counter,其中一些包括上图所示的XXX_OFFSET变量,而且图中所列的函数会予以使用,以递增或递减正确的字节。
尽管如此复杂,每当必须对当前进程做检查以了解是否可被抢占时,内核所必须知道的就是preempt_count是否为NULL(抢占功能为何被关闭其实不重要)。
下半部函数
下半部的基础架构必须解决下列需求
-
把下半部分类成适当类型
-
注册下半部类型及其处理函数间的关联关系
-
为下半部函数调度,以准备执行。
-
通知内核已有调度的BH存在。
微任务
微任务是函数,可以延迟某个中断事件或其他任务,使其晚一点执行。微任务建立在软IRQ之上,通常是由中断处理函数发出,但是内核其他部分也会用到微任务,后面会分析到的邻居子系统。
我们知道HI_SOFTIRQ适用于实现高优先级的微任务,而TASKLET_SOFTIRQ是用于实现较低的优先级的微任务。每次,发出延迟执行的请求之后,tasklet_struct结构的一个实例就会排入一个由HI_SOFTIRQ所处理的列表,或者另一个由TASKLET_SOFTIRQ所处理的列表。
由于软IRQ是由每个CPU各自独立处理,每个CPU有两份未决tasklet_struct列表,一份与HI_SOFTIRQ关联,而另一份与TASKLET_SOFTIRQ关联,因此就应该没什么好惊讶的了。以下是来自kernel/softirq.c的定义:
static DEFINE_PER_CPU(struct tasklet_head tasklet_vec) = {NULL};
static DEFINE_PER_CPU(struct tasklet_head tasklet_hi_vec) = {NULL};
初看起来,微任务似乎就是旧式的下半部函数,但实际上有一些实质性的差异:
-
不同微任务的数据不受限制,但是
bh_base的每个标识只受限于一种类型的下半部函数。 -
微任务提供两种等级的优先级
-
不同微任务可以在不同的CPU上同时运行
-
微任务与旧式下半部函数及软IRQ的不同之处就是动态,不需要在
XXX_BH或XXX_SOFTIRQ枚举列表中静态声明。
tasklet_struct数据结构定义在include/linux/interrupt.h中,如下所示:
struct tasklet_struct
{
struct tasklet_struct *next;
unsigned long state;
atomic_t count;
void (*func)(unsigned long);
unsigned long data;
};
字段描述
-
struct tasklet_struct *next- 是一个用于把关联到同一个CPU的未决结构链接起来的指针。新元素由函数
tasklet_hi_schedule和tasklet_schedule添加到头部。
- 是一个用于把关联到同一个CPU的未决结构链接起来的指针。新元素由函数
-
unsigned long state-
位图标识,其可能的取值由
TASKLET_STATE_XXX枚举列表 -
TASKLET_STATE_SCHED- 此微任务已进入调度准备执行,而该数据结构已放在
HI_SOFTIRQ或TASKLET_SOFTIRQ(依赖于所分派的优先级)关联列表中。相同微任务不能同时在不同的CPU上调度。当第一个微任务还没有开始执行前,其他执行此微任务的请求又到来了,则这些请求会被丢弃掉。因为对任何微任务而言,都只能有一个实例在执行中,所以,没有理由再调度而又多执行一次
- 此微任务已进入调度准备执行,而该数据结构已放在
-
TASKLET_STATE_RUN- 此微任务正在被执行中。此标识用于防止相同微任务的多个实例被同时执行。这一点只对SMP系统有意义。此标识的操作通过三个上锁函数完成。
tasklet_trylock、tasklet_unlock以及tasklet_unlock_wait。
- 此微任务正在被执行中。此标识用于防止相同微任务的多个实例被同时执行。这一点只对SMP系统有意义。此标识的操作通过三个上锁函数完成。
-
-
atomic_t count- 有些情况下,可能必须暂时关闭而后重新开启微任务。这是由计算器完成的:零值表示微任务被关闭(因此不可执行),而非零值意味着微任务已开启。其值由
tasklet[_hi]_enable和tasklet[_hi]_disable函数递增和递减。
