原文作者:John Stegeman ,图数据库产品专家,Neo4j。基于原文翻译并补充整理而成。
新近发布的Neo4j 版本5推出了自治集群(Autonomous Cluster),以支持易于部署、可扩展、自容错等重要特性。下面我们就来一睹自治集群的特性。
什么是自治集群?
Neo4j 图数据库版本 5(“Neo4j 5”)引入了自治集群,与之前版本相比,运行和管理容错且高可用的 Neo4j 集群变得更加容易。Neo4j 5 中的新功能可以根据业务需求和服务约束自动决定如何在服务器(裸机、虚拟机或容器)之间分配“主(primary,可写、同步)”和“从/辅助(secondary,只读、异步)”数据库实例或副本,这些服务约束是数据库管理员在定义集群拓扑时提供的。
在 Neo4j 5 中,服务器端路由 (Server Side Routing) 默认为开启。这使得使用标准网络负载均衡器和其他网络抽象云技术成为可能——Neo4j SSR 将透明地负责将查询路由到适当的 DBMS 服务器。自治集群自动负责跨集群配置数据库,从而更容易运行高可用性、高可扩展性的集群。
例如,想一想当集群中的一台机器出现故障时会发生什么?在自治集群中,无需手动将数据库实例重新分配给仍在正常运行的 DBMS 服务器,集群会自动集群中“主领导(Leader)实例” 中选择一个新的领导以代替故障的 DBMS 服务器。这一新功能减少了在设置和维护集群时需要进行的手动配置,从而可以更轻松地运行高可用和可扩展的集群。
