python爬虫2之利用cookie进行登录
- 利用requests模拟post方法
- cookies的获取
- session
- 综合实例
- 拓展:实现时间间隔(第一次抓取后间隔...秒进行下一次抓取)
利用requests模拟post方法
requests.post(url=,data=,hearders=)
- url即要解析的网址
- data即是向服务器添加的信息;注意类型必须为字典
- hearders此处常设置用户代理User-Agent
此处以百度翻译为例子,打开百度翻译输入相关信息观察,如下图所示:

例如requests实现代码如下:
#百度翻译栗子
import requests
url="https://fanyi.baidu.com/sug"
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.102 Safari/537.36 Edg/104.0.1293.70'
}
#要添加的信息
data={
'kw':'hello'
}
#post方法
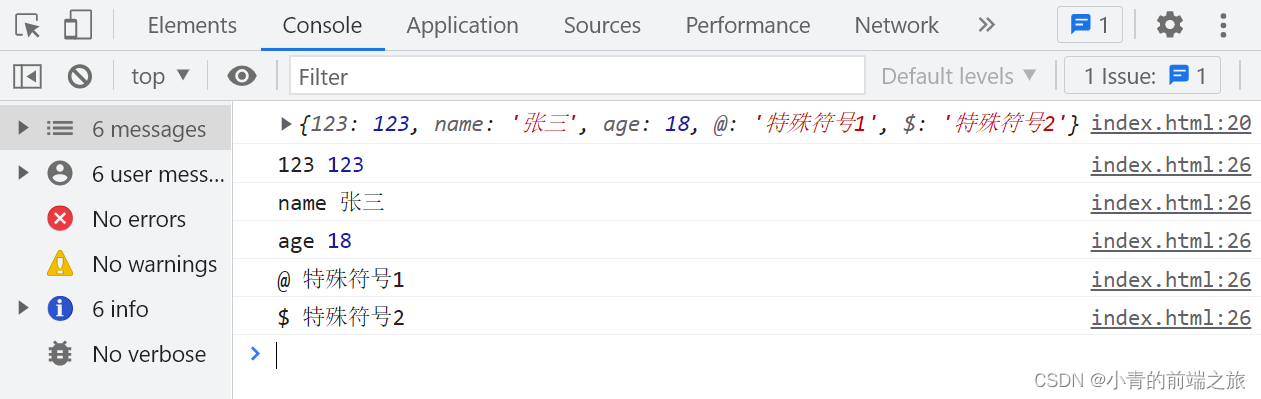
response=requests.post(url=url,headers=headers,data=data)
