文章目录
- 一、模拟实现单链表
- 成员属性
- 成员方法
- 0,构造方法
- 1,addFirst——头插
- 2,addLast——尾插
- 3,addIndex——在任意位置插入
- 3.1,checkIndex——判断index合法性
- 3.2,findPrevIndex——找到index-1位置的结点
- 4,contains——判定是否包含某个元素
- 5, remove——删除第一次出现关键字为key的结点
- 5.1, findPrevKey——找到key结点的前一个结点
- 6, removeAll——删除所有值为key的结点
- 7,size——获取单链表长度
- 8,clear——清空单链表
- 9,display——打印链表
- 二、Java提供的LinkedList
- 1,LinkedList 的说明
- 2,使用LinkedList
- 2.1,LinkedList 实例化方式
- 2.2,LinkedList 常用方法
- 链表和顺序表对比
- 总结
提示:是正在努力进步的小菜鸟一只,如有大佬发现文章欠佳之处欢迎评论区指点~ 废话不多说,直接发车~
一、模拟实现单链表
👉认识链表:
链表,是一种物理存储结构上 非连续 存储结构,数据元素的 逻辑顺序 是通过链表中的引用链接次序实现的 。
说人话:链表就是 “链接” 起来的。可以理解为火车,火车是由一节节车厢 “链接” 而成的;而链表,是由一个个结点/节点 “链接” 而成的
链表的结构可以细分为八种;我们主要掌握两种即可
1,无头单向非循环
结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结构的子结构,如哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多
2,无头双向循环
在Java的集合框架库中LinkedList底层实现就是无头双向循环链表
为什么要模拟实现:
自己模拟实现 简易版的 顺序表的增删查改等主要功能,大致理解顺序表的设计思想
再对比学习 Java 提供的集合类当中的 LinkedList,在学习 Java 的 LinkedList 常用方法的同时,也能学习源码的思想
我们模拟实现的是 无头单项非循环 链表
成员属性
Java 中的 LinkedList 是集合框架中的一个类,要模拟实现链表,也得自己实现一个类,首先要考虑这个类中的成员属性
已经说过,链表是由结点 “链接” 而成的,那么需要定义一个 静态内部类 Node:其中有两个域:
值域 value :来记录这个结点的值
指针域 next:来记录下一个结点的地址
还需要一个 成员变量:head 来记录当前链表的头结点
为了方便测试,全部设置为 public
public class MyLinkList {
// 静态内部类,不依赖于链表对象,可以单独存在
static class Node {
public int value;
public Node next;// Node类型的next值,存放下一个节点的地址
public Node(int value) {
this.value = value;
}
}
public Node head;// 链表的头节点
⚠️模拟实现重在理解理想,为了简便,不使用泛型🙅,数组中存放 int 类型
成员方法
// 无头单向非循环链表实现
public class MyLinkList {
// 1,头插
public void addFirst(int data){}
// 2,尾插
public void addLast(int data){}
// 3,任意位置插入,第一个数据节点为0号下标
public void addIndex(int index,int data){}
// 4,查找是否包含关键字key是否在单链表当中
public boolean contains(int key){}
// 5,删除第一次出现关键字为key的节点
public void remove(int key){}
// 6,删除所有值为key的节点
public void removeAllKey(int key){}
// 7,得到单链表的长度
public int size(){}
// 8,清空链表
public void clear() {}
// 9,打印(官方没有这个方法,写出来方便我们自己测试)
public void display() {}
}
0,构造方法
模拟的链表的这个类中构造方法只有内部类 Node 的构造方法,只用来对结点的 value 域赋值即可,指针域 next 不赋值,默认为 null ,在相应的方法内修改 Node 的指针域 next
// 静态内部类,不依赖于链表对象,可以单独存在
static class Node {
public int value;
public Node next;// Node类型的next值,存放下一个节点的地址
public Node(int value) {
this.value = value;
}
}
1,addFirst——头插
❗️❗️和顺序表不同,链表是由一个个结点组成的,而顺序表可以理解为一个数组
顺序表插入之前必须考虑数组是否以及满了,而链表只需要关心各个结点的next即可
我们还有一个成员属性:head,是用来记录头结点的
链表的头插操作就是:
1,new 一个结点 node,类型是 Node
2,链接:把头结点的地址( head 的值)赋给 node 的指针域 next
3,head 记录新的头结点
public void addFirst(int value) {
Node node = new Node(value);
node.next = head;
head = node;
}
2,addLast——尾插
尾插步骤:
1,new 一个 node,类型是 Node
2,找到尾结点
3,链接:把 node 的值(也就是地址)赋给尾结点的指针域 next
如何找到尾结点呢?