来看一个包含三个应用的简单示例,每个应用都有自己的 HA 和可伸缩性要求,数据库托管在由 5 个 DBMS 服务器组成的集群中。下图显示了 Neo4j 自治集群如何在集群中的 DBMS 服务器之间自动分配数据库:
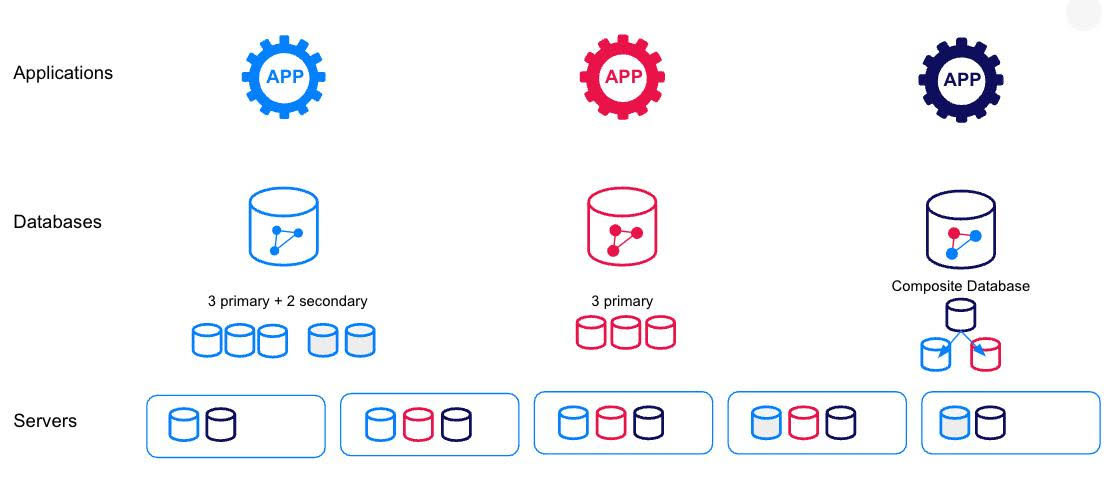
随着应用数量和用户数量的增长,自治集群能够极大减少与管理数据库和 DBMS 服务器相关的运维工作,因此对用户而言会越来越有价值。
自治集群是如何工作的:案例分析
下面让我们来深入看看自治集群是如何工作的。我们将设置一个三节点集群,检查它是如何工作的,创建一个新数据库,最后看看服务器端路由如何使我们能够连接到集群中的任何 DBMS 服务器并使用新数据库。如果您想阅读所有详细信息,可以按照文档进行操作。
对于下面的演示,我们将在同一个虚拟机上运行集群的所有三个 DBMS 服务器;当我们这样做时,我们需要确保每个 DBMS 服务器使用不同的端口以避免冲突。每个服务器都有一个名称和一个用于侦听连接的bolt协议端口——这些端口在每个服务器的 neo4j.conf 文件中配置。我们将分别为第一台、第二台和第三台服务器使用端口 7681、7682 和 7863。
服务器端路由在 Neo4j 5 中是默认启用的,不过还需要添加下面的行
dbms.routing.default_router=SERVER到neo4j.conf 配置文件中指定 SSR 作为默认值。如果使用客户端路由,你可以将它设置为 CLIENT。启动三个 DBMS 服务器后,我们运行cypher-shell数据库命令行工具连接到其中任何一个,例如 server1 然后执行show servers命令以查看集群的状态:
