有道无术,术尚可求,有术无道,止于术。
文章目录
- Elastic公司
- Elastic Stack
- Elasticsearch
- 结构化/非结构化数据
- 全文搜索
- ES 发展史
- ES 特点
- ES 应用场景
- ES 应用案例
- Beats 系列
- Logstash
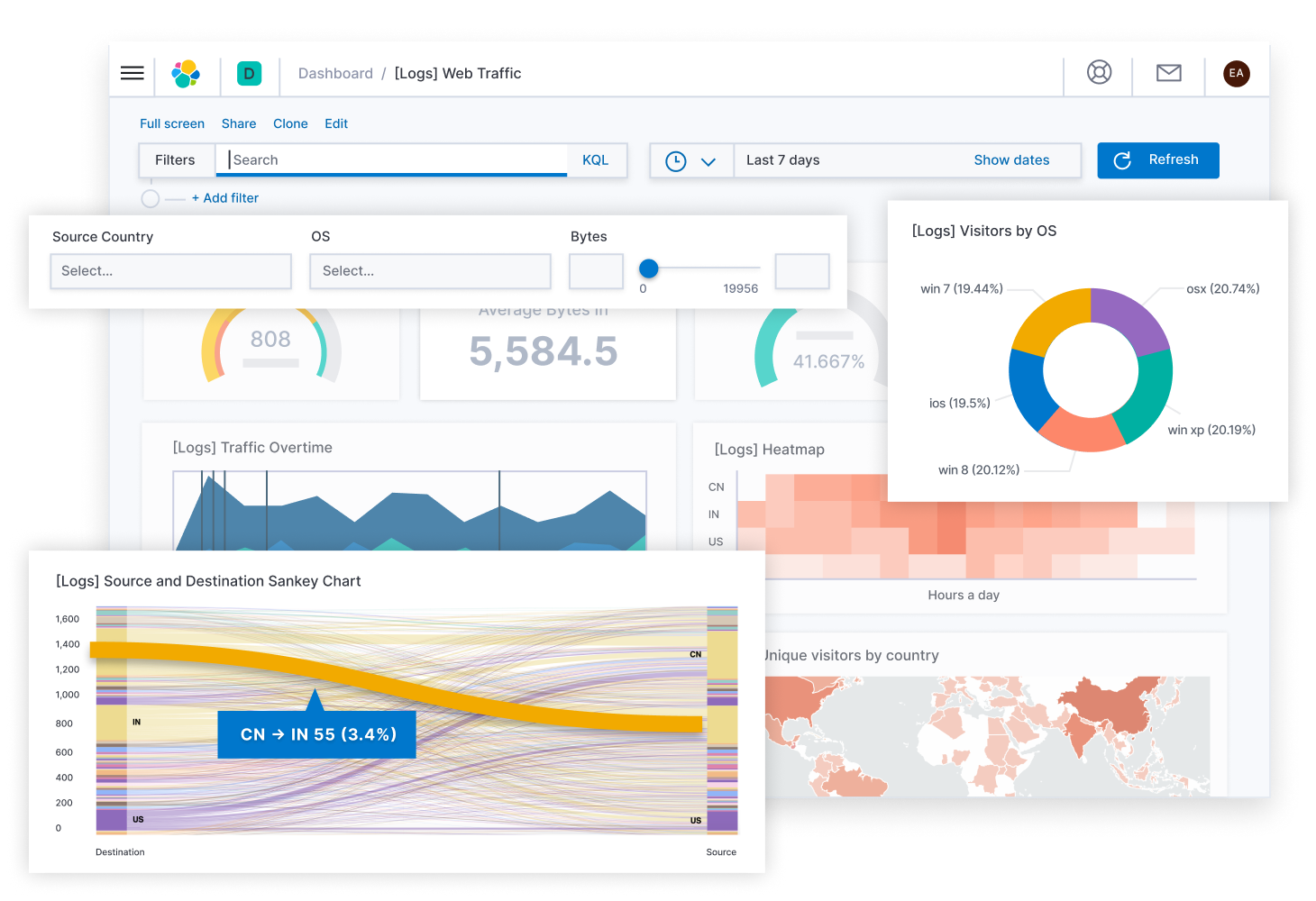
- Kibana
Elastic公司
Elastic是一家以搜索引擎闻名世界的软件公司。于2012年成立,总部位于美国的山景城。
2018年10月上市,目前市值近50多亿美金。❗️❗️❗️
Elastic 公司致力于结构化和非结构化数据的分布式实时全文搜索及分析,典型应用场景包括日志管理、分析、系统指标分析、安全分析、企业搜索、网站搜索、应用搜索、应用性能管理APM等。
Elastic 公司产品包括享誉业界的 Elastic Stack、具备多种高级特性的商业扩展插件、云服务Elastic Cloud等。
国内代表用户:华为,联想,华大基因,腾讯,网易,阿里巴巴,百度,携程,滴滴,京东,顺丰🐆🐆🐆
Elastic Stack
官网地址
Elastic Stack是一些系列能够安全可靠地获取任何来源、任何格式的数据,然后实时地对数据进行搜索、分析和可视化的软件。核心产品包括 Elasticsearch、Kibana、Beats 和 Logstash等等。
Elasticsearch
Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎。作为Elastic Stack的核心,Elasticsearch 集中存储数据,并完成数据搜索、分析。
结构化/非结构化数据
1、结构化数据
就像结构化一词所暗示的那样,这是高度组织化且格式整齐的数据,结构化数据被组织以表格格式(即,行和列)和有不同的行和列之间的关系,因此它是高度组织和格式化的,易于存储,处理和访问。
主要通过关系型数据库进行存储和管理。
2、非结构化数据
非结构化数据是未以任何预定义方式进行组织的数据,非结构化数据中的不规则性和混乱使得难以处理和理解。不适于由数据库二维表来表现,常见的包括所有格式的办公文档、Word 文档,邮件,各类报表、图片和咅频、视频信息等。
3、半结构化数据
可以更加细分具有自己特定的标签格式,可以根据需要按结构化数据来处理,也可抽取出纯文本按非结构化数据来处理的数据为半结构化数据。例如XML、JSON、HTML、NoSQL DB等。
全文搜索
对于结构化数据的搜索,如对数据库数据的搜索,可以使用 SQL 语句,也可以建⽴索引,通过索引快速搜索数据。
非结构化数据搜索方法主要有顺序扫描、全文搜索。
1、 顺序扫描
