《Caffeine(Java顶级缓存组件)一》
提示: 本材料只做个人学习参考,不作为系统的学习流程,请注意识别!!!
《Caffeine(Java顶级缓存组件)》
- 《Caffeine(Java顶级缓存组件)一》
- 1. Caffeine缓存概念
- 1.1 缓存的分类
- 1.2 Caffeine组件的特点
- 1.3 Caffeine依赖
- 2. 手工缓存
- 2.1 核心接口
- 2.2 手工缓存
- 3. 缓存同步加载
- 3.1 接口梳理
- 3.2 代码测试
- 4. 异步缓存
- 4.1 接口梳理
- 4.2 代码测试
- 5. 缓存数据驱逐
- 5.1 缓存容量驱逐策略
- 5.2 缓存权重驱逐策略
- 5.3 缓存时间驱逐策略
- 5.4 定制化缓存清除处理
- 5.5 JVM相关的驱逐操作
- 6. 缓存数据删除与监听
- 6.1 缓存数据删除
- 6.2 缓存数据监听
- 7. CacheStats
- 7.1 接口梳理
- 7.2 代码测试
1. Caffeine缓存概念
1.1 缓存的分类
- 分布式的缓存组件
- Redis
- Memcached
- 单机版本的缓存组件
- EHCache组件:一个随着Hibernate框架同时推广的缓存组件,也是Hibernate之中默认的实现,其属于一个纯粹的Java缓存框架,具有快速、简单等操作特点,同时支持有更多的缓存出来功能。
- Google Guava:是一个非常方便易用的本地化缓存组件,基于LRU算法实现,支持多种缓存过期策略。
- Caffeine:是对Guava缓存组件的重写版本,虽然功能不如EHCache多,但是其提供了最优的混存命中率。
1.2 Caffeine组件的特点
- 可以自动将数据加载到缓存之中,也可以采用异步的方式进行加载。
- 当基于频率和最近访问的缓存达到最大容量时,该组件会自动切换到基于大小的模式。
- 可以根据上一次缓存访问或上一次的数据写入来决定缓存的过期处理。
- 当某一条缓存数据出现过期访问后可以自动进行异步刷新。
- 考虑到JVM的内存管理机制,所有的缓存key自动包含在弱引用之中,value包含在弱引用或软引用中。
- 当缓存数据被清理后,将会收到相应的通知信息。
- 缓存数据的写入可以传播到外部存储。
- 自动记录缓存数据被访问的次数。
1.3 Caffeine依赖
添加依赖
在maven仓库搜索 caffeine,获取最新版本
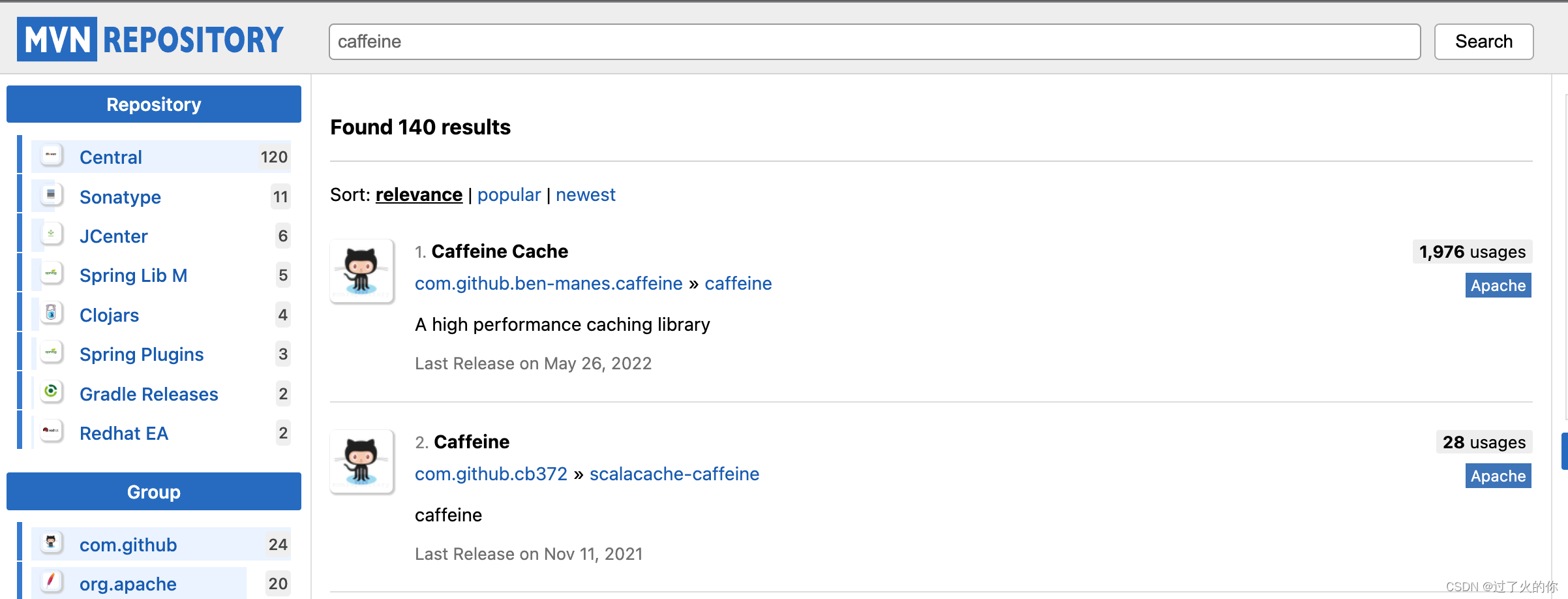
在项目中添加Maven依赖即可。
由于本人本地jdk版本为1.8, 所以下面实际测试使用的caffeine版本为2.9.0
<!-- https://mvnrepository.com/artifact/com.github.ben-manes.caffeine/caffeine -->
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>3.1.0</version>
</dependency>
2. 手工缓存
2.1 核心接口
caffeine组件的核心接口:com.github.benmanes.caffeine.cache.Cache
接口包含如下方法:
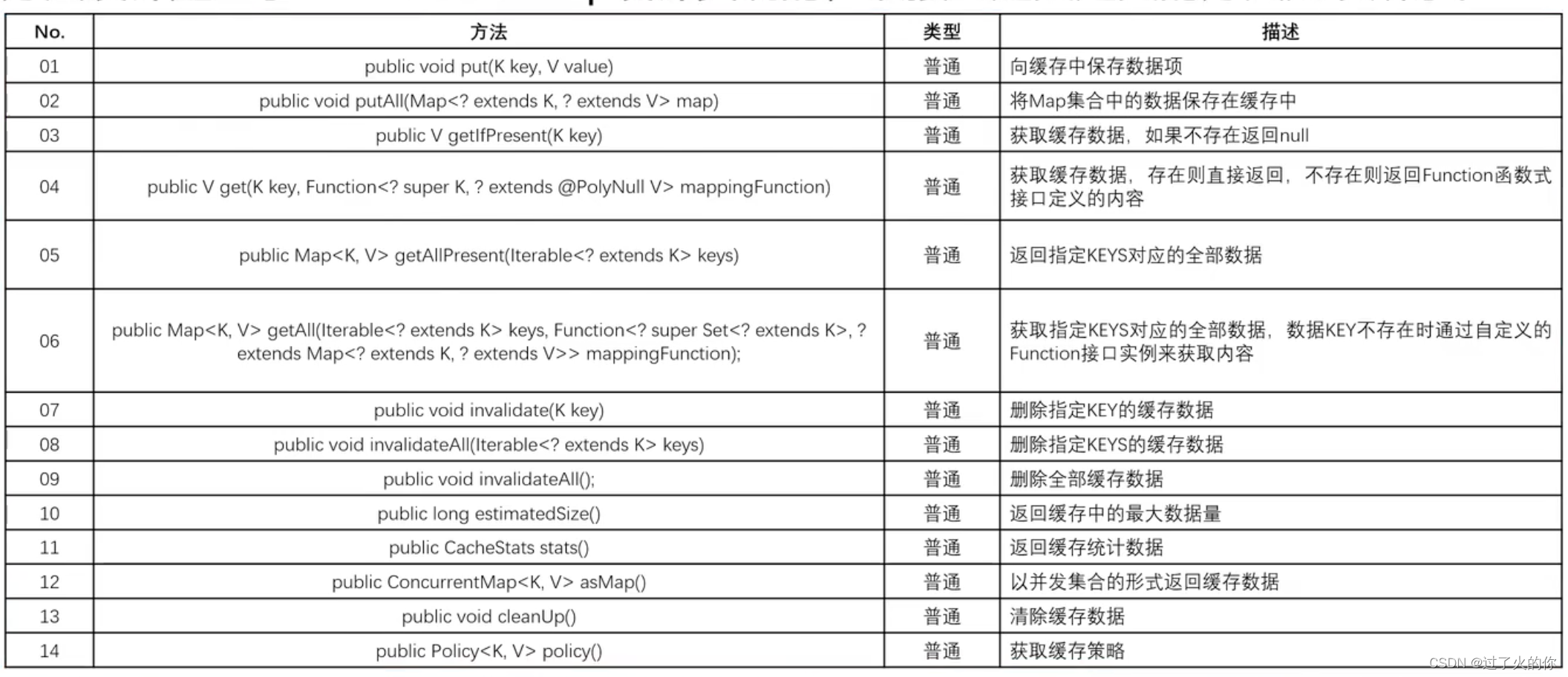
具体的实现类有:
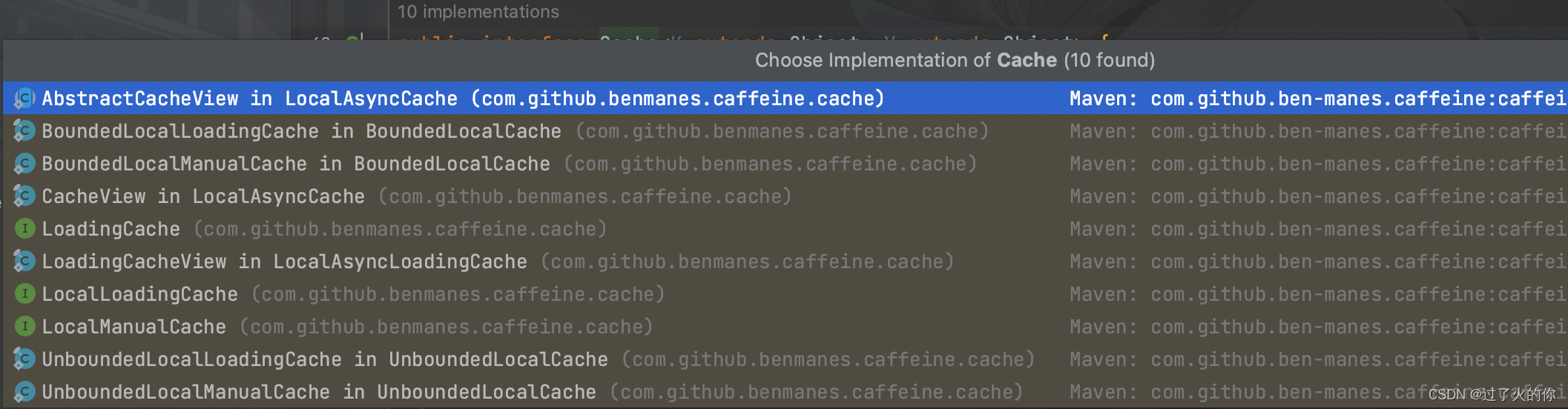
我们实际使用的肯定是Cache接口的实现类对象,而通过Caffeine官方给定的说明文档发现,如果想要获取Cache接口的对象实例,可以通过Caffeine工具类来实现,同时这个类里面提供了一个newBuilder()方法,于是打开该方法的源代码观察一下:
//私有构造方法
private Caffeine() {}
@CheckReturnValue
public static Caffeine<Object, Object> newBuilder() {
return new Caffeine<>();/每一次都返回一个新的实例
}
可以发现newBuilder()方法属于一个内部的工厂方法,每调用一次都会返回一个新的Caffeine类实例,而最终所需要的是一个Cache接口实例,这个时候可以继续观察Caffeine类中的build()方法。
@CheckReturnValue
public <K1 extends K, V1 extends V> Cache<K1, V1> build() {
requireWeightWithWeigher();
requireNonLoadingCache();
@SuppressWarnings("unchecked")
Caffeine<K1, V1> self = (Caffeine<K1, V1>) this;
return isBounded()
? new BoundedLocalCache.BoundedLocalManualCache<>(self)//创建有边界的缓存对象
: new UnboundedLocalCache.UnboundedLocalManualCache<>(self);//创建无边界的缓存对象
}
boolean isBounded() {
return (maximumSize != UNSET_INT)
|| (maximumWeight != UNSET_INT)
|| (expireAfterAccessNanos != UNSET_INT)
|| (expireAfterWriteNanos != UNSET_INT)
|| (expiry != null)
|| (keyStrength != null)
|| (valueStrength != null);
}
isBounded()方法中的几个配置项实际上都属于Caffeine之中关于缓存存储的配置处理,每一个配置项都有其特定的处理方法,下面举例说明。
2.2 手工缓存
所有的缓存数据都是保存在内存之中的,如果无限制的让缓存始终进行存储,那么必然会造成内存的溢出,内存一旦溢出之后,应用程序就可能直接崩溃,所以缓存数据的清理是所有缓存组件必须要提供的支持。
package com.personal.caffeine.test;
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.concurrent.TimeUnit;
/**
* 测试caffeine的基本操作
*/
public class TestCaffeine {
private static final Logger logger = LoggerFactory.getLogger(TestCaffeine.class);
public static void main(String[] args) throws InterruptedException {
Cache<String, String> cache = Caffeine.newBuilder()//构建一个新的Caffeine实例
.maximumSize(100)//设置缓存中保存的最大数据量
.expireAfterAccess(3L, TimeUnit.SECONDS)//如无访问则3秒后失效
.build();
cache.put("a", "1111");//设置缓存项
cache.put("b", "2222");//设置缓存项
cache.put("c", "3333");//设置缓存项
logger.info("[未超时获取缓存数据] a = {}", cache.getIfPresent("a"));//获取数据
TimeUnit.SECONDS.sleep(5);//5秒后超时
logger.info("[超时后获取缓存数据] a = {}", cache.getIfPresent("a"));//获取数据
}
}
17:53:50.592 [main] INFO com.personal.caffeine.test.TestCaffeine - [未超时获取缓存数据] a = 1111
17:53:55.600 [main] INFO com.personal.caffeine.test.TestCaffeine - [超时后获取缓存数据] a = null