需要 从头结点开始,遍历链表,找到一个结点的指针域 next 域为 null,它就是尾结点
head 是用来标记头结点的,所以 head 不能随意更改
我们需要再定义一个 Node 类型的 cur,让 cur 遍历链表
当 cur 找到尾结点后,需要让此时的尾结点和新结点 node 连接上
即:
cur.next = node;
如图:
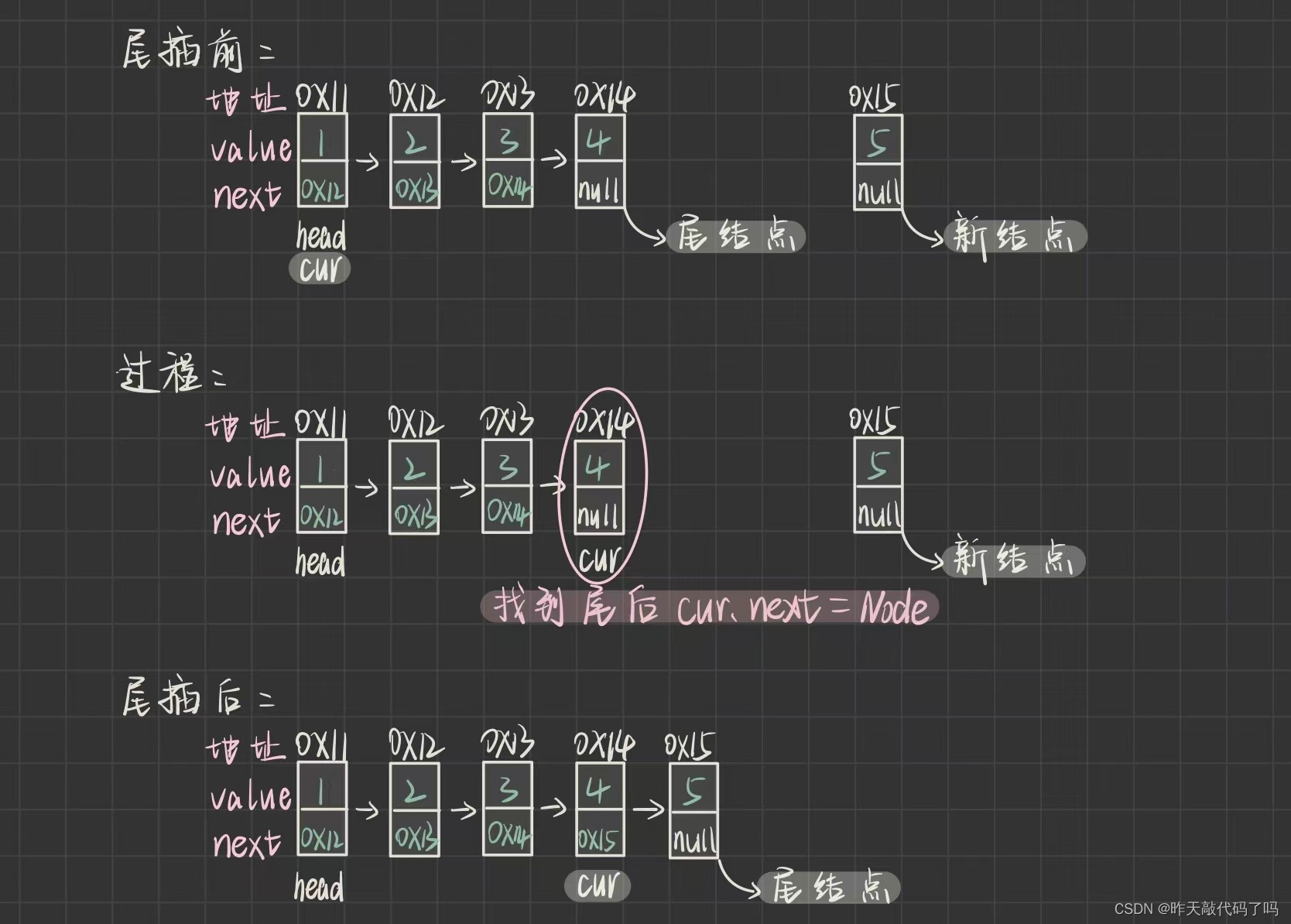
cur 从头开始遍历链表
Node cur = head;
遍历链表的过程就是一个循环,如果cur.next == null 时跳出循环
如果不满足条件,说明cur此时不是尾结点,那么cur要往下走,如何实现呢?