- 有些情况下,可能必须暂时关闭而后重新开启微任务。这是由计算器完成的:零值表示微任务被关闭(因此不可执行),而非零值意味着微任务已开启。其值由
-
void (*func)(unsigned long) -
unsigned long data- func要执行的函数,而data是选用的输入数据,可传给func
下面是一些处理微任务的重要内核函数:

软IRQ初始化
在内核初始化期间,softirq_init会以两个通用软IRQ对软IRQ层做初始化:tasklet_action和tasklet_hi_action(分别与TASKLET_SOFTIRQ以及HI_SOFTIRQ相关联)。
void __init softirq_init()
{
open_softirq(TASKLET_SOFTIRQ, tasklet_action, NULL);
open_softirq(HI_SOFTIRQ, tasklet_hi_action, NULL);
}
这两个由网路代码NET_RX_SOFTIRQ和NET_TX_SOFTIRQ所用的软件IRQ是在net_dev_init(网络初始化函数之一)中初始化的。
HI_SOFTIRQ主要是由声卡设备驱动程序使用的。
TASKLET_SOFTIRQ的使用者包括:
-
网络适配卡的驱动程序(不仅限于Ethernet)。
-
各种其他设备驱动程序。
-
媒介层(USB、IEEE1394等)。
-
网络子系统(邻居、ATM qdisc等)
未决软IRQ的处理
前面我们分析过do_softirq何时会被启用以负责处理那些未决的软IRQ。这里我们来说明该函数的内部细节。
如果CPU正在服务于硬件或软件中断,do_softirq就会停止而什么事也不做。此函数会调用in_interrupt以检查此事。
如果do_softirq决定继续下去,就会以local_softirq_pending把未决的软IRQ存储在pending
#ifndef __ARCH_HAS_DO_SOFTIRQ
asmlinkage void do_softirq(void)
{
if(in_interrupt())
return;
local_irq_save(flags);
pending = local_softirq_pending();
if(pending)
__do_softirq();
local_irq_restore;
}
EXPORT_SYMBOL(do_softirq);
#endif
由上述程序片段来看,do_softirq执行似乎IRQ是关闭的,但并非如此。只有在操作未决的软IRQ的位图时(也就是访问softnet_data结构),IRQ才会被关闭。等一下就会知道,执行IRQ函数时,__do_softirq会在内部重新开启IRQ。
__do_softirq函数
在do_softirq运行时,同一种软IRQ类型有可能被调度多次。由于在执行软IRQ函数时IRQ会被开启,而服务于一个中断事件时,未决的软IRQ的位图也可以受到操作,因此,任何已被__do_softirq执行的软IRQ函数在__do_softirq本身执行期间有可能会被重新调度。
因此__do_softirq重启IRQ之前,会把未决的软IRQ的当前位图存储至局部变量pending,然后使用local_softirq_pending() = 0将其从与本地CPU相关联的softnet_data实例中清楚。最后,再根据pending调用所有必需的处理函数。
一旦所有处理函数都已被调用,__do_softirq会同时检查是否有任何软IRQ又已进入调度(这个请求会关闭IRQ)。如果至少有一个未决的IRQ、则会重复整个流程。然而,__do_softirq只会重复最多MAX_OSFTIRQ_RESTART次(实验结果发现,10次就可以工作的很好)。
使用MAX_SOFTIRQ_RESTART是一种设计决策,为的是在几个CPU中的其中之一上,网络流中的某种类型的中断事件不会使其它中断事件饿死。没有__do_softirq的限制,当服务器因为网络流量而承受高负载,并且NET_RX_SOFTIRQ中断事件的数目达到最高的话,就很容易会发生饿死的事。
来看饿死是怎么发生的。do_IRQ引发NET_RX_SOFTIRQ中断事件,使得do_softirq被执行。__do_softirq会清除NET_RX_SOFTIRQ标识,但是,结束前可能会被另一个中断事件中断,使得NET_RX_SOFTIRQ会再次被设置,结果就这样没完没了。