在默认情况下,一旦缓存数据失效之后,Cache接口可以返回的内容就是null,于是有些人认为空值不利于标注,那么此时也可以考虑进行一些数据的控制。
package com.personal.caffeine.test;
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.security.Key;
import java.sql.Time;
import java.util.concurrent.TimeUnit;
/**
* 测试caffeine的基本操作
*/
public class TestCaffeine {
private static final Logger logger = LoggerFactory.getLogger(TestCaffeine.class);
public static void main(String[] args) throws InterruptedException {
Cache<String, String> cache = Caffeine.newBuilder()//构建一个新的Caffeine实例
.maximumSize(100)//设置缓存中保存的最大数据量
.expireAfterAccess(3L, TimeUnit.SECONDS)//如无访问则3秒后失效
.build();
cache.put("a", "1111");//设置缓存项
cache.put("b", "2222");//设置缓存项
cache.put("c", "3333");//设置缓存项
logger.info("[未超时获取缓存数据] a = {}", cache.getIfPresent("a"));//获取数据
TimeUnit.SECONDS.sleep(5);//5秒后超时
// logger.info("[超时后获取缓存数据] a = {}", cache.getIfPresent("a"));//获取数据
logger.info("[超时后获取缓存数据] a = {}", cache.get("a", key -> {
logger.info("[失效处理]没有发现KEY= {}的数据,要进行失效处理控制", key);
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
return "[EXPIRE]" + key;//失效后数据返回
}));//获取数据
}
}
17:57:41.646 [main] INFO com.personal.caffeine.test.TestCaffeine - [未超时获取缓存数据] a = 1111
17:57:46.692 [main] INFO com.personal.caffeine.test.TestCaffeine - [失效处理]没有发现KEY= a的数据,要进行失效处理控制
17:57:49.710 [main] INFO com.personal.caffeine.test.TestCaffeine - [超时后获取缓存数据] a = [EXPIRE]a
通过上面的操作发现,此时当缓存数据失效之后,可以自动的根据Function函数式接口加载所需要的数据内容,而这个加载的过程是属于同步的范畴,加载不停,数据是不会返回的。
3. 缓存同步加载
3.1 接口梳理
在之前进行缓存数据查询的时候,曾经使用过一个Cache接口中的get()方法,这个方法可以结合Function接口在缓存数据已经失效的之后进行数据的加载使用,首先来观察这个方法的基本定义。
@Nullable
V get(@NonNull K key, @NonNull Function<? super K, ? extends V> mappingFunction);
这种数据加载操作指的是在缓存数据不存在的时候进行数据的同步加载处理操作,而除这种加载操作的机制之外,在缓存组件之中还提供了一个较为特殊的CacheLoader接口,这个接口的触发机制有点不一样,它采用的依然是同步的加载处理,首先来打开这个接口的定义
@FunctionalInterface
@SuppressWarnings({"PMD.SignatureDeclareThrowsException", "FunctionalInterfaceMethodChanged"})
public interface CacheLoader<K, V> extends AsyncCacheLoader<K, V> {
@Nullable
V load(@NonNull K key) throws Exception;
}
如果想要使用这个接口,则需要根据Caffeine提供的build()方法进行处理,这个方法之中可以接收该接口的实例。
@NonNull
public <K1 extends K, V1 extends V> LoadingCache<K1, V1> build(
@NonNull CacheLoader<? super K1, V1> loader) {
requireWeightWithWeigher();
@SuppressWarnings("unchecked")
Caffeine<K1, V1> self = (Caffeine<K1, V1>) this;
return isBounded() || refreshAfterWrite()
? new BoundedLocalCache.BoundedLocalLoadingCache<>(self, loader)
: new UnboundedLocalCache.UnboundedLocalLoadingCache<>(self, loader);
}
此时可以发现当前build()方法返回的类型是一个LoadingCache,该接口为Cache子接口,表示可以进行数据的加载。
public interface LoadingCache<K, V> extends Cache<K, V> {
3.2 代码测试
1. 代码测试
package com.personal.caffeine.test;
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import com.github.benmanes.caffeine.cache.LoadingCache;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.concurrent.TimeUnit;
/**
* 测试caffeine的基本操作
*/
public class TestCaffeine2 {
private static final Logger logger = LoggerFactory.getLogger(TestCaffeine2.class);
public static void main(String[] args) throws InterruptedException {
LoadingCache<String, String> cache = Caffeine.newBuilder()//构建一个新的Caffeine实例
.maximumSize(100)//设置缓存中保存的最大数据量
.expireAfterAccess(3L, TimeUnit.SECONDS)//如无访问则3秒后失效
.build((key) -> {
TimeUnit.SECONDS.sleep(2);
return "[LoadingCache]" + key;
});
cache.put("a", "1111");//设置缓存项
logger.info("[未超时获取缓存数据] a = {}", cache.getIfPresent("a"));//获取数据
TimeUnit.SECONDS.sleep(5);//5秒后超时
logger.info("[超时后获取缓存数据] a = {}", cache.getIfPresent("a"));//获取数据
}
}
20:24:51.729 [main] INFO com.personal.caffeine.test.TestCaffeine2 - [未超时获取缓存数据] a = 1111
20:24:56.745 [main] INFO com.personal.caffeine.test.TestCaffeine2 - [超时后获取缓存数据] a = null