cur 这个变量中存放的值 要更改为下一个结点的地址:cur = cur.next;
写到这里就要小心了,cur.next这一句代码是要访问 cur 的 next 域,如果 cur == null 时,这里就会发生空指针异常
那么有没有可能会这种情况呢?
cur 是从 head 开始往后遍历的,那么如果 head 一开始就是 null ,也就是链表为空时,cur 就会被 head 赋值成 null,就会发生空指针异常
所以当链表为空时,就不需要遍历链表找尾结点,直接把 node 的值赋给 head 即可
完整代码:
public void addLast(int value) {
Node node = new Node(value);
// 链表为空的情况
if (head == null) {
head = node;
return;
}
Node cur = head;
// 找到最后一个结点的位置
while (cur.next != null) {
cur = cur.next;
}
cur.next = node;
}
3,addIndex——在任意位置插入
官方规定第一个数据的位置是0,和数组的位置(下标)规则一致
第一个参数就是 index,首先要判断 index 的合法性
3.1,checkIndex——判断index合法性
index<0 || index >链表长度是不合法的
public void checkIndex(int index) {
if (index < 0 || index > size()) {
// size()方法获取链表长度,遍历链表即可,比较简单,不多赘述
throw new LinkListIndexOutOfException("这个位置不合法");
// 异常处理
}
}
index 合法的情况下,如何在index位置插入删除呢?
index == 0就是头插,index = 链表长度就是尾插,主要是链表中间位置的插入和删除
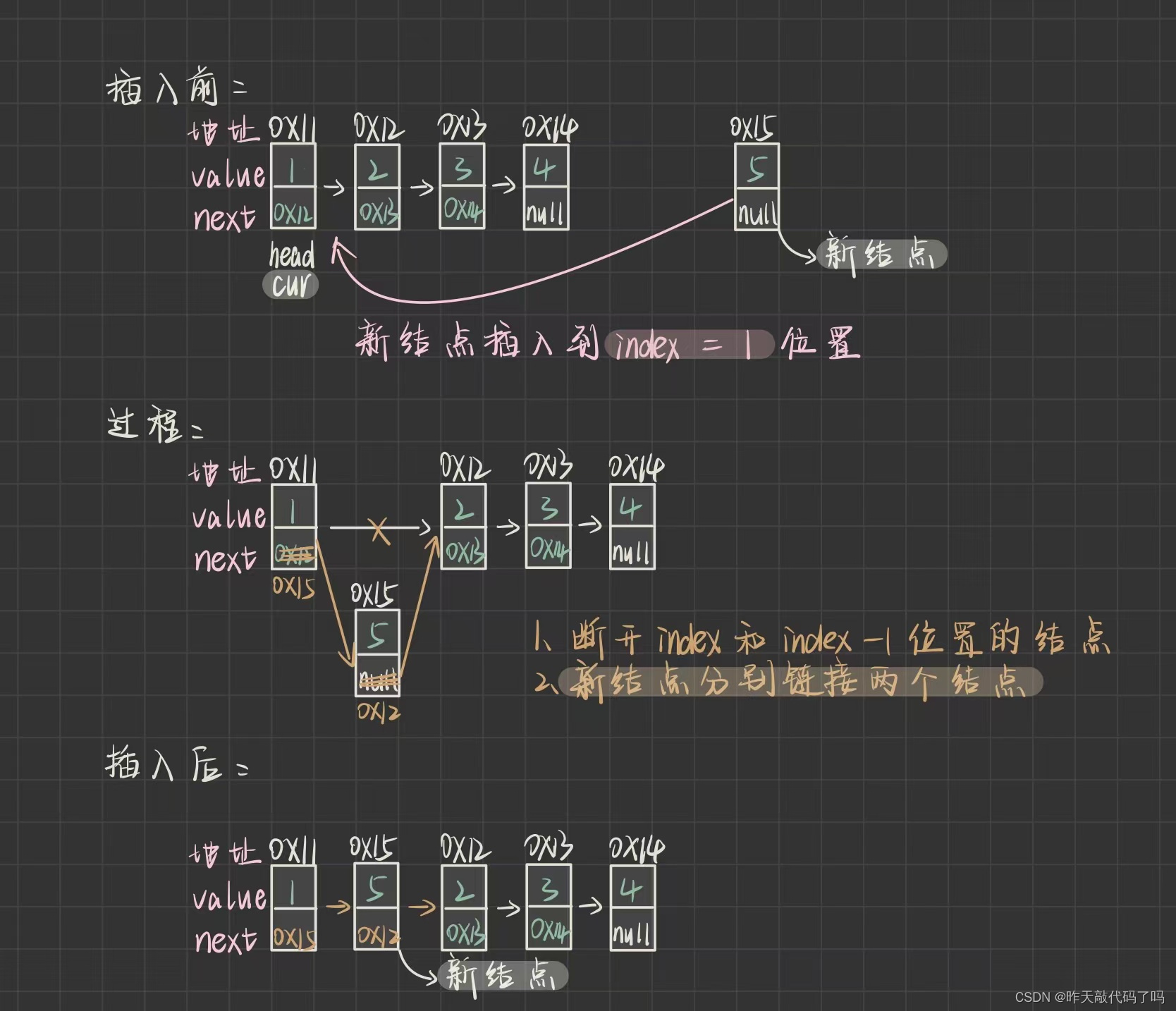
要想在两个结点中间插入新结点,首先要找到这两个结点的地址
找到index -1结点的位置也就相当于找到了index结点的位置
3.2,findPrevIndex——找到index-1位置的结点
public Node findPrevIndex(int index) {
Node cur = head;
int count = 0;
while (count != index - 1) {
cur = cur.next;
count++;
}
return cur;
}
代码实现很简单,cur遍历链表index-1次即可
具体插入步骤:
1,node.next = prevIndex.next;
2,prevIndex.next = node;