现在,我们来看__do_softirq的关键部分是如何启用软IRQ函数的。每一次一种软IRQ类型受到服务时,其位就会从活跃的软IRQ的本地副本pending中清除。h会初始化为指向全局数据结构softirq_vec,该数据结构持有IRQ类型及其函数处理函数间的关联。(例如,NET_RX_SOFTIRQ是由net_rx_action处理)。当位图被清除时,此循环结束。
最后,如果因为do_softirq已重复其工作MAX_SOFTIRQ_RESTART次,有些未决的软IRQ仍无法被处理而必须返回,则ksoftirqd线程会被唤醒,赋予稍后处理这些未决的IRQ的责任。因为do_softirq会在内核许多地方启用,实际上很有可能在ksoftirqd线程调度前,晚一点调用do_softirq就会处理这些中断事件。
#define MAX_SOFTIRQ_RESTART
asmlinkage void __do_softirq(void)
{
struct softirq_action *h;
__u32 pending;
int max_restart = MAX_SOFTIRQ_RESTART;
int cpu;
pending = local_softirq_pending();
local_bh_disable();
cpu = smp_processor_id();
restart:
/*开启irqs前先重设pending位屏蔽*/
local_softirq_pending() = 0;
local_irq_enable();
h = softirq_vec;
do{
if(pending & 1){
h->action(h);
rcu_bh_qsctr_inc(cpu);
}
h++;
pending >> = 1;
}while(pending);
local_irq_disable();
pending = local_softirq_pending();
if(pending && --max_restart)
goto restart;
if(pending)
wakeup_softirqd();
__local_bh_enable();
}
依体系结构处理软IRQ
kernel/softirq.c中所提供的do_softirq函数可以被体系结构代码(最后还是调用__do_softirq)所提供的另一个函数复写。这说明了为什么kernel/softirq.c中do_softirq的定义会以__ARCH_HAS_DO_SOFTIRQ包裹起来检查。
有些体系结构会定义自己的do_softirq版本,包括i386.当体系结构使用4KB堆栈(而非8KB),而且以剩余的4KB去实现堆栈来处理IRQ和软IRQ时,就会使用这类体系结构版本。
ksoftirqd内核线程
后台内核线程被分派的工作是检查没被前述函数执行到的软IRQ,然后,在必须把CPU交还给其他活动前,尽可能多地执行几个这些没被执行的软IRQ。每个CPU都有这么一个内核线程,名为ksoftirqd_CPU0、ksoftirqd_CPU1等。后面一节会说明这些线程在CPU引导期间是如何启动的。
和这些线程相关的ksoftirqd函数其实相当简单,就定义在同一个文件中(softirq.c):
static int ksoftirqd(void * __bind_cpu)
{
set_user_nice(current, 19);
...
while(!kthread_should_stop()){
if(!local_softirq_pending())
sechedule();
__set_current_state(TASK_RUNNING);
while(local_softirq_pending()){
/*抢占功能关闭可防止CPU离线(offline)。
但如果已离线,表示我们在错误的CPU上,不要处理*/
preempt_disable();
if(cpu_is_offline((long)__bind_cpu))
goto wait_to_die;
do_softirq();
preempt_enable();
cond_resched();
}
set_currrent_state(TASK_INTERRUPTIIBLE);
}
__set_curent_state(TASK_RUNNING);
return 0;
....