此时已经实现了CacheLoader接口的实例创建,但是在最终执行完成之后并没有返回所需要的内容,因为此时还没有触发数据的加载操作,实际上这个触发加载的操作需要通过Cache接口里面提供的一个getAll()的方法进行处理。
2. 代码测试
实现CacheLoader数据的加载
package com.personal.caffeine.test;
import com.github.benmanes.caffeine.cache.Caffeine;
import com.github.benmanes.caffeine.cache.LoadingCache;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Arrays;
import java.util.List;
import java.util.Map;
import java.util.concurrent.TimeUnit;
/**
* 测试caffeine的基本操作
*/
public class TestCaffeine2 {
private static final Logger logger = LoggerFactory.getLogger(TestCaffeine2.class);
public static void main(String[] args) throws InterruptedException {
LoadingCache<String, String> cache = Caffeine.newBuilder()//构建一个新的Caffeine实例
.maximumSize(100)//设置缓存中保存的最大数据量
.expireAfterAccess(3L, TimeUnit.SECONDS)//如无访问则3秒后失效
.build((key) -> {
logger.info("[CacheLoader] 进行缓存数据的加载出来,当前key = {}", key);
TimeUnit.SECONDS.sleep(2);
return "[LoadingCache]" + key;
});
cache.put("a", "1111");//设置缓存项
logger.info("[未超时获取缓存数据] a = {}", cache.getIfPresent("a"));//获取数据
TimeUnit.SECONDS.sleep(5);//5秒后超时
cache.put("b", "2222");//设置缓存项
for (Map.Entry<String, String> entry : cache.getAll(Arrays.asList("a", "b", "c")).entrySet()) {
logger.info("[数据加载] key = {},value = {}", entry.getKey(), entry.getValue());
}
logger.info("[超时后获取缓存数据] a = {}", cache.getIfPresent("a"));//获取数据
}
}
20:35:25.892 [main] INFO com.personal.caffeine.test.TestCaffeine2 - [未超时获取缓存数据] a = 1111
20:35:30.933 [main] INFO com.personal.caffeine.test.TestCaffeine2 - [CacheLoader] 进行缓存数据的加载出来,当前key = a
20:35:32.946 [main] INFO com.personal.caffeine.test.TestCaffeine2 - [CacheLoader] 进行缓存数据的加载出来,当前key = c
20:35:34.957 [main] INFO com.personal.caffeine.test.TestCaffeine2 - [数据加载] key = a,value = [LoadingCache]a
20:35:34.957 [main] INFO com.personal.caffeine.test.TestCaffeine2 - [数据加载] key = b,value = 2222
20:35:34.957 [main] INFO com.personal.caffeine.test.TestCaffeine2 - [数据加载] key = c,value = [LoadingCache]c
20:35:34.957 [main] INFO com.personal.caffeine.test.TestCaffeine2 - [超时后获取缓存数据] a = [LoadingCache]a
此时通过getAll()方法进行处理的时候,如果发现指定的KEY的缓存项不存在了,那么就进行数据的加载,这个时候就使用到CacheLoader接口。
与之前的get()的同步操作不同的是,此时是使用了专属的功能接口完成了数据的加载,从实现的结构上来说更加的标准化,同时也符合于Caffeine自己的设计要求。
4. 异步缓存
4.1 接口梳理
既然Caffeine提供了同步的数据加载操作,那么自然就会提供数据的异步加载处理操作了,对于异步数据加载,本身提供有如下几个处理方法。
public <K1 extends K, V1 extends V> AsyncCache<K1, V1> buildAsync()
public <K1 extends K, V1 extends V> AsyncLoadingCache<K1, V1> buildAsync(
@NonNull CacheLoader<? super K1, V1> loader)
public <K1 extends K, V1 extends V> AsyncLoadingCache<K1, V1> buildAsync(
@NonNull AsyncCacheLoader<? super K1, V1> loader)
AsyncCache是Cache的同级接口,这个接口很明显实现的就是对数据异步加载处理操作,AsyncLoadingCache是AsyncCache的子接口,这一点与Cache和LoadingCache是对应的。
而在进行数据加载的时候也提供了两个接口:CacheLoader、AsyncCacheLoader,观察这两个接口的源码:
public interface CacheLoader<K, V> extends AsyncCacheLoader<K, V> {}
public interface AsyncCacheLoader<K, V> {}
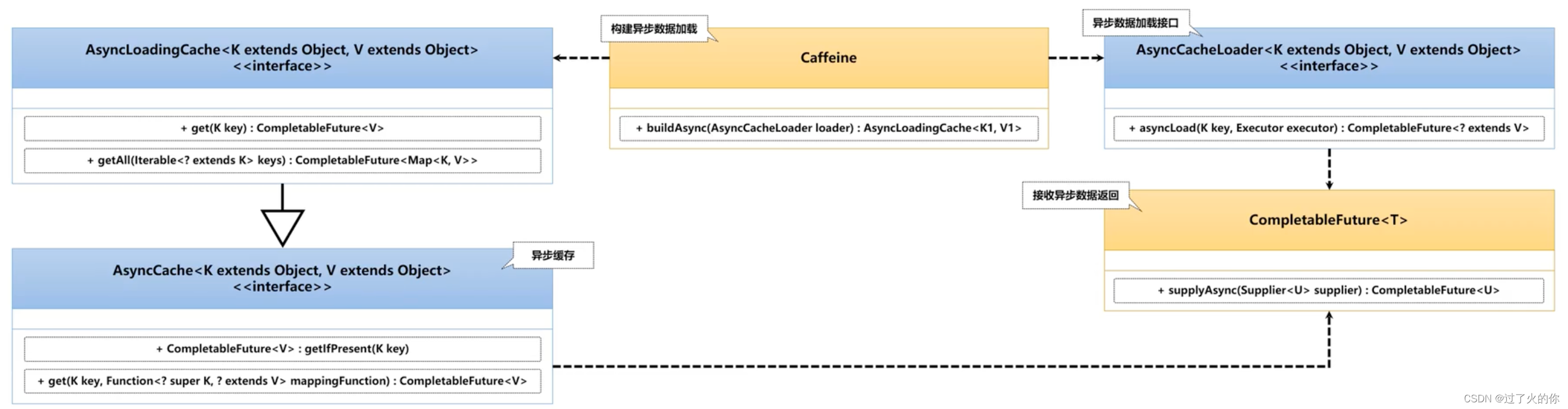
4.2 代码测试
package com.personal.caffeine.test;
import com.github.benmanes.caffeine.cache.AsyncLoadingCache;
import com.github.benmanes.caffeine.cache.Caffeine;
import com.github.benmanes.caffeine.cache.LoadingCache;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Arrays;
import java.util.Map;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
/**
* 测试caffeine的基本操作
*/
public class TestCaffeineAsync {
private static final Logger logger = LoggerFactory.getLogger(TestCaffeineAsync.class);
public static void main(String[] args) throws InterruptedException, ExecutionException {
AsyncLoadingCache<String, String> cache = Caffeine.newBuilder()//构建一个新的Caffeine实例