顺序扫描顾名思义,就是按照顺序依次扫描,例如要找出内容包含某个字符串的文件,需要依次对所有文件扫描,对于每一个文件,从头到尾扫描,如果当前文件包含该字符,此文件放入结果集,接着扫描下一个文件,直到扫描所有的文件,返回结果集。
顺序扫描查询准确率高,查询速度会随着查询数据量的增大而急速变慢。
2、 全文搜索
将非结构化数据中的一部分信息提取出来,重新组织,建立索引,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)。
例如字典的拼音表和部首检字表就相当于字典的索引,对每一个字的解释是非结构化的,如果字典没有音节表和部首检字表,在茫茫辞海中找一个字只能顺序扫描。
然而字的某些信息可以提取出来进行结构化处理,比如读音,就比较结构化,分声母和的母,分别只有几种可以一一列举,于是将读音拿出来按一定的顺序排列,每一项读音都指向此字的详细解释的页数。我们搜索时按结构化的拼音搜到读音,然后按其指向的页数,便可找到我们的非结构化数据也即对字的解释。
虽然创建索引的过程也是非常耗时的,但是索引一旦创建就可以多次使用,全文检索主要处理的是查询,所以耗时间创建索引是值得的。
互联网全文搜索引擎就是通过从互联网上提取的各个网站的信息(以网页文字为主)而建立的数据库中,检索与用户查询条件匹配的相关记录,然后按一定的排列顺序将结果返回给用户。国外代表有 Google,国内则有百度。
ES 发展史
Shay Banon是ElasticSearch的创始人,他曾说过:搜索是每一个软件都必须拥有的功能
2004年Shay Banon基于Lucene开发了Compass(ES的前身)。
2010年Shay Banon重写了Compass,取名ElasticSearch。
2010年2 月,Elasticsearch第一个公开版本正式发行,成为Github上最受欢迎的开源项目之一。
ES 特点
1、分布式
无论Elasticsearch是在一个节点上运行,还是在一个包含 300 个节点的集群上运行,都能够以相同的方式与Elasticsearch进行通信。
它能够水平扩展,每秒钟可处理海量事件,同时能够自动管理索引和查询在集群中的分布方式,以实现极其流畅的操作。
2、高可用
Elasticsearch 自动检测硬件、网络故障,并确保集群(和数据)的安全性和可用性。
Elasticsearch 运行在一个分布式的环境中,通过跨集群复制功能,辅助集群可以作为热备份随时投入使用。
3、廉价存储
数据是不断变化的,这使得存储和搜索全部数据变得非常昂贵。Elasticsearch 能让您在性能和成本之间取得平衡。可以将数据存储在本地以实现快速查询,也可以将无限量的数据远程存储于低成本的服务器上。
4、智能搜索