}
有几个小细节需要注意:进程优先级也称为仁慈优先级,其价值介于-20~+19之间。ksoftirqd线程被给定一个很低的优先级19,。只有这么做,那些时长执行的软IRQ(如NET_RX_SOFTIRQ)才不会完全绑定CPU,使得其他进程根本毫无资源可用。我们一直知道代码中有许多地方都会启用do_softirq,因此,这样的低优先级别并没什么阻碍。启动之后,循环只会持续调用do_softirq(抢占功能总是关闭),知道下列条件之一成立:
-
没有未决IRQ需要处理了(
local_softirq_pending()返回FALSE)。在这种情况下,此函数会把现线程的状态设成TASK_INTERRUPTIBLE,然后调用sechdule()以释放CPU。线程通过wakeup_softirq(可以由wakeup_softirq本身和raise_softirq_irqof调用)而被唤醒。 -
线程已执行太久了,被要求释放CPU。除了其他该做之事外,与定时器中断事件相关联的处理函数会设置
need_resched标识,通知说当前进程/线程已用掉时间片(time slot)。在这种情况下,ksoftirq会释放CPU,而使其状态保持在TASK_RUNNING,因为很快就会重新继续下去。
启动线程
每个CPU都有一个ksofirqd线程。当系统的第一个CPU上线(online)时,第一个线程就会在do_pre_smp_initcalls中启动(内核引导期间)。至于其他在引导时间运行起来的CPU,以及支持可热插拔CPU的系统上,有其他稍后开启的CPU,其ksoftirqd线程则是由cpu_chain通知链负责。
前面已经介绍过通知链。cpu_chain链让各种子系统知道一个CPU何时起来运行或者何时死掉。软IRQ子系统会以spawn_ksoftirqd(从刚开提到的so_pre_smp_initcalls函数捏调用)对cpu_chain注册。回调函数cpu_callback会处理来自于cpu_chain的通知信息,而且可用于对必要的各个CPU数据结构进行初始化,以及启动CPU上的ksoftirq线程。
CPU_XXX通知信息的完整列表在include/linux/notifier.h中,但是这里我们只需要知晓其中四个:
| CPU_UP__PREPARE | 当CPU将要运行起来但还没就绪时,就会产生 |
|---|---|
| CPU_ONLIE | 当CPU就绪时,就会产生 |
| CPU_UP_CANCELLED | |
| CPU_DEAD | 只有当内核编译为支持可热插拔CPU时,这两条信息才会产生。当先前的CPU_UP_PREPARE通知信息所触发的任务之一失败时,就会使用第一个通知信息,因此,CPU就无法上线了。当CPU死掉时,就会用到第二个。 |
CPU_PREPARE_UP会建立线程,并将此与相关联的CPU绑定,但是没有唤醒该线程。
CPU_ONLINE唤醒该线程。当CPU死掉时,其相关联的ksoftirqd实例也会被杀掉:
static int __devinit cpu_callback(struct notifier_block *nfb, unsigned
long action, void *hcpu)
{
...
switch(action){
...
}
return NOTIFY_OK;
}
static struct notifier_block__devinitdata cpu_nfb = {
.notifier_call = cpu_callback
};
__init int spawn_ksoftorqd(void)
{
void *cpu = (void *)(long)smp_processor_id();
cpu_callback(&cpu_nfb, CPU_UP_PREPARE, cpu);
cpu_callback(&cpu_nfb, CPU_ONLINE, cpu);
register_cpu_notifier(&cpu_nfb);
return 0;
}
注意,通过register_cpu_notifier向cpu_chain注册前,spawn_ksoftirqd会直接调用两次cpu_callback。这是必要的,因为对于第一个上线的CPU不会产生CPU通知信息。
微任务处理
低延时微任务(TASKLET_SOFTIRQ)和高延时微任务(HI_SOFTIRQ)的两个处理函数都相同:只是处理的是两个不同的列表。因此,我们只说明其中一个tasklet_action,也就是与TASKLET_SOFTIRQ相关联的哪一个。
任何时刻,每个微任务都只有一个实例可以等待执行。当tasklet_schedule或tasklet_hi_schedule为一个微任务调度时,该函数会设置TASKLET_STATE_SCHED位。尝试重新为相同微任务调度时则会被忽略掉,因为TASKLET_STATE_SCHED已设置。只有当微任务开始执行时,该位才会被清除;因此,在微任务执行期间或者在其执行之后,另一个实例就能被调度了。