.maximumSize(100)//设置缓存中保存的最大数据量
.expireAfterAccess(3L, TimeUnit.SECONDS)//如无访问则3秒后失效
.buildAsync((key, executor) -> CompletableFuture.supplyAsync(() -> {
logger.info("[CacheLoader] 进行缓存数据的加载出来,当前key = {}", key);
try {
TimeUnit.SECONDS.sleep(20);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
return "[LoadingCache]" + key;
}));
cache.put("a", CompletableFuture.completedFuture("1111"));//设置缓存项
logger.info("[未超时获取缓存数据] a = {}", cache.getIfPresent("a").get());//获取数据
TimeUnit.SECONDS.sleep(5);//5秒后超时
cache.put("b", CompletableFuture.completedFuture("2222"));//设置缓存项
for (Map.Entry<String, String> entry : cache.getAll(Arrays.asList("a", "b", "c")).get().entrySet()) {
logger.info("[数据加载] key = {},value = {}", entry.getKey(), entry.getValue());
}
}
}
14:46:20.256 [main] INFO com.personal.caffeine.test.TestCaffeineAsync - [未超时获取缓存数据] a = 1111
14:46:25.312 [ForkJoinPool.commonPool-worker-2] INFO com.personal.caffeine.test.TestCaffeineAsync - [CacheLoader] 进行缓存数据的加载出来,当前key = a
14:46:25.317 [ForkJoinPool.commonPool-worker-9] INFO com.personal.caffeine.test.TestCaffeineAsync - [CacheLoader] 进行缓存数据的加载出来,当前key = c
14:46:45.340 [main] INFO com.personal.caffeine.test.TestCaffeineAsync - [数据加载] key = a,value = [LoadingCache]a
14:46:45.341 [main] INFO com.personal.caffeine.test.TestCaffeineAsync - [数据加载] key = b,value = 2222
14:46:45.341 [main] INFO com.personal.caffeine.test.TestCaffeineAsync - [数据加载] key = c,value = [LoadingCache]c
可以看出异步加载采用的是ForkJoinPool进行加载。
5. 缓存数据驱逐
缓存之中的数据内容不可能一直被保留,因为只要时间一到,缓存就应该将数据进行驱逐,但是除了时间之外还需要考虑到一个问题,缓存数据满了之后呢?是不是也应该进行一些无用数据的驱逐处理呢?
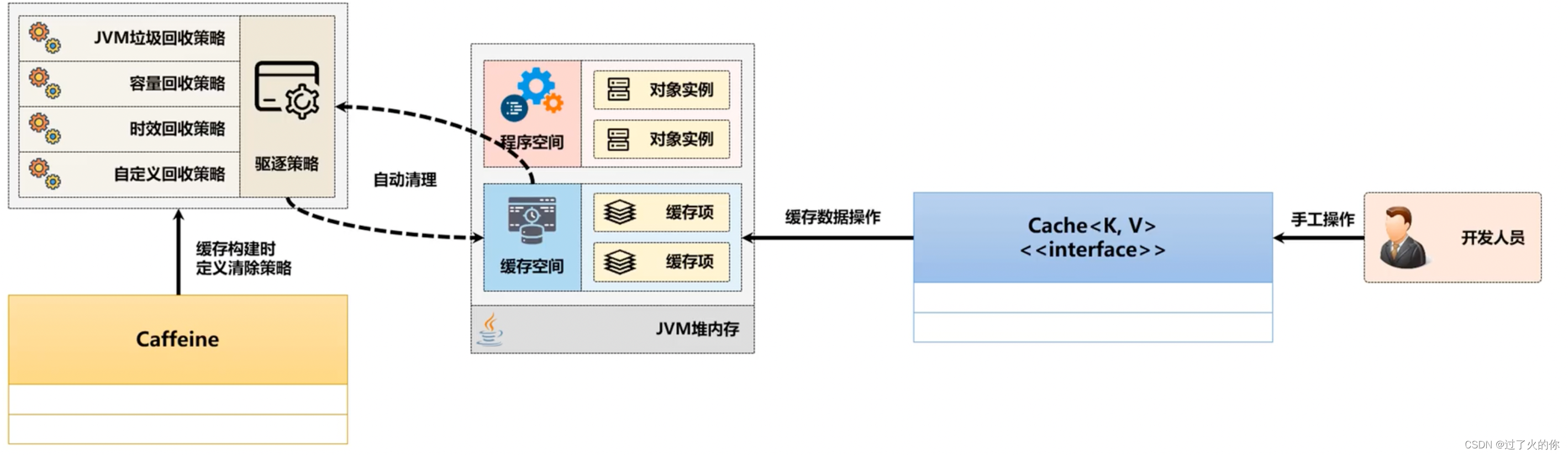
Caffeine类中提供的缓存驱逐处理方法:
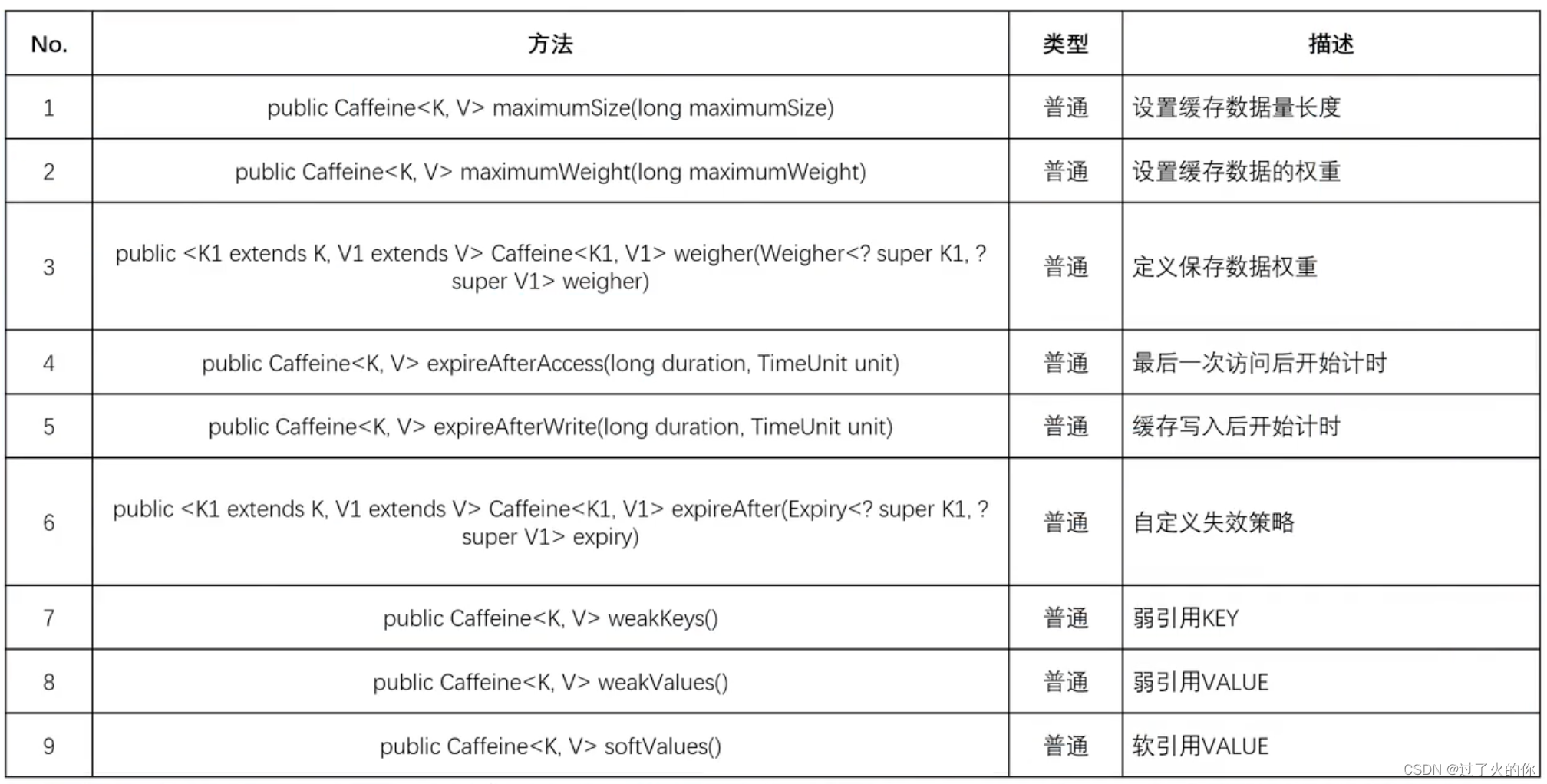
5.1 缓存容量驱逐策略
代码演示:
package com.personal.caffeine.test;
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import com.github.benmanes.caffeine.cache.LoadingCache;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Arrays;
import java.util.Map;
import java.util.concurrent.TimeUnit;
/**
* 测试caffeine的基本操作
*/
public class TestCaffeine3 {
private static final Logger logger = LoggerFactory.getLogger(TestCaffeine3.class);
public static void main(String[] args) throws InterruptedException {
Cache<String, String> cache = Caffeine.newBuilder()//构建一个新的Caffeine实例
.maximumSize(1)//设置缓存中保存的最大数据量
.expireAfterAccess(5L, TimeUnit.SECONDS)//如无访问则3秒后失效
.build();//构建Cache接口实例
cache.put("a", "1111");//设置缓存项
cache.put("b", "2222");//设置缓存项
TimeUnit.SECONDS.sleep(3);
logger.info("[未超时获取缓存数据] a = {}", cache.getIfPresent("a"));//获取数据
logger.info("[超时后获取缓存数据] b = {}", cache.getIfPresent("b"));//获取数据
}
}
13:50:13.282 [main] INFO com.personal.caffeine.test.TestCaffeine3 - [未超时获取缓存数据] a = null
13:50:13.299 [main] INFO com.personal.caffeine.test.TestCaffeine3 - [超时后获取缓存数据] b = 2222
5.2 缓存权重驱逐策略
在进行权重驱逐策略配置的时候,使用的方法为maximumWeight(),但是此时不再设置保存的个数了,因为个数的算法和权重的算法是两个不同的方式,二选一关系。
代码演示:
package com.personal.caffeine.test;
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.concurrent.TimeUnit;
/**
* 测试caffeine的基本操作
*/
public class TestCaffeine4 {
private static final Logger logger = LoggerFactory.getLogger(TestCaffeine4.class);
public static void main(String[] args) throws InterruptedException {
Cache<String, String> cache = Caffeine.newBuilder()//构建一个新的Caffeine实例
//.maximumSize(1)//设置缓存中保存的最大数据量
.maximumWeight(100)//设置缓存之中的最大权限
.weigher((key, value) -> {
logger.info("[Weigher权重计算器] key = {},value = {}", key, value);
return 51;
})
.expireAfterAccess(5L, TimeUnit.SECONDS)//如无访问则3秒后失效
.build();//构建Cache接口实例
cache.put("a", "1111");//设置缓存项
cache.put("b", "2222");//设置缓存项
TimeUnit.MILLISECONDS.sleep(100);
logger.info("[未超时获取缓存数据] a = {}", cache.getIfPresent("a"));//获取数据