这两行不能交换位置,如果先让 prevIndex.next = node;那么就会丢失 index 位置的那个结点,此时 node.next = prevIndex.next 就相当于 node.next = node;代码会发生错误
完整代码:
public void addIndex(int index, int value) {
// 先检查index参数是否合法
checkIndex(index);
// 如果index == 0;头插即可
if (index == 0) {
addFirst(value);
return;
}
// 如果index == size;尾插即可
if (index == size()) {
addLast(value);
return;
}
// 中间插入删除
Node node = new Node(value);
// 先找到index-1位置的结点
Node prevIndex = findPrevIndex(index);
node.next = prevIndex.next;
prevIndex.next = node;
}
4,contains——判定是否包含某个元素
比较简单,遍历这个数组即可
public boolean contain(int key) {
Node cur = head;
while (cur != null) {
if (cur.value == key) {
return true;
}
cur = cur.next;
}
return false;
}
因为这里我们存放的是 int 类型的变量,但 LinkedList 当中可以存放引用数据类型的
⚠️⚠️⚠️当表中是引用类型时,就不可以用“等号”比较,应该用 equals 方法
5, remove——删除第一次出现关键字为key的结点
1,如果链表为空就不能再删了
2,如果头结点就是要删除的 key 结点,直接 head 存放下一个结点的地址
3,如果链表其他结点是要删除的 key 结点,要先找到 key 结点的前一个结点
5.1, findPrevKey——找到key结点的前一个结点
// 找到key的前一个结点
public Node findPrevKey(int key) {
Node cur = head;
while (cur.next != null) {
// 注意循环判断条件 如果cur.next==null 说明cur此时是最后一个节点
// 如果再访问下一个结点的value值,会空指针异常
// 此时的cur的value值在上一次循环以及判断过了,所以cur走到最后一个结点时,是最后一趟循环
if (cur.next.value == key) {
return cur;
}
cur = cur.next;
}
return null;
}
返回找到的这个结点即可
删除过程如图:
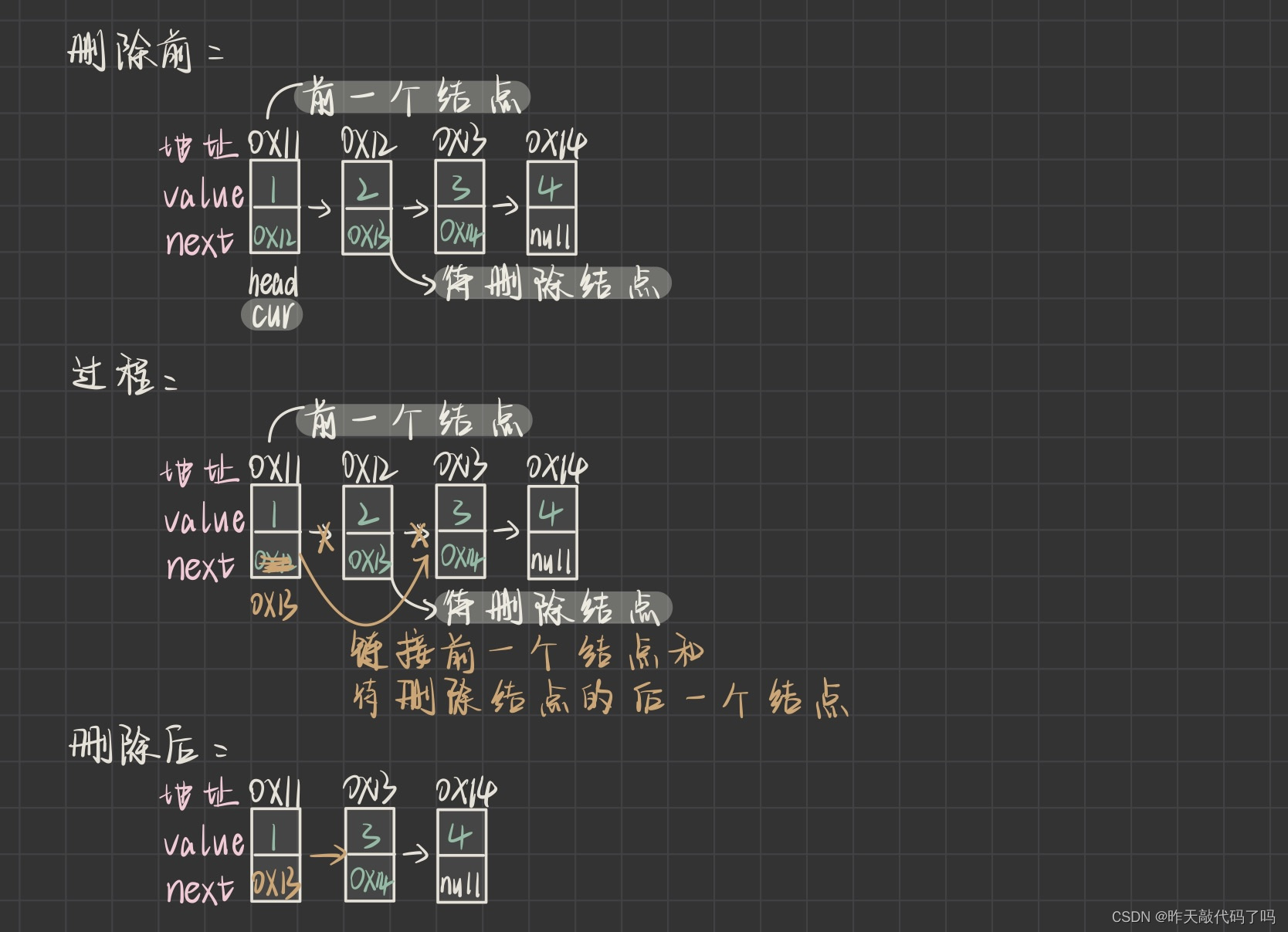
当 key 结点的前一个结点的 next 不再存放 key 结点地址时,key 结点此后不会再被使用,会被系统自动回收