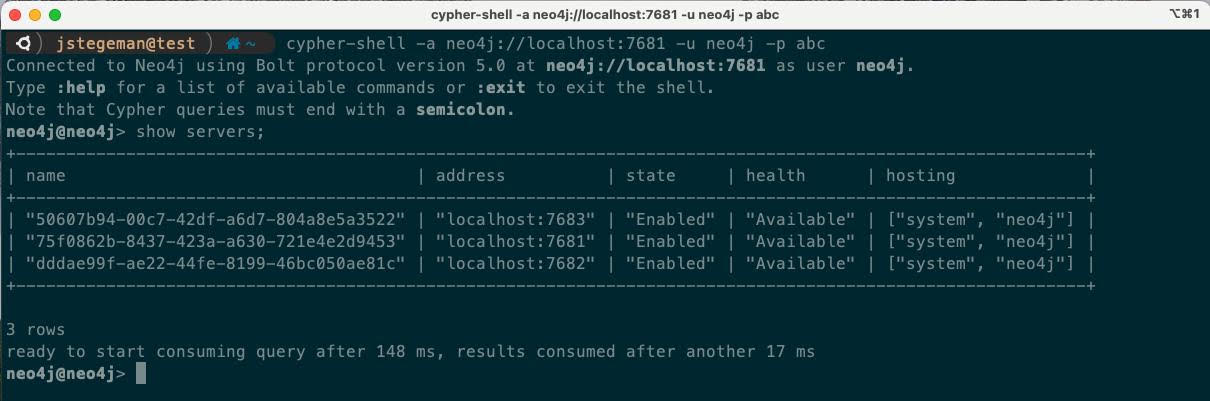
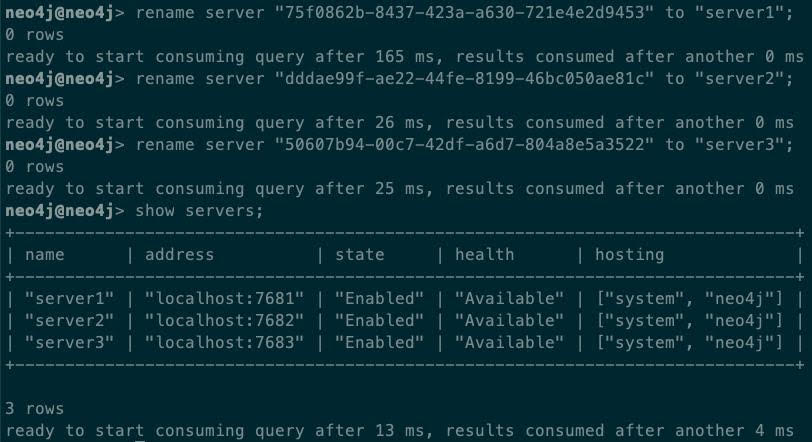
默认情况下,每个 DBMS 服务器都使用内部生成的 UUID 命名。我们可以使用rename server命令给DBMS一个更友好的名字,例如server1 / server2 / server3:
在集群 DBMS 服务器上自主创建数据库
现在,让我们看看怎样创建满足约束条件的新数据库,并让 Neo4j 自治集群自动确定运行数据库的 DBMS 服务器。这一步骤是相当容易的。我们可以简单地使用create database命令并指定 一个“部署架构拓补”(topology),Neo4j 将自动决定使用哪个 DBMS 服务器。
在这个示例中,我们制定包含一个主数据库(可写)和一个从数据库(只读)的部署架构。这种配置显然不支持高可用性,因为我们至少需要三个主节点才能够满足因果集群的要求。我们只是以此简单的例子来了解 Neo4j 5 自治集群的工作原理。创建数据库的完整命令是:
create database supplychain topology 1 primary 1 secondary;执行结果如下:
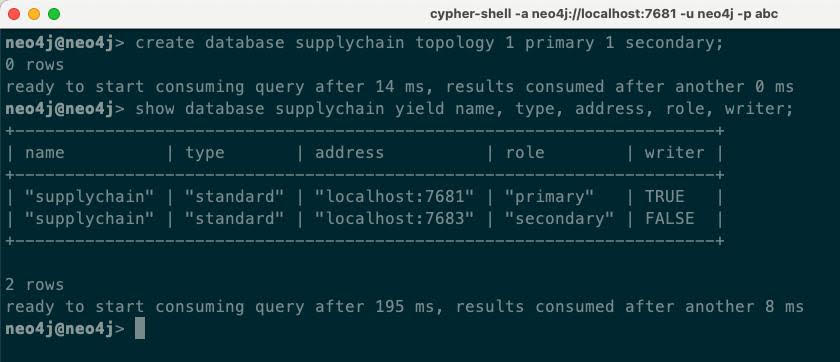