#response.json()表示以.json形式展示
dic_obj=response.json()
#访问字典中值
results=dic_obj['data']
#循环输出结果
for result in results:
print(result)
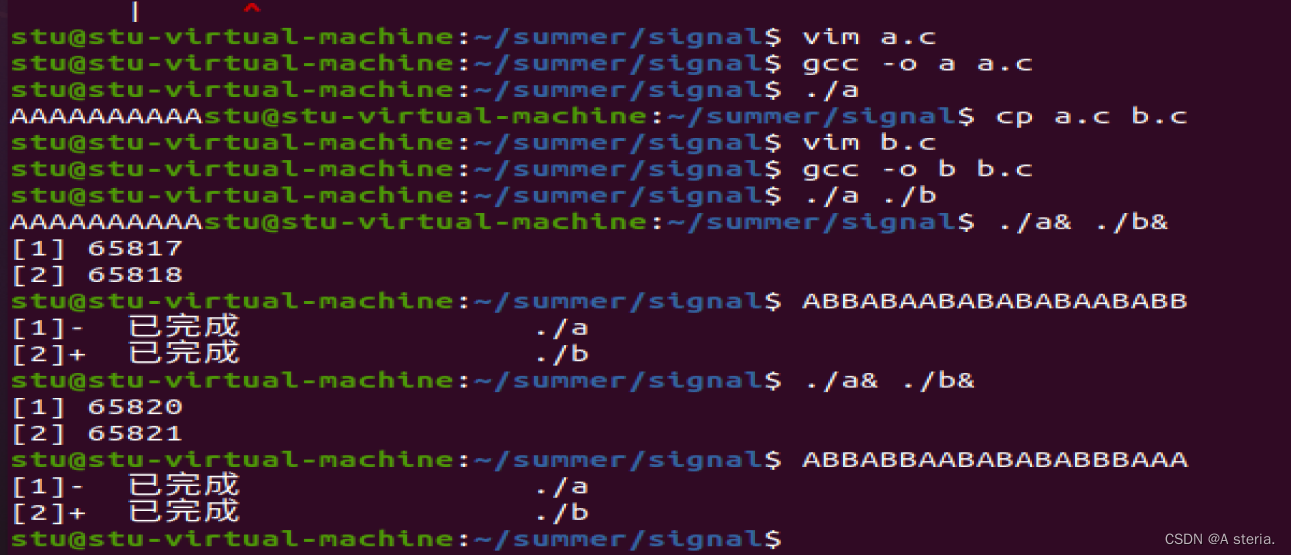
运行效果如下:

cookies的获取
cookie中文名称为小型文件系统,由于HTTP是一种无状态的协议,某些网站为了辨别用户身份、进行会话跟踪故产生了cookie;cookie多用于判断用户是否登录
import requests
response=requests.get("https://ffyx.vip")
#获取cookie对象
cookiejar=response.cookies
print(type(cookiejar))
print(cookiejar)
#将获取到的cookie对象转换为字典型
cookiedict=requests.utils.dict_from_cookiejar(cookiejar)
print(type(cookiedict))
print(cookiedict)
运行效果如下图所示:

session