完整代码如下:
public void remove(int key) {
// 如果链表为空
if (head == null) {
return;
}
// 如果头结点就是key
if (head.value == key) {
head = head.next;
return;
}
// 首先要找到key的前一个结点
Node prevKey = findPrevKey(key);
if (prevKey == null) {
return;
}
// 重新链接
Node del = prevKey.next;
prevKey.next = del.next;
}
6, removeAll——删除所有值为key的结点
这里需要一个 prevCur 结点来记录 cur 的前一个结点
当 cur 是 key 结点时,key结点的前一个结点(也就是 prevCur)可以直接断开和 key 结点的链接,指向 key 结点的下一个
利用循环操作每个结点的 next 即可
public void removeAll(int key) {
// 如果链表为空
if (head == null) {
return;
}
Node prevCur = head;
Node cur = head.next;
while (cur != null) {
if (cur.value == key) {
prevCur.next = cur.next;
cur = cur.next;
} else {
prevCur = cur;
cur = cur.next;
}
}
// 如果头结点就是key
if (head.value == key) {
head = head.next;
}
}
7,size——获取单链表长度
直接遍历链表即可
public int size() {
Node cur = head;
int count = 0;
while (cur != null) {
cur = cur.next;
count++;
}
return count;
}
8,clear——清空单链表
head 这个变量一直存放着链表的头结点位置,把head置空,就找不到此链表,那么链表中的所有结点都会被系统自动回收
public void clear() {
head = null;
}
9,display——打印链表
注意:LinkedList 中不存在该方法,为了方便看测试结果
public void disPlay() {
Node cur = head;
while (cur != null) {
System.out.print(cur.value + " ");
cur = cur.next;
}
System.out.println();
}
二、Java提供的LinkedList
1,LinkedList 的说明
🙋🏼Java官方的集合框架中,LinkedList 是一个普通的类,继承了List接口