logger.info("[超时后获取缓存数据] b = {}", cache.getIfPresent("b"));//获取数据
}
}
13:57:42.483 [main] INFO com.personal.caffeine.test.TestCaffeine4 - [Weigher权重计算器] key = a,value = 1111
13:57:42.491 [main] INFO com.personal.caffeine.test.TestCaffeine4 - [Weigher权重计算器] key = b,value = 2222
13:57:42.593 [main] INFO com.personal.caffeine.test.TestCaffeine4 - [未超时获取缓存数据] a = null
13:57:42.596 [main] INFO com.personal.caffeine.test.TestCaffeine4 - [超时后获取缓存数据] b = 2222
5.3 缓存时间驱逐策略
在进行驱逐的时候,对于时间的管理有两种,一种是通过最后一次读的方式进行配置(这是一种常见的模式),另一种就是通过写的时间进行计数。
写入时进行统计
package com.personal.caffeine.test;
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.concurrent.TimeUnit;
/**
* 测试caffeine的基本操作
*/
public class TestCaffeine5 {
private static final Logger logger = LoggerFactory.getLogger(TestCaffeine5.class);
public static void main(String[] args) throws InterruptedException {
Cache<String, String> cache = Caffeine.newBuilder()//构建一个新的Caffeine实例
.maximumSize(100)//设置缓存中保存的最大数据量
.expireAfterWrite(2L, TimeUnit.SECONDS)//写入后2s失效
.build();//构建Cache接口实例
cache.put("a", "1111");//设置缓存项
for (int i = 0; i < 3; i++) {
TimeUnit.MILLISECONDS.sleep(1500);
logger.info("[未超时获取缓存数据] a = {}", cache.getIfPresent("a"));//获取数据
}
}
}
14:14:37.481 [main] INFO com.personal.caffeine.test.TestCaffeine5 - [未超时获取缓存数据] a = 1111
14:14:38.988 [main] INFO com.personal.caffeine.test.TestCaffeine5 - [未超时获取缓存数据] a = null
14:14:40.489 [main] INFO com.personal.caffeine.test.TestCaffeine5 - [未超时获取缓存数据] a = null
5.4 定制化缓存清除处理
定制化的缓存驱逐策略可以通过Expiry接口来实现,这个接口内部定义有如下的处理方法
public interface Expiry<K, V> {
long expireAfterCreate(@NonNull K key, @NonNull V value, long currentTime);
long expireAfterUpdate(@NonNull K key, @NonNull V value,
long currentTime, @NonNegative long currentDuration);
long expireAfterRead(@NonNull K key, @NonNull V value,
long currentTime, @NonNegative long currentDuration);
}
}
代码演示:
package com.personal.caffeine.test;
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import com.github.benmanes.caffeine.cache.Expiry;
import org.checkerframework.checker.index.qual.NonNegative;
import org.checkerframework.checker.nullness.qual.NonNull;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.sql.Time;
import java.util.concurrent.TimeUnit;
/**
* 测试caffeine的基本操作
*/
public class TestCaffeine6 {
private static final Logger logger = LoggerFactory.getLogger(TestCaffeine6.class);
public static void main(String[] args) throws InterruptedException {
Cache<String, String> cache = Caffeine.newBuilder()//构建一个新的Caffeine实例
.maximumSize(100)//设置缓存中保存的最大数据量
.expireAfter(new Expiry<String, String>() {
@Override
public long expireAfterCreate(@NonNull String key, @NonNull String value, long currentTime) {
logger.info("[创建后失效计算] key = {},value = {}", key, value);
return TimeUnit.NANOSECONDS.convert(2, TimeUnit.SECONDS);
}
@Override
public long expireAfterUpdate(@NonNull String key, @NonNull String value, long currentTime, @NonNegative long currentDuration) {
logger.info("[更新后失效计算] key = {},value = {}", key, value);
return TimeUnit.NANOSECONDS.convert(5, TimeUnit.SECONDS);
}
@Override
public long expireAfterRead(@NonNull String key, @NonNull String value, long currentTime, @NonNegative long currentDuration) {
logger.info("[读取后失效计算] key = {},value = {}", key, value);
return TimeUnit.NANOSECONDS.convert(3, TimeUnit.SECONDS);
}
})//写后2s失效
.build();//构建Cache接口实例
cache.put("a", "1111");//设置缓存项
for (int i = 0; i < 3; i++) {
TimeUnit.MILLISECONDS.sleep(1500);
logger.info("[未超时获取缓存数据] a = {}", cache.getIfPresent("a"));//获取数据
}
}
}
14:24:40.272 [main] INFO com.personal.caffeine.test.TestCaffeine6 - [创建后失效计算] key = a,value = 1111