session代表一次用户会话,从客户端浏览器连接服务器开始,到客户端浏览器与服务器断开,用户可以理解为一通电话,从拨打到挂断
- 创建session对象
session变量名=requests.session()
- post模拟用户登录操作保存cookie值
session变量名.post('登录页面URL',data=登录的用户名和密码等信息(数据类型为字典))
- get访问登陆后才可访问的相关页面
session变量名.get('URL')
综合实例
实现FFYX 网站的登录
用浏览器点击该网站进行登录操作观察相关URL:
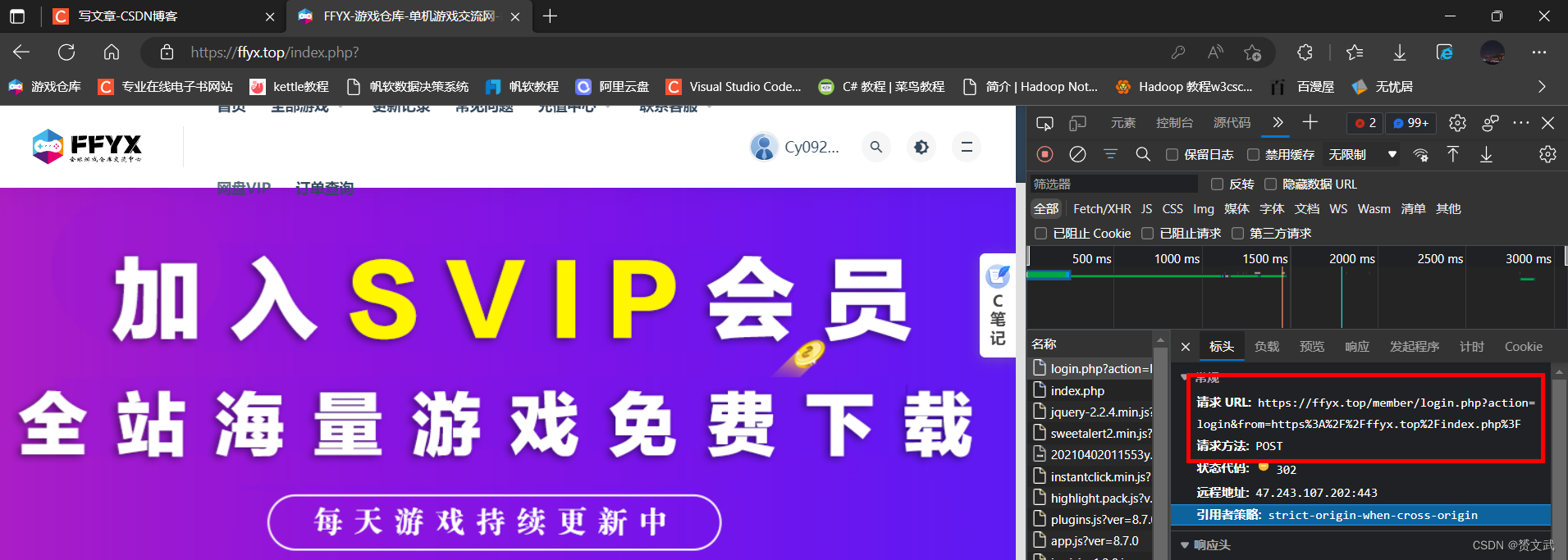
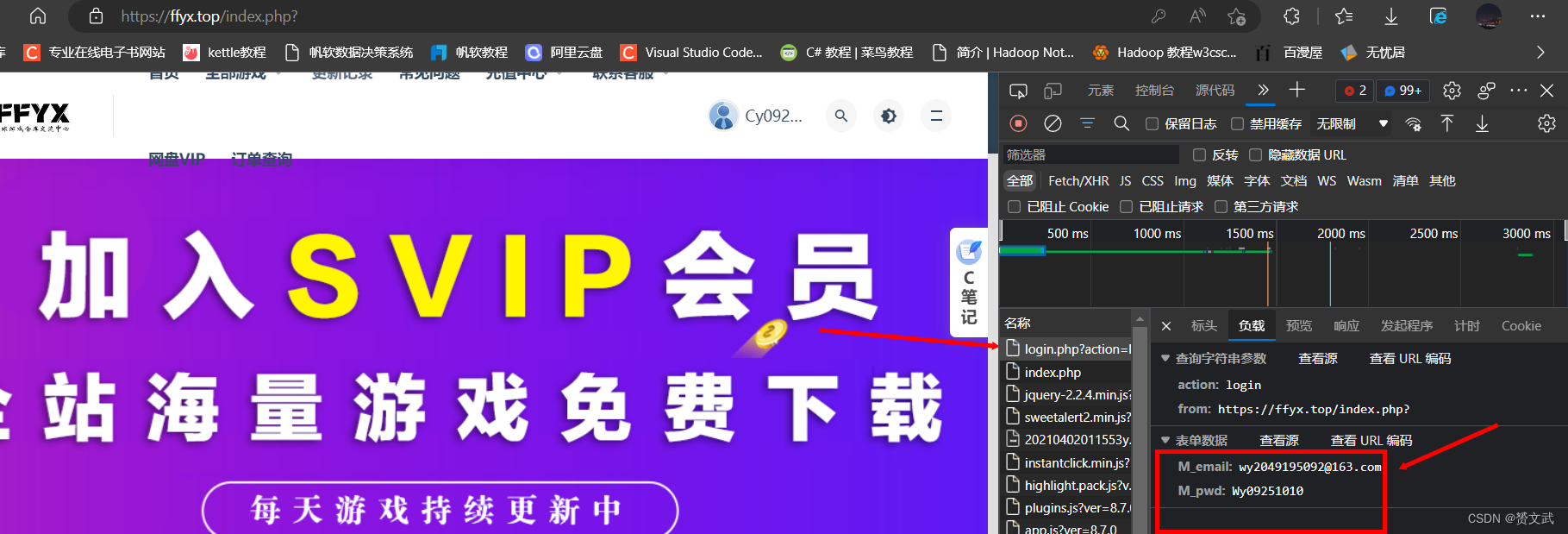
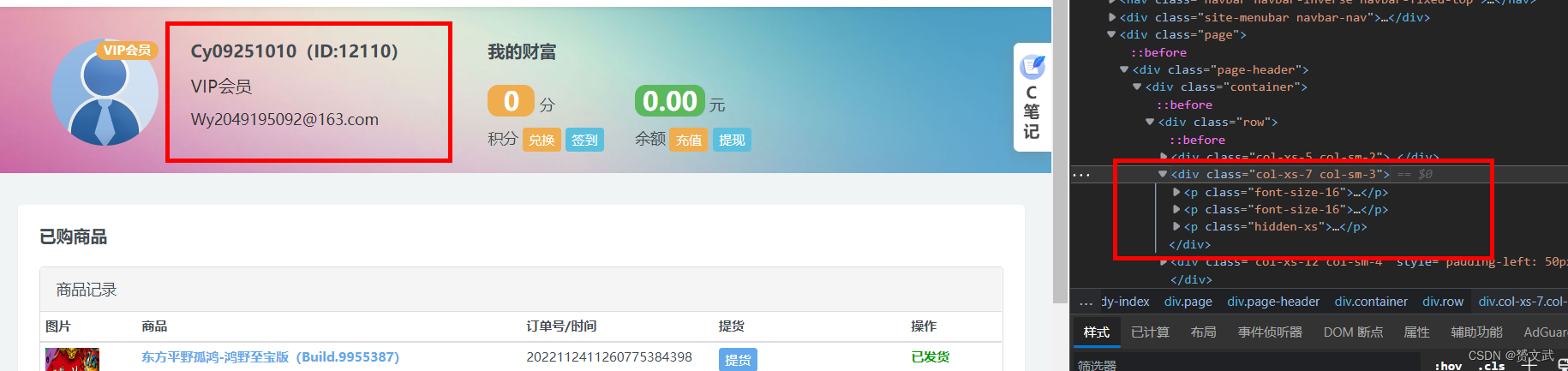
点击我的订单确定要抓取的数据:
完整代码如下所示:
import requests
from bs4 import BeautifulSoup
# 创建session对象
ssion=requests.session()
# 登录传递的数据
data={
'M_email':'wy2049195092@163.com',
'M_pwd':'Wy09251010'