LinkedList 的底层是双向链表结构,由于链表没有将元素存储在连续的空间中,元素存储在单独的结点中,然后通过引用将结点连接起来了,因此在在任意位置插入或者删除元素时,不需要搬移元素,效率比较高。
⚠️特殊说明:
1 LinkedList 实现了List接口
2. LinkedList 的底层使用了双向链表
3. LinkedList 没有实现 RandomAccess 接口,因此 LinkedList 不支持随机访问
4. LinkedList 的任意位置插入和删除元素时效率比较高,时间复杂度为O(1)
5. LinkedList 比较适合任意位置插入的场景
2,使用LinkedList
2.1,LinkedList 实例化方式
1️⃣无参构造法
ArrayList<Integer> arrayList1 = new ArrayList<>();
3️⃣有参数——参数是其他 Collection
Collection是集合框架中的一个接口,实现了这个接口的类的对象就可以作为参数,说白了就是
可以把其他的顺序表,链表,栈,队列等等 作为参数传参,例如:
ArrayList<Integer> arrayList = new ArrayList<>();
arrayList .add(1);
arrayList .add(2);
LinkedList<Integer> linkedList= new LinkedList<>(arrayList );
我先 new 了一个顺序表对象 arrayList ,在这个表中插入了 “1” “2” 两个数据,顺序表中的数据是顺序存储的
当 arrayList 作为参数传递时,linkedList 对象中就有了 arrayList 中的所有数据,linkedList 中的数据是链式存储❗️的
2.2,LinkedList 常用方法
在 main 方法中展示使用方式:
public class Test {
public static void main(String[] args) {
LinkedList<Integer> linkedList = new LinkedList<>();
// 1,插入(默认是尾插)
linkedList.add(1);
linkedList.add(2);
linkedList.add(3);
linkedList.add(4);
linkedList.add(5);
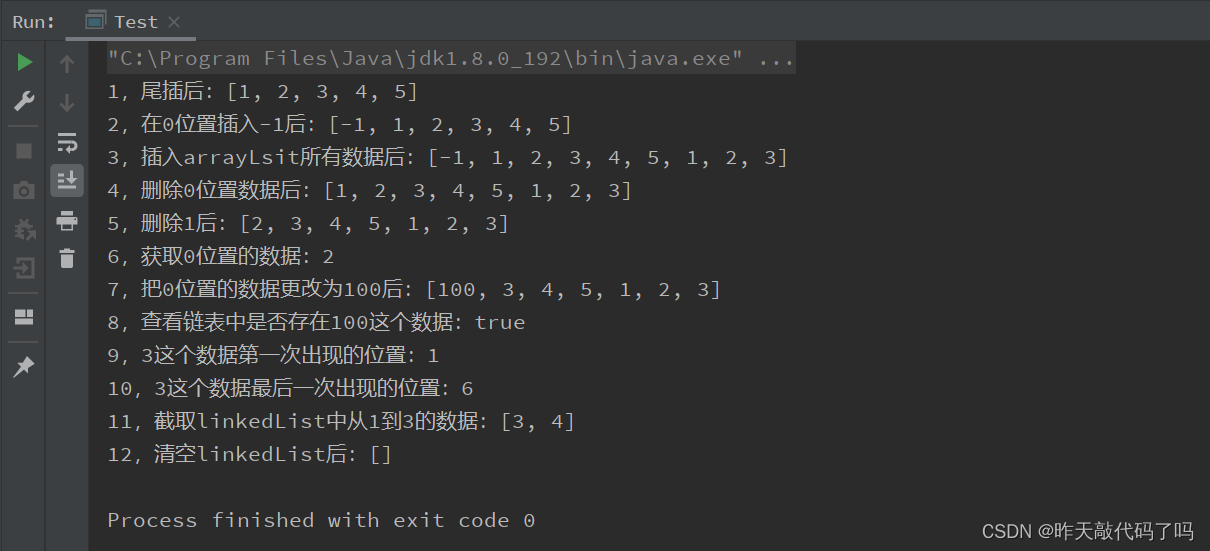
System.out.println("1,尾插后:" + linkedList);
// 2,任意位置插入
linkedList.add(0, -1);
System.out.println("2,在0位置插入后:" + linkedList);
// 先new一个顺序表对象
ArrayList<Integer> arrayList = new ArrayList<>();
arrayList.add(1);