14:24:41.785 [main] INFO com.personal.caffeine.test.TestCaffeine6 - [读取后失效计算] key = a,value = 1111
14:24:41.792 [main] INFO com.personal.caffeine.test.TestCaffeine6 - [未超时获取缓存数据] a = 1111
14:24:43.298 [main] INFO com.personal.caffeine.test.TestCaffeine6 - [读取后失效计算] key = a,value = 1111
14:24:43.298 [main] INFO com.personal.caffeine.test.TestCaffeine6 - [未超时获取缓存数据] a = 1111
14:24:44.804 [main] INFO com.personal.caffeine.test.TestCaffeine6 - [读取后失效计算] key = a,value = 1111
14:24:44.805 [main] INFO com.personal.caffeine.test.TestCaffeine6 - [未超时获取缓存数据] a = 1111
由于此时每次读取数据的时候,都要进行一次重新的失效计算操作,所以间隔1.5秒读取的话,是可以持续读取到数据的。
如果长时间不读取数据
package com.personal.caffeine.test;
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import com.github.benmanes.caffeine.cache.Expiry;
import org.checkerframework.checker.index.qual.NonNegative;
import org.checkerframework.checker.nullness.qual.NonNull;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.sql.Time;
import java.util.concurrent.TimeUnit;
/**
* 测试caffeine的基本操作
*/
public class TestCaffeine6 {
private static final Logger logger = LoggerFactory.getLogger(TestCaffeine6.class);
public static void main(String[] args) throws InterruptedException {
Cache<String, String> cache = Caffeine.newBuilder()//构建一个新的Caffeine实例
.maximumSize(100)//设置缓存中保存的最大数据量
.expireAfter(new Expiry<String, String>() {
@Override
public long expireAfterCreate(@NonNull String key, @NonNull String value, long currentTime) {
logger.info("[创建后失效计算] key = {},value = {}", key, value);
return TimeUnit.NANOSECONDS.convert(2, TimeUnit.SECONDS);
}
@Override
public long expireAfterUpdate(@NonNull String key, @NonNull String value, long currentTime, @NonNegative long currentDuration) {
logger.info("[更新后失效计算] key = {},value = {}", key, value);
return TimeUnit.NANOSECONDS.convert(5, TimeUnit.SECONDS);
}
@Override
public long expireAfterRead(@NonNull String key, @NonNull String value, long currentTime, @NonNegative long currentDuration) {
logger.info("[读取后失效计算] key = {},value = {}", key, value);
return TimeUnit.NANOSECONDS.convert(3, TimeUnit.SECONDS);
}
})//写后2s失效
.build();//构建Cache接口实例
cache.put("a", "1111");//设置缓存项
TimeUnit.MILLISECONDS.sleep(3000);
logger.info("[未超时获取缓存数据] a = {}", cache.getIfPresent("a"));//获取数据
}
}
14:29:19.527 [main] INFO com.personal.caffeine.test.TestCaffeine6 - [创建后失效计算] key = a,value = 1111
14:29:22.556 [main] INFO com.personal.caffeine.test.TestCaffeine6 - [未超时获取缓存数据] a = null
5.5 JVM相关的驱逐操作
除了以上的这种Caffeine组件的支持之外,还可以使用JVM之中提供的数据进行驱逐操作。
package com.personal.caffeine.test;
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import com.github.benmanes.caffeine.cache.Expiry;
import org.checkerframework.checker.index.qual.NonNegative;
import org.checkerframework.checker.nullness.qual.NonNull;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.concurrent.TimeUnit;
/**
* 测试caffeine的基本操作
*/
public class TestCaffeine7 {
private static final Logger logger = LoggerFactory.getLogger(TestCaffeine7.class);
public static void main(String[] args) throws InterruptedException {
Cache<String, String> cache = Caffeine.newBuilder()//构建一个新的Caffeine实例
.maximumSize(100)//设置缓存中保存的最大数据量
.weakKeys()//弱引用的key
.weakValues()//弱引用的key用的value
// .expireAfterAccess(5L, TimeUnit.SECONDS)//如无访问则3秒后失效
.build();//构建Cache接口实例
String key = new String("a");
String value = new String("1111");
cache.put(key, value);//设置缓存项
logger.info("[GC前 获取缓存数据] a = {}", cache.getIfPresent(key));//获取数据
value = null;
Runtime.getRuntime().gc();
TimeUnit.MILLISECONDS.sleep(100);
logger.info("[GC后 获取缓存数据] a = {}", cache.getIfPresent(key));//获取数据
}
}