从执行结果可以看到,自治集群决定在 server1 上运行主节点,在 server3 上运行从节点。我们可以通过连接到 server2(端口7682) 并测试对新数据库的读取和写入。因为开启了显示服务器端路由,即使server2上没有新创建的supplychain数据库,读写请求也会被路由到server1和server3上执行。下面是执行的输出:
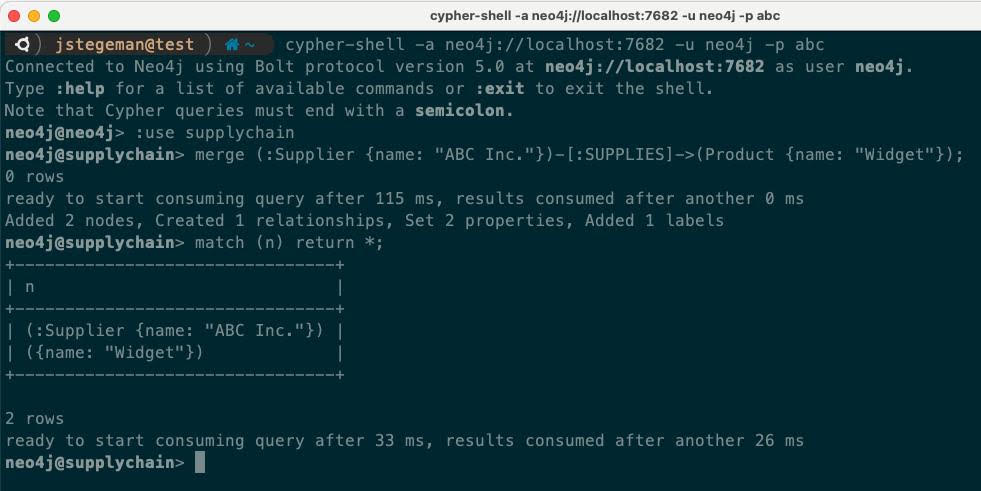
随着数据库的使用发生变化,例如扩大或缩小,我们随时使用 CYPHER 命令来改变我们新数据库的拓扑结构。这里我们来增加一个从数据库:
alter database supplychain set topology 1 primary 2 secondaries;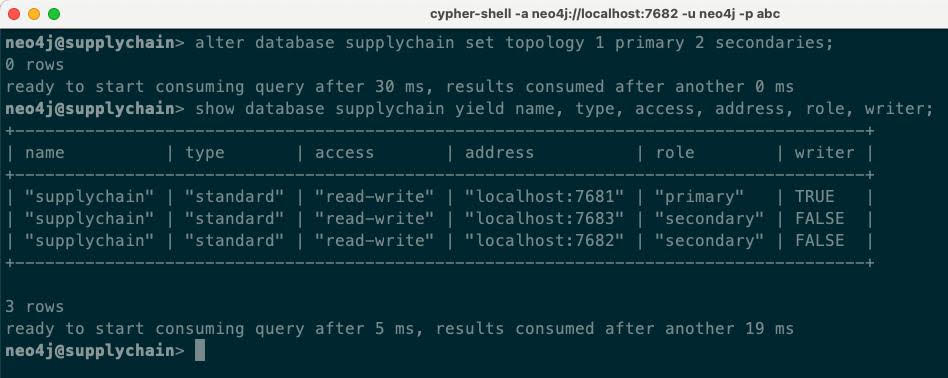
随着集群不断扩展、更多数据库被添加进来时,自治集群的优势会越来越显现。当向集群中添加了另外 6 个 DBMS 服务器(达到总共有 9 个服务器),以及 6 个具有各种拓扑结构的数据库时,自治集群自动处理了所有配置工作:
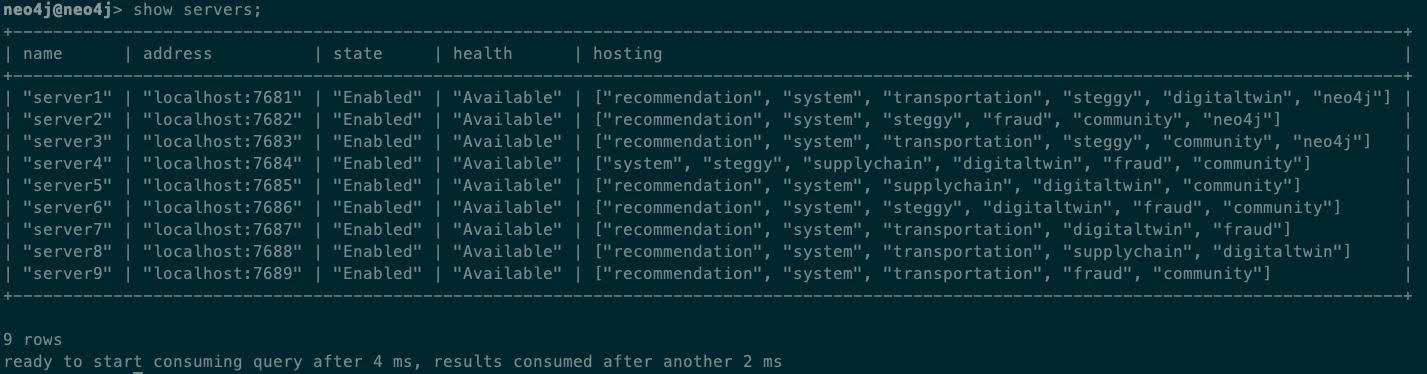
查看一下数据库,我们会看到主实例和从实例是如何自动分布在可用服务器上的。命令如下:
show database yield name,address,role,writer limit 20;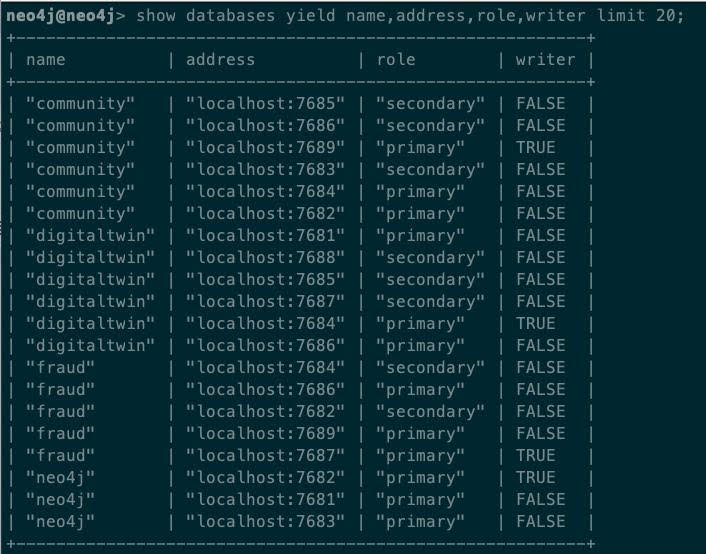
当我们需要关闭某个数据库服务器时,操作同样很简单。第一步,先将该服务器上的数据库迁移,CYPHER命令如下:
deallocate database from server "server9";