arrayList.add(2);
arrayList.add(3);
// 3,插入其他Collection的所有元素(尾插)
linkedList.addAll(arrayList);
System.out.println("3,插入arrayLsit所有数据后:" + linkedList);
// 4,删除任意位置的数据
linkedList.remove(0);
System.out.println("4,删除0位置数据后:" + linkedList);
// 5,删除任意数据
linkedList.remove(new Integer(1));
System.out.println("5,删除1后:" + linkedList);
// 6,获取任意位置的数据
int ret = linkedList.get(0);
System.out.println("6,获取0位置的数据:" + ret);
// 7,更改任意位置的数据
linkedList.set(0, 100);
System.out.println("7,把0位置的数据更改为100后:" + linkedList);
// 8,查看链表中是否存在该数据
boolean bl = linkedList.contains(100);
System.out.println("8,查看链表中是否存在100这个数据:" + bl);
// 9,获取链表中任意数据第一次出现的位置
int index = linkedList.indexOf(3);
System.out.println("9,3这个数据第一次出现的位置:" + index);
// 10,获取链表中任意数据最后一次出现的位置
int lastIndex = linkedList.lastIndexOf(3);
System.out.println("10,3这个数据最后一次出现的位置:" + lastIndex);
// 11,截取
List<Integer> list = linkedList.subList(1, 3);// 左闭右开
System.out.println("11,截取linkedList中从1到3的数据:" + list);
// 12,清空
linkedList.clear();
System.out.println("12,清空linkedList后:" + linkedList);
}
}
运行结果:
链表和顺序表对比

链表和顺序表都有各自的优缺点,并且这两种结构的优缺点基本是互补的,所以不存在哪一种结构更优秀,只有在不同的场景,会有更加合适的结构。
总结
以上就是今天分享的关于数据结构中【链表】的内容,
一方面介绍了如何模拟实现简易的单链表,
一方面介绍了Java集合框架中的 LInkedList 类的基本使用,
并且分析了链表和顺序表的区别对比
如果本篇对你有帮助,请点赞收藏支持一下,小手一抖就是对作者莫大的鼓励啦🤪🤪🤪
上山总比下山辛苦
下篇文章见