}
# 实现登陆操作并获取登陆后的cookie值
ssion.post('https://ffyx.top/member/login.php?action=login&from=index.php',data=data)
# 访问登陆后才能访问的页面(我的订单)
req=ssion.get('https://ffyx.top/member/product.php')
bs=BeautifulSoup(req.content,'html.parser')
# 抓取我的订单登录个人信息
results=bs.find_all('div',{'class':'col-xs-7 col-sm-3'})
for result in results:
print(result.get_text())
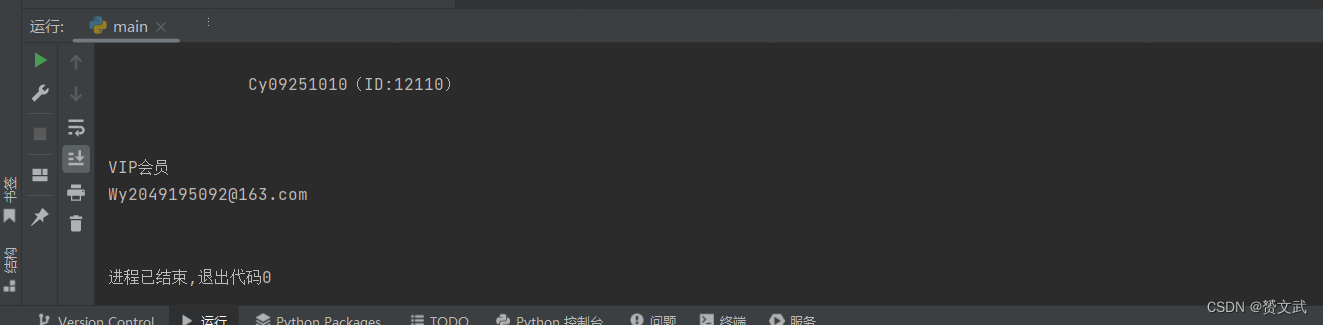
运行结果如下所示:
拓展:实现时间间隔(第一次抓取后间隔…秒进行下一次抓取)
#导入时间模块
import time
#睡眠15秒即等待15秒
time.sleep(15)
#打印hello world
print('hello world')
运行该代码,hello world会在15秒后被打印,将其放在爬虫相关位置可实现每隔一段时间爬取下一页面