基于各项元素(从词频或新近度到热门度等)对搜索结果进行排序。将这些内容与功能进行混搭,以优化向用户显示结果的方式。
而且,由于我们的大部分用户都是真实的人,Elasticsearch 具备齐全功能,可以处理包括各种复杂情况(例如拼写错误)在内的人为错误。
5、搜索方式多样性
通过 Elasticsearch,能够执行及合并多种类型的搜索(结构化数据、非结构化数据、地理位置、指标),搜索方式随心而变。
6、海量数据
找到与查询最匹配的 10 个文档并不困难。但如果面对的是十亿行日志,又该如何解读呢?Elasticsearch 聚合让您能够从大处着眼,探索数据的趋势和规律。
7、速度快
通过有限状态转换器实现了用于全文检索的倒排索引,实现了用于存储数值数据和地理位置数据的BKD树,以及用于分析的列存储。
而且由于每个数据都被编入了索引,因此不用因为某些数据没有索引而烦心。可以用快到令人惊叹的速度使用和访问所有数据。
ES 应用场景
适用于所有数据类型。数字、文本、地理位置、结构化数据、非结构化数据。全文本搜索只是全球众多公司利用 Elasticsearch 解决各种挑战的冰山一角。

ES 应用案例
GitHub: 2013 年初,抛弃了 Solr,采取 Elasticsearch 来做 PB 级的搜索。 GitHub 使用Elasticsearch 搜索 20TB 的数据,包括 13 亿文件和 1300 亿行代码。
维基百科:以Elasticsearch为基础的核心搜索架构。
百度:目前广泛使用 Elasticsearch 作为文本数据分析,采集百度所有服务器上的各类指标数据及用户自定义数据,通过对各种数据进行多维分析展示,辅助定位分析实例异常或业务层面异常。目前覆盖百度内部 20 多个业务线(包括云分析、网盟、预测、文库、直达号、钱包、 风控等),单集群最大 100 台机器,200个 ES 节点,每天导入 30TB+数据。
新浪:使用Elasticsearch分析处理 32 亿条实时日志。
阿里:使用 Elasticsearch 构建日志采集和分析体系。
Stack Overflow:解决 Bug 问题的网站,全英文,编程人员交流的网站。
Beats 系列
Beats系列集合了多种单一用途数据采集器,可以从成百上千或成千上万台机器和系统向 Logstash 或 Elasticsearch 发送数据。

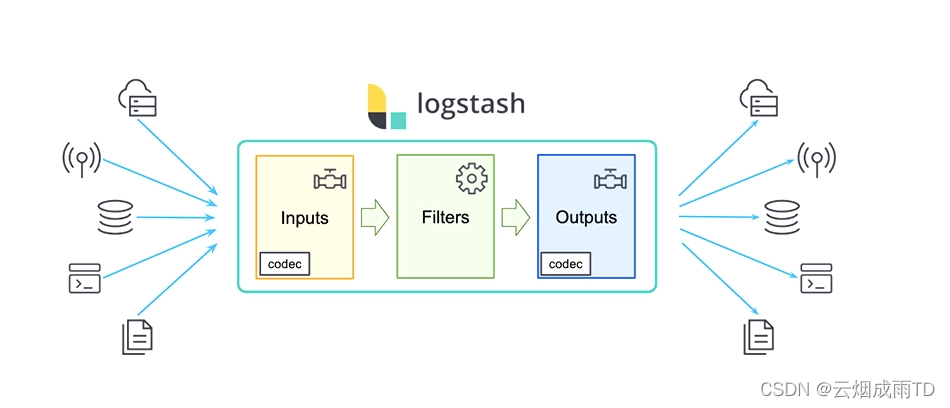
Logstash
Logstash是具有实时流水线能力的开源的数据收集引擎。可以动态统一不同来源的数据,并将数据标准化到您选择的目标输出。它提供了大量插件,可帮助我们解析,丰富,转换和缓冲任何类型的数据。
Kibana
Kibana 是一个免费且开放的用户可视化界面,能够让您对Elasticsearch数据进行可视化。