查看一下结果:

接着停止数据库服务器:
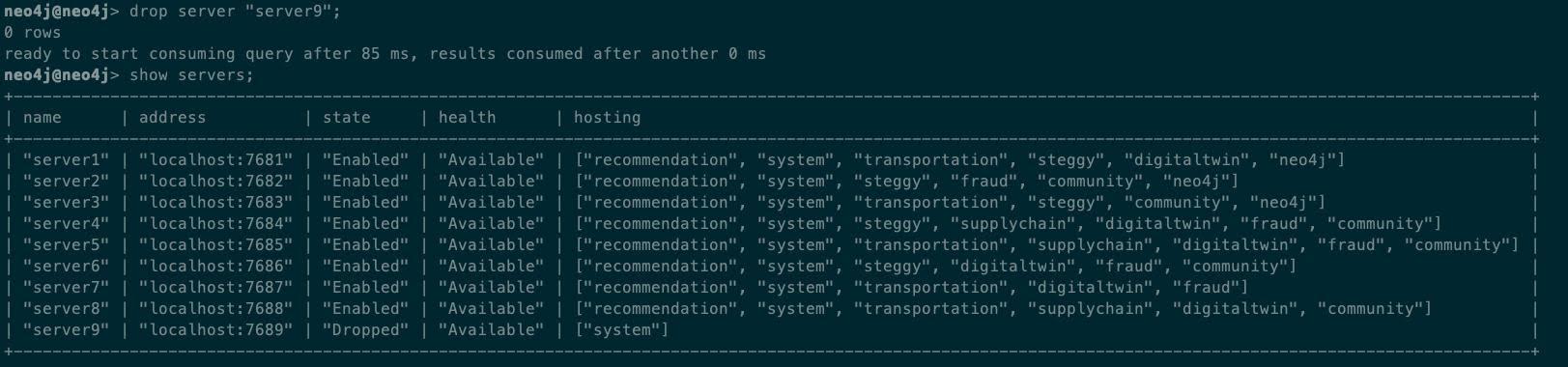
以及要求集群重新分配原先运行在该服务器上的数据库:
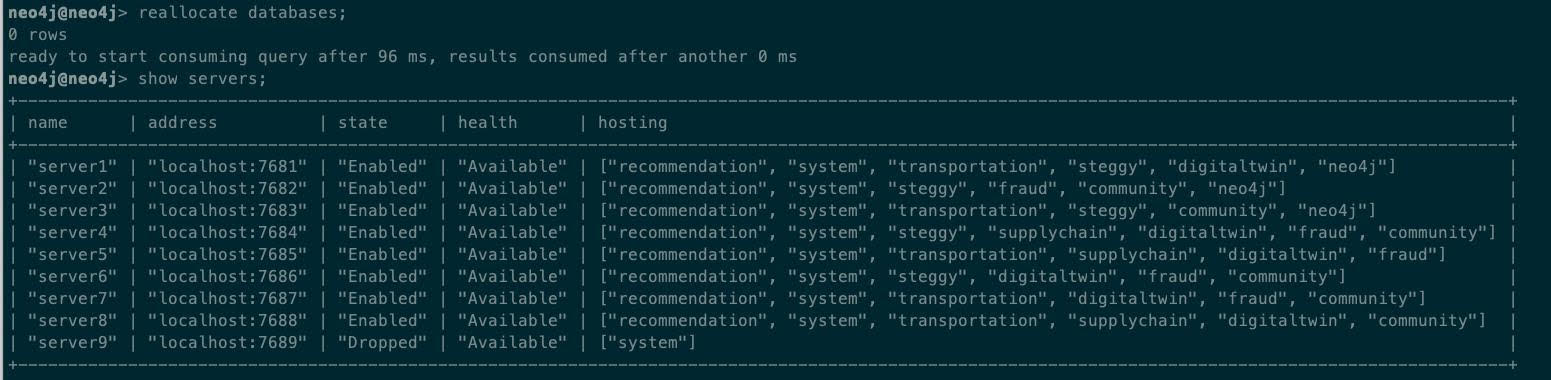
结果原先运行在server9上的数据库主动迁移到server5和server7上了。
服务器属性和标签
我们还可以使用服务器属性为自治集群提供更多信息。设置参数modeConstraint可以为PRIMARY或SECONDARY,以确保该 DBMS 服务器仅托管数据库的主要或从实例,或者设置为 NONE(默认值)以允许托管任何实例类型。我们还可以设置参数allowedDatabases和deniedDatabases属性来进一步配置集群。
在 Neo4j 5 的未来版本中还将引入标签,它可用于为 DBMS 服务器标记地理、容量等重要描述信息。在创建数据库时,这些特征对部署数据库会很有用,例如,“在欧洲地区的大型服务器上创建两个主服务器,在亚太地区创建三个辅助服务器等等。
总结
作为企业版的独有特性,Neo4j 5 中的自治集群使得构建高度可靠的大规模集群变得非常容易,这些集群可以处理大量并发工作负载,方便地水平扩展以满足企业级应用程序的需求。








![python学习——numpy库的使用[超详细的学习笔记]](https://img-blog.csdnimg.cn/f85bdaf3c1074ce1bfd672c3e42ecc44.jpeg)