14:38:50.278 [main] INFO com.personal.caffeine.test.TestCaffeine7 - [GC前 获取缓存数据] a = 1111
14:38:50.405 [main] INFO com.personal.caffeine.test.TestCaffeine7 - [GC后 获取缓存数据] a = null
注意:基于这种弱引用或软引用的缓存数据的驱逐处理形式,是无法再异步缓存之中使用的。
6. 缓存数据删除与监听
6.1 缓存数据删除
对于缓存数据的删除在Caffeine组件里面有两种类型:一种是基于自动的驱逐策略的实现方式,另一种就是手工的方式实现的,如果想要删除某一个数据直接使用invalidate()方法即可。
手工删除缓存数据
package com.personal.caffeine.test;
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.concurrent.TimeUnit;
/**
* 测试caffeine的基本操作
*/
public class TestCaffeine8 {
private static final Logger logger = LoggerFactory.getLogger(TestCaffeine8.class);
public static void main(String[] args) throws InterruptedException {
Cache<String, String> cache = Caffeine.newBuilder()//构建一个新的Caffeine实例
.maximumSize(100)//设置缓存中保存的最大数据量
.build();//构建Cache接口实例
cache.put("a", "1111");//设置缓存项
logger.info("[删除前 获取缓存数据] a = {}", cache.getIfPresent("a"));//获取数据
cache.invalidate("a");
logger.info("[删除后 获取缓存数据] a = {}", cache.getIfPresent("a"));//获取数据
}
}
15:16:42.064 [main] INFO com.personal.caffeine.test.TestCaffeine8 - [删除前 获取缓存数据] a = 1111
15:16:42.074 [main] INFO com.personal.caffeine.test.TestCaffeine8 - [删除后 获取缓存数据] a = null
6.2 缓存数据监听
在进行组件设计的时候,一般会提供数据的回调操作,例如:在删除之前请给我一些“忏悔”的时间。为了实现这样的支持,Caffeine组件里面提供了一个删除监听的操作,删除数据之前可以通过监听获取到一些信息。
package com.personal.caffeine.test;
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import com.github.benmanes.caffeine.cache.RemovalCause;
import com.github.benmanes.caffeine.cache.RemovalListener;
import org.checkerframework.checker.nullness.qual.NonNull;
import org.checkerframework.checker.nullness.qual.Nullable;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.concurrent.TimeUnit;
/**
* 测试caffeine的基本操作
*/
public class TestCaffeine8 {
private static final Logger logger = LoggerFactory.getLogger(TestCaffeine8.class);
public static void main(String[] args) throws InterruptedException {
Cache<String, String> cache = Caffeine.newBuilder()//构建一个新的Caffeine实例
.maximumSize(100)//设置缓存中保存的最大数据量
.expireAfterAccess(2L, TimeUnit.SECONDS)
.removalListener(new RemovalListener<String, String>() {
@Override
public void onRemoval(@Nullable String key, @Nullable String value, @NonNull RemovalCause cause) {
logger.info("[数据删除监听] key = {}, value = {}, cause = {}", key, value, cause);
}
})
.build();//构建Cache接口实例
cache.put("a", "1111");//设置缓存项
cache.put("b", "2222");//设置缓存项
cache.invalidate("a");
TimeUnit.SECONDS.sleep(5);
logger.info("[删除后 获取缓存数据] b = {}", cache.getIfPresent("b"));//获取数据
TimeUnit.SECONDS.sleep(Long.MAX_VALUE);
}
}
15:23:38.752 [ForkJoinPool.commonPool-worker-9] INFO com.personal.caffeine.test.TestCaffeine8 - [数据删除监听] key = a, value = 1111, cause = EXPLICIT
15:23:43.762 [main] INFO com.personal.caffeine.test.TestCaffeine8 - [删除后 获取缓存数据] b = null
15:23:43.768 [ForkJoinPool.commonPool-worker-9] INFO com.personal.caffeine.test.TestCaffeine8 - [数据删除监听] key = b, value = 2222, cause = EXPIRED
所有被清除的数据清除之后,都会触发配置的删除监听器,并且通过RemovalCause枚举类获取当前数据被清除的真实原因,以便于开发者控制。
7. CacheStats
7.1 接口梳理
Caffeine开发组件有一个最为重要的特点就是自带数据的统计功能,例如:你的缓存查询了多少次,有多少次是查询准确(指定的KEY存在并且可以返回最终的数据),查询有多少次是失败的。默认情况下是没有开启数据统计信息,如果想要获取到统计信息,则需要使用Caffeine开发类提供的处理方法。
static final Supplier<StatsCounter> ENABLED_STATS_COUNTER_SUPPLIER = ConcurrentStatsCounter::new;
public Caffeine<K, V> recordStats() {
requireState(this.statsCounterSupplier == null, "Statistics recording was already set");
statsCounterSupplier = ENABLED_STATS_COUNTER_SUPPLIER;
return this;
}
在使用数据统计的时候,Caffeine内部使用了一个StatsCounter接口类型,观察此接口。同时还存在有一个ConcurrentStatsCounter类型
public final class ConcurrentStatsCounter implements StatsCounter {
private final LongAdder hitCount;