tasklet_action函数会把等待处理的为人诶列表拷贝到一个局部变量,然后清除该全局列表。此函数以中断功能关闭而执行的地方只有这里而已。关闭中断功能是必要的,为的是避免引发竞争,即其他中断处理函数可以把新元素添加到该列表中,但tasklet_action又在访问该列表。
此时,该函数会按照列表一个微任务接一个微任务地执行。就每个元素而言,如果下列条件都为成立,就会启用处理函数:
-
微任务已经停止运行,换言之,
TASKLET_STATE_RUN被清除(此函数会执行tasklet_trylock以得知TASKLET_STATE_RUN是否已设置,如果没有,tasklet_trylock就会设置该位)。 -
微任务已开启(
count是零)。
函数中实现这些活动的部分如下:
struct tasklet_struct *lust;
local_irq_disable();
list = __get_cpu_var(tasklet_vec).list;
__get_cpu_var(tasklet_vec).list = NULL;
local_irq_enable();
while(list){
struct tasklet_struct *t = list;
list = list->next;
if(tasklet_trylock(t)){
if(!atomic_read(&t->count)){
/*此时,由于微任务还没执行,而且已从未决的微任务列表中抽取出来,因此
TASKLET_STATE_SCHED标识必须设置*/
if(!test_and_clear_bit(TASKLET_STATE_SCHED, &t->state))
BUG();
t->func(t->data);
tasklet_unlock(t);
continue;
}
tasklet_unlock(t);
}
/*如果处理函数不能执行,微任务就会被放回列表中,而TASKLET_SOFTIRQ会重新调度
以完成那些现在因前述两点理由之一而并无法处理的所有微任务*/
local_irq_disable();
t->next = __get_cpu_var(tasklet_vec).list;
__get_cpu_var(tasklet_vec).list = t;
__raise_softirq_irqoff(TASKLET_SOFTIRQ);
local_irq_enable();
}
网络代码何时使用软IRQ
网络子系统分派两种不同的软IRQ。NET_RX_SOFTIRQ会处理进来的流量,而NET_TX_SOFTIRQ会处理出去的流量。这两个软IRQ都是通过下列几行代码在net_dev_init中注册:
open_softirq(NET_TX_SOFTIRQ, net_tx_action, NULL);
open_softirq(NET_RX_SOFTIRQ, net_rx_action, NULL);
因为同一个软IRQ函数的不同实例可以在不同的CPU上同时执行(和微任务不同),因此,网代码不但是低延时的,而且又具有适应性。
这两个网络软IRQ的优先级都比普通微任务(TASKLET_SOFTIRQ)要高,但是,比高优先级微任务(HI_SOFTIRQ)要低。这样的优先级安排,即使系统处于高网络负载情况下,也可以保证其他高优先级地任务运行具有足够的响应力和及时的效果。
softnet_data结构
后面我们就会知道,每个CPU都有其队列,用来接收进来的帧。因为每个CPU都有其数据结构用来处理入口和出口流量,因此,不同CPU之间没必要使用上锁机制。此队列的数据结构softnet_data就定义在include/linux/netdevice.h中,如下所示
struct softnet_data
{
int throttle;
int cng_level;
int avg_blog;
struct sk_buff_head input_pkt_queue;
struct list_head poll_list;
struct net_device *output_queue;
struct sk_buff *completion_queue;
struct net_device backlog_dev;
}
此结构的字段可用于接收和传输。换言之,NET_RX_SOFTIRQ和NET_TX_SOFTIRQ软IRQ都引用此结构。入口帧会排入input_pkt_queue,而出口队列会放入流量控制(QoS层)所处理的特殊队列(而不是由软IRQ和softnet_data结构所处理),但是,稍后软IRQ依然可用于清理已传输的缓冲区,以免该任务传输缓慢。