private final LongAdder missCount;
private final LongAdder loadSuccessCount;
private final LongAdder loadFailureCount;
private final LongAdder totalLoadTime;
private final LongAdder evictionCount;
private final LongAdder evictionWeight;
.......
}
最终如果想要实现数据统计的处理操作,那么肯定是需要通过StatsCounter接口实现的,而这个接口提供有一个内置的并发数据统计的操作实现子类。以上的操作仅仅是开启了数据统计的处理支持,但是如果想要最终获取到这些统计的信息,那么就需要提供有另一个方法的支持,这个方法是由Cache接口来定义的。
CacheStats stats();
此时的方法返回的是一个CacheStats类对象,而后这个类也提供了许多数据统计的处理操作方法,实际上StatsCounter接口的内部也提供有一个快照的处理方法。
CacheStats snapshot();
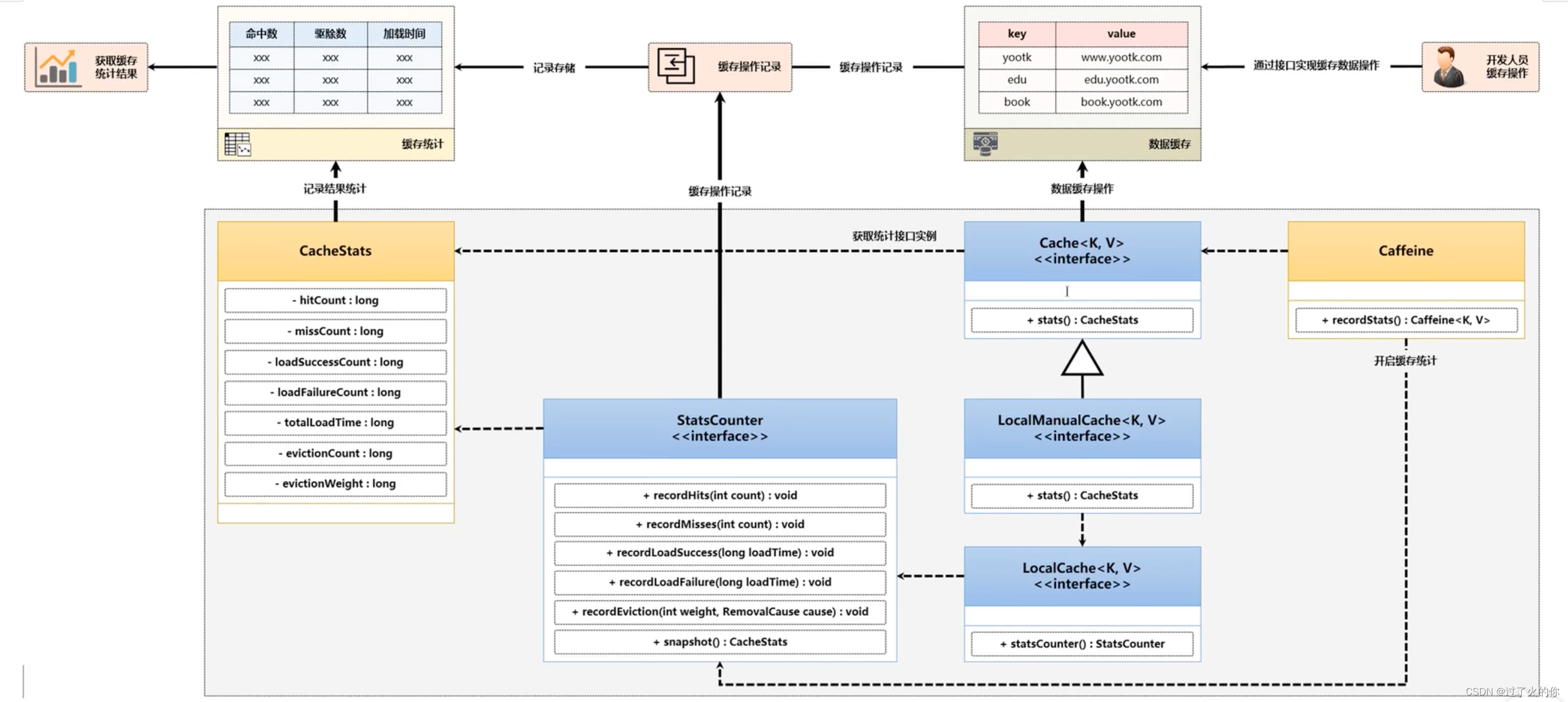
按照以上的分析,已经可以得出对于数据统计操作里面所使用的相关的核心处理方法,那么下面给出的一张完整的操作接口图,来观察一下这些方法之间的联系。
Caffeine缓存组件除了提供强大的缓存处理性能之外,也额外提供了一些缓存数据的统计功能,每当用户进行缓存数据操作时,都可以对这些操作记录的结果进行记录,这样就可以准确的知道缓存命中数、失效数、驱逐数等统计结果。
CacheStats类常用的方法:
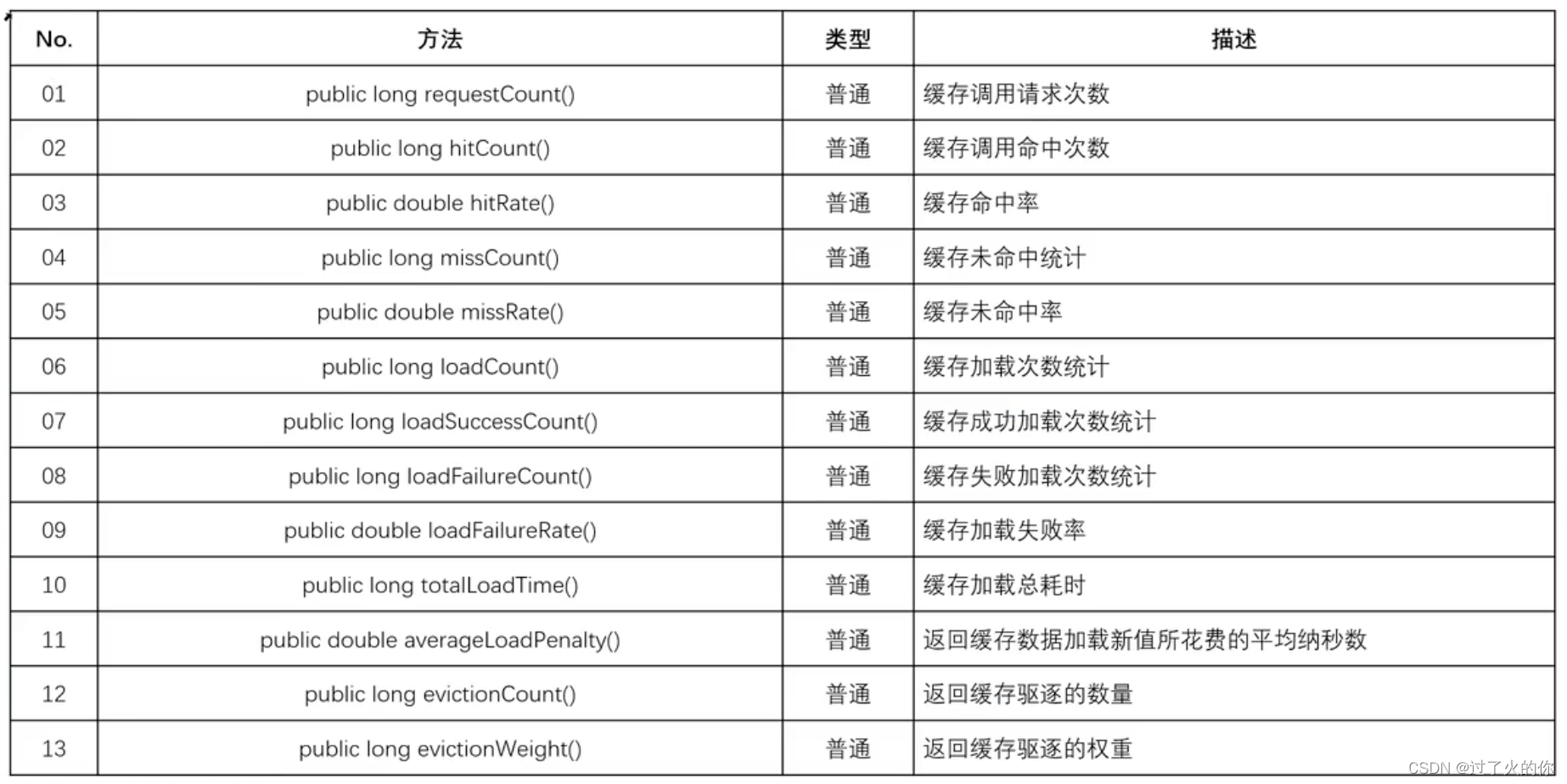
7.2 代码测试
package com.personal.caffeine.test;
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import com.github.benmanes.caffeine.cache.RemovalCause;
import com.github.benmanes.caffeine.cache.RemovalListener;
import com.github.benmanes.caffeine.cache.stats.CacheStats;
import org.checkerframework.checker.nullness.qual.NonNull;
import org.checkerframework.checker.nullness.qual.Nullable;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Random;
import java.util.concurrent.TimeUnit;
/**
* 测试caffeine的基本操作
*/
public class TestCaffeine9 {
private static final Logger logger = LoggerFactory.getLogger(TestCaffeine9.class);
public static void main(String[] args) throws InterruptedException {
Cache<String, String> cache = Caffeine.newBuilder()//构建一个新的Caffeine实例
.maximumSize(100)//设置缓存中保存的最大数据量
.expireAfterAccess(1000L, TimeUnit.MILLISECONDS)
.recordStats()
.build();//构建Cache接口实例
cache.put("a", "1111");//设置缓存项
cache.put("b", "2222");//设置缓存项
cache.put("c", "3333");//设置缓存项
//此时设置的候选key数据是有些不存在的,通过这些不存在的数据进行最终的非命中统计操作
String[] keys = new String[]{"a", "b", "c", "d", "e",};
Random random = new Random();
for (int i = 0; i < 100; i++) {
TimeUnit.MILLISECONDS.sleep(50);
new Thread(() -> {
String key = keys[random.nextInt(keys.length)];
logger.info("[{}] key = {}, vaule = {}", Thread.currentThread().getName(), key, cache.getIfPresent(key));
}, "查找线程 - " + i).start();
}
TimeUnit.SECONDS.sleep(1);
CacheStats stats = cache.stats();
logger.info("[CacheStats] 缓存操作请求次数 : {}", stats.requestCount());
logger.info("[CacheStats] 缓存命中次数 : {}", stats.hitCount());
logger.info("[CacheStats] 缓存未命中次数 : {}", stats.missCount());
//所有缓存组件中,最为重要的一项性能指标就是命中率的处理问题
logger.info("[CacheStats] 缓存命中率 : {}", stats.hitRate());
logger.info("[CacheStats] 缓存驱逐次数 : {}", stats.evictionCount());
}
}
......
16:44:51.870 [查找线程 - 97] INFO com.personal.caffeine.test.TestCaffeine9 - [查找线程 - 97] key = d, vaule = null
16:44:51.921 [查找线程 - 98] INFO com.personal.caffeine.test.TestCaffeine9 - [查找线程 - 98] key = a, vaule = 1111
16:44:51.974 [查找线程 - 99] INFO com.personal.caffeine.test.TestCaffeine9 - [查找线程 - 99] key = c, vaule = null
16:44:52.992 [main] INFO com.personal.caffeine.test.TestCaffeine9 - [CacheStats] 缓存操作请求次数 : 100
16:44:52.993 [main] INFO com.personal.caffeine.test.TestCaffeine9 - [CacheStats] 缓存命中次数 : 38
16:44:52.993 [main] INFO com.personal.caffeine.test.TestCaffeine9 - [CacheStats] 缓存未命中次数 : 62
16:44:52.993 [main] INFO com.personal.caffeine.test.TestCaffeine9 - [CacheStats] 缓存命中率 : 0.38
16:44:52.996 [main] INFO com.personal.caffeine.test.TestCaffeine9 - [CacheStats] 缓存驱逐次数 : 1
对于缓存数据的命中率来讲还是挺高的,在实际开发之中要利用命中率的方式来进行一些缓存数据KEY的优化,包括过期处理方案的优化,如果现在结合到数据库上去使用这个操作,那么最终如果命中率很低,那么就会带来数据库查询的猛增,从而出现整体的性能问题。







![[Spring Boot]09 Spring Boot集成和使用Redis](https://img-blog.csdnimg.cn/fe81bf7f5ba648b4864de8c504b30e7a.gif#pic_center)