softnet_data字段
下面是对此数据结构的主要字段进行描述,其细节会在后面说明。有些驱动程序使用NAPI接口,而其他的则还没更新使用NAPI。这两种类型的驱动程序都会使用此结构,但是,有些字段是保留给非NAPI驱动程序的。
-
throttle -
avg_blog -
cng_level- 这三个参数由拥塞管理算法使用,后面会说明“拥塞管理”。默认地,每接收一个帧这三个字段都会被更新。
-
input_pkt_queue- 这个队列(在
net_dev_init中初始化)用来保存进来的帧(被驱动程序处理前)。非NAPI驱动程序也会使用此字段,那些还没更新为使用NAPI的则会使用其自己私有的队列。
- 这个队列(在
-
backlog_dev- 这是一个完整的嵌入式数据结构(不只是指针而已),类型为
net_device代表着一个设备已在相关联的CPU上为net_rx_action调度以准备执行。这个字段是有非NAPI驱动程序使用。其名称指的是backlog device(积压设备)。
- 这是一个完整的嵌入式数据结构(不只是指针而已),类型为
-
poll_list- 这是一个双向列表,其中的设备都带有输入帧等着被处理。
-
output_queue -
completion_queueoutput_queue是设备列表,其中的设备有数据要传输。而completion_queue是缓冲列表,其中缓冲区已成功传输,因此可以释放掉。
throttle被视为布尔变量,当CPU超负荷则为真,否则为假。其依赖于input_pkt_queue中的帧数目。当throttle标识设置时,此CPU所接收的所有输入帧都会被丢弃,无论队列的帧数据有多少。
avg_blog代表地是input_pkt_queue队列长度加权后的平均值,其值介于0到最大长度(由netdev_max_backlog表示)。avg_blog可用于计算cng_level。
cng_level代表拥塞等级,其值可以是下图中任何值。当avg_block遇到此图所示的极限之一时,cng_level就改变其值。NET_RX_XXX枚举值的定义放在include/net/core/dev.c中。方括号中的字符串(/DROP和/HIGH)后面会说明。默认会按每个帧重新计算avg_blog和cng_level,但是,重新计算可能会延缓,而且和定时器绑定在一起以免过于耗时。
avg_blog与cng_level是与CPU相关的,因此,可用于非NAPI设备(共享每个CPU所用的队列input_pkt_queue)。

softnet_data初始化
每个CPU的softnet_data结构是由net_dev_init在引导期间执行初始化的。其初始化代码如下:
for(i =0 ; i<NR_CPUS; i++)
{
struct softnet_data *queue;
queue = &per_cpu(softnet_data, 1);
skb_queue_head_init(&queue->input_pkt_queue);
queue->throttle = 0;
queue->cng_level = 0;
queue->avg_blog = 10 /*任何非零值*/
queue->completion_queue = NULL;
INIT_LIST_HEAD(&queue->poll_list);
set_bit(__LINK_STATE_START, &queue->backlog_dev.state);
queue->backlog_dev.weight = weight_p;
queue->backlog_dev.poll = process_backlog;
atomic_set(&queue->backlog_dev.refcnt, 1);
}
NR_CPUS是Linux内核所能处理的最大CPU数目,而softnet_data是一个向量,内含一些struct softnet_data结构。
此程序也会对softnet_data->blog_dev(此结构的类型为net_device,为一种特殊设备,代表的是非NAPI设备)的字段做初始化。后面会进行详细说明如何使用旧式netif_rx接口,而以透明化的方式处理非NAPI设备驱动程序。


![[附源码]SSM计算机毕业设计旅游管理系统JAVA](https://img-blog.csdnimg.cn/b4acd43e603549c2a47c6ac4f255b7aa.png)


![【linux】【platform[1]】简述device和driver几种匹配方式](https://img-blog.csdnimg.cn/4e22985a8b234d4d9e66123fbec83925.png)